未经允许,不得转载,谢谢~~
《Deformable Convolutional Networks》是微软亚洲研究院发在ICCV2017上的论文。
原文链接: Deformable Convolutional Networks
这是一篇我琢磨了很久才看懂的论文,也是每看一次都觉得idea很惊艳的一篇论文。
那主要从以下几个问题进行介绍吧:
- 为什么要提出可变的神经网络?
- 论文的主要贡献在哪里?
- 可变卷积层是怎么样实现的?
为什么要提出可变的神经网络?
怎么样在计算机视觉识别上更好的适应物体在大小,姿态,角度上的几何变换?
通俗地说就是一个物体比如杯子,由于拍摄的远近,视角等因素最后呈现的样子在大小,角度上都会有差别,那怎么样更好的在这些差别存在的情况下识别这个杯子呢?
一般来说,有2种方法可以解决这个问题:
- 用充分多的变种构建训练数据库;
还是以杯子为例,即采集不同大小,姿势的杯子作为训练数据。 - 用变换不变特征;
例如尺度不变特征转换的SIFT就属于这一类方法。
这两种方法都具有一些共同的局限性:
- 都假定几何变换是固定的且可以预知的,对于新出现的任务处理效果不好;
- 手动去采集或者设计不同的特征非常的困难。
广泛应用于深度学习的CNN网络也由于其卷积核是固定的形状,所以很难处理这种变换的情况。
以上就是现有方法对于解决几何变换问题的不足,哪里有需求,哪里就会有创新,这也正是该论文的闪光之处。
论文的主要贡献在哪里?
论文提出了两种用于提高CNN应对几何变换的建模能力:
- deformable convolution;
- deformable ROI pooling;
- 第一次发现在深度网络总学习稠密的空间变化对复杂的任务有帮助。
两个方法都是基于用额外的偏置来增强空间采样位置的想法,其基本原理都是类似的,因此本文只讲解可变卷积的实现,具体的可以详细去看论文。
可变卷积层是怎么样实现的?
核心思想
以2D卷积,3×3的卷积核为例,先上图:
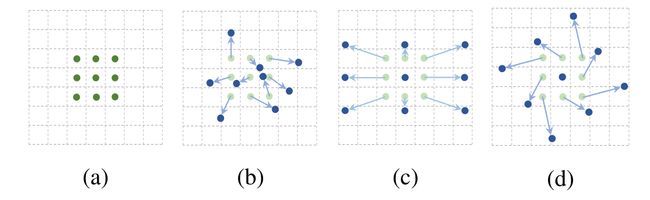
- 图(a)是我们最熟悉的标准卷积网络。
- 图(b)是变换之后的卷积采样点分布,轻绿色的表示原来的采样点,蓝色的表示变换后的采样点。
- 图(c)是图(b)的一种特例:采样尺寸放大的情况。
- 图(d)是图(b)的一种特例:采样尺寸放大+旋转的情况。
普通2D卷积的实质其实是用卷积核在输入特征上滑动,各个采样点乘上模板的权重之和得到一个新的值。
以图(a)为例,最中间的绿色点卷积后的值就等于9个采样点对应的x值乘上对应卷积核的权重之和。
这里注意一个思维的转换:采样点指的是原输入特征上对应点,权重指的是卷积核对应的值。
用数学方法来表示:
以坐标化的方式来表示接受域:
那么原输入特征中的点P0卷积后的值就等于:

其实就是就是采样点的值×卷积核权重之和。
那么可变卷积的实现是不是只需要改变采样点的位置即可。而这个改变就可以根据给每一个采样点+一个偏置deta-p(x方向的偏置,y方向的偏置)得到,偏置具体值仍然是通过神经网络学习的。。
以图b为例,每个轻绿色的点表示原来常规卷积下的采样点,现在每一个点都移到了新的位置(蓝色处),而且每个点的移动方向和长度都可以是不一样的。
这里先不管是偏置怎么样得到的,假设我们已经知道每个采样点对应的偏置值。那么点P0卷积之后的值就等于:

这样呢就完成了可变卷积的的部分,也就是我们看到的图(b)。
图(c)和图(d)都是图(b)的特殊情况。
图(c)中的采样区域变大了,很自然的可以想到这对于物体尺寸变化的处理效果是会比较好的,能比较完整地抽象到物体的特征。
图(d)也是同样的道理,可以很好的理解这种变换后的接受域对于物体尺寸变化+旋转之后的特征学习是有益的。
细节补充
由于学到的偏置一般都很小,新的坐标并不能落在整数的坐标点上,所以需要用到双线性插值来实现。
这里简单介绍一下是什么意思,对于我们的新采样点p_new, 大概率不会刚好落在整数的坐标点上,但它一定能找到与它最近的4个点,并且落在这4个点的内部。
那么就利用这四个点进行双线性插值即可,在scipy的包中提供了这个函数:
from scipy.ndimage.interpolation import map_coordinates
我们来看一下运行效果就知道了
import numpy as np
from scipy.ndimage.interpolation import map_coordinates as sp_map_coordinates
input=np.arange(12,dtype=float).reshape(3,4)
print input
coords=[[0.5,1.5,1.8],[0.5,1.2,2.0]]
output_array=sp_map_coordinates(input,coords,order=1)
print output_array
运行结果如下所示:

如上图,input为输入的数组,order=1 表示为线性插值。
coords里面存的是列表,为(npoints,2)大小的,左边的数组代表要插入的x坐标,右边的数组表示要插入的y坐标。即在此处要在原来的inputs中插入三个点,这是三个点的坐标分别为(0.5,0.5) (1.5,1.2) (1.8,2.0),以(0.5,0.5)为例,下标落在(0,0) , (0,1), (1,0), (1,1)这四个点之间,即要在在值0,1,4,5之间差值,所以这里用了双线性插值,最后得到的值为2.5
具体实现
这里论文中让我很惊艳的一点是:
上面的图1我们看到的好像是对卷积核的坐标做了偏置。
但其实还是上文提到的思维转换的问题:可变卷积是由改变采样点的位置决定的,而采样点是对于输入特征而言的。更宏观一点来看,它是对采样点对了偏置,就是对输入feature的每个位置学习一个offset。
这里给出论文中的结构图:

这里的offset filed就是通过卷积层conv学到的偏置。
因为输入特征input feature map 上的每个点都需要一个偏置offset(x上的偏置,y上的偏置), 所以得到的offest field的平面大小的input feature map是一样的,但深度方向是input feature map的2倍(x,y两个方向的偏置)。
这样就得到每个点p的偏置窗口了,也就是得到了上文图1中的图(b)。
得到偏置窗口之后就可以用上文中的方式去得到最后的output feature map了。
写在最后
文中图片来自原文: Deformable Convolutional Networks
这真的是一篇创新点新奇的文章,超级推荐阅读。
有理解不到位的地方欢迎简信交流~~
转载记得注明出处,感激不尽。