体系结构与内核分析续
deque&queue 和 stack 深度探索
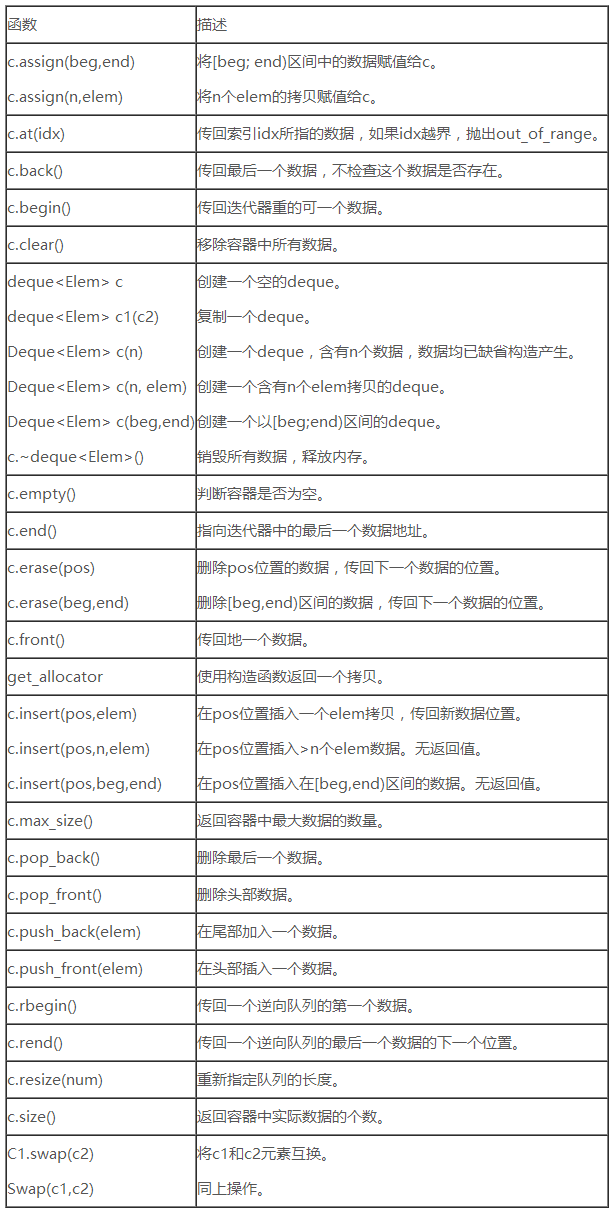
deque双向队列是一种双向开口的连续线性空间,可以高效的在头尾两端插入和删除元素,deque在接口上和vector非常相似。(连续是假象,分段是事实)
deque的内存空间分布是小片的连续,小片间用链表相连,实际上内部有一个map的指针。其中buffer表示deque的缓冲区,每个buffer可以存放多个元素结点。并且每个buffer指针存放在vector容器中。每个iterator存放四个指针:cur、first、last、node,cur表示当前数据结点的指针,first表示buffer首指针,last表示buffer的尾指针,node表示这个iterator在vector中的指针地址。所有容器都有两个iterator分别指向头和尾begin& finish。
deque用法:http://blog.csdn.net/hnust_xiehonghao/article/details/8800007
源代码示例:deque::insert()
//在position处安插一个元素,其值为x
iterator insert(iterator position,const value_type& x){
if(position.cur == start.cur){ //如果安插点是deque最前端
push_front(x); //交给push——front()做
return start;
}
else if (position.cur == finish.cur) { //如果安插点是deque最尾端
push_back(x); //交给push——back()做
iterator tmp =finish;
--tmp;
return tmp;
}
else {
return insert_aux(position,x);
}
}
template
typename deque::iterator
deque::insert_aux(iterator pos,const value_type& x){
difference_type index = pos - start; //安插点之前的元素个数
value_type x_copy =x;
if (index
push_front(front()); //在最前端加入与第一元素同值的元素
...
copy(front2,pos1,front1); //元素搬移
}
else{ //安插点之后的元素个数较少
push_back(back()); //在尾端加入与最末元素同值的元素
...
