Lesson 003 —— 字符编码
字符编码(英语:Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和ASCII。其中,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以1个字节的方式存储。
ASCII
美国(国家)信息交换标准(代)码,一种使用7个或8个二进制位进行编码的方案,最多可以给256个字符(包括字母、数字、标点符号、控制字符及其他符号)分配(或指定)数值。
ASCII码划分为两个集合:128个字符的标准ASCII码和附加的128个字符的扩充和ASCII码。比较EBCDIC。其中95个字符可以显示。另外33个不可以显示。 标准ASCII码为7位,扩充为8位。
目前使用最广泛的西文字符集及其编码是 ASCII 字符集和 ASCII 码( ASCII 是 American Standard Code for Information Interchange 的缩写),它同时也被国际标准化组织( International Organization for Standardization, ISO )批准为国际标准。
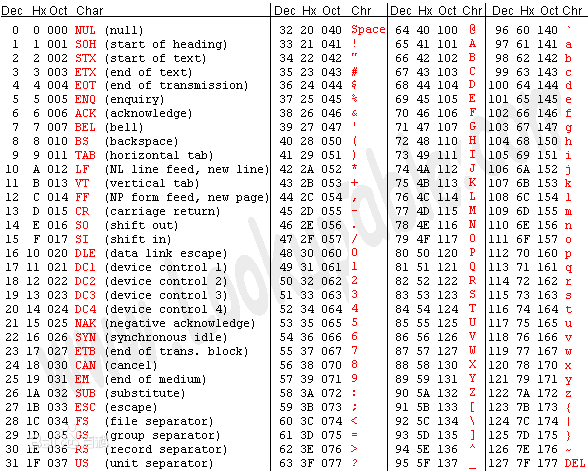
基本的 ASCII 字符集共有 128 个字符,其中有 96 个可打印字符,包括常用的字母、数字、标点符号等,另外还有 32 个控制字符。标准 ASCII 码使用 7 个二进位对字符进行编码,对应的 ISO 标准为 ISO646 标准。
0-31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(振铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10和13分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序而对文本显示有不同的影响。32-126(共95个)是字符(32sp是空格),其中48-57为0到9十个阿拉伯数字,65-90为26个大写英文字母,97-122为26个小写字母,其余为一些标点符号、运算符号等。
ASCII 字符表
MBCS
为了扩充ASCII编码,以用于显示本国的语言,不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码,又称为"MBCS(Muilti-Bytes Charecter Set,多字节字符集)"。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码,所以在中文 windows下要转码成gb2312,gbk只需要把文本保存为ANSI 编码即可。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。一个很大的缺点是,同一个编码值,在不同的编码体系里代表着不同的字。这样就容易造成混乱。导致了unicode码的诞生。
GB2312
GB2312 也是ANSI编码里的一种,对ANSI编码最初始的ASCII编码进行扩充,为了满足国内在计算机中使用汉字的需要,中国国家标准总局发布了一系列的汉字字符集国家标准编码,统称为GB码,或国标码。其中最有影响的是于1980年发布的《信息交换用汉字编码字符集-基本集》,标准号为GB 2312-1980,因其使用非常普遍,也常被通称为国标码。GB2312编码通行于我国内地;新加坡等地也采用此编码。几乎所有的中文系统和国际化的软件都支持GB 2312。
GB 2312是一个简体中文字符集,由6763个常用汉字和682个全角的非汉字字符组成。其中汉字根据使用的频率分为两级。一级汉字3755个,二级汉字3008个。由于字符数量比较大,GB2312采用了二维矩阵编码法对所有字符进行编码。首先构造一个94行94列的方阵,对每一行称为一个“区”,每一列称为一个“位”,然后将所有字符依照下表的规律填写到方阵中。这样所有的字符在方阵中都有一个唯一的位置,这个位置可以用区号、位号合成表示,称为字符的区位码。如第一个汉字“啊”出现在第16区的第1位上,其区位码为1601。因为区位码同字符的位置是完全对应的,因此区位码同字符之间也是一一对应的。这样所有的字符都可通过其区位码转换为数字编码信息。
GB2312 字符编码分布表
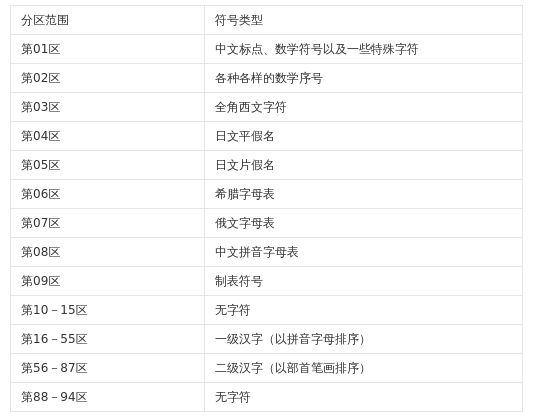
GB2312字符在计算机中存储是以其区位码为基础的,其中汉字的区码和位码分别占一个存储单元,每个汉字占两个存储单元。由于区码和位码的取值范围都是在1-94之间,这样的范围同西文的存储表示冲突。例如汉字‘珀’在GB2312中的区位码为7174,其两字节表示形式为71,74;而两个西文字符‘GJ’的存储码也是71,74。这种冲突将导致在解释编码时到底表示的是一个汉字还是两个西文字符将无法判断。
为避免同西文的存储发生冲突,GB2312字符在进行存储时,通过将原来的每个字节第8bit设置为1同西文加以区别,如果第8bit为0,则表示西文字符,否则表示GB2312中的字符。实际存储时,采用了将区位码的每个字节分别加上A0H(160)的方法转换为存储码,计算机存储规则是此编码的补码,而且是位码在前,区码在后。例如汉字‘啊’的区位码为1601,其存储码为B0A1H,其转换过程为:
| 区位码 | 区码转换 | 位码转换 | 存储码 |
|---|---|---|---|
| 1001H | 10H + A0H = B0H | 01H + A0H = A1H | B0A1H |
