1. 为什么会提出因果关系计算法
在文章的开始,我们来讨论一个话题:哪些药一起服用会产生不良反应?
针对这个问题,传统的观察法和分析法做法可能如下:
- 用随机试验来测试药品,但是这种方法并不能给我们提供多少信息,因为这些试验往往会避免让参与者同时服用多种药物
- 用模拟实验来预测药物之间的相互作用,但是这样的实验需要有大量的背景知识才能完成
- 用实验的方法对一些药物组合之间的相互作用进行测试,但考虑到这种实验需要的成本和时间,它可能只适用于少数几种可能的药物组合
上述这些方法的共同缺点就是:实际操作层面比较复杂、费力,不能通过计算机自动化完成。
例如笔者在上篇文章中讨论的观察法,其用于理论研究方面是没有问题的,但是一旦要将其用于工程实践,就显得捉襟见肘了。
为了解决这个问题,学者提出了计算法,计算法本质上是一种数据挖掘驱动、从海量数据中自动寻找因果关系的有效方法。
举个例子来说,
以美国为例,一种药物上市之后,一些疑似不良反应的事件会被病人、制药公司和医疗服务机构报告给食品及药品管理局(FDA),并被输入数据库。如果某人服用了一种抗过敏药物,几天后心脏病发作了,那么他或者他的临床医师就可以把这一情况报告给FDA。
当然,这些报告里所说的情况通常都是未经证实的。可能某个人的心脏病发作实际上是与药物无关的血块引起的,但仅仅是由于最近有新闻报道说出现了很多起药物引发心脏病的事件,因此将这个人的心脏病发作解释为该药物引发的不良反应似乎就很合理了。
很多情况都可能会导致数据出现虚假的因果关系。例如:
- 病人身上可能还有其他疾病引发了心脏病,比如未诊断出的糖尿病
- 数据本身也可能会出问题,比如样本被污染了或者症状被误诊了
- 事件发生的顺序可能因为观测原因被搞错了,比如心脏病是在吃药前就发生了
- 数据收集不完整,很多真正的不良反应可能并未报告给FDA,因为人们可能认为这些不良反应并不是服药引起的
即便有些报告所说的情况是错的,它们仍然可以帮助我们形成新的有待检验的假设。如果我们想要通过实验来验证这些不良反应,比如让一组病人服用各种药物组合,或者让每个病人分别服用每种药物,那我们可能要耽误很长时间才能找到这些药物之间的相互作用,从而导致更多病人可能出现药物不良反应。
相反,如果使用另一组来自医院的观察数据,我们就能准确地知道病人服用某种药物组合后会出现什么情况。当然,我们无法确定病人有没有服用医院给他们开的药,也无法确定同时服用两种药物的病人和其他病人有没有什么不同。
尽管这种类型的观测数据存在很多局限性,但是和传统观察法相比,计算法最大的优势是对先验领域知识的要求很低,我们不强制需要从某个具体的因果假设出发,然后再对这个假设进行评估,而是可以直接从数据中自动发现某种因果关系。
通过将计算能力和从数据中有效发现原因的各种方法进行结合,我们对数据的分析已经不再是一次只考察一个因果关系,而是通过对数据的挖掘同时揭示多种因果关系。
通过这些自动化的方法,我们还可以发现很多人们无法直接观察到的更加复杂的关系,比如,我们可能会发现一个让病人在中风后恢复意识的、由多个步骤(每个步骤又包含多个必要组成部分)组成的事件序列。
2. 什么样的数据适合用来推理因果关系 -- 因果结构搜索的假设前提
