第一章.Redis的性能测试
性能测试是通过往Redis中插入数据和读取数据执行多条命令实现的.
1. Redis- redis-benchmark
1.1 语法结构
redis-benchmark [option] [option value]
1.2 命令参数
| 序号 | 选项 | 描述 | 默认值 |
| 1 | -h | 指定服务器主机名,可以是本地的和远端的 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | --csv | 以 CSV 格式输出 | |
| 12 | -l | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
1.3 执行测试
[root@redis01 ~]# redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 100000 -q
SET: 55401.66 requests per second
LPUSH: 58072.01 requests per second
性能测试,参考地址,点击这里
第二章.shell脚本简单测试写入
2.1 shell脚本
1.写一个简单的for ,因为for是一行一行的执行,插入的会相对慢.
[root@redis01 ~]# cat redis_performance.sh
#!/bin/bash
##############################################################
# File Name: redis_performance.sh
# Version: V1.0
# Author: liych
# Organization: http://itshangyun.com
# Created Time : 2020-03-22 9:45:32
# Description:
##############################################################
for redis in {1..100000}
do
redis-cli -h redis01 set K_${redis} v_${redis}
done
2.2 操作示例
1.执行脚本
[root@redis01 ~]# time sh redis_performance.sh
real 4m29.302s
user 0m51.673s
sys 2m54.324s
2.登陆到redis查看
> KEYS *
可以看到已经写入3万多 用时0.78s
36372) "K_23129"
(0.78s)
第三章.Redis持久化缓存数据
3.1 为什么要用持久化缓存呢?
说明:
因为我们插入到redis的数据都在redis自身的缓存程序中,并不在我们的本地硬盘内,这样的话,当我们重启或者杀死redis这个进程后,发现redis中的数据会不存在的,那么之前我们规划的数据目录中依旧也是没有数据的,然后呢? 数据就真的不复存在了,这样的话,没有缓存就没有数据,是不行的.不能实现数据缓存并加速读的效率,首先来验证一下 杀死或僵死的Redis中数据丢失这种情况.之后才能认识到持久化的重要性.
3.2 Redis中数据丢失 杀死进程
1.查看redis中
[root@redis01 ~]# redis-cli -h redis01
redis01:6379> KEYS *
...
52334) "K_48636"
52335) "K_23129"
(1.07s)
#这时的redis中是有缓存数据的.
2.杀死进程
[root@redis01 ~]# pkill redis
[root@redis01 ~]# ps -ef |grep redis
root 74652 17796 0 22:36 pts/0 00:00:00 grep --color=auto redis
3.启动redis
[root@redis01 ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
4.验证数据是否还在redis中
[root@redis01 ~]# redis-cli -h redis01
redis01:6379> KEYS *
(empty list or set)
# 这时候发现缓存在内的数据已经不复存在了.
5.本地的数据目录也是没有的
[root@redis01 ~]# ll /data/redis_cluster/redis_6379/
总用量 0
缓存数据留存在Redis内存中的数据,当发生杀死进程,或异常断电,重启等,缓存数据会丢失
3.3 持久化缓存数据
点击一下 官网介绍Redis的持久化性能
Redis的持久化提供给两种 RDB和AOF.
3.4 RDB持久化介绍
RDB持久性, 按指定的时间间隔执行数据集的时间点快照,并把内存的数据快照到硬盘. 需要定时定点的执行bgsave将数据进行快照备份.
RDB优点:
① RDB是非常紧凑的二进制文件用LZF压缩格式留存,全量备份数据,恢复速度快 ,RDB文件非常适合备份。
---
RDB不足:
① 存在丢失数据的风险,Redis使用特定的二进制文件格式留存,伴随着Redis的更新,存在这老版本的Redis和新版本的Redis, 恢复数据时候的导致RDB数据格式不兼容
② RDB需要经常使用Fork才能使用子进程将其持久化在磁盘上。 如果数据量很大,Fork可能很耗时 , 则可能导致Redis停止为客户端服务几毫秒甚至一秒钟,没有办法做到实时的持久化,因为bgsave每次运行时候 ,都要启动一个FORK进程.
③ 执行bgsave的时候,是将原本的内存数据,复制一份到本地存储目录,属于重量性操作,耗内存.
3.4.1 RDB备份方式
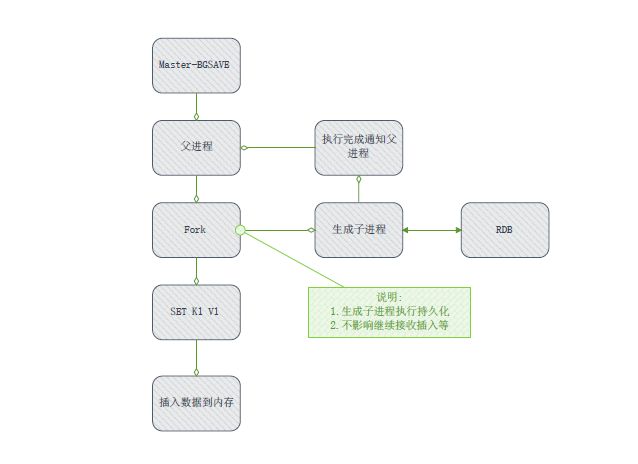
1.执行bgsave命令Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在,将直接返回.
2.父进程执行fork操作 创建子进程,fork操作过程中,父进程会阻塞,可以登陆通过Redis后执行 info stats 命令查看,latest_fork_usec选项,可以获取到最近一个fork操作的耗时时间.单位是秒
3.父进程fork完成 BGSAVE后 返回 Background saving started后,将不再进行阻塞,可以继续响应其他的命令.