copy_backward(pos,back2,back1); //元素搬移
}
*pos = x_copy; //在安插点上设定新值
return pos;
}
deque是如何模拟连续空间:源代码做了大量的操作符重载,尤其是遇到buffer边界时如何跳到控制中心,使得deque的iterator能够在buffer之间模拟出连续空间。iterator的功劳特别是大量的操作符重载。
实现源代码如下:
reference operator[] (size_type n)
{
return start[difference_type(n)];
}
reference front(){return *start;}
reference back()
{
iterator tmp = finish;
--tmp;
return *tmp;
}
size_type size() const {return finish - start;}
bool empty() const {return == start;}
reference operator*() const {return *cur;}
pointer operator->() const {return & (operator*());}
queue(先进先出)和stack(先进后出):内含一个deque封掉某些功能。
stack和queue都不允许遍历,也不提供iterator。
stack和queue都可选择list和deque作为底层容器。
queue不可选择vector作为底层结构,stack可选择vector作为底层结构。
stack和queue都不可选择set或map做底层结构。
RB-tree深度探索
Red-Black tree(红黑树)是平衡二元搜寻树(balanced binary search tree)中常被使用的一种。平衡二元搜寻树的特征:排列规则有利于search和insert,并保持适度平衡,即无任何节点过深。
红黑树的性质如下:
1) 每一个节点或者着红色,或者着成黑色.
2) 根是黑色的
3) 如果一个节点是红色的,那么它的子节点必须是黑色的.
4) 从一个节点到一个NULL指针的每一条路径必须包含相同数目的黑色节点.
re_tree提供“遍历”操作及iterators。按正常规则(++ite)遍历,便能获得排序状态(sorted)。我们不应使用rb_tree的iterators改变元素值(因为元素有其严谨排列规则)。编程并未阻止此事。如此设计是正确的,因为rb_tree即将为set和map服务(作为其底部支持),而map允许元素的data被改变,只有元素的key才是不可被改变的。key和data一起才为value。rb_tree提供两种insertion操作:insert_unique()和insert_equal( )。前者表示节点的key一定在整个tree中独一无二,否则安插失败;后者表示节点的key可重复。
RB-tree的用法:
begin()函数获取最左(最小)的节点处,end()获取的是根结点(由于使用了一个实现上的技巧,其实并不是真的根结点);
empty()判断是否为空, size(), max_size()最大数据的数量,count();
insert_unique(const value_type& x)将x插入RB-tree中,保持节点值独一无二;
insert_equal(const value_type& x)将x插入RB-tree中,允许节点值重复。
关联式容器
set/multiset(set中key不可重复,multiset可以|后面map相同) (key就是vault)二分树(高度平衡)map/multimap(有key和vault)(所有元素都会根据元素的键值自动被排序)在STL中关联容器使用红黑树来实现,因为不是顺序结构,因而不能使用上面提到的push和pop函数,使用insert和erase函数来实现元素的插入删除操作。关联容器支持通过键来高效地查找和读取元素,两个基本的关联容器类型是map和set。map的元素以键-值(key-value)对的形式组织:键用于元素在map中的索引,而值则表示所存储和读取的数据。set仅包含一个键,并有效地支持关于某个键是否存在的查询。map可理解为字典,set可理解为一类元素的集合。关联容器和顺序容器的本质差别在于:关联容器通过键(key)存储和读取元素,而顺序容器则通过元素在容器中的位置顺序存储和访问元素。set 和 map 类型的对象所包含的元素都具有不同的键,不允许为同一个键添加第二个元素。如果一个键必须对应多个实例,则需使用 multimap 或 multi set,这两种类型允许多个元素拥有相同的键。
set/multiset深度探索
