所有代码均在本地编译运行测试,环境为 Windows7 32位机器 + eclipse Mars.2 Release (4.5.2)
2016-10-17 整理
- 字符,字符串类问题
- 正则表达式问题
- Java字符编码问题
- 字符串内存问题
简述String和StringBuffer、StringBuilder的区别?
比较初级的一个题目,而初级题目又是除高端职位外,笔试题海量筛人的首选,但是作为经典题目,还是入选了我的笔记,因为它能延伸的Java字符串的问题太多了……另一种延伸的高端问法就是套路你,因为这个题100%会回答多线程的知识点:前者是线程安全的,后者是非线程安全的。然后他们就问什么是线程,或者说进程和线程的区别,为什么有线程?它如何实现的线程安全,接下来稍微高端的就引入Java并发的问题……呵呵。闲言少叙,看几个此类不同难度的系列问题。
下面的代码发生了什么?
String s = "abcd";
s = s.concat("ef");
String是final的,字符串对象内部是用final的字符数组存储的,故String是有字面量这一说法的,这是其他类型所没有的特性(除原生类型)。另外,java中也有字符串常量池这个说法,用来存储字符串字面量。可以画一个图表示:
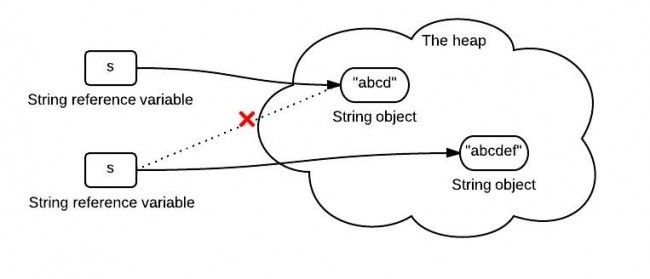 String 类的操作本质是产生了新的 String 对象,给人假象:好像是字符串被改变了似的。
String 类的操作本质是产生了新的 String 对象,给人假象:好像是字符串被改变了似的。
String和StringBuffer、StringBuilder三者的类图(或者选择题:类的关系)是怎样的?
我们先要记住:

String、StringBuffer、StringBuilder 都实现了 CharSequence 接口,内部都是用一个char数组实现,虽然它们都与字符串相关,但是其处理机制不同。
- String:是不可改变的,也就是创建后就不能在修改了。
- StringBuffer:是一个可变字符串序列,它与 String 一样,在内存中保存的都是一个有序的字符串序列(char 类型的数组),不同点是 StringBuffer 对象的值都是可变的。
- StringBuilder:与 StringBuffer 类基本相同,都是可变字符串序列,不同点是 StringBuffer 是线程安全的,StringBuilder 是线程不安全的。所以StringBuilder效率更高,因为锁的获取和释放会带来开销。
不论是创建StringBuffer 还是 StringBuilder对象,都是默认创建一个容量为16的字符数组。区别就是所有的方法中,比如append,前者有synchronized关键字修饰。

StringBuffer、StringBuilder,两者的toString()方法是如何返回的字符串类型?
虽然StringBuffer使用了缓存,但是本质上都一样,每次toString()都会创建一个新的String对象,而不是使用底层的字符数组,StringBuffer/StringBuilder的存在是为了高效的操作字符串(字符数组)的状态,但是当我们使用toString()的时候一定是一个稳定的状态,具有确切的行为。
String和StringBuffer、StringBuilder三者的使用场景
使用 String 类的场景:在字符串不经常变化的场景中可以使用 String 类,例如常量的声明、少量的变量运算。
使用 StringBuffer 类的场景:在频繁进行字符串运算(如拼接、替换、删除等),并且运行在多线程环境中,则可以考虑使用 StringBuffer,例如 XML 解析、HTTP 参数解析和封装。
使用 StringBuilder 类的场景:在频繁进行字符串运算(如拼接、替换、和删除等),并且运行在单线程的环境中,则可以考虑使用 StringBuilder,如 SQL 语句的拼装、JSON 封装等。
String和StringBuffer、StringBuilder三者的性能分析
在性能方面,由于 String 类的操作是产生新的 String 对象,而 StringBuilder 和 StringBuffer 只是一个字符数组的扩容而已,所以 String 类的操作要远慢于 StringBuffer 和 StringBuilder。简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象。所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer,如果没有同步问题,推进直接使用StringBuilder ,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接。而在解释的过程中,自然速度会慢一些。
下面这些语句执行会发生什么事情?