在考察推理方法之前,我们还要讨论一下使用这些方法需要输入的数据内容。这里所说的数据可能是指随时间变化的事件序列,比如一只股票价格每天发生的变化,也可能是指某个时间点上的事件序列。
不同的研究方法假设出的数据也有所不同,但有些特征几乎对所有研究方法都是一样的,而且这些特征还会影响我们从数据中得出的结论。
0x1:无隐藏的共同原因假设
1、共同原因假设原理
一个最重要且最普遍的假设就是:我们已经测量了正在进行因果推理的变量中的所有共同原因。这在图示模型法中也被称为因果关系的充分性。如果想要从一组变量中找出原因,那么我们必须确保测量了这些变量中的所有共同原因。
如果咖啡因是真正导致睡眠不足与心率上升的原因,而且这也是睡眠和心率之间的唯一底层联系,那么如果我们不测量咖啡因的摄入量,可能就会得出错误的结论,在咖啡因导致的两个结果(睡眠不足和心率上升)之间找到联系。
数据中缺少的原因叫做潜在变量,两个或两个以上的变量之间未测量到的原因可能会导致人们做出错误的推理,这样的原因被称为隐藏的共同原因或潜在的混杂因子。而由此导致的问题被称为混杂和遗漏变量偏差。
共同原因发现不足是观察性研究的主要局限之一,也是大多数计算法输入内容的主要局限之一。它不仅会导致人们在变量之前发现错误的联系,还会导致人们高估原因的强度。
2、共同原因和非共同原因对因果关系发现的影响
注意!我们并不一定非要假设每一个原因都要测量到,我们只需要测量那些共同的原因,如下图所示:

上图中,咖啡因不仅引起了睡眠的变化,还引起了心率的变化,它是心率和睡眠的共同原因。而白酒仅仅引起了睡眠的变化。如果没有白酒摄入量的数据,那么我们将无法找到引起睡眠变化的原因,但也不会因此就在其他变量之间(心率和睡眠)找到错误的关系。因为只要咖啡因的观测是完整的,即使白酒的观测不完全,至少我们会得出以下几个结论:
- 心率和睡眠之间不存在因果关系
- 心率和咖啡因之间存在因果关系
3、因果关系链中的间接原因缺失问题
还是继续上面咖啡因的例子,如果咖啡对睡眠的影响是通过一个中间变量(代理变量)引起的,它们之间的关系是咖啡因引起心率上升,而心率上升又导致睡眠减少,如下图所示:
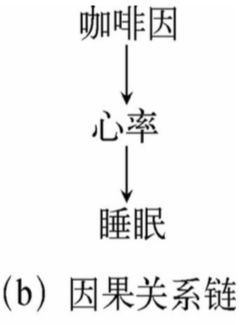
如果我们不测量心率,最多只会找到一个间接的原因,而不是一个完整的因果结构。
4、如何规避共同原因缺失问题
为了规避有共同原因没有被测量到的情况,有一种可行的方法是找到与我们的观测数据一致的所有可能的模型,包括那些带有隐藏变量的模型。
比如说,如果我们在睡眠和心率之间发现了一个表面上的因果关系,并且知道这两个变量之间可能存在某些未测量到的共同原因,那么一个可能的模型就会包含一个能够引起这两个观察到的变量的隐藏变量。
这种方法的好处在于,所有能够解释这些数据的模型之间可能会存在一些共同的联系,这样一来,即便存在多种可能的因果结构,我们依然能够找出一些可能的联系。
0x2:典型分布假设
除了要确保找到了正确的变量集,我们还需要确保观察到的内容反映了观察对象的真实行为,这就是信息论中的充分统计量理论。
例如:
- 如果我们要考察【有没有报警系统,是导致抢劫案发生的原因】,那么我们的数据需要确保抢劫案的发生完全依赖于是否安装了报警系统,如果还有其他的依赖原因没有观测到或者没有被纳入考察范围,就会导致因果关系结构的错乱,这就是变量缺失问题。
- 如果我们要考察【学习时间,是SAT成绩的原因】,那么我们的数据需要确保覆盖了所有学习时间的学生的SAT成绩,否则就会出现我们在这篇文章里讨论过的抽样偏差问题,由于样本缺乏变化,我们可能无法找到事物之间的真正关联
- 如果我们要考察【跑步时间,是体重下降的原因】,那么我们要注意,跑步和体重下降之间存在两种关系,一种是跑步对体重下降有积极影响,另一种是跑步对体重下降有消极影响,因为跑步后会增大食欲和促进吸收。如果搜集到的数据分布得不好,因为这种抵消关系的存在,我们可能会错误地发现跑步和体重下降之间没有任何关系
- 如果我们要考察【某基因的表达,是某种生物显性特征的原因】,就会遇到所谓的优先权问题。当很多基因都能产生同一种显性特征时,即便我们让其中一个基因不起作用,这个显性特征依然会出现,这是很多具备自平衡能力的生物体都会具备的特征。这种现象会导致我们错误地发现原因和结果之间似乎并不存在因果依赖性
- 如果我们要考察【硬币是否有做手脚的的问题】,我们只抛10次硬币就是不够的,在小数的实验次数下很可能会出现罕见事件,只有在抛硬币次数接近无穷次时,实验结果才会真实地反映该硬币背后的真实概率分布。如果该硬币是一个标准硬币,那么正面朝上和反面朝上的次数比例会接近1:1。这就是大数定律问题。
- 如果我们要考察【能够判定一个文本文档是恶意文档的原因】,那么就要求我们能够获取到完全的“恶意样本全集”,这在理论上是合理的,但在实际工程中是很难做到了,恶意样本本质上是基于一种编程语言规范的无限字符串组合,总量和类别都是无限的
辛普森悖论表明,根据考察数据的不同(整体数据或小群体数据),会发现不同的因果结构。
因果推理取决于真实的依赖性关系,我们通常要假设我们观测到的数据是满足典型分布特性的,这种假设被称为忠实性原则,因为那些不能反映真正的潜在因果结构的数据在某种意义上是“不忠实的”。
0x3:稳定系统假设
上一节说道的典型集假设,我们在进行因果推理时往往会做出这样的假设:假设我们有足够多数据,假设我们看到的是由某个原因引起的某个结果出现的真正概率,而不是一个异常现象。
但是要注意的是,对于有些系统(比如那些非稳定性系统)而言,即便是一个无穷大的数据集也无法满足这个假设的要求。
例如,像股票平均收益这种时间序列数据,它本身是不稳定的,或者说系统本身可能就不具备任何可预测的规律性存在。这种情况下,我们不应该从观测数据中发现任何因果关系。
所以一般情况下,在进行因果推理前,我们必须假设这些关系是不会随着时间的变化而变化的
0x4:正确变量假设
对于因果推理活动来说,我们首先要确保我们测量了正确的事物,
- 如果我们手上掌握的是金融市场的数据,那我们研究的变量可能就是各个股票
- 如果在政治学领域,那我们研究的变量可能是竞选捐款额和通话量
- 如果在入侵检测领域,那我们研究的变量可能是表示服务器运行指标的各种统计量
- 对于共生多原因导致某结果的问题,单独考察单个变量可能无法找到任何关系,但如果同时考察所有的共生变量,则可能可以找到这种因果关系
