背景
不久前,我们处理了一个用户工单,该工单对应的 HQL 如下所示:

这个 HQL 看上去并不复杂,其目的不过是计算 column0 这个字段的几个近似分位点(percentile_approx),就一个 stage,应该会比较顺利地完成计算才对。不巧的是,其 MapReduce 任务在 reduce 阶段抛出如下异常:

顺着 stacktrace,我跟踪了一下 NumericHistogram(为了支持 percentile_approx,于 2010 年引入) 的实现。这个类的头部有一段注释,引发了我的好奇心,最终促成了 HIVE-15872 的修复。

为何 Hive 的 histogram 实现会跟「决策树」扯上关系?看上去有点意思。
技术实现
需要说明的是,percentile_approx 得到的是近似值,不同的系统或算法针对同一个 Query 很可能会得到不同的结果。Hive 和 Spark SQL 在这个问题上就有差异,两者无论具体实现还是设计思想都有所不同,后面会给出详细解释。
Hive
「Partial aggregation 」VS 「Combiners」
-
为什么要提前把这俩概念提出来?
对于大多数 MapReduce Job,整体性能的瓶颈往往出现在 shuffle 阶段的 I/O 上。为了减少 shuffle 阶段的 I/O,MapReduce 引入了 Combiner,其本质就是期望能够在 map 之后加一层 combine 聚合计算以减少 shuffle 到下游的数据规模。但是,Combiner 是有局限性的。一般来讲,CombinerClass 和 ReducerClass 都是同一个类。这要求 Combiner 或 Reducer 的具体实现方法满足「交换律」和「结合律」,类似 C(C(x3,x2), C(x1,x4)) <=> C(C(x1,x4), C(x2,x3)) 这样。常见的满足「交换律」和「结合律」的方法有 Max、Min、Count、Sum 等,而 histogram 或者 percentile 之类的聚合函数则不满足。Hive 为了让不同的 UDAF 在工程实现上保持一定的接口一致性,全部放弃使用 Combiner,转而使用 Partial aggregation。这也是 Hive 的源码里面没有一行代码调用了 JobConf#setCombinerClass 的原因。需要说明的是,Combiner 本质上是一种 「trade CPU for gains in IO」的做法,而 Partial aggregation 则是「trade Memory for IO gains by caching values (up to a threshold)」。
-
Partial aggregation 到底是怎么一回事?
严格讲,Partial aggregation 不同于 Combiner,并不是 MapReduce 层面的概念,它只是应用层面的一种优化策略。Hive 有做这样的优化,另外一个叫做 Cascading 的 BigData 项目也有做类似的工作,我们这里只说下 Hive 的实现。Hive 里面存在一个叫做 GroupByOperator 的算子,它既可以工作在 ExecMapper,也可以工作在 ExecReducer,其内部存在一个 hashAggregations 的 HashMap(前面提到过这是一种牺牲内存而得到 IO 收益的做法):
// Used by hash-based GroupBy: Mode = HASH, PARTIALS private transient HashMap简言之,如果 Hive 需要做一个 UDAF 的计算,那么 ExecMapper 是需要在生成
-
Partial aggregation 对分布式 histogram 有何意义?
后面介绍了 Hive 的 histogram 实现之后自然会明白。
histogram
在讨论 Hive 的 percentile_approx 实现之前,我们先看看 A Streaming Parallel Decision Tree Algorithm(发表于 2010 年)这篇论文到底要解决什么问题或者提出哪种算法给了 Hive 一些启发思想。其中论文摘要如下:
We propose a new algorithm for building decision tree classifiers. The algorithm is executed in a distributed environment and is especially designed for classifying large data sets and streaming data. It is empirically shown to be as accurate as a standard decision tree classifier, while being scalable for processing of streaming data on multiple processors. These findings are supported by a rigorous analysis of the algorithm’s accuracy.
The essence of the algorithm is to quickly construct histograms at the processors, which compress the data to a fixed amount of memory. A master processor uses this information to find near-optimal split points to terminal tree nodes. Our analysis shows that guarantees on the local accuracy of split points imply guarantees on the overall tree accuracy.
这篇论文对 Hive 最大的启发就是提出了一种 On-line Histogram Building 算法。什么是 histogram?定义如下:
A histogram is a set of B pairs (called bins) of real numbers {(p1,m1),...,(pB,mB)}, where B is a preset constant integer.
这里的 pair,Hive 用了一个叫做 Coord 的 Class 来表示:

在 histogram 的定义里面,有一个用于标识 bins 数量的常量 B。为何一定要引入这个常量?假设我们有一个简单的 sample 数据集(元素可重复):
[1, 1, 1, 2, 2, 2, 3, 4, 4, 5, 6, 7, 8, 9, 9, 10, 10]
简单心算一下就可以得到其 histogram 为:[(1, 3), (2, 3), (3, 1), (4, 2), (5, 1), (6, 1), (7, 1), (8, 1), (9, 2), (10, 2)]。可以看出,这个 histogram 内部的 bins(数据点和频率一起构成的 pair) 数组长度实质上就是 sample 数据集的基数(不同元素的个数)。histogram 的存储开销会随着 sample 数据集的基数线性增长,这意味着如果不做额外的优化,histogram 将无法适应超大规模数据集合的统计需求。常量 B 就是在这种背景下引入的,其目的在于控制 histogram 的 bins 数组长度(内存开销)。histogram 提供了四个基本的方法:update、merge、sum 和 uniform,为了简化问题,这里只介绍 update 和 merge。
-
update
update 的作用是将一个 point(数据元素)添加到 histogram,同时会保证整个 histogram 的 bins 数组长度不超过常量 B。
 image
image「步骤 7」的替换方法,应该是整个算法的关健点,感兴趣的同学可以想想这个替换公式是如何得来的。无论是为了控制 bins 数组长度,还是为了得到 percentile 的近似值,没有「步骤 7」的替换,都不可能完成。所谓 approximate,其实就是这里的 replace 引入的。 Hive 在工程实现上,对 update 的操作总是假设已经存在的 bins 数组已经有序(sort by bin.x asc),通过二分查找得到插入点。这个查找的结果可能会精确命中已经存在的 bin,也可能不会。前者只需要简单做下 increment 即可,后者则需要加入一个 trim 过程(也就是上面的「步骤 7」)。update(Hive 里面的方法名叫 add) 的具体实现如下:

-
merge
merge 和 update 差别不大,只不过它是将两个 histogram 做合并,方法类似。
 image
image这里仍然少不了 update 算法里面用到的「replace」,Hive 对应的代码实现如下:

从代码的实现来看,other 这个 List(结构为 [nbins, bin0.x, bin0.y, bin1.x, bin1.y, ..., binB.x, binB.y]),其长度必须是奇数。但是,我们前面提到的那个工单,它的错误日志里面拿到的这个 other 的长度为 2(偶数)且数据内容非常奇怪([0.0, 10000.0],nbins 怎么可能是 0?),后面会分析产生这个奇怪数组的原因。
percentile_approx
对 histogram 来说,percentileapprox 算是它的一个应用 case(histogram 不仅仅可以用来计算 percentile)。Hive 的 percentileapprox 由 GenericUDAFPercentileApprox 实现,其核心实现是在 histogram 的 bins 数组前面加上一个用于标识分位点的序列。以上面的 HQL 为例,percentile_approx 的 partial aggregations 序列化之后的结果如下:
// [分位点个数,分位点1,分位点2,分位点3,分位点4,分位点5,bins 数组长度上限 B,bin0.x, bin0.y, bin1.x, bin1.y, ..., binK.x, binK.y],bins 的默认长度上限是 10000
[5, 0.50, 0.70, 0.90, 0.95, 0.99, 10000, x0, y0, x1, y1, ..., xK, yK]
理解了上面这个结构,也就不难理解为何 Hive 的 PercentileAggBuf 会有如下源码:

同 histogram 相对应,percentileapprox 也有一个 merge 过程(基本思想仍然是 Partial aggregation)。这个 merge 最主要的操作仍然是 PercentileAggBuf#histogram 层面的 merge,而前面的 quantiles 数组在 merge 过程中并没有什么用途,主要用在最终依据分位点获取相关结果上。percentileapprox 在做 merge 时,需要将上面那个数组最前面的 quantiles 子序列删除,仅保留 histogram 序列(长度为奇数)。
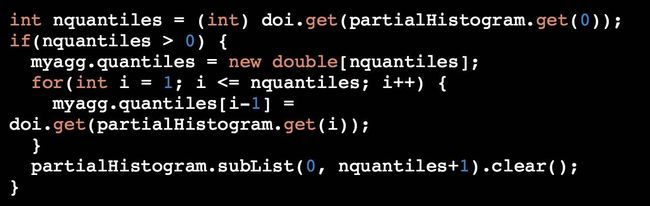
前面那个工单提到的 bug,实际上就是这一步的 clear 操作仅仅针对 nquantiles 大于 0 的情况作了考虑,而针对 nquantiles 为 0 的情况则是完全忽略(这份代码存在了 6 年)。从前面的 HQL 可以知道,我们传入的 quantiles 数组是 array(0.50, 0.70, 0.90, 0.95, 0.99),其长度为 5,nquantiles 本不应该为 0 的。那这个 0 是从哪来的?最后追查代码发现,如果一个 Query 的在 map 阶段经过 filter 之后得到的数据为 NULL,那么在这个 NULL 数据集上做 percentileapprox 时,map 端的 GroupByOperator 所做的事情只会对 PercentileAggBuf 填充 [0(分位点个数), 10000(histogram 的 bins 数组默认最大长度)]。这才导致了 stacktrace 里面那行导致 IndexOutOfBoundsException 的奇怪 value:{"col0":[0.0,10000.0]}。追到这里,Hive 的这个隐藏 bug 算是被定位清楚了,之后的提交 patch 并被 commit 就水到渠成了。验证这个 bug 的数据可以通过以下 HQL 得到(查询结果是 NULL):

bug 修复了,那么 percentile_approx 是如何从 histogram 里面计算出来的呢?histogram 相关代码实现如下:

Spark SQL
讨论完了 Hive 的 percentile_ approx,我们再来看看 Spark SQL 是如何实现的。Spark SQL 和 Hive 使用了完全不一样的算法,甚至连参考的论文都差了近十年。Spark SQL 的 percentile_approx 是在 SPARK-16283 得到实现和支持的,其参考的论文 Space-Efficient Online Computation of Quantile Summaries 发表于 2001 年。由于篇幅有限加上 Spark SQL 这一块并没有发现 bug,所以不做过多介绍。感兴趣的同学可以翻看论文和源码。