String m = "hello,world"; String n = "hello,world"; String u = new String(m); String v = new String("hello,world");
Java堆中会分配一个长度11的char数组,并在字符串常量池分配一个由这个char数组组成的字符串,然后由栈中引用变量m指向这个字符串。
用n去引用常量池里边的同一个字符串,所以和m引用的是同一个对象。
生成一个新的字符串,但新字符串对象内部的字符数组引用着m内部的字符数组。
同样会生成一个新的字符串,但内部的字符数组引用常量池里边的字符串内部的字符数组,意思是和u是同样的字符数组。
如果使用一个图来表示的话,情况就大概是这样的(使用虚线只是表示两者其实没什么特别的关系):
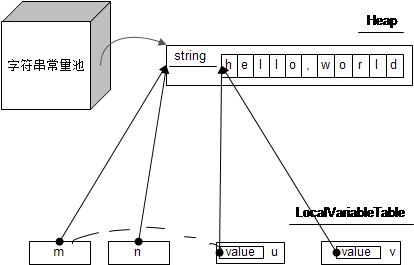
结论就是,m和n是同一个对象,但m,u,v都是不同的对象,但都使用了同样的字符数组,并且用equal判断的话也会返回true。
如下代码的执行结果是什么?
class Workout { private static String m = "hello,world"; private static String n = "hello,world"; private static String u = new String(m); private static String v = new String("hello,world"); public static void main(String[] args) throws Exception { test1(); } public static void test1() throws Exception { Field f = m.getClass().getDeclaredField("value"); f.setAccessible(true); char[] cs = (char[]) f.get(m); cs[0] = 'H'; String p = "Hello,world"; System.out.println(p.equals(m)); System.out.println(p.equals(n)); System.out.println(p.equals(u)); System.out.println(p.equals(v)); } }
执行全部是true,说明反射起作用了,即String作为一直标榜的不可变对象,竟然被修改了!可以看到,经常说的字符串是不可变的,其实和其他的final类还是没什么区别,还是引用不可变的意思。 虽然String类不开放value,但同样是可以通过反射进行修改,只是通常没人这么做而已。 即使是涉及JDK自己的 ”修改” 的方法,都是通过产生一个新的字符串对象来实现的,例如replace、toLower、concat等。 这样做的好处就是让字符串是一个状态不可变类,在多线程操作时没有后顾之忧。
看下String类的主要源码:

有一个final类型的char数组value,它是能被反射攻击的!全部输出true,也证明了之前的解释是正确的,存在字符串常量池,且新对象也好,直接引用的常量池也好,内部的char数组都是这一个。如果内容一样的话。即:字符串常量通常是在编译的时候就确定好的,定义在类的方法区里,也就是说,不同的类,即使用了同样的字符串,还是属于不同的对象。所以才需要通过引用字符串常量来减少相同的字符串的数量。
下面这些语句执行会发生什么事情?
String m = "hello,world"; String u = m.substring(2,10); String v = u.substring(4,7);
m,u,v是三个不同的字符串对象,但引用的value数组其实是同一个。 同样可以通过上述反射的代码进行验证。
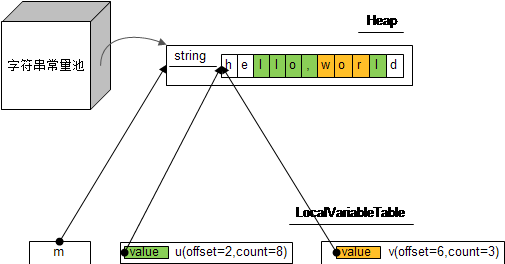
虽然产生了新的字符串对象,但是引用的字符串常量池还是原来的,
下面这些语句执行会发生什么事情?
String m = "hello,"; String u = m.concat("world"); String v = new String(m.substring(0,2));
注意:字符串操作时,可能需要修改原来的字符串数组内容或者原数组没法容纳的时候,就会使用另外一个新的数组,例如replace,concat, + 等操作。对于String的构造方法,对于字符串参数只是引用部分字符数组的情况(count小于字符数组长度),采用的是拷贝新数组的方式,是比较特别的,不过这个构造方法也没什么机会使用到。
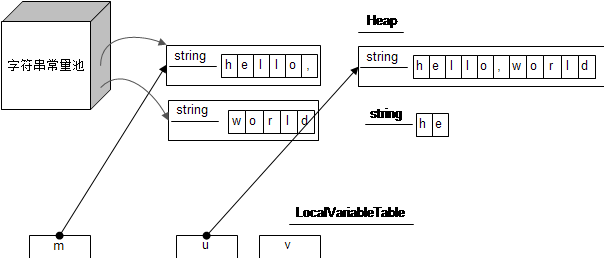
可以发现,m,u,v内部的字符数组并不是同一个。且单独看 m.substring(0,2); 产生的“he”字符串引用的字符数组是常量池里的“hello,”。但是在String构造方法里,采用的是拷贝新数组的方式,然后v来引用,这里很特殊。别忘了,world也在字符串常量池里,常量池中的字符串通常是通过字面量的方式产生的,就像上述m语句那样。 并且他们是在编译的时候就准备好了,类加载的时候,顺便就在常量池生成。
注意:在JDK7,substring()方法会创建一个新的字符数组,而不是使用已有的。
如下代码的执行结果是什么?
