KNN最邻近规则,主要应用领域是对未知事物的识别,即判断未知事物属于哪一类,判断思想是,基于欧几里得定理,判断未知事物的特征和哪一类已知事物的的特征最接近;
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比(组合函数)。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
K-NN可以说是一种最直接的用来分类未知数据的方法。基本通过下面这张图跟文字说明就可以明白K-NN是干什么的
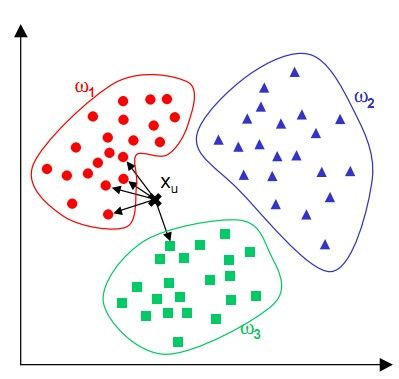
简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
算法步骤:
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离dist
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6---统计K-最近邻样本中每个类标号出现的次数
step.7---选择出现频率最大的类标号作为未知样本的类标号
KNN的matlab简单实现代码
function target=KNN(in,out,test,k)
% in: training samples data,n*d matrix
% out: training samples' class label,n*1
% test: testing data
% target: class label given by knn
% k: the number of neighbors
ClassLabel=unique(out);
c=length(ClassLabel);
n=size(in,1);
% target=zeros(size(test,1),1);
dist=zeros(size(in,1),1);
for j=1:size(test,1)
cnt=zeros(c,1);
for i=1:n
dist(i)=norm(in(i,:)-test(j,:));
end
[d,index]=sort(dist);
for i=1:k
ind=find(ClassLabel==out(index(i)));
cnt(ind)=cnt(ind)+1;
end
[m,ind]=max(cnt);
target(j)=ClassLabel(ind);
end
R语言的实现代码如下
library(class)
data(iris)
names(iris)
m1<-knn.cv(iris[,1:4],iris[,5],k=3,prob=TRUE)
attributes(.Last.value)
library(MASS)
m2<-lda(iris[,1:4],iris[,5]) 与判别分析进行比较
b<-data.frame(Sepal.Length=6,Sepal.Width=4,Petal.Length=5,Petal.Width=6)
p1<-predict(m2,b,type="class")
C++ 实现 :
// KNN.cpp K-最近邻分类算法
//
////////////////////////////////////////////////////////////////////////////////////////////////////////
#include
#include
#include
#include
#include
#include
#include
using namespace std;
////////////////////////////////////////////////////////////////////////////////////////////////////////
//
// 宏定义
//
////////////////////////////////////////////////////////////////////////////////////////////////////////
#define ATTR_NUM 4 //属性数目
#define MAX_SIZE_OF_TRAINING_SET 1000 //训练数据集的最大大小
#define MAX_SIZE_OF_TEST_SET 100 //测试数据集的最大大小
#define MAX_VALUE 10000.0 //属性最大值
#define K 7
//结构体
struct dataVector {
int ID; //ID号
char classLabel[15]; //分类标号
double attributes[ATTR_NUM]; //属性
};
struct distanceStruct {
int ID; //ID号
double distance; //距离
char classLabel[15]; //分类标号
};
////////////////////////////////////////////////////////////////////////////////////////////////////////
//
// 全局变量
//
////////////////////////////////////////////////////////////////////////////////////////////////////////
struct dataVector gTrainingSet[MAX_SIZE_OF_TRAINING_SET]; //训练数据集
struct dataVector gTestSet[MAX_SIZE_OF_TEST_SET]; //测试数据集
struct distanceStruct gNearestDistance[K]; //K个最近邻距离
int curTrainingSetSize=0; //训练数据集的大小
int curTestSetSize=0; //测试数据集的大小
////////////////////////////////////////////////////////////////////////////////////////////////////////
//
// 求 vector1=(x1,x2,...,xn)和vector2=(y1,y2,...,yn)的欧几里德距离
//
////////////////////////////////////////////////////////////////////////////////////////////////////////
double Distance(struct dataVector vector1,struct dataVector vector2)
{
double dist,sum=0.0;
for(int i=0;i
sum+=(vector1.attributes[i]-vector2.attributes[i])*(vector1.attributes[i]-vector2.attributes[i]);
}
dist=sqrt(sum);
return dist;
}
////////////////////////////////////////////////////////////////////////////////////////////////////////
//
// 得到gNearestDistance中的最大距离,返回下标
//
////////////////////////////////////////////////////////////////////////////////////////////////////////
int GetMaxDistance()
{
int maxNo=0;
for(int i=1;i
if(gNearestDistance[i].distance>gNearestDistance[maxNo].distance) maxNo = i;
}
return maxNo;
}