我们不仅需要测量正确的事物,还需要确保描述这些事物的方式是正确的。例如,在某些研究中,肥胖症和肥胖可能属于一个类别,合在一起统计就行。但是对于那些致力于治疗肥胖症患者的研究来说,对肥胖症和肥胖的区分,就至关重要了。
0x5:时序不变性假设
如果变量之间的关系是随着时间而变化的,那么就可能出现这样的情况。变量在时间序列的一个时间段里是相互独立的,但在另一个时间段里却不尽然。在这种情况下,尽管变量之间的关系在一段时间内可能很强,但是当我们考察整个时间段,变量之间的关系可能会显得很弱。
3. 图解模型 -- 找到一个模型来了解数据中所有的因果关系
0x1:什么是图解模型
为了向别人描述某个因果关系,或者为了理解各个事物是如何组成一个整体的,我们常常会画一张因果结构图。
下面这个图形展示的是一个变量出现的概率是如何受另一个变量影响的。
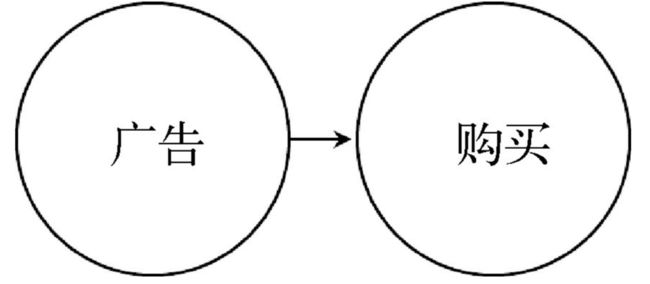
这个图告诉我们以下几点信息:
- 广告和购买行为之间存在某种关系
- 广告和购买行为之间的关系是单向的,即广告影响购买行为,而不是购买行为影响广告
接下来看另一个因果概念图:
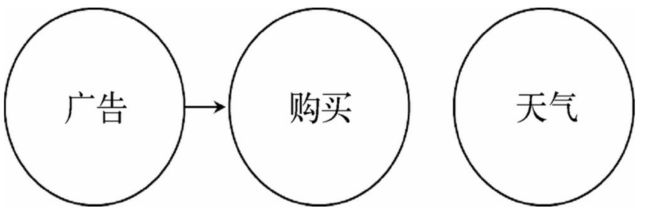
这个图告诉我们以下几点信息:
- 广告和购买行为之间存在某种关系
- 广告和购买行为之间的关系是单向的,即广告影响购买行为,而不是购买行为影响广告
- 天气和购买不存在任何关系,我们不能用天气影响或预测购买行为
0x2:图解模型能够表示因果关系的条件
尽管我们可以用图形来表示因果关系,但这并不意味着我们绘制的或者知道的每一个图解模型表示的都是因果关系。一个图解模型要能够具备表示因果关系,需要具备以下几个条件:
- 因果关系中的马尔可夫条件:一个变量的概率只取决于引起这个变量的原因
- 充分性原则:所有共同的原因都要测量到
- 忠实性原则:所使用的数据准确地反映了变量之间真正的依赖关系
- 变量描述正确性原则:变量的描述必须正确
- 典型集原则:观测数据的概率分布要保证充分性
1、充分性原则
假设广告不仅能够引起购买行为,还能提高品牌认知度,
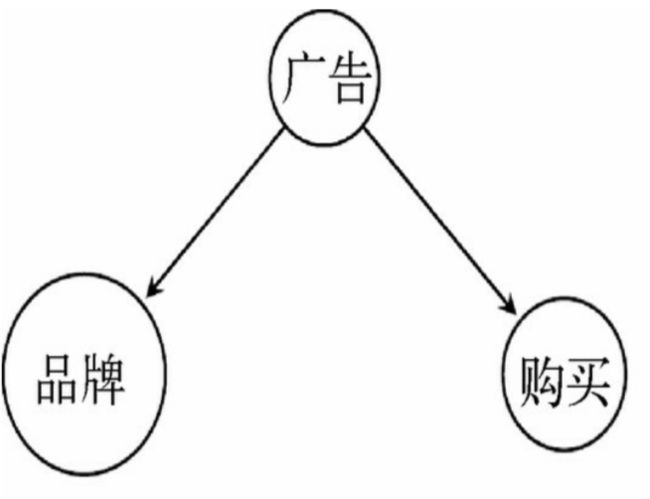
如果我们没有用来表示广告的变量,还要试图从一组数据中推理出变量之间的关系,那我们可能会发现如下图所示的图形,
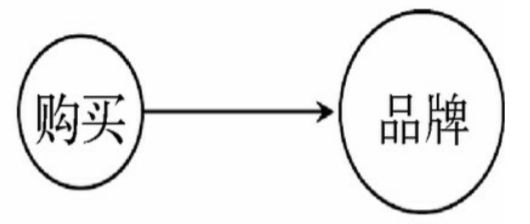
这会让我们错误地认为购买行为提高了品牌认知度,而实际上,这是一个伪因果性。
一般来说,任意数量的变量中都可能有一个共同的原因,如果这个原因没有被测量到的话,我们就无法保证由此推理出的关系是正确的。
另一种复杂的情况是出现决定性关系。比如说,每收到一封电子邮件,我的电脑都会发出声响,而电脑的声响又会让我的狗汪汪乱叫。
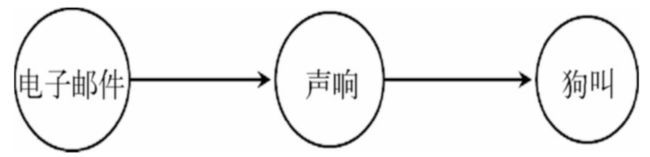
如果在出现声响的情况下,狗叫的概率为1,而在出现电子邮件的情况下,电脑发出声响的概率也为1。
尽管从图解模型图上,我们可以看到电子邮件和狗叫应该是相互独立的。但是如果仅从观测结果上,我们可以会错误地推导出电子邮件是声响和狗叫的共同原因,因为电子邮件的出现,都会100%伴随声响和狗叫的出现。