String m = "hello,world"; String u = m + "."; String v = "hello,world."; String q = "hello,world."; System.out.println(u.equals(v)); System.out.println(u == v); System.out.println(q == v);
true,false,true
即使是字符串的内容是一样的,都不能保证是同一个字符串数组,u和v虽然是一样内容的字符串,但内部的字符数组不是同一个。画成图的话就是这样的:

因为m引用的字符数组长度固定,多一个".",原数组无法容纳,会使用另外一个新的字符数组,也就是u引用新的对象,没有放到常量池。
如下代码的执行结果是什么?
final String m = "hello,world"; String u = m + "."; String v = "hello,world."; String q = "hello,world."; System.out.println(u.equals(v)); System.out.println(u == v); System.out.println(q == v);
true true true 如果让m声明为final,u和v会变成同一个对象。这应该怎么解释?这其实都是编译器搞的鬼,因为m是显式final的,常量和常量连接, u直接被编译成”hello,world.”了。
画成图的话就是这样的:
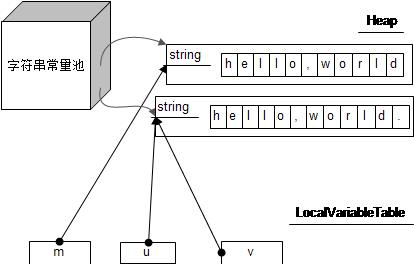
下面程序的运行结果是?

false String str1 = "hello"; 这里的str1指的是方法区(java7中又把常量池移到了堆中)的字符串常量池中的“hello”,编译时期就知道的; String str2 = "he" + new String("llo"); 这里的str2必须在运行时才知道str2是什么,所以它是指向的是堆里定义的字符串“hello”,所以这两个引用是不一样的,如果用str1.equal(str2),那么返回的是True;因为两个字符串的内容一样。 和上个问题类型,因为,编译器没那么智能,它不知道"he" + new String("llo")的内容是什么,所以才不敢贸然把"hello"这个对象的引用赋给str2. new String("llo")外边包着一层外衣呢,如果语句改为:"he"+"llo"这样就是true了。
下面这些语句执行会发生什么事情?
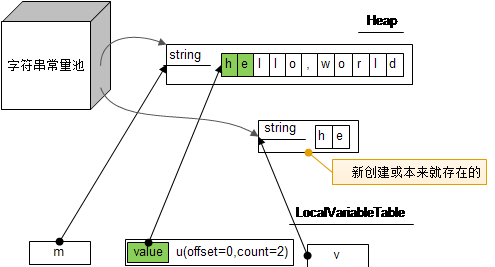
String m = "hello,world"; String u = m.substring(0,2); String v = u.intern();
上面我们已经知道m,u虽然是不同的对象,但是使用的是同一个value字符数组,但intern方法会到常量池里边去寻找字符串”he”,如果找到的话,就直接返回该字符串, 否则就在常量池里边创建一个并返回,所以v使用的字符数组和m,n不是同一个。
画成图的话就是这样的:
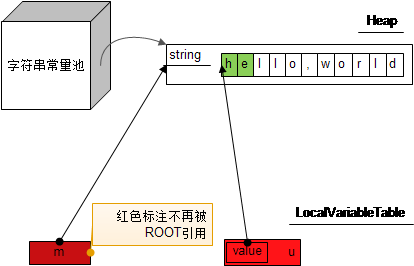
下面这些语句执行后,JVM以后会回收m,n么?
String m = "hello,world"; String n = m.substring(0,2); m = null; n = null;
字面量字符串,因为存放在常量池里边,被常量池引用着,是没法被GC的。
画成图的话就是这样的:
经过上面几个题的分析,对于Java字符串,像substring、split等方法得到的结果都是引用原字符数组的,如果某字符串很大,而且不是在常量池里存在的,当你采用substring等方法拿到一小部分新字符串之后,长期保存的话(例如用于缓存等),会造成原来的大字符数组意外无法被GC的问题。如果这样的大字符串对象较多,且每个都被substring等方法切割了,那么这些大对象都无法被GC,必然会内存浪费。关于这个问题,常见的解决办法就是使用new String(String original)。在String构造方法里,采用的是拷贝新数组的方式来被引用。
请简述 equal 和 ==的区别?