GB2312编码用两个字节(8位2进制)表示一个汉字,所以理论上最多可以表示256×256=65536个汉字。但这种编码方式也仅仅在中国行得通。
GBK
GBK即汉字内码扩展规范,K为扩展的汉语拼音中“扩”字的声母。英文全称Chinese Internal Code Specification。GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。GB2312码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集-基本集》,1980年由国家标准总局发布。基本集共收入汉字6763个和非汉字图形字符682个,通行于中国大陆。
GBK采用双字节表示,总体编码范围为8140-FEFE,首字节在81-FE 之间,尾字节在40-FE 之间,剔除 xx7F一条线。总计23940 个码位,共收入21886个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号883 个。P-Windows3.2 和苹果 OS 以 GB2312 为基本汉字编码, Windows 95/98 则以 GBK 为基本汉字编码。
GBK码对字库中偏移量的计算公式为:
[(GBKH - 0x81) * 0xBE + (GBKL - 0x41)] * (汉字离散后每个汉字点阵所占用的字节)
编码方式:
字符有一字节和双字节编码,00–7F范围内是一位,和ASCII保持一致,此范围内严格上说有96个字符和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。、
Big5
为统一繁体字符集编码,1984年,台湾五大厂商宏碁、神通、佳佳、零壹以及大众一同制定了一种繁体中文编码方案,因其来源被称为五大码,英文写作Big5,后来按英文翻译回汉字后,普遍被称为大五码。
大五码是一种繁体中文汉字字符集,其中繁体汉字13053个,808个标点符号、希腊字母及特殊符号。大五码的编码码表直接针对存储而设计,每个字符统一使用两个字节存储表示。第1字节范围81H-FEH,避开了同ASCII码的冲突,第2字节范围是40H-7EH和A1H-FEH。因为Big5的字符编码范围同GB2312字符的存储码范围存在冲突,所以在同一正文不能对两种字符集的字符同时支持。
Big5字符主要部分集中在三个段内:标点符号、希腊字母及特殊符号;常用汉字;非常用汉字。其余部分保留给其他厂商支持。
Big5 字符编码分布表
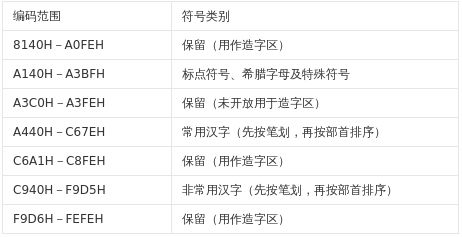
Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
UTF-8
事实证明,对可以用ASCII表示的字符使用UNICODE并不高效,因为UNICODE比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。常见的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。
UTF-8编码规则:如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。
UTF-8 转换表
| Unicode/UCS-4 | bit 数 | UTF-8 | byte 数 | 备注 |
|---|---|---|---|---|
| 0000 - 007F | 0 - 7 | 0XXX XXXX | 1 | |
| 0080 - 07FF | 8 - 11 | 110X XXXX 10XX XXXX | 2 | |
| 0800 - FFFF | 12 - 16 | 1110XXXX 10XX XXXX 10XX XXXX | 3 | 基本定义范围:0~FFFF |
| 1 0000 - 1F FFFF | 17 - 21 | 1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX | 4 | Unicode6.1定义范围:0~10 FFFF |
| 20 0000 - 3FF FFFF | 22 - 26 | 1111 10XX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX | 5 | 说明:此非unicode编码范围,属于UCS-4 编码。早期的规范UTF-8可以到达6字节序列,可以覆盖到31位元(通用字符集原来的极限)。尽管如此,2003年11月UTF-8 被 RFC 3629 重新规范, |
| 400 0000 - 7FFF FFFF | 27 - 31 | 1111 110X 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX | 只能使用原来Unicode定义的区域, U+0000到U+10FFFF。根据规范,这些字节值将无法出现在合法 UTF-8序列中 |
实际表示ASCII字符的UNICODE字符,将会编码成1个字节,并且UTF-8表示与ASCII字符表示是一样的。所有其他的UNICODE字符转化成UTF-8将需要至少2个字节。每个字节由一个换码序列开始。第一个字节由唯一的换码序列,由n位连续的1加一位0组成, 首字节连续的1的个数表示字符编码所需的字节数。
Unicode转换为UTF-8时,可以将Unicode二进制从低位往高位取出二进制数字,每次取6位,如上述的二进制就可以分别取出为如下示例所示的格式,前面按格式填补,不足8位用0填补。