事实上,这个问题不仅是图示模型中存在的问题,也是大部分概率法中的一个难题。
2、变量描述正确性原则
如果广告变量表示的是“是否在电视台购买了广告空间”,但真正的原因却是“消费者看到广告的次数”,这可能会导致我们无法找到真正的因果关系。
3、忠实性原则
一个贝叶斯网网络包括两部分:
- 结构:各个变量之间的连接方式
- 条件性概率分布组合:这些组合不过是一些表格,这些表格让我们能够在给定原因变量值(真或假)出现的概率。例如广告和购买行为的例子:
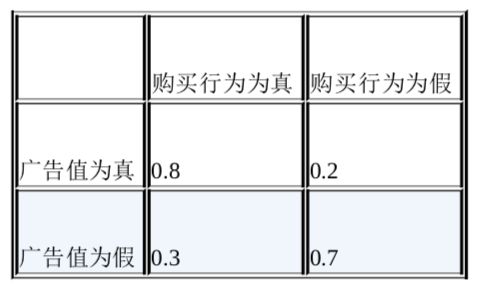
对于贝叶斯网络中的每一个节点来说,我们都会有一个类似的表格。知道这个网络结构信息可以极大地简化我们的计算工作,因为每一个变量的值都是由其父级元素决定的。
相反,如果我们对变量之间的联系一无所知,就不得不将每一个变量都包含到表格的每一行之中。如果存在 N 个可以为真或为假的变量,那么我们就会有 2N 行。
我们既可以从数据中了解变量之间的结构和各个变量出现的概率,也可以根据我们了解的信息构建一个结构,以此来了解各个变量发生的概率。
4、因果关系中的马尔可夫条件
只要知道一个变量的直接原因就能够预测这个变量,这个前提条件被称为因果关系中的马尔科夫条件。
在变量的直接原因已经给定的情况下,变量是独立于它的非衍生物的(衍生物指的是由变量导致的结果,以及由这些结果导致的结果,等等)。
这在贝叶斯网理论中被称为tail-to-head(证据迹),可以抽象为下图所示的结构:

这种结构代表的意思是:
- c未知时:影响可以经过c从a流向b,a可以作为证据影响b的后验概率
- c已知时:在c给定的条件下,a,b被阻断,是独立的。
还是用广告投入的例子来说明,
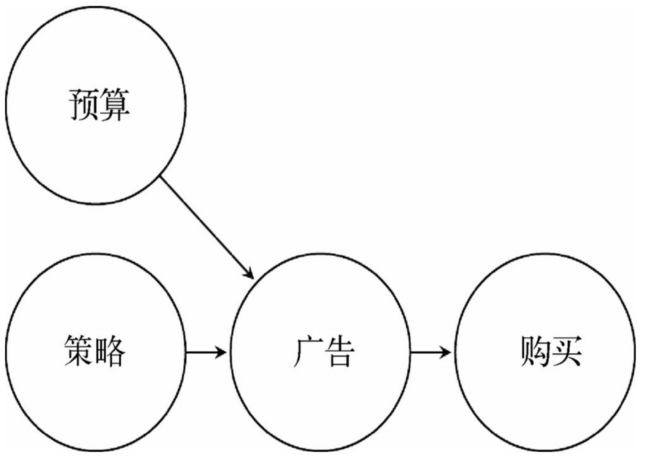
如果营销策和预算只能通过广告来影响购买行为,那么购买行为的发生概率则只取决于广告,广告是导致购买行为的直接原因。
一旦广告这个值确定了,那么其他的原因将不再重要了,换句话说,广告已经提供了预测购买结果的所有信息,除此之外,不再需要其他信息。所有的原因对购买行为的影响都要通过广告来实现。
从理论上说,如果我们能直接干预广告活动,那么无须对营销策略或预算做任何调整也能让购买行为发生变化,因为购买行为完全是由我们设定的广告值决定的。
0x3:从数据自动推理得到概率图形
1、将概率图示模型搜索问题转化为目标函数最优化问题
假设我们有一些关于某个公司雇员情况的数据,我们知道:
- 他们的工作时间
- 休假信息
- 部分生产指标
接下来的问题是,如何自动化地找到这些因素之间存在的因果关系网络呢?这个问题的本质上是,如何在所有的因果关系网络集合中,寻找到一个或一批和观测数据最匹配的拓朴结构(最大似然思想)。
显然,这个问题是一个最优目标搜索问题,那我们就可以借用优化理论里的目标函数优化理论来解决这个问题。
我们可以找一个指标来衡量一个模型对数据的描述能力,然后搜索可能的模型,找到在这个指标下得分最高的模型。这种方法叫作搜索评分法。
如果休假导致生产力提高是这个数据的唯一关系,那么带有这样一个(从休假指向生产力)的箭头的模型应该比包含其他关系的模型得分高,