也是初级的,但是想得满分不太容易,能拉开档次,之前看网上有的解释说,前者比较内容,后者比较地址,其实这是不严谨的,作为一个宣称掌握Java的程序员,实在不应该,equal方法是Object这个超级根类里的,默认是实现的==,只有在重写(比如字符串操作里)后,按照Java的设计规范,equal才被重写为了比较对象的内容。故,应该分类别(重写否),不同环境和不同数据类型(对象还是基本类型)下进行分析。 == 用于比较两个对象的时候,是来check 两个引用是否指向了同一块内存,比较的是地址,比较基本类型,比较的是数值大小。 equals() 是Object的方法,默认情况下,它与== 一样,比较的地址。但是当equal被重载之后,根据设计,equal 会比较对象的value。而这个是java希望有的功能。String 类就重写了这个方法,比较字符串内容。
上述几个问题得出结论
-
任何时候,比较字符串内容都应该使用equals方法
-
修改字符串操作,应该使用StringBuffer,StringBuilder
-
可以使用intern方法让运行时产生的字符串复用常量池中的字符串
-
字符串操作可能会复用原字符数组,在某些情况可能造成内存泄露的问题,split,subString等方法。要小心。
下面哪段程序能够正确的实现GBK编码字节流到UTF-8编码字节流的转换:
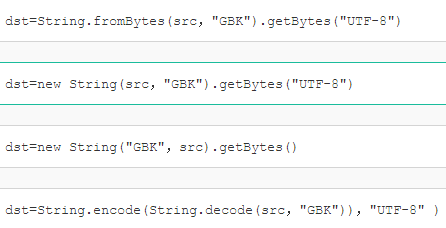
操作步骤就是先解码再编码,用new String(src,"GBK")解码得到字符串,用getBytes("UTF-8")得到UTF8编码字节数组
在Java语言中,下列关于字符集编码(Character set encoding)和国际化(i18n)的问题,哪些是正确的?

Java内部默认使用Unioncode编码,即不论什么语言都是一个字符占两个字节,Java的class文件编码为UTF-8,而虚拟机JVM编码为UTF-16。UTF-8编码下,一个中文占3个字节,一个英文占1个字节,Java中的char默认采用Unicode编码,所以Java中char占2个字节。B 也是不正确的,不同的编码之间是可以转换的,必须太绝对了。C 是正确的。Java虚拟机中通常使用UTF-16的方式保存一个字符。D 也是正确的。ResourceBundle能够依据Local的不同,选择性的读取与Local对应后缀的properties文件,以达到国际化的目的。
语句:char foo='中'; 是否正确?(假设源文件以GB2312编码存储,并且以javac – encoding GB2312命令编译)
这在java中是正确的,在C语言中是错误的,java的char类型默认占两个字节。这种写法是正确的,此外java还可以用中文做变量名。因为java内部都是用unicode的,所以java其实是支持中文变量名的,比如string 世界 = "我的世界";这样的语句是可以通过的。综上,java中采用GB2312或GBK编码方式时,一个中文字符占2个字节,而char是2个字节,所以是对的。
以下Java代码将打印出什么?

由于replaceAll方法的第一个参数是一个正则表达式,而"."在正则表达式中表示任何字符,所以会把前面字符串的所有字符都替换成"/"。 如果想替换的只是“.”的话,正则表达式那里就要写成“\\.”或者是“[.]”。前者将“.”转义为“.”这个具体字符,后者则匹配“[]”中的任意字符,“.”就代表具体字符“.”。 输出 ///////MyClass.class
以下Java代码将打印出什么?Test1是本类名。完整,类名是com.dashuai.Test1
System.out.println(Test1.class.getName().replaceAll("\\.", File.separator) + ".class");
这个程序根据底层平台的不同会显示两种行为中的一种。如果在类UNIX 上运行,那么该程序将打印com/dashuai/Test1.class,这是正确的。但是在Windows 上运行,那么该程序将抛出异常: Exception in thread "main" java.lang.IllegalArgumentException: character to be escaped is missing at java.util.regex.Matcher.appendReplacement(Matcher.java:809) at java.util.regex.Matcher.replaceAll(Matcher.java:955) at java.lang.String.replaceAll(String.java:2223) at wangdashuai.Test1.main(Test1.java:25) 在Windows 上出了什么错呢?事实证明,String.replaceAll 的第二个参数不是一个普通的字符串,而是一个替代字符串(replacement string),就像在java.util.regex 规范中所定义的那样。在Linux平台,是正斜杠,在win下士反斜杠。在替代字符串中出现的反斜杠会把紧随其后的字符进行转义,从而导致其被按字面含义而处理。 修改:5.0 + 版本提供了解决方案。该方法就是 String.replace(CharSequence, CharSequence),它做的事情和String.replaceAll 相同,但是它将模式和替代物都当作字面含义的字符串处理。 System.out.println(Test1.class.getName().replace(".", File.separator) + ".class"); 小结:在使用不熟悉的类库方法时一定要格外小心。当你心存疑虑时,就要求助于Javadoc。还有就是正则表达式是很棘手的:它所引发的问题趋向于在运行时刻而不是在编译时刻暴露出来。还要记住,replaceAll,会把模式当做正则表达式,而replace不会。
Java中用正则表达式截取字符串中第一个出现的英文左括号之前的字符串。比如:北京市(海淀区)(朝阳区)(西城区),截取结果为:北京市。正则表达式为()
做这个题,如果想做对,必须知道和理解正则表达式的贪婪匹配。 String str="abcaxc"; Patter p="ab*c"; 贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc 非贪婪匹配:就是匹配到结果就好,尽量少的匹配字符。如上面使用模式p匹配字符串str,结果就是匹配到:abc 正则表达式默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式匹配。 量词: {m,n}:m到n个 *:任意多个(0个或者多个) +:一个或者多个 ?:0或一个 (?=Expression) 顺序匹配Expression 正确答案:“.*?(?=\\()” ”(?=\\()” 就是顺序匹配正括号,前面的.*?是非贪婪匹配的意思, 表示找到最小的就可以了
使用Java写一个方法,判断一个ip地址是否有效
private static boolean isIp(String ip) { String ipString = "^(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[1-9])\\." + "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\." + "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\." + "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)$"; Pattern pattern = Pattern.compile(ipString); Matcher matcher = pattern.matcher(ip); return matcher.matches(); }
Java中如何用正则表达式判断一个网址地址是否有效,写出正则表达式即可?
