什么是机器学习 ?
机器学习是从数据中自动分析获取规律,并利用规律对未知数据进行预测。
常用领域智能客服,帮助看病,智能推送等等,应用领域很广。
机器学习的常用数据:csv文件,mysql等数据库的读取速度是不够快的。同时格式也不符合。
数据结构组成:特征值+目标值比如通过头发长度,眼睛颜色等这些特征值来推测是男是女(目标值)对特征进行处理,我们把它叫做特征工程。
环境搭建
建议创建一个虚拟环境。
安装Scikit-learn:pip install Scikit-learn
注意:需要以numpy和pandas为基础库
测试是否安装成功:
import sklearn,运行看是否报错。对于特征工程我们长使用Scikit-learn。
对数据进行特征值化目的是为了让计算机更好的处理。
# 对字典进行特征化处理
实例:
# 导入特征化字典模块
from sklearn.feature_extraction import DictVectorizer
def dictvec():
# 数据
list_dict = [{'city':'武汉','PM2.5':73},{'city':'上海','PM2.5':160},{'city':'天津','PM2.5':31}]
# 实例化
dict = DictVectorizer()
# 调用fit_transform处理
data = dict.fit_transform(list_dict)
print(data)
return None
if __name__ == "__main__":
dictvec()
会输出:
(0, 0) 73.0
(0, 3) 1.0
(1, 0) 160.0
(1, 1) 1.0
(2, 0) 31.0
(2, 2) 1.0
看上去一脸懵逼,不知道是什么!
将实例化的时候添加一个参数,修改成:
dict = DictVectorizer(sparse=False)
输出:
[[ 73. 0. 0. 1.]
[160. 1. 0. 0.]
[ 31. 0. 1. 0.]]
这个就比较熟悉了,是一个二维数组。
我们把这输出的对比来看:
(0,0) 73.0 也就是二维数组中第一行,第一列的第一个值73
同理(0, 3) 1.0 就是二维数组中第一行,第4列的值1
其他的值都是一样的道理。将有值的地方输出了出来。
下面的二位数值是ndarray类型,而第一次输出的是sparse类型,也可以叫他sparse矩阵。
为什么需要转化成sparse矩阵,0和1是怎么来的?
可以在上诉实例中再输出一行:
print(dict.get_feature_names())
会输出:
['PM2.5', 'city=上海', 'city=天津', 'city=武汉']
[[ 73. 0. 0. 1.]
[160. 1. 0. 0.]
[ 31. 0. 1. 0.]]
这样再来看,这个二维数组第一列输出的就是PM2.5的实际的值。
第二列数据对应上海,是上海标记为1,不是上海标记为0
以此类推,第三列为天津,第四列为武汉。
把数据特征值化,转化成sparse矩阵,来更好的处理,同时还能节约内存。
简单来讲就是把汉字转化成0和1。也就是one-hot编码。
# 对文本数据的特征值化
实例:
# 导入模块
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
# 对文本进行特征化
# 创建两个文本
text = ["My name is Zhang San","My friend is Li Si"]
# 实例化
c = CountVectorizer()
# 特征值化
data = c.fit_transform(text)
print(data)
print("-----")
print(c.get_feature_names())
# 转化成数组
print(data.toarray())
return None
if __name__ == "__main__":
countvec()
输出:
(0, 5) 1
(0, 7) 1
(0, 1) 1
(0, 4) 1
(0, 3) 1
(1, 6) 1
(1, 2) 1
(1, 0) 1
(1, 1) 1
(1, 3) 1
-----
['friend', 'is', 'li', 'my', 'name', 'san', 'si', 'zhang']
[[0 1 0 1 1 1 0 1]
[1 1 1 1 0 0 1 0]]
-以上直接看不是很明白,直接看-下面的。
get_feature_names()统计出了不重复的单词。但是如果我们的文本中有I,这种单个词汇,
是默认放弃统计的。因为它没有分类依据。
data.toarray()一一对应 get_feature_names()中每个文本出现的次数
以friend为例:再第一个文本中为出现为0,再第二个文本中出现1次,为1。
其他都是这样。常用于文本分类,情感分析等。
但是如果换成中文,会以,为分隔符,把他们分隔开,但这不是我们想要的。
比如写成["人生苦短,我用python","微信公众号,python入门到放弃"]
会分割成:['python入门到放弃', '人生苦短', '微信公众号', '我用python']
如果我们写成["人生 苦短,我用 python","微信 公众号,python 入门到 放弃"]
分割成:['python', '人生', '入门到', '公众号', '微信', '我用', '放弃', '苦短']
所以在处理中文的时候我们需要先进行分词处理。就会用到jieba分词库。
简单介绍jieba的使用方法:
安装:pip install jieba
使用:
import jieba
text1 = jieba.cut("人生苦短,我用python")
text2 = jieba.cut("微信公众号,python入门到放弃")
text3 = jieba.cut("我的名字是张三")
# 由于返回值不是文本,我们进行转化列表处理
te1 = list(text1)
te2 = list(text2)
te3 = list(text3)
# 转换成字符串,用空格拼接
t1 = ' '.join(te1)
t2 = ' '.join(te2)
t3 = ' '.join(te3)
此时t1,t2,t3就传化成一个字符串,就可以传入其中了。
但是这种方式还不是很高效,因为一篇文章其实是有很多中性词的。比如,因为,所以这些词语。
在实际操作中我们常用tf idf来做文本分类。
tf:词的频率。
idf:逆文档频率。
第一步tf和上面的功能一样,统计某个词在文章中出现的次数。
第二步idf,是一个公式log(总文档数量/该词出现的文档数量)
(该词出现的文档数量:也就是某个词在那些文档中出现过)
总文档数量/该词出现的文档数量的值越小,log(总文档数量/该词出现的文档数量)也是越小的。
第三步:tf*idf,得到的值说明了该词的重要性。
这就是朴素贝叶斯算法。
实例:
# 导入模块
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
def tf_idfvec():
# 文本
text = ["人生 苦短,我用 python","微信 公众号,python 入门到 放弃"]
# 实例化
tf = TfidfVectorizer()
data = tf.fit_transform(text)
print(data)
print("-----")
print(tf.get_feature_names())
print(data.toarray())
return None
if __name__ == "__main__":
tf_idfvec()
输出:
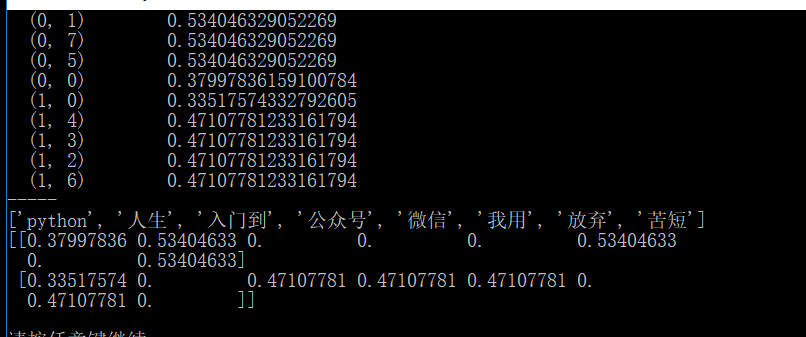
这里的0.xxxx就表示这个词的重要性。