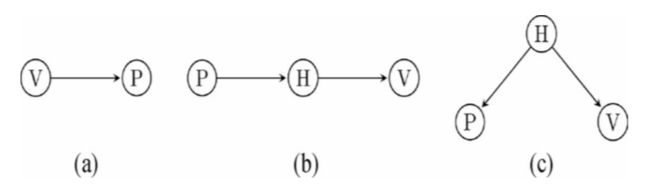
如果实际情况是 V(休假) 导致 P(生产力),那么第一个图形的得分应该是最高的
具体到操作层面,要想从候选模型中做出最优选择,我们还需要用一个方法来计算哪个图形与数据更相符。
用来评分的函数有很多,但从根本上来说,除了要避免将图形和特定数据集中的噪声过拟合,我们对数据的描述程度也存在一个平衡点。我们可以通过一个非常复杂的结构来完美解释数据集中的每一个点,但我们想要找到一个模型来描述各个变量之间更为普遍的关系(即泛化能力),而不是解释数据中的每一处噪声。
因此,当图形变得越来越复杂时,搜索空间会变得十分巨大。只要25个变量,我们得到的所有可能图形的数量(超过10110)就会让宇宙中所有原子的数量(估计只有1080)相形见绌。
没有任何方法能让我们一一测试这些图形,我们必须寻找一个相对聪明的搜索策略,高效地进行拓朴搜索。
2、启发式因果拓朴搜索方法
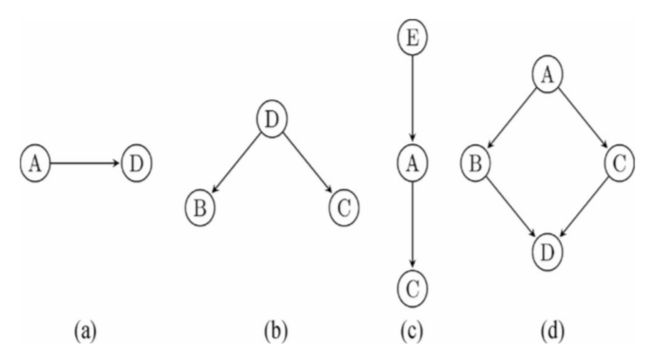
假设我们一一测试了上图中的前三个图形,然后发现(c)的得分最高。接下来最好的策略是去研究与这个图形相近的其他图形,而不是随机想出第四个图形。
我们可以增加一个箭头、改变箭头的方向或者删除一个箭头,来看看图形的得分是如何变化的。这种方法本质上是一种启发式搜索的思想。
这种启发式搜索有存在很大的问题,就是“容易陷入局部最优”,因为也有可能最好的图形其实是(d),但由于我们使用了启发式策略,一直在优化第三个图形,并且在找到真正的结构之前就已经停止了测试工作,所以我们永远也没有机会测试到第四个图形。
但是如果我们不能测试到每一个图形,就无法确保最好的图形已经被测试了。
局部最优化陷阱
3、引入先验知识的拓朴搜索方法
先验知识可以简化待搜素的拓朴空间,如果我们知道性别只能是原因而绝不会是结果,那就可以避免测试所有将性别当做结果的图形。
如果我们对要寻找的结构有一定的先验了解,那么就能为整个图形组合设计出一个概率分布图,并且可以用它来引导我们找到那些更有研究价值的各种可能的结构。
4、基于约束法的拓朴搜索方法
除了采用更优秀的搜索方法去搜索海量的潜在图像集之外,我们还可以使用变量之间的依赖性来建构那个得分最高的图形。约束法就是这样一种搜索方法。
约束法通过不断重复测试变量之间的独立性,并在测试结果中增加、减少图形中的箭头,或者改变图形中箭头的方向。
- 其中有些方法是每次增加一个变量
- 还要一些方法一开始就已经将所有变量连接在一起,然后再一个一个地删除箭头
这其实就是贝叶斯网中的局部独立性假设,基于局部独立性假设,我们可以大大化简贝叶斯图的复杂拓朴结构,从而简化节点间的条件概率计算。
以下图为例,
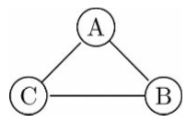
如果我们发现在给定 C 的情况下,A 和 B 是相互独立的,那么就可以删除它们之间的连线,然后继续寻找变量之间的其他关系,看看还能删除哪些连线。
在真实的工程实践中,我们会发现变量之间完全相互独立的可能性不大,或多或少都会有一些相关性。而我们需要判断的是,应该在什么时候接受或拒绝变量之间相互独立的假设。
