大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop、Storm,还是后来的Spark、Flink。然而,毕竟没有哪一个框架可以完全支持所有的应用场景,也就说明不可能有任何一个框架可以完全取代另一个。今天,大圣众包威客平台(www.dashengzb.cn)将从几个项出发着重对比Spark与Flink这两个大数据处理引擎,探讨其两者的区别。

一、Spark与Flink几个主要项目的对比与分析
1.性能对比
测试环境:
CPU:7000个
内存:单机128GB
版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
数据:800MB,8GB,8TB
算法:K-means:以空间中K个点为中心进行聚类,对最靠近它们的对象归类,通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果
迭代:K=10,3组数据

相同点:Spark与Flink都运行在Hadoop YARN上,两者都拥有非常好的计算性能,因为两者都可以基于内存计算框架以进行实时计算。
相异点:结合上图三者的迭代次数(纵坐标是秒,横坐标是次数)图表观察,可得出在性能上,呈现Flink > Spark > Hadoop(MR)的结果,且迭代次数越多越明显。Flink之所以优于Spark和Hadoop,最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
结果:Flink胜。
2.流式计算比较
相同点:Spark与Flink都支持流式计算。
相异点:Spark是基于数据片集合(RDD)进行小批量处理的,它只能支持秒级计算,所以Spark在流式处理方面,不可避免会增加一些延时。Flink是一行一行的,它的流式计算跟Storm的性能差不多,是支持毫秒级计算的。
结果:Flink胜。
3.与Hadoop兼容性对比
相同点:Spark与Flink的数据存取都支持HDFS、HBase等数据源,而且,它们的计算资源调度都支持YARN的方式。
相异点:Spark不支持TableMapper和TableReducer这些方法。Flink对Hadoop有着更好的兼容,如可以支持原生HBase的TableMapper和TableReducer,唯一不足是新版本的MapReduce方法无法得到支持,现在只支持老版本的MapReduce方法。
结果:Flink胜。
4.SQL支持对比
相同点:两者都支持SQL。
相异点:从范围上说,Spark对SQL的支持比Flink的要大一些,而且Spark支持对SQL的优化(包括代码生成和快速Join操作),还要提供对SQL语句的扩展和更好地集成。Flink主要支持对API级的优化。
结果:Spark胜。
5.计算迭代对比
相同点:如下图所示,Hadoop(MR)、Spark和Flink均能迭代。
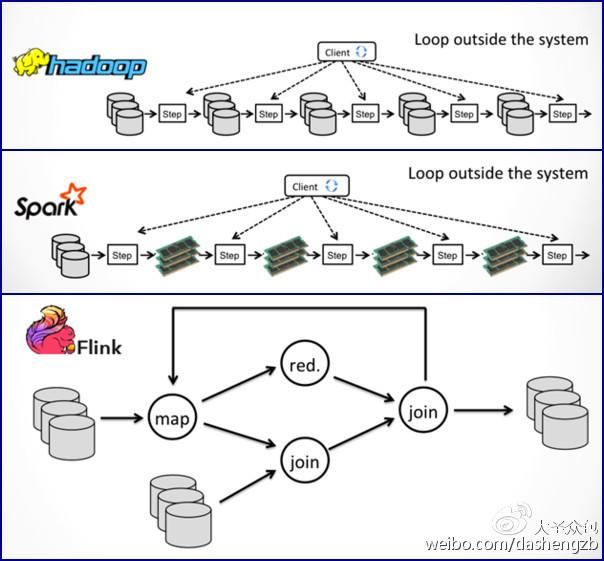