String urlString = "(^(([hH][tT]{2}[pP])|([hH][tT]{2}[pP][sS]))://(([a-zA-Z0-9-~]+).)+([a-zA-Z0-9-~\\/]+)$)";
注意:以上编程答案仅仅是个人解答,不唯一。
下面这条语句一共创建了多少个对象?
String s=“a”+”b”+”c”+”d”;
只创建了一个String对象。System.out.println(s== “abcd”);打印的结果为true。
javac编译可以对字符串常量直接相加的表达式进行优化,不必要等到运行期去进行加法运算处理,而是在编译时去掉其中的加号,直接将其编译成一个这些常量相连的结果。
如果改成 String s = a+b+c+d+e; 又是几个了?
就是说上面的每个字符串 "a"、"b"、"c"、"d"、"e"用5个变量代替。
Java编译器,自动生成一个StringBuilder对象,对字符串变量进行拼接操作。使用append方法,分别加入a,b,c,d,e。然后调用toString()方法返回。 看append方法源码: public AbstractStringBuilder append(String str) { if (str == null) return appendNull(); int len = str.length(); ensureCapacityInternal(count + len); str.getChars(0, len, value, count); count += len; return this; } 而ensureCapacityInternal方法内部使用了Arrays.copyOf()方法,该方法内部又调用了本地方法System.arraycopy(),该本地方法没有产生新对象,但是在Arrays.copyOf()内部其他地方还产生了一个新对象new char[newLength],源码如下: public static char[] copyOf(char[] original, int newLength) { char[] copy = new char[newLength]; System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; } 而getchars方法内部直接调用了本地方法System.arraycopy();没有产生新对象。 看StringBuilder默认构造器: public StringBuilder() { super(16); } 我们的字符串长度不会超过16,不会扩容。如果题目出现了总长度超过16,则会出现如下的再次分配的情况: /** * This implements the expansion semantics of ensureCapacity with no * size check or synchronization. */ void expandCapacity(int minimumCapacity) { int newCapacity = value.length * 2 + 2; if (newCapacity - minimumCapacity < 0) newCapacity = minimumCapacity; if (newCapacity < 0) { if (minimumCapacity < 0) // overflow throw new OutOfMemoryError(); newCapacity = Integer.MAX_VALUE; } value = Arrays.copyOf(value, newCapacity); } 在看最后的返回过程,调用了toString()方法,此时产生一个String新对象。 @Override public String toString() { // Create a copy, don't share the array return new String(value, 0, count); } 故,一共产生三个对象,一个StringBuilder对象,一个String对象,一个new char[]对象。
Java里String a = new String("abc");一共能创建几个String对象?
其实这个问题,问的很没意思,不严谨,如果不幸在笔试遇到了,没办法,照着标准答案:两个或一个对象,”abc”本身生成一个对象,放在字符串池(缓冲区),new的时候再生成一个,结果是2个。如果之前就使用了“abc”,那么”abc”本身就不再生成对象,就是1个。一个字符串常量池里的,一个new出来的,但是如果面试中遇到了,可以尝试的和面试官沟通这个题目的问题。请看从事JVM开发的 R大神的解答:
请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧
StringBuffer sb = new StringBuffer("abc"); 创建了几个String对象?
这种问题,一定是问创建多少string对象,否则涉及其他对象,就太多了,不好说。看字节码: Code: stack=3, locals=2, args_size=1 0: new #16 // class java/lang/StringBuffer 3: dup 4: ldc #18 // String 123 6: invokespecial #20 // Method java/lang/StringBuffer."":(Ljava/lang/String;)V 9: astore_1 10: return 答案很明显。ldc:从常量池加载string,如果常量池中有“123”,就不创建。而new指令 :创建了一个buffer对象。
Java里对于密码等敏感信息优先使用字符数组还是字符串,为什么?