如果在给定B的情况下,A出现的概率和A本身出现的概率完全一样(即互信息为零),那么这两个变量之间就是相互独立的。
在实际研究中,我们需要选择一个统计学上的门槛(临界值),来决定是否接受基于这些测试而提出的条件独立性结论。
4. 因果衡量模型 -- 重点对每一个关系的强度进行分别评估的方法
0x1:因果衡量模型原理及优缺点
因果衡量模型,并不要求寻找一个与数据一致的或者能够对数据做出完美解释的图解模型,因果衡量模型更多地是侧重于研究局部,它主要研究的是量化各种因果关系强度的问题。例如:
- 如果休假可以提高生产力,但生产力不能导致休假,那么休假作为提高生产力的原因的强度应该很高;
- 反之,生产力提高作为放假的原因的强度应该很低
尽管相关性是对称的,但在衡量因果关系的显著性时,需要利用这些关系中的非对称性特征。在某种意义上,因果关系的显著性应该与原因对结果的解释程度相称,与原因作为一种干预手段能够带来某种结果的有效程度也相称。
如果休假只能偶尔提高生产力,而加班总是能够提高生产力,那么作为生产力提高的原因,加班的强度要高于休假的强度。
如果休假能够提高生产力的原因只是因为休假可以让员工在这家公司待得久一些,且有经验的员工的生产力更高,那么我们想要知道的是,经验对于提高生产力的重要性是否高于休假。也就是说,我们想要发现最直接的原因,这些原因在图形中是直接父级原因,而不是更遥远的祖父级原因。
如果可以用一种方法,以完全独立于其他任何无关变量的方式,去单独评估生产力提高的原因(局部评估),那么我们可以做更少的测试,并且可以同时进行这些测试,从而大大提高计算这些事情的计算程序的速度。
这种方法的局限性在于,如果没有一个结构来展示所有变量之间的联系,我们可能无法直接使用这些结论来进行预测。
假设我们发现党派的支持会让参议员们投票支持某些法案,而这些参议员所属选区选民的支持也会起到同样的效果。因果衡量模型并没有告诉我们这两种方案是如何相互作用的,也没有告诉我们如果这两种支持相加,是否会导致参议员支持某个法案的决心更强。
要想解决这个问题,可以去寻找更为复杂的关系,我么并不是要使用所有测量过的变量,而是要去建立各种联系(政党和选民对提案的支持的复合因果关系结构),而这往往是需要借助贝叶斯网那样的理论体系才能较好地解决的。
0x2:概率与因果关系的显著性
在给定原因的情况下,某个结果出现的条件性概率也可以用来衡量原因的显著性。
衡量原因强度的方法有很多,但这些方法的基本理念都是要以某种方式吸收其他信息来解释这些共同的原因,即信息论中的互信息概念。
例如,如果在休假和加班这两个变量都为真时,生产力提高的概率为 X%,而只有加班这一个变量为真实,生产力提高的概率也为 X%,那么知道休假信息也并不能提升我们预测生产力提高这一事件出现概率的准确性。换句话说,休假信息并不能为确定生产力提高这个结果提供更多的信息。
因此,要想量化某个原因的显著性,我们可以计算这个原因平均在多大程度上影响了其结果出现的概率。简单来说,就是在其他因素保持不变的情况下,这个原因出现和未出现时某个结果出现的概率会有多大的变化。