4.子进程创建RDB文件,根据文件进程内存生成时的快照文件,完成后对原文件进行替换,命令行执行last save 命令可以获取最后一次生成的RDB的时间,对应的info stats 统计的是rdb_last_save_time选项,
5.进程发送信号给父进程表示完成,父进程更新统计信息,可执行info persistence查看rdb选项的状态信息
6.需要注意的是 生成的子进程也是需要一个独立的内存空间,当系统内存空间不足是,进程将进入僵死状态.比如redis服务器共计64G内存,redis使用32G,剩下归系统和子进程使用.
3.4.2 RDB文件处理
保存
1.RDB文件保存在配置文件内指定的目录中,文件名通过dbfilename配置指定,Redis运行期间可通过config set 配置新的目录保存位置,当下次运行RDB的时候文件会保存在set的目录中.
压缩
1.Redis默认采用LZF算法对生成的RDB文件做压缩处理,压缩后的文件小于内存大小,默认是开启,可以通过参数 config set rdbcompression (yes|no) 动态修改
校验
1.如果Redis加载损坏的RDB文件是拒绝启动,并打印如下信息
#Short read or OMM loading DB Unrecoverable error aborting now
这是可以使用Redis提供的 redis-check-dump工具,检测RDB文件并获取对应的错误报告
3.4.3 如何配置ROB持久化
使用BGSAVE 保存数据缓存到本地的备份目录
1.首先在配置文件内修改好本地硬盘存储数据位置并设定持久化策略 /data/redis_cluster/redis_6379/
2.登陆到Redis中保存数据
| 参数 | 说明 |
|---|---|
| save 900 1 | 900秒内有1个更改触发备份 |
| save 300 10 | 300秒内有10个更改触发备份 |
| save 60 10000 | 60秒内有10000个更改触发备份 |
| # 满足上述条件之一就执行RDB存储. |
一: 修改配置文件增加触发条件
1.修改配置文件 增加设定持久化数据留存条件
[root@redis01 ~]# vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
## 指定本地持久化文件的文件名,默认是dump.rdb
dbfilename redis_6379.rdb
## 本地数据库的目录
dir /data/redis_cluster/redis_6379/
## 设定持久化数据留存条件
save 900 1
save 300 10
save 60 10000
-----
2.重新启动redis
redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
3.关闭命令,不执行
redis-cli -h redis01 shutdown
二: RDB备份持久化
一: RDB备份持久化
1.登陆到Redis内
redis01:6379> KEYS *
1000) "K_76"
redis01:6379> BGSAVE #执行保存
Background saving started #保存成功
2.查看本地数据目录
[root@redis01 ~]# ls /data/redis_cluster/redis_6379/
redis_6379.rdb #数据留存
三: RDB恢复持久化
1. 将备份文件 (默认dump.rdb)移动到 redis 安装目录并启动服务,redis就会自动加载文件数据至内存了。Redis 服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
2. 使用 CONFIG GET dir 获取持久化目录
redis01:6379> CONFIG GET dir
1) "dir"
2) "/data/redis_cluster/redis_6379"
四: RDB停止持久化
两种方式:
1.注释配置文件的save参数
2.替换空字符形式
redis-cli config set save " "
这时杀掉redis进程后,重启Redis,数据依旧会显示出来,那是因为我们备份的数据会预加载到内存中
3.4.4 持久化数据总结
1.触发条件设定后,执行shutdown,Redis会自动执行bgsave,然后再执行shutdown.数据会留存本地硬盘.
2.触发条件设定后,执行pkill kill(kill -15) killall.依旧会触发条件并做持久化.
6.kill -9 redis 强制杀死进程后,Redis内部不会触发持久化,数据目录内没有数据.
3.恢复持久化的数据的时候,RDB文件名称要和配置文件里dbfilename设定的一样,没有rdb数据内存也是不会有的
4.未配置save参数,执行shutdown不会自动触发bgsave持久化,现象数据丢失
5.未配置save参数,手动执行bgsave触发持久化并保存到本地设定好的目录dir
3.5 AOF介绍(append only file)
AOF持久化会记录服务器接收的每个写入操作,这些操作将在服务器启动时再次执行,以恢复原始数据集。使用与Redis协议本身相同的格式记录命令,并且仅采用追加方式。当日志太大时,Redis可以在后台重写日志.主要的作用是解决了数据持久化的实时性, 可以理解为 MySQL的binlog. 只记录操作记录,不记录历史数据.
AOF优点:
1.AOF日志仅是一个追加日志,因此,如果断电,也不会出现寻道或损坏问题。它是逐条记录备份,损失数据最多1秒,当出现数据损坏可以使用redis-check-aof 工具轻松修复它。
2.Redis数据集太大时,Redis可以在后台自动重写AOF。重写是完全安全的,因为Redis继续追加到旧文件时,会生成一个全新的文件,其中包含创建当前数据集所需的最少操作集,一旦准备好第二个文件,Redis会切换这两个文件并开始追加到新的那一个。
3.AOF以易于理解和解析的格式包含所有操作的日志。您甚至可以轻松导出AOF文件。例如,即使您使用FLUSHALL命令刷新了所有错误文件,如果在此期间未执行任何日志重写操作,您仍然可以保存数据集,只是停止服务器,删除最新命令并重新启动Redis。
---
AOF不足:
1.恢复较大数据会比较慢
3.5.1 AOF备份方式
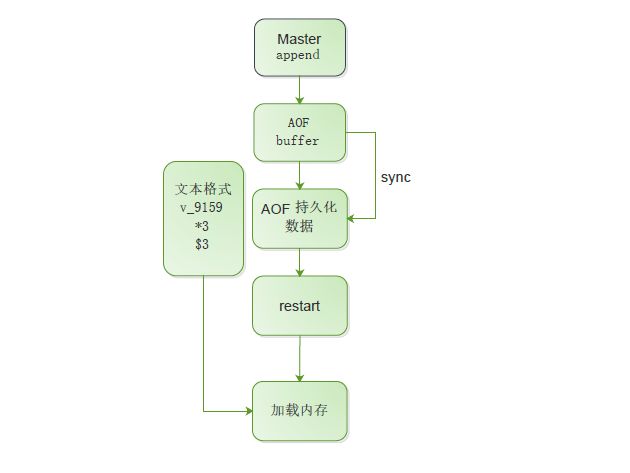
1.所有写入命令追加到AOF buffer 缓冲区中.