虽然String加载密码之后可以把这个变量扔掉,但是字符串并不会马上被GC回收(考虑常量池,即使没有常量池引用,GC也不一定立即回收它),一但进程在GC执行到这个字符串之前被dump,dump出的的转储中就会含有这个明文的字符串。那如果去“修改”这个字符串,比如把它赋一个新值,那么是不是就没有这个问题了?答案是否定的,因为String本身是不可修改的,任何基于String的修改函数都是返回一个新的字符串,原有的还会在内存里。对于char[]来说,可以在抛弃它之前直接修改掉它里面的内容,密码就不会存在了。但是如果什么也不做直接交给gc的话,也会存在上面一样的问题。
以下Java代码将打印出什么?
System.out.print("H"+"a");
System.out.print('H'+'a');
打印的是Ha169。 第一个对System.out.print 的调用打印的是Ha:它的参数是表达式"H"+"a",显然它执行的是一个字符串连接。 第二个对System.out.print 的调用,'H'和'a'是字符型字面常量,这两个操作数都不是字符串类型的,所以 + 操作符执行的是加法而不是字符串连接。编译器在计算常量表达式'H'+'a'时,是通过我们熟知的拓宽原始类型转换将两个具有字符型数值的操作数('H'和'a')提升为int 数值而实现的(类似的还有byte,short,char类型计算的时候都是自动提升为int)。从char 到int 的拓宽原始类型转换是将16 位的char 数值零扩展到32 位的int。对于'H',char 数值是72,而对于'a',char 数值是97(需要记一下,0的asc码是48,A是65,a是97,这些常用的),因此表达式'H'+'a'等价于int常量72 + 97=169。 修改为打印Ha,可以使用类库: StringBuffer sb = new StringBuffer(); sb.append('H'); sb.append('a'); System.out.println(sb); 很丑陋。其实我们还是有办法去避免这种方式所产生的拖沓冗长的代码。 你可以通过确保至少有一个操作数为字符串类型,来强制 + 操作符去执行一个字符串连接操作,而不是一个加法操作。这种常见的惯用法用一个空字符串("")作为一个连接序列的开始 System.out.println("" + 'H' + 'a');
以下Java代码将打印出什么?
System.out.print("2 + 2 = " + 2 + 2);
2 + 2 = 22 因为进行的是字符串连接,不是数值加法计算。 修改: int a = 2 + 2; System.out.print("2 + 2 = " + a);
这几道题说明,使用字符串连接操作符要格外小心。+ 操作符当且仅当它的操作数中至少有一个是String 类型时,才会执行字符串连接操作;否则,它执行的就是加法。如果要连接的没有一个数值是字符串类型的,那么你可以有几种选择:
• 预置一个空字符串;
• 将第一个数值用String.valueOf 显式地转换成一个字符串;
• 使用一个字符串缓冲区StringBuilder等;
• 或者如果你使用的JDK 5.0,可以用printf 方法,类似c语言。
以下Java代码将打印出什么?
char[] numbers = {'1', '2', '3'}; System.out.println(numbers);
尽管char 是一个整数类型,但是许多类库都对其进行了特殊处理,因为char数值通常表示的是字符而不是整数。例如,将一个char 数值传递给println 方法会打印出一个Unicode 字符而不是它的数字代码。字符数组受到了相同的特殊处理:println 的char[]重载版本会打印出数组所包含的所有字符,而String.valueOf和StringBuffer.append的char[]重载版本的行为也是类似的。
以下Java代码将打印出什么?
String letters = "ABC"; char[] numbers = {'1', '2', '3'}; System.out.println(letters + " easy as " + numbers);
打印的是诸如 ABC easy as [C@1db9742 之类的东西。尽管char 是一个整数类型,但是许多类库都对其进行了特殊处理,然而,字符串连接操作符在这些方法中没有被定义。该操作符被定义为先对它的两个操作数执行字符串转换,然后将产生的两个字符串连接到一起。对包括数组在内的对象引用的字符串转换定义如下: 如果引用为null,它将被转换成字符串"null"。否则,该转换的执行就像是不用任何参数调用该引用对象的toString 方法一样; 但是如果调用toString 方法的结果是null,那么就用字符串"null"来代替。 那么,在一个非空char 数组上面调用toString 方法会产生什么样的行为呢? 数组是从Object 那里继承的toString 方法,规范中描述到:“返回一个字符串,它包含了该对象所属类的名字,'@'符号,以及表示对象散列码的一个无符号十六进制整数”。有关Class.getName 的规范描述到:在char[]类型的类对象上调用该方法的结果为字符串"[C"。将它们连接到一起就形成了在我们的程序中打印出来的那个字符串。 有两种方法可以修改这个程序。可以在调用字符串连接操作之前,显式地将一个数组转换成一个字符串: String letters = "ABC"; char[] numbers = {'1', '2', '3'}; System.out.println(letters + " easy as " + String.valueOf(numbers)); 可以将System.out.println 调用分解为两个调用,以利用println 的char[]重载版本: System.out.print(letters + " easy as "); System.out.println(numbers);
以下Java代码将打印出什么?
