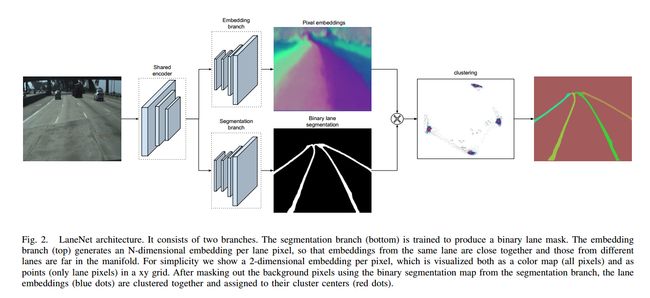
LaneNet
- LanNet
- Segmentation branch 完成语义分割,即判断出像素属于车道or背景
- Embedding branch 完成像素的向量表示,用于后续聚类,以完成实例分割
- H-Net
Segmentation branch
解决样本分布不均衡
车道线像素远小于背景像素.loss函数的设计对不同像素赋给不同权重,降低背景权重.
该分支的输出为(w,h,2).
Embedding branch
loss的设计思路为使得属于同一条车道线的像素距离尽量小,属于不同车道线的像素距离尽可能大.即Discriminative loss.
该分支的输出为(w,h,n).n为表示像素的向量的维度.
实例分割
在Segmentation branch完成语义分割,Embedding branch完成像素的向量表示后,做聚类,完成实例分割.
H-net
透视变换
to do
车道线拟合
LaneNet的输出是每条车道线的像素集合,还需要根据这些像素点回归出一条车道线。传统的做法是将图片投影到鸟瞰图中,然后使用二次或三次多项式进行拟合。在这种方法中,转换矩阵H只被计算一次,所有的图片使用的是相同的转换矩阵,这会导致坡度变化下的误差。
为了解决这个问题,论文训练了一个可以预测变换矩阵H的神经网络HNet,网络的输入是图片,输出是转置矩阵H。之前移植过Opencv逆透视变换矩阵的源码,里面转换矩阵需要8个参数,这儿只给了6个参数的自由度,一开始有些疑惑,后来仔细阅读paper,发现作者已经给出了解释,是为了对转换矩阵在水平方向上的变换进行约束。
代码分析
binary_seg_image, instance_seg_image = sess.run(
[binary_seg_ret, instance_seg_ret],
feed_dict={input_tensor: [image]}
)
输入(1,256,512,3) 输出binary_seg_image:(1, 256, 512) instance_seg_image:(1, 256, 512, 4)
完成像素级别的分类和向量表示
class LaneNet的inference分为两步.
第一步提取分割的特征,包括了用于语义分割的特征和用以实例分割的特征.
class LaneNet(cnn_basenet.CNNBaseModel):
def inference(self, input_tensor, name):
"""
:param input_tensor:
:param name:
:return:
"""
with tf.variable_scope(name_or_scope=name, reuse=self._reuse):
# first extract image features
extract_feats_result = self._frontend.build_model(
input_tensor=input_tensor,
name='{:s}_frontend'.format(self._net_flag),
reuse=self._reuse
)
#得到一个字典,包含了用于语义分割的feature map和用于实例分割的feature map.
#binary_segment_logits (1,256,512,2) 2是类别数目.即车道/背景.
#instance_segment_logits (1,256,512,64) 用以后面再做卷积为每个像素生成一个向量表示
print('features:',extract_feats_result)
# second apply backend process
binary_seg_prediction, instance_seg_prediction = self._backend.inference(
binary_seg_logits=extract_feats_result['binary_segment_logits']['data'],
instance_seg_logits=extract_feats_result['instance_segment_logits']['data'],
name='{:s}_backend'.format(self._net_flag),
reuse=self._reuse
)
if not self._reuse:
self._reuse = True
return binary_seg_prediction, instance_seg_prediction
第一步得到的features如下:
features : OrderedDict([('encode_stage_1_share', {'data': , 'shape': [1, 256, 512, 64]}), ('encode_stage_2_share', {'data': , 'shape': [1, 128, 256, 128]}), ('encode_stage_3_share', {'data': , 'shape': [1, 64, 128, 256]}), ('encode_stage_4_share', {'data': , 'shape': [1, 32, 64, 512]}), ('encode_stage_5_binary', {'data': , 'shape': [1, 16, 32, 512]}), ('encode_stage_5_instance', {'data': , 'shape': [1, 16, 32, 512]}), ('binary_segment_logits', {'data': , 'shape': [1, 256, 512, 2]}), ('instance_segment_logits', {'data': , 'shape': [1, 256, 512, 64]})])
特征提取完毕,做后处理
class LaneNetBackEnd(cnn_basenet.CNNBaseModel):
def inference(self, binary_seg_logits, instance_seg_logits, name, reuse):
"""
:param binary_seg_logits:
:param instance_seg_logits:
:param name:
:param reuse:
:return:
"""
with tf.variable_scope(name_or_scope=name, reuse=reuse):
with tf.variable_scope(name_or_scope='binary_seg'):
binary_seg_score = tf.nn.softmax(logits=binary_seg_logits)
binary_seg_prediction = tf.argmax(binary_seg_score, axis=-1)
with tf.variable_scope(name_or_scope='instance_seg'):
pix_bn = self.layerbn(
inputdata=instance_seg_logits, is_training=self._is_training, name='pix_bn')
pix_relu = self.relu(inputdata=pix_bn, name='pix_relu')
instance_seg_prediction = self.conv2d(
inputdata=pix_relu,
out_channel=CFG.TRAIN.EMBEDDING_FEATS_DIMS,
kernel_size=1,
use_bias=False,
name='pix_embedding_conv'
)
return binary_seg_prediction, instance_seg_prediction
对每个像素的分类,做softmax转成概率.再argmax求概率较大值的下标. 对每个像素的向量表示,用1x1卷积核做卷积,得到channel维度=CFG.TRAIN.EMBEDDING_FEATS_DIMS(配置为4).即(1,256,512,64)卷积得到(1,256,512,4)的tensor.即每个像素用一个四维向量表示.