可以将各种情况出现的概率进行加权计算。如果在一个非常普遍的情况下,一个原因可以显著地提高某个结果出现的概率,那么这个原因的显著性比那些只在极少数情况下才能提高某个结果出现概率的原因要大得多。
要注意的是,因果衡量模型,同样也需要遵循前面讨论过的“因果结构搜索的假设前提”,这里不再赘述。
另一方面,由于在实践中总会出现一些噪声、失误和数据缺失的情况,所以我们不能假定不是原因的事物的显著性指标的值就一定为零。相反,我们经常需要确定哪些因果显著性指标的值具有统计意义。
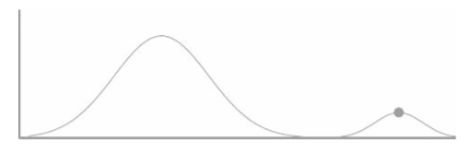
比如说,有很多变量可能是某些变量的原因,但是它们之间又没有真正的因果关系,我们在计算这些变量的因果显著性指标的平均值时,会发现这些显著性值的分布看起来就像一个钟形曲线,就像吐下图中的灰色柱状图,
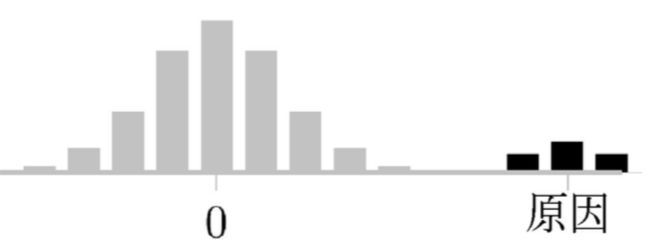
而当测试的数据集中存在一些真正的因果关系时,这些显著性会分布成另一种图形,例如上图中的黑色柱状图部门。
我们可以利用这种差异来判断显著性指标的哪些值应该被看成是具有因果关系的值。
0x3:因果关系的显著性计算方法
1、基于时间窗口的统计性方法
在有些计算因果关系的显著性方法中,可以在原因和结果之间指定一个时间间隔或时窗,以便计算原因的显著性。
如果与流感病人亲密接触后,接触者会在1-4天后出现流感症状,那么4天这个统计时间窗口,就能让我们计算出二者之间的因果显著性。
如果这种方法的问题在于,如果我们对引起流感的原因一无所知,怎样才能知道需要测试多大的时窗呢?如果我们测试的时间窗不对,我们可能就会错误一些真正的原因,或者只能找到真正窗的一个子集或超集。
在下图中,我么测试的时窗与真正的时窗重合了一部分,但也有不一样的地方,
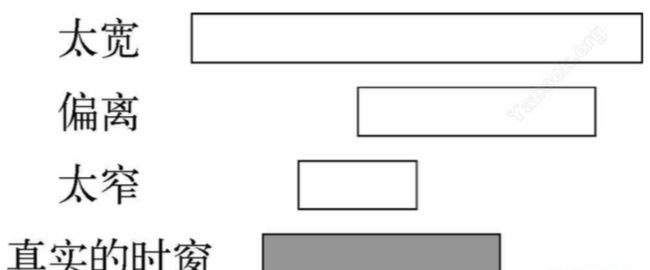
- 如果测试的时窗太长,那么就会出现很多这样的情况:我们很期待某个结果出现,但是这个结果却没有出现。由于在原因为真的情况下结果并未出现,所以这些案例会对原因的显著性值造成不利影响
- 如果测试的时窗太窄,那么即便测试的潜在原因没有出现,某个结果可能也会出现。
- 随着测试时窗与真实时窗越来越接近,显著性值也会变大,并且最终会与真实的显著性值相一致
5. 还有什么自动因果发现方法?
因果推理的方法不止一种,目前还没有哪一种方法能够在所有案例中都准确无误地找到事件之间的因果关系。有些方法得出的结论更具普遍性,但是这些结论取决于那些实际上不一定为真的假设。只用一种因果搜索方法来解决问题都是不可行的,我们需要的是一个工具箱。
没有一种方法是完美的,所以一定要了解每一种方法的局限性,例如:
- 如果你的推理是建立在双变量格兰杰因果关系基础之上的,那么你应该意识到,你找到的只是一种单向相关性,同时还应该考虑一下多变量的方法
- 如果因果结构是已知的,而我们想要从一些数据中找出这个结构的各种参数(概率分布),这时贝叶斯网也许是一个很好的选择
- 如果时间是其中一个重要变量,那么使用动态贝叶斯网可能更合适
- 如果数据中包含大量变量,或者我们并不需要找出完整的关系结构,那么用于计算因果关系强度的方法比推理因果模型的方法的效率要更高