为了帮助大家更深入地理解 ArcBlock 的开放链访问协议的实现和技术细节,我们的工程团队将定期写技术文章来“解密”我们在设计和开发 OCAP 过程中的一些技术细节。 希望读者能借此了解 OCAP 背后的设计思路和实现细节,也许你可以参与来实现更多的 OCAP 链适配器,支持更多的区块链协议。 也欢迎大家来指出我们设计中的不足,在讨论中完善我们的设计。
作者:丁沛灵 (ArcBlock 团队软件工程师)
为什么要解析 Bitcoin 数据?
我们在七月底如期发布了 OCAP 的第一版本。在这一版本中,OCAP 提供了针对 Bitcoin 数据的查询服务。用户不仅可以快速的通过 Hash 拿到某一个 Block 或者 Transaction 的信息,并且还可以做复杂的级联查询,比如查询特定的两个地址之间的交易。下面的这个 query 就可以返回那个著名的 Pizza 交易
{
transactionsByAddress(sender: "17SkEw2md5avVNyYgj6RiXuQKNwkXaxFyQ", receiver: "13TETb2WMr58mexBaNq1jmXV1J7Abk2tE2") {
data {
blockHeight
hash
total
numberInputs
numberOutputs
}
}}
原生的 Bitcoin API 并不支持这样的数据查询,所以想要让 OCAP 具备这样的查询功能,我们就必须预处理 Bitcoin 上的数据,让它以我们想要的方式存储。这也就引出了我们今天的主题 – 如何解析 Bitcoin 数据?
概述
在讲技术细节之前我们先从整体上理解一下我们要干什么,为了说清楚一点,我们可以类比搜索引擎。
众所周知,互联网上的数据纷繁复杂,而搜索引擎却能在海量的数据里面迅速的查找出用户想要的结果。其之所以能够做到这一点是因为搜索引擎的后面还有两个默默付出的组件 – 爬虫和倒排索引。 爬虫负责不停的从互联网上搜集数据,倒排索引负责将数据以特定的形式存储,以便搜索引擎能够快速的查询。
同样的,ArcBlock OCAP 所支持的区块链查询就相当于提供针对区块链的“搜索引擎”服务,也少不了类似的预处理过程。不同于搜索引擎,我们不需要一个爬虫,因为 Bitcoin 的数据都是以二进制的形式存在节点的磁盘上的。但是数据是以一种对人不太友好的方式组织在一起的,所以我们首先需要一个解析器,将这些二进制数据读出来,还原成它们本来的面目。之后我们再对这些数据进行一些加工,就得到了 OCAP 所需要的数据。
技术细节
在这里我会主要谈谈 Bitcoin 的数据具体是怎么存储的,并且在得到这些数据之后还需要做哪些额外的计算。
Bitcoin 数据是如何存储的
存储数据的文件
Bitcoin 的原始数据可以在$HOME/.bitcoin/blocks 下面找到。这个目录下面主要有两类文件,一种是类似于这样的文件:blk00952.dat, 而另一种是类似于这样的文件:rev000952.dat。 前一种 blk 开头的文件就是存储 Bitcoin 源数据的文件,而后一种是用来做 rewind 的。关于 rewind 我们下回再表,我们这次的重点在源数据文件。每一个 blk 数据文件大小的上限都是 128MB。当一个文件写满后,Bitcoin 程序会新建一个类似的文件来存储新收到的区块信息。
让我们先通过如下命令,来看看这些文件里面都存了什么。
od -x --endian=big -N 297 -An blk00000.dat
f9be b4d9 1d01 0000 0100 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 3ba3 edfd
7a7b 12b2 7ac7 2c3e 6776 8f61 7fc8 1bc3
888a 5132 3a9f b8aa 4b1e 5e4a 29ab 5f49
ffff 001d 1dac 2b7c 0101 0000 0001 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 ffff
ffff 4d04 ffff 001d 0104 4554 6865 2054
696d 6573 2030 332f 4a61 6e2f 3230 3039
2043 6861 6e63 656c 6c6f 7220 6f6e 2062
7269 6e6b 206f 6620 7365 636f 6e64 2062
6169 6c6f 7574 2066 6f72 2062 616e 6b73
ffff ffff 0100 f205 2a01 0000 0043 4104
678a fdb0 fe55 4827 1967 f1a6 7130 b710
5cd6 a828 e039 09a6 7962 e0ea 1f61 deb6
49f6 bc3f 4cef 38c4 f355 04e5 1ec1 12de
5c38 4df7 ba0b 8d57 8a4c 702b 6bf1 1d5f
ac00 0000 00f9 beb4 d900
上面的文件就是 Bitcoin 的 Genesis BLock。它是二进制数据(以 16 进制表示),每两个字符表示一个字节。乍一看感觉乱七八糟看不懂,但是当你了解他们的数据格式之后,一切都不是那么难。
数据的存储结构
Bitcoin 官网上有关于数据格式的具体讲解,但是他们的文档的组织结构并不容易阅读理解,所以我们自己总结了一个更直观的图表。
对图的说明:
这个图代表一个区块文件,而一个 blkxxxx.data 文件正是由一个个这样的区块组成的。