所以,整个LaneNet的inference返回的是两个tensor.一个shape为(1,256,512) 一个为(1,256,512,4).
后处理
class LaneNetPostProcessor(object):
def postprocess(self, binary_seg_result, instance_seg_result=None,
min_area_threshold=100, source_image=None,
data_source='tusimple'):
对binary_seg_result,先通过形态学操作将小的空洞去除.参考https://www.cnblogs.com/sdu20112013/p/11672634.html
然后做聚类.
def _get_lane_embedding_feats(binary_seg_ret, instance_seg_ret):
"""
get lane embedding features according the binary seg result
:param binary_seg_ret:
:param instance_seg_ret:
:return:
"""
idx = np.where(binary_seg_ret == 255) #idx (b,h,w)
lane_embedding_feats = instance_seg_ret[idx]
# idx_scale = np.vstack((idx[0] / 256.0, idx[1] / 512.0)).transpose()
# lane_embedding_feats = np.hstack((lane_embedding_feats, idx_scale))
lane_coordinate = np.vstack((idx[1], idx[0])).transpose()
assert lane_embedding_feats.shape[0] == lane_coordinate.shape[0]
ret = {
'lane_embedding_feats': lane_embedding_feats,
'lane_coordinates': lane_coordinate
}
return ret
获取到坐标及对应坐标像素对应的向量表示.
np.where(condition)
只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)。这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
测试结果
tensorflow-gpu 1.15.2
4张titan xp
(4, 256, 512) (4, 256, 512, 4)
I0302 17:04:31.276140 29376 test_lanenet.py:222] imgae inference cost time: 2.58794s
(32, 256, 512) (32, 256, 512, 4)
I0302 17:05:50.322593 29632 test_lanenet.py:222] imgae inference cost time: 4.31036s
类似于高吞吐量,高延迟.对单帧图片处理在1-2s,多幅图片同时处理,平均下来的处理速度在0.1s.
论文里的backbone为enet,在nvida 1080 ti上推理速度52fps.
对于这个问题的解释,作者的解释是
2.Origin paper use Enet as backbone net but I use vgg16 as backbone net so speed will not get as fast as that. 3.Gpu need a short time to warm up and you can adjust your batch size to test the speed again:)
一个是特征提取网络和论文里不一致,一个是gpu有一个短暂的warm up的时间.
我自己的测试结果是在extract image features耗时较多.换一个backbone可能会有改善.
def inference(self, input_tensor, name):
"""
:param input_tensor:
:param name:
:return:
"""
print("***************,input_tensor shape:",input_tensor.shape)
with tf.variable_scope(name_or_scope=name, reuse=self._reuse):
t_start = time.time()
# first extract image features
extract_feats_result = self._frontend.build_model(
input_tensor=input_tensor,
name='{:s}_frontend'.format(self._net_flag),
reuse=self._reuse
)
t_cost = time.time() - t_start
glog.info('extract image features cost time: {:.5f}s'.format(t_cost))
# second apply backend process
t_start = time.time()
binary_seg_prediction, instance_seg_prediction = self._backend.inference(
binary_seg_logits=extract_feats_result['binary_segment_logits']['data'],
instance_seg_logits=extract_feats_result['instance_segment_logits']['data'],
name='{:s}_backend'.format(self._net_flag),
reuse=self._reuse
)
t_cost = time.time() - t_start
glog.info('backend process cost time: {:.5f}s'.format(t_cost))
if not self._reuse:
self._reuse = True
return binary_seg_prediction, instance_seg_prediction
参考:https://www.cnblogs.com/xuanyuyt/p/11523192.html https://zhuanlan.zhihu.com/p/93572094