2.AOF缓冲区根据对应的策略向硬盘同步操作
3.随着AOF文件越来越大,需要定时对AOF文件进行重写,达到压缩的目的
4.当Redis服务器重启时,可以加载AOF文件进行数据恢复
5.AOF命令写入的内容是文本格式
3.5.2 关于AOF的两个疑惑?
一. AOF为什么直接采用文件协议格式?
1.文本协议具有很好的兼容性
2.开启AOF后,所有的写入命令都可以追加操作,避免来回调用的数据开销
3.文本协议具有可读性,方便直接修改和处理
二. AOF为什么把命令追加到 AOF Buffer中?
1.Redis使用单线程响应命令,如果每次写入AOF文件命令都直接追加到硬盘,那么性能完全取决当前硬盘的负载,先写入缓冲区,还有另外一个好处 ,可以提供多种缓冲区同步硬盘的策略,在性能和安全安性方便做出平衡.
3.5.3 如何配置AOF持久化
redis提供多种AOF缓冲区同步文件策略,由参数 appendfsync控制
| 参数 | 说明 |
|---|---|
| appendonly | yes 开启AOF日志功能 |
| always | 写入AOF缓冲区调用系统的fsync 操作同步到AOF文件,执行立即持久化,完成后返回 | 配置为always时,每次写入都要同步AOF文件, 在一般的SATA硬盘上,Redis只支持大约几百TPS写入,不能实现高速缓存,并不建议配置. |
| everysec | 写入AOF缓冲区调用系统的write操作,完成后返回,fsync同步文件操线程每秒调用一次 | 建议配置为everysec是建议的同步策略,同时也是默认配置,它做到兼顾性能和数据的安全性,当然在系统宕机的时候官方说丢失1秒的数据,也存在数据全部丢失的风险. |
| no | 写入AOF 缓冲区调用系统的write操作,不对AOF文件做fsync同步,同步硬盘由操作系统负责,通常同步周期最长30秒 | 配置为 no .由于操作系统每次同步AOF文件的周期不可控,而且会加大同步硬盘的数据量,虽然提升了性能,但是数据安全性无法保证. |
一: 修改配置文件增加触发条件
1.修改配置文件 增加设定持久化数据留存条件
[root@redis01 ~]# vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
#指定本地持久化文件的文件名
appendfilename "redis_6379.aof"
#本地数据库的目录
dir /data/redis_cluster/redis_6379/
#开启AOF
appendonly yes
#立即缓存到硬盘
appendfsync always
#一秒一次
appendfsync everysec
#交由系统负责缓存区大小在留存AOF中
appendfsync no
-----
2.重新启动redis
redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
3.关闭命令,不执行
redis-cli -h redis01 shutdown
二: 验证数据
[root@redis01 redis_6379]# ls /data/redis_cluster/redis_6379/
redis_6379.aof redis_6379.rdb
#两种数据同时存在数据目录内,Redis出现故障后,在重新启动的时候只读AOF数据.
[root@redis01 redis_6379]# tail -10 redis_6379.aof
K_1999
$6
v_1999
*3
$3
set
$6
K_2000
$6
v_2000
#AOF持久化数据
二: 恢复数据
[root@redis01 ~]# redis-cli -h redis01 -a 123456 < /data/redis_cluster/redis_6379/redis_6379.aof
3.5.4 write 和fsync说明
| write | 操作会触发延迟写(deiayed write)机制,linux内核提供页缓冲区用来提高硬盘IO性能,操作在写入系统缓冲区后直接返回,同步硬盘操作依赖系统调度. 例如: 缓冲区空间写满或达到特定时间周期,同步文件之前,如果此时系统故障或宕机,缓冲区内数据丢失 |
| fsync | 针对单个文件操作 (如AOF文件 ) 做强制磁盘同步fsync将阻塞直接写入硬盘完成后返回,保证数据持久化 |
3.5.5 重写机制
Redis持久化命令的不断写入到AOF文件,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制,压缩文件体积,AOF文件重写是把Redis进程内部的数据转化为写命令同步到新的AOF文件的过程.
第四章.Redis的安全认证
第四章.Redis安全认证
Redis的用户认证指的是登陆的时候可以输入密码,或其他的token等认证方式,这里说明的是基于密码认证方式.默认开启了密码认证保护,只允许本地的127.0.0.1登陆.
4.1 开启密码认证
4.1.1 第一种方式
[root@redis01 ~]# vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
1.配置监听内网主机地址
2.增加requirepass
##绑定主机上的网卡IP地址,这里需要修改成你当前主机的内网IP地址,允许主机认证
bind 127.0.0.1 192.168.188.159
##增加requirepass password
requirepass 123456
4.1.2 第二种方式
redis01:6379> config set requirepass 123456
4.1.3 测试密码登陆
1.第一种登陆测试
redis-cli -h db01
redis01:6379> AUTH 123456
OK
2.第二种登陆测试
redis-cli -h db01 -a 123456 get kname
4.2 禁用危险命令
1)禁用命令
rename-command KEYS ""
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
2)重命名命令
rename-command KEYS "X"
rename-command FLUSHALL "X"
rename-command FLUSHDB "X"
rename-command CONFIG "X"
第五章.Redis主从复制 Replication
5.1 主从复制的作用
主要是解决单台主机发生故障时候,数据丢失的风险, 做主从实现数据的备份,和MySQL的主从复制性质一样.