////////////////////////////////////////////////////////////////////////////////////////////////////////
//
// 对未知样本Sample分类
//
////////////////////////////////////////////////////////////////////////////////////////////////////////
char* Classify(struct dataVector Sample)
{
double dist=0;
int maxid=0,freq[K],i,tmpfreq=1;;
char *curClassLable=gNearestDistance[0].classLabel;
memset(freq,1,sizeof(freq));
//step.1---初始化距离为最大值
for(i=0;i
gNearestDistance[i].distance=MAX_VALUE;
}
//step.2---计算K-最近邻距离
for(i=0;i
//step.2.1---计算未知样本和每个训练样本的距离
dist=Distance(gTrainingSet[i],Sample);
//step.2.2---得到gNearestDistance中的最大距离
maxid=GetMaxDistance();
//step.2.3---如果距离小于gNearestDistance中的最大距离,则将该样本作为K-最近邻样本
if(dist
gNearestDistance[maxid].ID=gTrainingSet[i].ID;
gNearestDistance[maxid].distance=dist;
strcpy(gNearestDistance[maxid].classLabel,gTrainingSet[i].classLabel);
}
}
//step.3---统计每个类出现的次数
for(i=0;i
for(int j=0;j
if((i!=j)&&(strcmp(gNearestDistance[i].classLabel,gNearestDistance[j].classLabel)==0))
{
freq[i]+=1;
}
}
}
//step.4---选择出现频率最大的类标号
for(i=0;i
if(freq[i]>tmpfreq)
{
tmpfreq=freq[i];
curClassLable=gNearestDistance[i].classLabel;
}
}
return curClassLable;
}
////////////////////////////////////////////////////////////////////////////////////////////////////////
//
// 主函数
//
////////////////////////////////////////////////////////////////////////////////////////////////////////
void main()
{
char c;
char *classLabel="";
int i,j, rowNo=0,TruePositive=0,FalsePositive=0;
ifstream filein("iris.data");
FILE *fp;
if(filein.fail()){cout<<"Can't open data.txt"<
while(!filein.eof())
{
rowNo++;//第一组数据rowNo=1
if(curTrainingSetSize>=MAX_SIZE_OF_TRAINING_SET)
{
cout<<"The training set has "<
}
//rowNo%3!=0的100组数据作为训练数据集
if(rowNo%3!=0)
{
gTrainingSet[curTrainingSetSize].ID=rowNo;
for(int i = 0;i < ATTR_NUM;i++)
{
filein>>gTrainingSet[curTrainingSetSize].attributes[i];
filein>>c;
}
filein>>gTrainingSet[curTrainingSetSize].classLabel;
curTrainingSetSize++;
}
//剩下rowNo%3==0的50组做测试数据集
else if(rowNo%3==0)
{
gTestSet[curTestSetSize].ID=rowNo;
for(int i = 0;i < ATTR_NUM;i++)
{
filein>>gTestSet[curTestSetSize].attributes[i];
filein>>c;
}
filein>>gTestSet[curTestSetSize].classLabel;
curTestSetSize++;
}
}
filein.close();
//step.2---KNN算法进行分类,并将结果写到文件iris_OutPut.txt
fp=fopen("iris_OutPut.txt","w+t");
//用KNN算法进行分类
fprintf(fp,"************************************程序说明***************************************\n");
fprintf(fp,"** 采用KNN算法对iris.data分类。为了操作方便,对各组数据添加rowNo属性,第一组rowNo=1!\n");
fprintf(fp,"** 共有150组数据,选择rowNo模3不等于0的100组作为训练数据集,剩下的50组做测试数据集\n");
fprintf(fp,"***********************************************************************************\n\n");
fprintf(fp,"************************************实验结果***************************************\n\n");
for(i=0;i
fprintf(fp,"************************************第%d组数据**************************************\n",i+1);
classLabel =Classify(gTestSet[i]);
if(strcmp(classLabel,gTestSet[i].classLabel)==0)//相等时,分类正确
{
TruePositive++;
}
cout<<"rowNo: ";
cout<
cout<
if(strcmp(classLabel,gTestSet[i].classLabel)!=0)//不等时,分类错误
{
// cout<<" ***分类错误***\n";
fprintf(fp," ***分类错误***\n");
}
fprintf(fp,"%d-最临近数据:\n",K);
for(j=0;j
// cout<
}
fprintf(fp,"\n");
}
FalsePositive=curTestSetSize-TruePositive;
fprintf(fp,"***********************************结果分析**************************************\n",i);
fprintf(fp,"TP(True positive): %d\nFP(False positive): %d\naccuracy: %f\n",TruePositive,FalsePositive,double(TruePositive)/(curTestSetSize-1));
fclose(fp);
return;
}
以上内容为参考网上有关资料;加以总结;
转自:http://blog.csdn.net/xlm289348/article/details/8876353