String letters = "ABC"; Object numbers = new char[] { '1', '2', '3' }; System.out.print(letters + " easy as "); System.out.println(numbers);
打印ABC easy as [C@1db9742这样的字符串,因为它调用的是println 的Object 重载版本,而不是char[]重载版本。 总之,记住: char 数组不是字符串。要想将一个char 数组转换成一个字符串,就要调用String.valueOf(char[])方法。某些类库中的方法提供了对char 数组的类似字符串的支持,通常是提供一个Object 版本的重载方法和一个char[]版本的重载方法,而之后后者才能产生我们想要的行为。。
以下Java代码将打印出什么?
final String pig = "length: 10"; final String dog = "length: " + pig.length(); System.out.println("Animals are equal: " + pig == dog);
分析可能会认为它应该打印出Animal are equal: false。对吗? 运行该程序,发现它打印的只是false,并没有其它的任何东西。它没有打印Animal are equal: 。+ 操作符,不论是用作加法还是字符串连接操作,它都比 == 操作符的优先级高。因此,println 方法的参数是按照下面的方式计算的: System.out.println(("Animals are equal: " + pig) == dog); 这个布尔表达式的值当然是false,它正是该程序打印的输出。避免此类错误的方法:在使用字符串连接操作符时,当不能确定你是否需要括号时,应该选择稳妥地做法,将它们括起来。 小结: 字符串连接的优先级不应该和加法一样。这意味着重载 + 操作符来执行字符串连接是有问题的。
以下Java代码打印26对么,如果不对,为什么?
System.out.println("a\u0022.length() + \u0022b".length());
对该程序的一种很肤浅的分析会认为它应该打印出26,因为在由两个双引号"a\u0022.length()+\u0022b"标识的字符串之间总共有26 个字符。稍微深入一点的分析会想到 \u0022 是Unicode 转义字符,其实它是双引号的Unicode 转义字符,肯定不会打印26。 如果提示你Unicode 转义字符是双引号,打印什么? 有人说打印16,因为两个Unicode 转义字符每一个在源文件中都需要用6个字符来表示,但是它们只表示字符串中的一个字符。因此这个字符串应该比它的外表看其来要短10 个字符。 其实如果运行,它打印的既不是26 也不是16,是2。理解这个题的关键是要知道:Java 对在字符串字面常量中的Unicode 转义字符没有提供任何特殊处理。编译器在将程序解析成各种符号之前,先将Unicode转义字符转换成为它们所表示的字符。因此,程序中的第一个Unicode转义字符将作为一个单字符字符串字面常量("a")的结束引号,而第二个Unicode 转义字符将作为另一个单字符字符串字面常量("b")的开始引号。程序打印的是表达式"a".length()+"b".length(),即2。 可能的情况是该程序员希望将两个双引号字符置于字符串字面常量的内部。使用Unicode 转义字符你是不能实现这一点的,但是你可以使用转义字符序列来实现。表示一个双引号的转义字符序列是一个反斜杠后面紧跟着一个双引号(\”)。如果将最初的Unicode 转义字符用转义字符序列来替换,那么它将打印出16: System.out.println("a\".length() + \"b".length());
在字符串和字符字面常量中要优先选择的是转义字符序列,而不是Unicode 转义字符。Unicode 转义字符可能会因为它们在编译序列中被处理得过早而引起混乱。不要使用Unicode 转义字符来表示ASCII 字符。在字符串和字符字面常量中,应该使用转义字符序列。
以下Java代码将打印出什么?
/** * Generated by the IBM IDL-to-Java compiler, version 1.0 * from F:\TestRoot\apps\a1\units\include\PolicyHome.idl * Wednesday, June 17, 1998 6:44:40 o’clock AM GMT+00:00 */ public class Test1 { public static void main(String[] args) { System.out.print("Hell"); System.out.println("o world"); } }
通不过编译。问题在于注释的第三行,它包含了字符\units。这些字符以反斜杠(\)以及紧跟着的字母u 开头的,而它(\u)表示的是一个Unicode 转义字符的开始。而这些字符后面没有紧跟四个十六进制的数字,因此,这个Unicode 转义字符是错误的,而编译器则被要求拒绝该程序。即使是出现在注释中也是如此。
Javadoc注释中要小心转移字符,要确保字符\u 不出现在一个合法的Unicode 转义字符上下文之外,即使在注释中也是如此。在机器生成的代码中要特别注意此问题。
除非确实是必需的,否则就不要使用Unicode 转义字符。它们很少是必需的。
以下Java代码运行将会出现什么问题?