在上图中,蓝色代表复合数据类型,橙色代表简单数据类型,绿色是注解。比如一个区块文件由 Preamble 和 Block 组成。而一个 Block 由一个 Block Header,Number of Transactions 和若干个 Transaction 组成。每个 Transaction 又由几个简单数据类型和若干个 Transaction Input/Ouput 组成。以此类推。
几乎所有数据都是以小端类型(注:Little-Endian,下同)存储的,但是 Transaction Input/Output 里的
script除外。它们是以大端方式(注:Big-Endian,下同)存储的。magic number是一个固定的数,其值为 0xD9B4BEF9variable integer本身的长度不定,在 1 到 9 字节之间。具体的解析规则如下:
如果第一个字节小于 253,那么直接返回该字节所代表的数值
如果第一个字节等于 253,那么往后再读一个字节作,将其值作为返回值
如果第一个字节等于 254,那么往后再读四个字节作,将其值作为返回值
如果第一个字节等于 255,那么往后再读八个字节作,将其值作为返回值
如果我们把之前的数据按照上述规则带入的话可以得到如下图表。
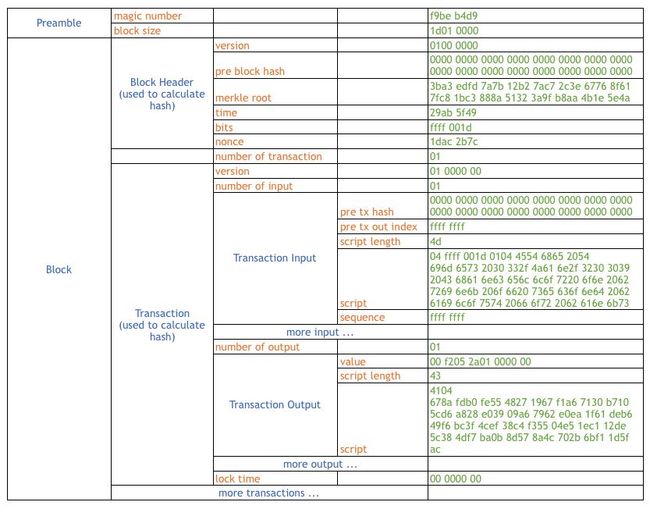
怎么样,现在是不是清楚多了?注意,我并有没把数据换成大端格式,请自行转换。
计算额外字段
细心的同学可能已经注意到了,这些数据中不包括几个非常重要的字段,Block Hash,Block Height,Transaction Hash 以及 Addresses。不错,中本聪在设计 Bitcoin 的时候可谓是极度的“抠门”,能通过计算得出的数据绝对不存在链上。从链的设计角度来看,这样做是绝对正确的,它能节省许多磁盘空间,但是这却给我们带来了额外的工作。下面我们分别谈谈各个字段的计算。
计算 Block Hash 以及 Transaction Hash
Block 和 Transaction 的 Hash 值都是由相同的算法得出的,不同点只是在于参与计算的数据不同。对于 Block Hash 来讲,我们的输入数据只是 80 字节的 Block Header,而对于 Transaction 来讲是整个 Transaction 的数据。Block Header 里面是包括 Merkle Root 的,所以在计算 Block Hash 的时候不需要整个 Block 最为输入。
Hash 值是由输入数据进行两次 sha-256 运算得出的,其形式如下:
hash = sha256(sha256(data))
我们分别将 Block Header 和整个 Transaction 带入上述公式便能得到相应的 Hash 值。
计算 Block Height
我们知道,Bitcoin 的原始数据是存储在 blkxxxxx.data 中的,每个 data 文件中都存放了许多个 Block。如果我们按顺序从第 0 字节开始读,把其中的所有 Block 都解析出来,我们会发现这些 Block 并不是完全有序的。换句话说你有可能先读出第 178 个 Block,然后才读出第 177 个 Block。至于为什么会这样,大家可以想想以前用 BT 下载的时候,那个进度条长什么样。
所以想要得到正确的 Block Height, 我们就必须对读出来的、无序的 Block 进行排序。了解 Blockchain 的同学应该知道,Blockchain 的数据结构是一个倒过来的单链表,我们可以通过 Block Hash 和 Previous Block Hash 来将这些 Block 重新串联起来。Genesis Block 的 Previous Block Hash 固定为全 0。这样一来我们也就可以得出 Block Height 了。
计算 Addresses
想要支持最开始的那种根据地址查询 Transaction 的功能,我们就必须求出每笔交易的发款人和收款人地址。这两个数据分别蕴含在 Transaction Input 和 Output 的script字段里面。求出地址的方法大致分为两步:
对于 Transaction Output,找出其中的 public key 或 public key hash,再根据一定的算法计算出地址。
对于 Transaction Input, 从其对应的 Previous Transaction Output 中取出地址,作为它的地址。
限于篇幅,我就不过多讨论第一点了。如果大家感兴趣,不妨告诉我们,我可以单独再用一期来讲解如何解析 Bitcoin Script。但是我想对第二点进行一些补充说明。虽然在 Transaction Input 里面你能拿到 public key,但是我不建议大家直接从 Transaction Input 里面计算地址。这是因为经过隔离见证之后,计算地址的方式发生了变化,直接从 Input 中解析地址很有可能得到一个与 Previous Transaction Output 不一样的地址。简单来说就是,你有可能以张三的名义收了一笔钱,却用李四的名义花掉了这笔钱。张三李四本来是同一个人,但是因为这个错误,计算账户余额的时候就会出现余额为负数的情况。
结语
经过上述的所有步骤,我们就完成了 OCAP 数据预处理的第一步 – 解析数据。之后我们还需要重新演绎 Bitcoin 的历史来获取整个 UTXO Pool 以及对每个地址做一些统计,如它们进行的所有交易数量和它们的余额等。
最后我想说,中本聪作为 Blockchain 之父,在设计 Bitcoin 的时候有许多奇思妙想,他对那些细节的把控真是让人叹为观止。在这个项目中,我也是一边学一边做,而且学到的东西真不是三言两语能说完。如果各位有时间,不妨写一些代码试着解析一下原始数据,这对彻底理解 Bitcoin 有很大的帮助。