5.2 主从同步操作示例
| 环境主机 | 角色 |
|---|---|
| 192.168.188.159-Redis01 | 主端(主库) |
| 192.168.188.160-Redis02 | 备端(从库) |

5.2.1 主节点操作
1.打包备份目录的后上传到备份节点
[root@redis01 ~]# tar zcvf redis01.tar.gz /opt/redis_cluster/
[root@redis01 ~]# scp redis01.tar.gz redis02:/opt/
5.2.2 从节点操作
1.解压缩,生成redids-cli命令
[root@redis02 ~]# cd /opt/
[root@redis02 opt]# tar xf redis01.tar.gz
[root@redis02 opt]# mv opt/* .
[root@redis02 opt]# rm -rf redis01.tar.gz opt/
[root@redis02 opt]# cd redis_cluster/redis/ ; make install
2.创建备份目录
[root@redis02 redis-3.2.9]# mkdir -p /data/redis_cluster/redis_6379/
3.修改配置文件
[root@redis02 redis]# vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
## 绑定主机上的网卡IP地址,这里需要修改成你当前主机的内网IP地址,备的地址
bind 127.0.0.1 192.168.188.160
##同步主数据文件
SLAVEOF 192.168.188.159 6379
##验证主库认证密码
#masterauth 123456
[root@redis02 redis]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@redis02 redis]# netstat -lntp
[root@redis02 redis]# redis-cli -h redis02
redis02:6379> KEYS *
5.2.3 建立主从复制关系
从库端操作
配置方法:
1.临时生效
[root@redis02 redis]# redis-cli -h redis02
redis02:6379> SLAVEOF 192.168.188.159 6379
OK
2.写入配置文件永久生效
SLAVEOF 192.168.188.159 6379
5.2.4 检查日志,是否成功
主端日志:
[root@redis01 ~]# tail -8 /opt/redis_cluster/redis_6379/logs/redis_6379.log
1112:M 24 Mar 00:24:13.174 * Slave 192.168.188.160:6379 asks for synchronization
1112:M 24 Mar 00:24:13.174 * Full resync requested by slave 192.168.188.160:6379
1112:M 24 Mar 00:24:13.174 * Starting BGSAVE for SYNC with target: disk
1112:M 24 Mar 00:24:13.358 * Background saving started by pid 1663
1663:C 24 Mar 00:24:13.432 * DB saved on disk
1663:C 24 Mar 00:24:13.433 * RDB: 6 MB of memory used by copy-on-write
1112:M 24 Mar 00:24:13.526 * Background saving terminated with success
1112:M 24 Mar 00:24:13.532 * Synchronization with slave 192.168.188.160:6379 succeeded
#出现连接的slave端信息后,日志说明已经配置成功
备端日志:
[root@redis02 redis]# tail -8 /opt/redis_cluster/redis_6379/logs/redis_6379.log
2005:C 24 Mar 00:24:13.635 * Parent agreed to stop sending diffs. Finalizing AOF...
2005:C 24 Mar 00:24:13.636 * Concatenating 0.00 MB of AOF diff received from parent.
2005:C 24 Mar 00:24:13.637 * SYNC append only file rewrite performed
2005:C 24 Mar 00:24:13.638 * AOF rewrite: 6 MB of memory used by copy-on-write
1984:S 24 Mar 00:24:13.694 * Background AOF rewrite terminated with success
1984:S 24 Mar 00:24:13.694 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
1984:S 24 Mar 00:24:13.694 * Background AOF rewrite finished successfully
1984:S 24 Mar 00:25:51.481 * SLAVE OF would result into synchronization with the master we are already connected with. No operation performed.
#未检测到主端的操作记录,配置成功
5.2.5 主从复制流程
从日志中看出:
1.从节点发送同步请求到主节点上进行确立同步关系
2.主节点接收到从节点的请求之后,做的相关操作
- 确定主从关系
- 主节点立即执行bgsave将当前内存里的持久化数据,保存在硬盘上,用作同步使用.
- 持久化完成之后(DB saved on disk),将持久化数据发送给从节点
3.从节点接收到持久化数据文件之后,做的相关操作
- 清空从节点的自身内存中的数据
- 加载来自主节点的持久化数据到从节点的内存中
- 从库确定完成结果,发送给主库,主库确认完成
4.确定完成同步,往后的操作就是主写入从同步(只读,不可写)
5.2.6 总结主从复制
关于同步:
1.配置主从同步的时候 ,需要优先备份主从库的持久化数据,避免出现问题数据丢失的情况.
2.开始同步 SLAVEOF 192.168.188.159 6379 #从库指定主库的host和port
3.停止同步 SLAVEOF no one #可在从库配置文件或内存中操作
4.主从同步的时候, 主库负责写入,从库负责接收主库的信息,且从库不可写,只可以读.
如从库插入数据会报错 (error) READONLY You can't write against a read only slave.
5.当主节点发生故障后,从节点依旧同步主节点,从节点不会因主挂掉就不同步.日志显示一直连接主.
6.当主发生故障后,从节点操作如下:
1.修改配置文件的bind指向主节点主机信息
2.从节点执行停止同步 SLAVEOF no one
7.建立主从同步后,从节点会清空现有数据后,在开始发起同步请求.如果同步错误,从库数据就不复存在.
