摘要: Fastai社区的Jeremy Howard教授的《Practical Deep Learning for Coders(第一部分)》八大最佳实践。
去年九月,我参加了《Practical Deep Learning for Coders(第一部分)》的课堂,由Fastai社区的Jeremy Howard教授,它将于2018年1月份可在慕课网上线。经过七周的时间,我学会了很多技能:
1.使用预训练模型构建世界一流的图像分类器;
2.从调查过的数据集中构建语言模型的情感分析工具;
3.如何对结构化数据集进行深度学习;
4.如何使用深度学习通过协同过滤构建构建推荐引擎。
上述工作都是通过Jupyter笔记本的高效接口以及PyTorch提供的fastai深度学习库来完成。本文介绍了这8种技术,在每种技术中,我将用较为简短的fastai代码片段概括其基本思想,并在括号内指出该技术是否普遍使用(在做图像识别和分类,自然语言处理,构建结构化数据或协同过滤时,深度学习是否适用?),或者具体到深度学习应用的某种数据。 在课堂上,图像识别课程使用Kaggle的 Dogs vs. Cats: Kernels Edition,Dog Breed Identification和Planet: Understanding the Amazon from Space。
我在互联网上构建了自己的模型,模仿Dogs vs. Cats,取而代之的是蜘蛛和蝎子:Spiders vs. Scorpions。我从Google 上搜索并下载了约1500张“蜘蛛”和“沙漠蝎”,并删除了所有的非.jpg格式、所有多余的非图像文件以及没有扩展名的图像来清理数据,现在大约有815张图片可以使用。训练集中每个[蜘蛛,蝎子]类有290张,实验集和验证集分别有118只蜘蛛和117只蝎子。令我感到惊讶的是,模型的准确度达到了95%的准确度。

一、微调 VGG-16和ResNext50迁移学习(计算机视觉和图像分类)
对于图像分类,您可以通过微调获得大量好处,可以针对具体问题,建立一个更具有普遍挑战性的神经网络架构,例如:残差网络ResNext50是一个有50层的卷积神经网络,它在ImageNet上的1000种类别上进行训练,并且由于表现出色,所以从图像数据中提取出来的特征也很重要。 为了让它适应我的问题领域,我需要做的就是用输出为2维矢量的层替换最后一层(输出为1000维ImageNet矢量)。在上述代码片段中,两个输出类放在上图代码中PATH路径下。对于蜘蛛蝎子分类模型,请看下面:

请注意,train路径下的两个内容本身就是文件夹,每个文件夹包含290个图像。微调程序的示意图如下,它重新训练了一个最终层为10维的层。

二、周期性调整学习率(普遍使用)
学习率可能是训练深度神经网络微调中最重要的一个超参数。在非自适应配置环境(即不使用Adam,AdaDelta或其他变形)中最具有代表性的方法是深度学习从业者/研究人员同时运行多个实验,每个实验的学习率差异较小。如果数据集较为庞大且容易出错,并且你在使用随机矩阵构建上没有经验的话,这将需要很长的时间。然而,在2015年,美国海军研究实验室的Leslie N. Smith发现了一种自动搜索最佳学习率的方法:从一个非常小的值开始,在网络上运行几个小批量数据,调整学习率,同时跟踪损耗变化,直到损耗开始下降。Fastai社区的学生们解释了周期学习率的方法。
三、可重启随机梯度下降(普遍适用)
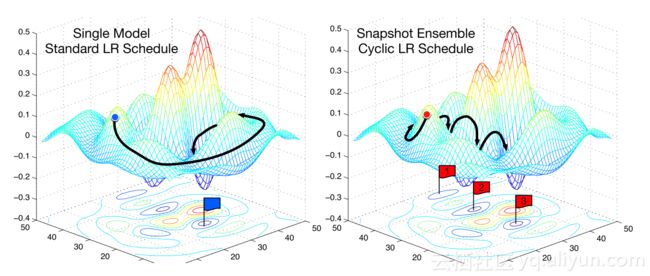
另一种加速随机梯度下降的方法是,随着训练的进行逐渐降低学习速度。这有助于观察学习率的变化和损耗的改善是否一致。当靠近最佳权重时,你需要采取更小步,因为如果采取大步,你可以会跳过误差曲面的最佳区域。如果学习率和损耗之间的关系不稳定,即如果学习率的较小变化导致损耗的巨大变化,那么我们不在稳定的区域(上图2)。那么,这个策略就会周期性的提高学习率。这里的“时期”是决定提高学习率的次数。这是周期性学习率计划。在fastai深度学习中,使用cycle_len和cycle_mult参数赋值给learner.fit。在图2中,学习率被重置3次。在使用正常的学习率计划时,通常需要更长的时间才能找到最优的损失,当开发人员等待直到所有的训练次数完成,然后再以不同的学习率再次手动尝试。
四、数据增广(计算机视觉和图像分类)
数据增广是为了增加训练和测试数据数量的简单方法。对于图像,这依赖于现成的学习问题,因此也取决于数据集图像的对称数量。其中一个例子就是Spiders vs. Scorpions 问题:数据集中的很多图像都可以被锁定,并且动物的形状没有奇怪的扭曲,称为transforms_side_on。例如:

五、测试(推断)时增广(计算机视觉和图像分类)
我们也可以在测试(推断)时间使用数据增广。在测试时候,你所能做的就是预测,你可以使用测试集中的单个图像来完成此操作,但是如果在可访问的测试集中对每个图像随机生成几个增量,则该过程会更加稳健。在fastai深度学习库中,预测时使用每个测试图像的4个随机增量,并且将这些预测的平均值作为该图像的预测。
六、用预训练RNN代替词向量
在不使用词向量的情况下,得到一个世界一流的情感分析架构的方法是,将你打算分析的整个训练数据集用来构建一个深度RNN语言模型。当模型具有高精度时,保存模型的编码器,并使用从编码器中获取的嵌入矩阵来构建情感分析模型。这比从词向量中获取的嵌入矩阵要好,因为循环神经网络可以比词向量有更好的依赖关系。
七、时序反向传播算法(BPTT) (NLP)
如果在一些时间步(time-step)的反向传播后没有重启,深度循环网络的隐藏状态可能会变得较难处理。例如,在一个基于字符的循环神经网络中,如果有一百万个字符,那么你也会有一百万个隐藏状态矢量。为了调整神经网络的梯度,我们需要对每一批的每个字符执行一百万条链式法则的计算,这将会消耗较多的内存。所以,为了降低内存需求,我们设定了字符反向传播的最大数值。由于循环神经网络的每个循环被称为时间步,因此,通过反向传播保持隐藏状态历史来限制层的数量的任务被称为基于时间的反向传播。层的数量值决定了模型的计算时间和内存要求,但是它提高了模型处理长句或操作序列的能力。
八、分类变量的实体向量化(结构化数据和NLP)
当对结构化数据进行深度学习时,这有助于将包含连续数据的列(如在线商店中的价格信息)从包含分类数据的列(如日期和接送地点)中分离开来。然后,将分类列的独热编码过程转换为指向神经网络全连接嵌入层的查找表。因此,你的神经网络有机会学习这些分类变量/列,而忽略列的分类性质。它可以学习周期性事件,如一周中哪天销售量最大。这是预测产品最优价格和协同过滤的非常有效的方法,也是所有拥有表格数据的公司的标准数据分析和预测方法。
以上为译文。
本文由阿里云云栖社区组织翻译。
文章原标题《8 Deep Learning Best Practices I Learned About in 2017》