set/multiset以rb_tree为底层结构(内含一个tree),因此有元素自动排序特性。排序的依据是key,而set/multiset元素的value和key合一:value就是key。
set/multiset提供“遍历”操作及iterators。按正常规则(++ite)遍历,便能获得排序状态(sorted)。
我们无法使用set/multiset的iterators改变元素值(因为key有其严谨排列规则)。set/multiset的iterator是其底部的RB tree的const-iterator,就是为了禁止user对元素赋值。
set元素的key必须独一无二,因此其insert()用的是rb_tree的insert_unique()。multiset元素的key可以重复,因此其insert()用的rb_tree的insert_equal()。
map/multimap深度探索
map/multimap以rb_tree为底层结构,因此有元素自动排序特性。排序的依据是key。
map/multimap提供“遍历”操作及iterators。按正常规则(++ite)遍历,便能获得排序状态(sorted)。我们无法使用map/multimap的iterators改变元素的key(因为key有其严谨排列顺序),但可以用它来改变元素的data。因此map/multimap内部自动将user指定的key type设为const,如此便能禁止user对元素的key赋值。(内含tree限制某些功能)
map元素的key必须独一无二,因此其insert()用的是rb_tree的insert_unique()。multimap元素的key可以重复,因此其insert()用的是rb_tree的insert_equal()。
hashtable深度探索
Hashtable是非泛型的集合,所以在检索和存储值类型时通常会发生装箱与拆箱的操作。
当把某个元素添加到 Hashtable 时,将根据键的哈希代码将该元素放入存储桶中,由于是散列算法所以会出现一个哈希函数能够为两个不同的键生成相同的哈希代码,该键的后续查找将使用键的哈希代码只在一个特定存储桶中搜索,这将大大减少为查找一个元素所需的键比较的次数。
Hashtable 的加载因子确定元素与Hashtable 可拥有的元素数的最大比率。加载因子越小,平均查找速度越快,但消耗的内存也增加。默认的加载因子 0.72通常提供速度和大小之间的最佳平衡。当创建 Hashtable 时,也可以指定其他加载因子。(元素总量/ Hashtable 可拥有的元素数=加载因子 )当向 Hashtable 添加元素时,Hashtable 的实际加载因子将增加。当实际加载因子达到指定的加载因子时,Hashtable 中存储桶的数目自动增加到大于当前 Hashtable 存储桶数两倍的最小素数。(Hashtable适用于读取操作频繁,写入操作很少的操作类型)
当碰撞的元素超过“篮子”的个数,经验判断为危险,则将“篮子”的数量扩大为原来的两倍,一般篮子数量是素数。GUC初始篮子数量为53,两倍变成106,附近的素数而且比106大的为193。可以使用hashtable iterators改变元素的data,但不能改变元素的key(因为hashtable根据key实现严谨的元素排列)。
hashtable源代码:
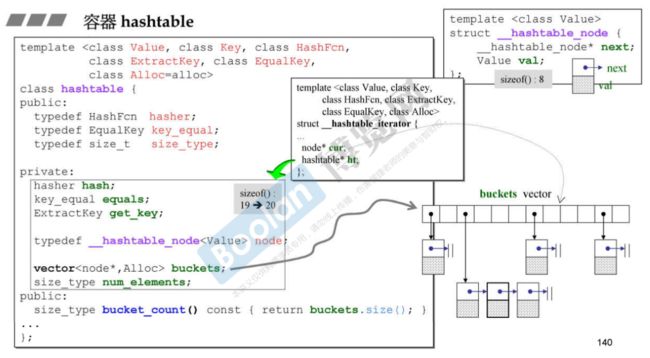
template六个模板参数:value和key参数与红黑树为底层的set和map类似,第三个模板参数hashFcn(hash-function)的目的是希望根据元素值算出一个hash code(一个可进行modulus运算的值),使得元素hash code映射之后能够够杂乱够随机地被置于hashtable内,越是乱,越是不容易碰撞,可以传函数、仿函数、函数对象,它是通过模板偏特化实现,c风格的字符串char*是一个指针,stl提供了实现方式,而C++的字符串string则需要自己写实现方式;第四个ExtractKey告诉我们如何取出key;第五个EqualKey告诉我们如何比较key大小;第六个alloc为分配器。
hash_map和map的区别在哪里?
构造函数 hash_map需要hash函数,等于函数;map只需要比较函数(小于函数).
存储结构 hash_map采用hash表存储,map一般采用红黑树(RB Tree)实现。因此其memory数据结构是不一样的。
unordered容器概念
Before C++11
hash_set
hash_multiset
hash_map
hash_multimap
Since C++11
unordered_set
unordered_multiset
unordered_map
unordered_multimap
只是名称不同,用法不变