8.主从同步配置完成后,当主库有认证登录的时候,从库需要配置认证信息,配置文件增加 masterauth 123456
5.2.7 主从复制配置文件
###########1.基础设定###################################################
#守护进程模式启动
daemonize yes
#绑定redis监听的主机IP地址.(当前主机IP地址)
bind 127.0.0.1 192.168.188.159
#增加密码认证安全(requirepass password)
#requirepass 123456
#默认redis监听的端口
port 6379
#Pid文件和Log文件的保存目录信息
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
#设置数据库的数量,默认数据库为0,部署集群节点只有1个数据库
databases 16
##############2.主从复制####################################################
#配置主从复制时候,主节点配置文件不添加这行配置; 从节点添加SLAVEOF
#开启主从复制模式,从同步主的IP+端口
#SLAVEOF 192.168.188.159 6379
############3.本地RDB持久化##################################################
#指定本地持久化文件的文件名,默认是dump.rdb
dbfilename redis_6379.rdb
#本地持久化数据库存放的目录
dir /data/redis_cluster/redis_6379/
#设定持久化数据留存条件
#900秒内有1个更改触发备份
#300秒内有10个更改触发备份
#60秒内有10000个更改触发备份
save 900 1
save 300 10
save 60 10000
#############4.本地AOF持久化###################################################
#指定本地持久化文件的文件名,默认是appendonly.aof
appendfilename "redis_6379.aof"
#本地数据库的目录
dir /data/redis_cluster/redis_6379/
#开启AOF持久化数据备份
appendonly yes
#立即缓存到硬盘,并不建议配置.数据直接写入到硬盘
appendfsync always
#1秒1次的数据写入到硬盘,官方建议默认的配置
appendfsync everysec
#写入交给系统负责,操作系统每次同步AOF文件的周期不可控,而且会加大同步硬盘的数据量,虽然提升了性能,但是数据安全性无法保证.不建议配置
appendfsync no
#########################################################################################
第六章.Redis哨兵(Sentinel )高可用
6.1 哨兵模式(sentinel)的作用
Sentinel介绍
Redis Sentinel是Redis的官方高可用性解决方案 , 使用Sentinel可以创建Redis部署 ,解决redis单点故障,和主从复制时出现的故障后,不能自动迁移故障 ,有效的监控主从环境的健康状态,并提供通知故障信息. Sentinel的当前版本称为Sentinel 2
具体提供了, 监控, 通知, 自动故障转移. 配置提供程序; 点击一下直达Redis Sentinel官方文档
1.监控(Monitoring)
Sentinel会定期检查主从复制的服务器的工作状态是否运行正常.
2.消息通知(Message notification)
监控主从服务状态,当其中一台发生故障后,Sentinel可以通过API通知系统管理员或其他计算机程序发送通知
3.自动故障转移(Automatic failover) 配置提供程序(Configuration provider)
主从复制中,当一个主服务器不能正常工作时, Sentinel会启动一次故障转移,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器
6.2 哨兵模式操作示例
| 环境主机 | 角色 | 端口 |
|---|---|---|
| 192.168.188.159-Redis01 | Master/ Sentinel-01 | 6379/ 26379 |
| 192.168.188.160-Redis02 | Slave/ Sentinel-02 | 6379/ 26379 |
| 192.168.188.161-Redis03 | Slave/ Sentinel-03 | 6379/ 26379 |

工作原理就是,当Master宕机的时候,Sentinel会选举出新的Master,并根据Sentinel中配置的内容,去动态修改VIP(虚拟IP),将VIP(虚拟IP)指向新的Master。我们的客户端就连向指定的VIP即可!
6.2.1 Sentinel环境
1.哨兵是基于主从复制,所以要先配置好主从复制 (159,160,160)
2.每个redis节点都需要安装哨兵
快速的配置1台主从命令集合(基于redis基础环境)
rsync -avz 192.168.188.159:/opt/* /opt/
mkdir -p /data/redis_cluster/redis_6379/
cd /opt/redis_cluster/redis; make install
sed -i 's#159#161#g' /opt/redis_cluster/redis_6379/conf/redis_6379.conf
redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
redis-cli -h redis03
2.启动所有节点
redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
3.开启所有节点的主从复制
redis-cli -h 192.168.188.159 slaveof 192.168.188.159 6379
redis-cli -h 192.168.188.160 slaveof 192.168.188.159 6379
redis-cli -h 192.168.188.161 slaveof 192.168.188.159 6379
4.检查登录查看
[root@redis01 ~]# redis-cli -h redis01
redis01:6379>
[root@redis02 ~]# redis-cli -h redis02
redis02:6379>
[root@redis03 ~]# redis-cli - redis03
redis03:6379>
6.2.2 Master操作步骤(159)
1.在Master上配置
#配置哨兵的相关目录
mkdir -p /data/redis_cluster/redis_26379
mkdir -p /opt/redis_cluster/redis_26379/{conf,pid,logs}
2.增加哨兵的配置文件,三台机器都需要操作 (159,160,160)
cat >/opt/redis_cluster/redis_26379/conf/redis_26379.conf<< EOF
bind 192.168.188.159
port 26379
daemonize yes
logfile /opt/redis_cluster/redis_26379/logs/redis_26379.log
dir /data/redis_cluster/redis_26379
sentinel monitor myredis 192.168.188.159 6379 2
sentinel down-after-milliseconds myredis 3000
sentinel parallel-syncs myredis 1
sentinel failover-timeout myredis 18000
EOF
配置文件注释
sentinel monitor myredis 192.168.188.159 6379 2
#myredis 主节点的别名 ip 和端口,判断主节点失败,至少两个Sentinel节点参与竞选
sentinel down-after-milliseconds myredis 3000
#指定Sentinel认为Master已经掉线需要的毫秒数
sentinel parallel-syncs myredis 1
#向新的Master节点发起复制操作的从节点的个数,1 轮询发起复制,响应复制的个数,完成1个在继续下1个.