相异点:Flink特有delta-iterations,这让它能够在迭代中显著减少计算。并且Flink具有自动优化迭代程序功能,具体流程如下图所示。
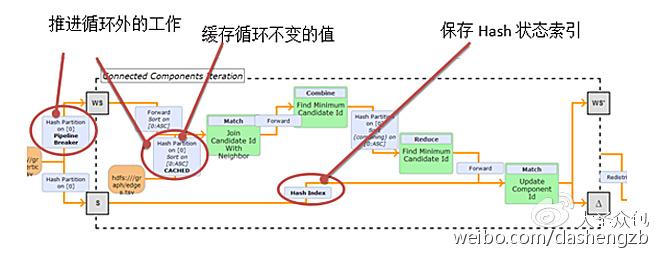
结果:Flink胜。
6.社区支持对比
相同点:Spark与Flink均有社区支持。
相异点:Spark社区活跃度比Flink高很多。
结果:Spark胜。
二、Spark与Flink的特点剖析
1.Spark 1.4的6大特点
众所周知,提出最主要抽象概念——弹性分布式数据集(RDD)的是Spark。RDD是一个元素集合,将其划分到集群的各个节点上可以被并行操作。当然,用户也可以让Spark保留一个RDD在内存里,让其能在并行操作中被有效地重复使用。Spark是实至名归的快速、通用的计算集群系统。结合下图Spark架构图与生态系统图,可以看出Spark 1.4的6大特点:
①Spark SQL(DataFrame)添加了ORCFile类型支持以及所有的Hive metastore支持;
②增加了UI的Spark Streaming,使得用户查看各种状态更加地便捷,随着和Kafka融合的加深,对Kinesis的支持也加强了很多;
③Spark之所以提供了更多的算法和工具,是因为Spark ML/MLlib的ML pipelines越来越成熟;
④使用了REST API,Spark可以为应用获取如jobs、stages、storage info、tasks等各种信息;
⑤内存管理、代码生成、垃圾回收等方面都有很多改进,这些都得益于Tungsten项目的持续优化;
⑥SparkR的发布让Spark得到更友好的R语法的支持。
2.Flink 0.9的7大特点
作为可扩展的批处理和流式数据处理的数据处理平台,Flink的设计思想主要来源于Hadoop、MPP数据库、流式计算系统等。支持增量迭代计算是Flink最大的特点,而且其对于迭代计算和流式计算的支持力度都将会加强。结合下图Flink架构图与生态系统图,可以看出Flink 0.9的7大特点:
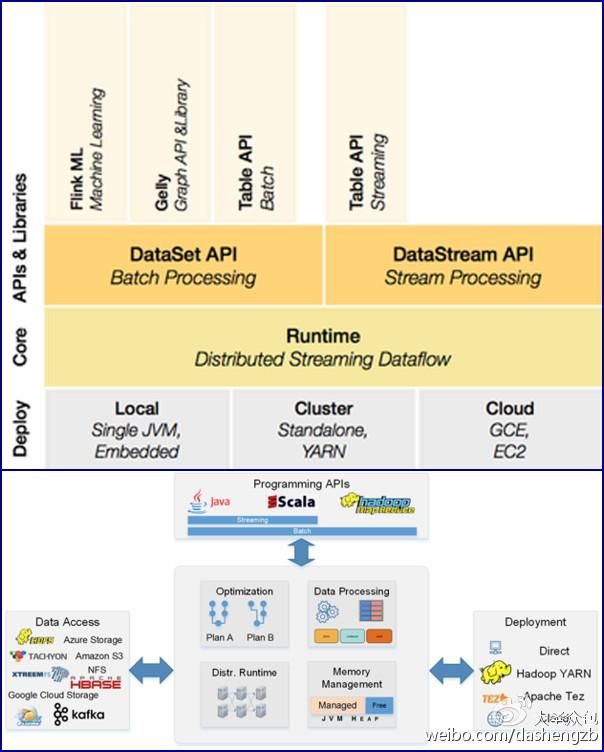
①搭载DataSet API,让Flink支持Java、Python和Scala等多种编程语言;
②同样地,搭载DataStream API,让Flink支持Java和Scala;
③Flink ML和Gelly提供机器学习和图处理的多种库;
④Table API能够支持类SQL;
⑤Flink能够支持高效序列化、反序列化;
⑥Flink和Hadoop相互兼容;
⑦Flink拥有自动优化迭代的功能。
放眼未来,无论是Spark还是Flink,两者的发展重点都将是数据科学和平台API化,使其生态系统越来越完善。亦或许,会有更新的大数据处理引擎出现,谁知道呢。
原文地址:http://www.dashengzb.cn/articles/a-330.html
(更多大数据与商业智能领域干货、或电子书,可添加个人微信号(dashenghuaer))