【领域文章来源】:
通过百度查找余光中的《寻李白》,复制粘贴内容,在本地自己创建txt文件。
【程序编写基本思路】:
通过jieba库和wordcloud库制作词云图片。调用目标txt内容,通过jieba的分词功能来产生词组;再用wordcloud库展示词云。
【源代码】:
import jieba from wordcloud import WordCloud excludes={'高力士','靴子','而今','太太','你','我','自从','那年'} f=open('寻李白.txt','r',encoding='utf-8') txt=f.read() f.close() words=jieba.lcut(txt) newtxt=''.join(words) wordcloud=WordCloud(background_color="white",\ width=900,\ height=600,\ font_path='msyh.ttc',\ stopwords=excludes,\ ).generate(newtxt) wordcloud.to_file("寻李白.png")
【词云效果】:

【遇到问题及解决方法】:
在最开始的时候其实我是用一首英文歌的歌词试试水,整体还都很顺畅,但是最终词云效果出来之后感觉不太美观。于是就想制作一个中文词云试试,然后.......问题就出现了。
代码1.0:
import jieba from wordcloud import WordCloud excludes={'高力士','靴子','而今','太太','你','我','自从','那年'} f=open('寻李白.txt','r') txt=f.read() f.close() words=jieba.lcut(txt) newtxt=''.join(words) wordcloud=WordCloud(background_color="white",\ width=900,\ height=600,\ stopwords=excludes,\ ).generate(newtxt) wordcloud.to_file("寻李白.png")
运行!然后发现出现了不能解码的问题......

我就去网上搜了一圈,参考CSDN博客,txt文档是gbk编码而Python不能识别,需要通过encoding=‘utf-8’转换一下。
【这里虽然输出问题解决了,但是对于英文内容就可以直接生成词云,中文内容就需要增加这一行代码的原因我其实还是不是特别明白......如果有了解的同学,希望能够留言解答,非常感谢了。】
开心地修改代码:
import jieba from wordcloud import WordCloud excludes={'高力士','靴子','而今','太太','你','我','自从','那年'} f=open('寻李白.txt','r',encoding='utf-8') txt=f.read() f.close() words=jieba.lcut(txt) newtxt=''.join(words) wordcloud=WordCloud(background_color="white",\ width=900,\ height=600,\ stopwords=excludes,\ ).generate(newtxt) wordcloud.to_file("寻李白.png")
运行!然后......
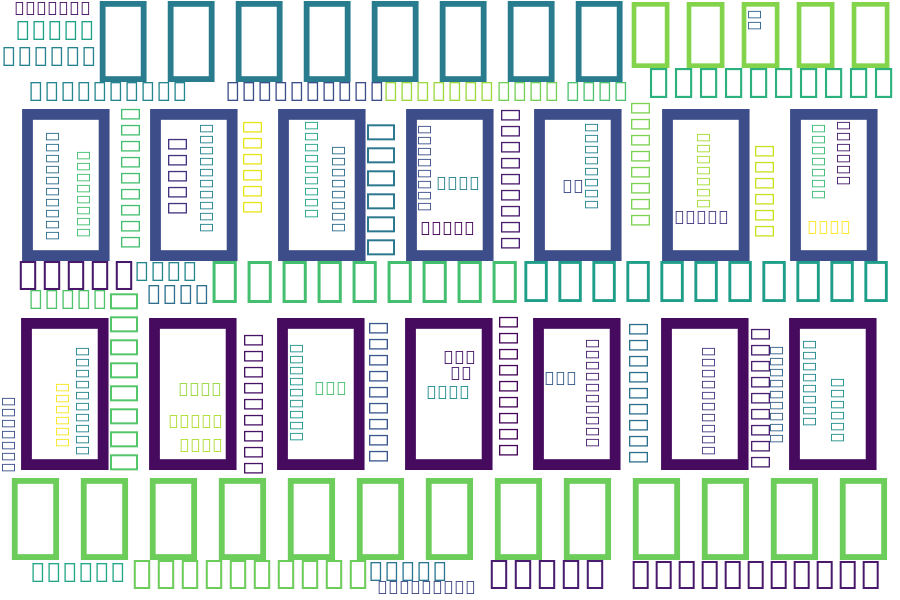
?????????
翻开二级教程书看一看发现写着这么一句话:“处理中文时还需要指定中文字体”
也就是说需要在最后WordCloud()中加入参数:font_path='xxx.ttc',其中xxx表示某字体。
修改之后就是上面源代码部分的代码了。
本人水平有限,难免会有错误的地方,还请多批评指正!