sentinel failover-timeout myredis 18000
#故障转移超时时间
6.2.3 Slave操作步骤(160)(161)
redis01操作
rsync -avz /opt/* redis02:/opt/
rsync -avz /opt/* redis03:/opt/
#没有命令执行 yum install rsync -y
redis02操作
mkdir -p /data/redis_cluster/redis_26379
mkdir -p /opt/redis_cluster/redis_26379/{conf,pid,logs}
cd /opt/redis_cluster/redis
make install
sed -i '/^bind/c bind 192.168.188.160' /opt/redis_cluster/redis_6379/conf/redis_6379.conf
sed -i '/^bind/c bind 192.168.188.160' /opt/redis_cluster/redis_26379/conf/redis_26379.conf
redis03操作
mkdir -p /data/redis_cluster/redis_26379
mkdir -p /opt/redis_cluster/redis_26379/{conf,pid,logs}
cd /opt/redis_cluster/redis
make install
sed -i '/^bind/c bind 192.168.188.161' /opt/redis_cluster/redis_6379/conf/redis_6379.conf
sed -i '/^bind/c bind 192.168.188.161' /opt/redis_cluster/redis_26379/conf/redis_26379.conf
6.2.4 配置主从关系
redis02 redis03操作 都需要配置主从关系
#检查一下主从复制的关系,没有配置的话增加SLAVEOF参数(只检查slave2台)
vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
SLAVEOF 192.168.188.159 6379
#启动&检查
redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
ps -ef |grep redis
#检查两台的日志 看状态是否成功
tailf /opt/redis_cluster/redis_6379/logs/redis_6379.log
13862:C 24 Mar 23:04:13.290 * Parent agreed to stop sending diffs. Finalizing AOF...
13862:C 24 Mar 23:04:13.290 * Concatenating 0.00 MB of AOF diff received from parent.
13862:C 24 Mar 23:04:13.290 * SYNC append only file rewrite performed
13862:C 24 Mar 23:04:13.291 * AOF rewrite: 6 MB of memory used by copy-on-write
13832:S 24 Mar 23:04:13.334 * Background AOF rewrite terminated with success
13832:S 24 Mar 23:04:13.334 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
13832:S 24 Mar 23:04:13.334 * Background AOF rewrite finished successfully #证明配置成功.
6.2.5 启动哨兵
#3台都需要操作
redis-sentinel /opt/redis_cluster/redis_26379/conf/redis_26379.conf
ps -ef |grep redis
[root@redis03 redis]# ps -ef |grep redis
root 2854 1 0 15:45 ? 00:00:45 redis-server 127.0.0.1:6379
root 4081 1 0 22:05 ? 00:00:05 redis-sentinel 192.168.188.161:26379 [sentinel]
root 4279 1922 0 22:34 pts/1 00:00:00 grep --color=auto redis
#测试检查一下哨兵日志,是否可以识别到slave; 共计3台做的一主两从,每台上面都会有另外2台的信息.
[root@redis01 conf]# tail /opt/redis_cluster/redis_26379/logs/redis_26379.log
4336:X 24 Mar 23:05:18.327 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
4336:X 24 Mar 23:05:18.332 # Sentinel ID is f9e2ef6e47f9e510f076ac04a98012b39f5439a8
4336:X 24 Mar 23:05:18.332 # +monitor master myredis 192.168.188.159 6379 quorum 2
4336:X 24 Mar 23:05:18.332 * +slave slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.159 6379
4336:X 24 Mar 23:05:18.336 * +slave slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
4336:X 24 Mar 23:05:24.940 * +sentinel sentinel 464edc58a7480062b123a7ff427a1d2e95573d4a 192.168.188.160 26379 @ myredis 192.168.188.159 6379
4336:X 24 Mar 23:05:28.073 * +sentinel sentinel c39a54f22ad1ca5aeed7a6cc1afa2e4281ef9f17 192.168.188.161 26379 @ myredis 192.168.188.159 6379
6.2.6 对比配置文件
配置前
bind 192.168.188.159
port 26379
daemonize yes
logfile /opt/redis_cluster/redis_26379/logs/redis_26379.log
dir /data/redis_cluster/redis_26379
sentinel monitor myredis 192.168.188.159 6379 2
sentinel down-after-milliseconds myredis 3000
sentinel parallel-syncs myredis 1
sentinel failover-timeout myredis 18000
启动后
[root@redis01 conf]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.188.159
port 26379
daemonize yes
logfile "/opt/redis_cluster/redis_26379/logs/redis_26379.log"
dir "/data/redis_cluster/redis_26379"
sentinel myid f9e2ef6e47f9e510f076ac04a98012b39f5439a8 #启动后新增的ID,每台都有
sentinel monitor myredis 192.168.188.159 6379 2
sentinel down-after-milliseconds myredis 3000
sentinel failover-timeout myredis 18000
# Generated by CONFIG REWRITE #以下也是启动后增加的信息
sentinel config-epoch myredis 0
sentinel leader-epoch myredis 0
sentinel known-slave myredis 192.168.188.160 6379
sentinel known-slave myredis 192.168.188.161 6379
sentinel known-sentinel myredis 192.168.188.161 26379 c39a54f22ad1ca5aeed7a6cc1afa2e4281ef9f17
sentinel known-sentinel myredis 192.168.188.160 26379 464edc58a7480062b123a7ff427a1d2e95573d4a
sentinel current-epoch 0
通过查看日志和配置文件,可以看出1主2从的环境配置完成.
6.2.7 哨兵配置文件
###############1.哨兵模式配置参数###################################################
#守护进程模式启动
daemonize yes
#绑定redis监听的主机IP地址.(当前主机IP地址)
bind 192.168.188.159
#默认redis监听的端口
port 26379
#Log文件的保存目录信息
logfile /opt/redis_cluster/redis_26379/logs/redis_26379.log
#数据的保存目录,记住哨兵模式不记录数据,只复制自动故障转移,消息通知,监控
dir /data/redis_cluster/redis_26379
#myredis主节点的别名; ip+端口,判断主节点故障后,至少两个Sentinel节点参与竞选,1主2从模式
sentinel monitor myredis 192.168.188.159 6379 2
#指定Sentinel认为Master已经节点掉线在3000毫秒后进行其他节点竞选master的毫秒数
sentinel down-after-milliseconds myredis 3000
#当master服务挂掉后, 从节点竞选为master后,需要同步数据时候,是1台1台的同步 ,完成后在同步另外1台 ; 1 表示轮询复制
sentinel parallel-syncs myredis 1
#自动故障转移超时时间
sentinel failover-timeout myredis 18000
#########################################################################################
6.3 哨兵常用的命令 API
登录命令:
[root@redis01 conf]# redis-cli -h redis01 -p 26379
redis01:26379>
-p 指定登录到哨兵,默认是6379
INFO Sentinel #查看当前哨兵的信息
Sentinel masters #查看Master具体的信息
Sentinel master #指定查看各节点master信息
Sentinel slaves #查看从节点信息,会显示2台从节点信息状态
Sentinel sentinels #显示哨兵组信息
Sentinel get-master-addr-by-name #显示当前的master节点主机和端口
Sentinel failover #查看自动故障转移状态,手动故障转移
Sentinel flushconfig #刷新哨兵配置
6.4 案例一.Master故障,自动转移
模拟master节点挂掉.
在哨兵模式下,怎么样才会出现故障?
需要知道的是,哨兵模式下,这里配置的是一主两从,当主节点挂掉之后, 从的2个节点自动开始故障转移,开始竞选,在2个之中竞选出来一个主 ,之后从同步竞选后主的持久化数据; 那么当原来的主修复上线后,在哨兵内发现自己已经不是原来的主节点的了 ,经过消息共享后,已经竞选的主告知修复原来是主节点,你已经不是主了,你要同步我的数据,便开始同步了.文字说明太模糊了,看下草图,了解下.

操作示例:
1.master操作:
[root@redis01 ~]# pkill redis
2.slave (160)观察日志
#master节点宕机了.
12114:X 26 Mar 09:13:26.777 # +sdown master myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:26.777 # +sdown sentinel eb8dfb48987a37637c62606d0bd88455244c9793 192.168.188.159 26379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:26.861 # +odown master myredis 192.168.188.159 6379 #quorum 2/2
12114:X 26 Mar 09:13:26.861 # +new-epoch 1
12114:X 26 Mar 09:13:26.862 # +try-failover master myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:26.864 # +vote-for-leader 75c70a0d58755223e74b9cbb2b7a28172c197744 1
12114:X 26 Mar 09:13:26.875 # 360a6a89bc576b150f00e967479851bc8a29c795 voted for 75c70a0d58755223e74b9cbb2b7a28172c197744 1
12114:X 26 Mar 09:13:26.921 # +elected-leader master myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:26.921 # +failover-state-select-slave master myredis 192.168.188.159 6379
#开始故障转移
12114:X 26 Mar 09:13:27.005 # +selected-slave slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:27.005 * +failover-state-send-slaveof-noone slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:27.071 * +failover-state-wait-promotion slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:27.886 # +promoted-slave slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:27.888 # +failover-state-reconf-slaves master myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:27.947 * +slave-reconf-sent slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:28.893 * +slave-reconf-inprog slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:28.893 * +slave-reconf-done slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:28.955 # -odown master myredis 192.168.188.159 6379
12114:X 26 Mar 09:13:28.955 # +failover-end master myredis 192.168.188.159 6379
#转移确立完成
12114:X 26 Mar 09:13:28.956 # +switch-master myredis 192.168.188.159 6379 192.168.188.160 6379
#通告最新主节点
12114:X 26 Mar 09:13:28.956 * +slave slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.160 6379
12114:X 26 Mar 09:13:28.957 * +slave slave 192.168.188.159:6379 192.168.188.159 6379 @ myredis 192.168.188.160 6379
12114:X 26 Mar 09:13:31.992 # +sdown slave 192.168.188.159:6379 192.168.188.159 6379 @ myredis 192.168.188.160 6379
3. slave(161)日志
12138:X 26 Mar 09:13:26.731 # +sdown sentinel eb8dfb48987a37637c62606d0bd88455244c9793 192.168.188.159 26379 @ myredis 192.168.188.159 6379
12138:X 26 Mar 09:13:26.798 # +sdown master myredis 192.168.188.159 6379
12138:X 26 Mar 09:13:26.899 # +new-epoch 1
12138:X 26 Mar 09:13:26.903 # +vote-for-leader 75c70a0d58755223e74b9cbb2b7a28172c197744 1
12138:X 26 Mar 09:13:27.941 # +odown master myredis 192.168.188.159 6379 #quorum 2/2
12138:X 26 Mar 09:13:27.942 # Next failover delay: I will not start a failover before Thu Mar 26 09:14:03 2020
12138:X 26 Mar 09:13:27.979 # +config-update-from sentinel 75c70a0d58755223e74b9cbb2b7a28172c197744 192.168.188.160 26379 @ myredis 192.168.188.159 6379
#收到最新主节点后,同步最新节点
12138:X 26 Mar 09:13:27.980 # +switch-master myredis 192.168.188.159 6379 192.168.188.160 6379
12138:X 26 Mar 09:13:27.980 * +slave slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.160 6379
12138:X 26 Mar 09:13:27.981 * +slave slave 192.168.188.159:6379 192.168.188.159 6379 @ myredis 192.168.188.160 6379
12138:X 26 Mar 09:13:30.986 # +sdown slave 192.168.188.159:6379 192.168.188.159 6379 @ myredis 192.168.188.160 6379
存在的不足:
1.主从切换的过程中会丢数据
2.Redis只能单点写,不能水平扩容
6.5 案例二.Master故障主机上线
其实在自动转移的是,从节点竞选是根据权重id的大小,开始竞选; 手动故障转移是将权重 ID 调大,从节点权重ID调小,这样的话就能实现手动故障转移 .并上线!
权重的概念.
3台ID均为 0 的时候,公平竞选; 当master节点为2的时候,master节点便优先竞选为主; 从2个节点的权重ID是0, 便是从节点了.
设定权重命令.slave-priority
CONFIG GET slave-priority #查看当前主从复制权重值.优先级
CONFIG SET slave-priority 0 #设定优先级,权重
sentinel failover myredis #手动哨兵故障转移
例如: 159 Master节点修复完成l,准备上线 ,还是继续做主节点,操作如下:
第一步: 恢复主master159上线
1.159master恢复上线:
[root@redis01 ~]# redis-se /opt/redis_cluster/redis_26379/conf/redis_26379.conf
[root@redis01 ~]# redis-sentinel /opt/redis_cluster/redis_26379/conf/redis_26379.conf
2. 从节点的日志信息.
[root@redis02 redis]# tail /opt/redis_cluster/redis_26379/logs/redis_26379.log
12114:X 26 Mar 09:27:07.825 # -sdown slave 192.168.188.159:6379 192.168.188.159 6379 @ myredis 192.168.188.160 6379
12114:X 26 Mar 09:27:17.815 * +convert-to-slave slave 192.168.188.159:6379 192.168.188.159 6379 @ myredis 192.168.188.160 6379
12114:X 26 Mar 09:27:20.751 # -sdown sentinel eb8dfb48987a37637c62606d0bd88455244c9793 192.168.188.159 26379 @ myredis 192.168.188.160 6379
#日志可以看出,原来的master主,已经不是主了, 需要同步最新的主的节点是 160.
3.原来的master上线检查,当前最新的主是谁
[root@redis01 ~]# redis-cli -h redis01 -p 26379
redis01:26379> Sentinel get-master-addr-by-name myredis
1) "192.168.188.160"
2) "6379"
#看到最新的主是 160,那么我即热已经恢复 ,我还是继续做主吧
第二步: 设定优先级,调整权重
1.查看当前3台的环境的优先级
[root@redis01 ~]# redis-cli -h redis01 -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"
[root@redis01 ~]# redis-cli -h redis02 -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"
[root@redis01 ~]# redis-cli -h redis03 -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"
#发现全都是100的权重.
设定权重:
1.可以将两个从节点均都设定为0,这样的master159,变优先晋升为主
2.权重不宜设定超过100的值
2.设定2个从节点为0
[root@redis01 ~]# redis-cli -h redis02 -p 6379 CONFIG SET slave-priority 0
OK
[root@redis01 ~]# redis-cli -h redis03 -p 6379 CONFIG SET slave-priority 0
OK
第三步: 强制设定故障转移
1.故障转移需要在哨兵内执行.
[root@redis01 ~]# redis-cli -h redis01 -p 26379
redis01:26379> sentinel failover myredis
OK
2.查看从节点日志160
12114:X 26 Mar 09:56:31.646 # +new-epoch 2
12114:X 26 Mar 09:56:31.925 # +config-update-from sentinel eb8dfb48987a37637c62606d0bd88455244c9793 192.168.188.159 26379 @ myredis 192.168.188.160 6379
12114:X 26 Mar 09:56:31.926 # +switch-master myredis 192.168.188.160 6379 192.168.188.159 6379
12114:X 26 Mar 09:56:31.927 * +slave slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:56:31.927 * +slave slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
12114:X 26 Mar 09:56:41.983 * +convert-to-slave slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
3.查看从节点日志161
12138:X 26 Mar 09:56:31.708 # +new-epoch 2
12138:X 26 Mar 09:56:31.989 # +config-update-from sentinel eb8dfb48987a37637c62606d0bd88455244c9793 192.168.188.159 26379 @ myredis 192.168.188.160 6379
12138:X 26 Mar 09:56:31.989 # +switch-master myredis 192.168.188.160 6379 192.168.188.159 6379
12138:X 26 Mar 09:56:31.990 * +slave slave 192.168.188.161:6379 192.168.188.161 6379 @ myredis 192.168.188.159 6379
12138:X 26 Mar 09:56:31.991 * +slave slave 192.168.188.160:6379 192.168.188.160 6379 @ myredis 192.168.188.159 6379
4.哨兵模式内查看,当前组的成员的信息
redis01:26379> Sentinel get-master-addr-by-name myredis
1) "192.168.188.159"
2) "6379"
#日志中和哨兵中都可以看出,现在的159又晋升为主节点了.这样就完成了,故障修复后上线,晋升主恢复.
第四步: 恢复从的2个节点优先级
为什么要恢复呢? 避免当master159.发生故障后,2台从节点无法开始竞选,产生故障
1.恢复设定原来默认值:
[root@redis01 ~]# redis-cli -h redis02 -p 6379 CONFIG SET slave-priority 100
OK
[root@redis01 ~]# redis-cli -h redis03 -p 6379 CONFIG SET slave-priority 100
OK
2.查看最新优先级
[root@redis01 ~]# redis-cli -h redis02 -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"
[root@redis01 ~]# redis-cli -h redis03 -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"
[root@redis01 ~]# redis-cli -h redis01 -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"