byte bytes[] = new byte[256]; for (int i = 0; i < 256; i++) { bytes[i] = (byte) i; } String str = new String(bytes); for (int i = 0, n = str.length(); i < n; i++) { System.out.println((int) str.charAt(i) + " "); }
首先,byte 数组从0 到255 每一个可能的byte 数值进行了初始化,然后这些byte 数值通过String 构造器被转换成了char 数值。最后,char 数值被转型为int 数值并被打印。打印出来的数值肯定是非负整数,因为char 数值是无符号的,因此,你可能期望该程序将按顺序打印出0 到255 的整数。 如果你运行该程序,可能会看到这样的序列。但是在运行一次,可能看到的就不是这个序列了。如果在多台机器上运行它,会看到多个不同的序列,这个程序甚至都不能保证会正常终止,它的行为完全是不确定的。这里的罪魁祸首就是String(byte[])构造器。有关它的规范描述道:“在通过解码使用平台缺省字符集的指定byte 数组来构造一个新的String 时,该新String 的长度是字符集的一个函数,因此,它可能不等于byte 数组的长度。当给定的所有字节在缺省字符集中并非全部有效时,这个构造器的行为是不确定 的”。 到底什么是字符集?从技术角度上讲,字符集是一个包,包含了字符、表示字符的数字编码以及在字符编码序列和字节序列之间来回转换的方式。转换模式在字符集之间存在着很大的区别:某些是在字符和字节之间做一对一的映射,但是大多数都不是这样。ISO-8859-1 是唯一能够让该程序按顺序打印从0 到255 的整数的缺省字符集,它更为大家所熟知的名字是Latin-1[ISO-8859-1]。J2SE 运行期环境(JRE)的缺省字符集依赖于底层的操作系统和语言。如果你想知道你的JRE 的缺省字符集,并且你使用的是5.0 或更新的版本,那么你可以通过调用java.nio.charset.Charset.defaultCharset()来了解。如果你使用的是较早的版本,那么你可以通过阅读系统属性“file.encoding”来了解。 修改: 当你在char 序列和byte 序列之间做转换时,你可以且通常是应该显式地指定字符集。除了接受byte 数字之外,还可以接受一个字符集名称的String 构造器就是专为此目的而设计的。如果你用下面的构造器去替换在最初的程序中的String 构造器,那么不管缺省的字符集是什么,该程序都保证能够按照顺序打印从0 到255的整数: String str = new String(bytes, "ISO-8859-1"); 这个构造器声明会抛出UnsupportedEncodingException 异常,因此你必须捕获它,或者更适宜的方式是声明main 方法将抛出它,要不然程序不能通过编译。尽管如此,该程序实际上不会抛出异常。Charset 的规范要求Java 平台的每一种实现都要支持某些种类的字符集,ISO-8859-1 就位列其中。 小结: 每当你要将一个byte 序列转换成一个String 时,你都在使用某一个字符集,不管你是否显式地指定了它。如果你想让你的程序的行为是可预知的,那么就请你在每次使用字符集时都明确地指定。
以下Java代码将打印出什么?
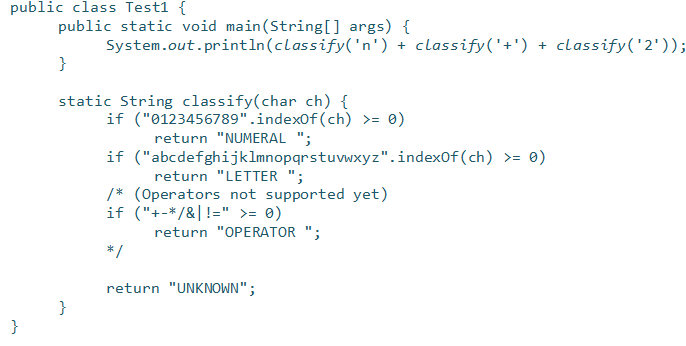
如果回答打印LETTER UNKNOWN NUMERAL,那么你就掉进陷阱里面了。程序连编译都通不过。因为注释在包含了字符*/的字符串内部就结束了,字面常量在注释中没有被特殊处理。更一般地讲,注释内部的文本没有以任何方式进行特殊处理。因此,块注释不能嵌套。
总之,块注释不能可靠地注释掉代码段,应该用单行的注释序列来代替。
以下Java代码将打印出什么?
System.out.print("iexplore:");
http://www.google.com;
System.out.println(":maximize");
正确运行并打印 iexplore::maximize。在程序中间出现的URL是一个语句标号(statement label),后面跟着一行行尾注释(end-of-line comment)。在Java中很少需要标号,这多亏了Java 没有goto 语句(作为保留字)。
Java中很少被人了解的特性:”实际上就是你可以在任何语句前面放置标号。这个程序标注了一个表达式语句,它是合法的,但是却没什么用处。”
注意:令人误解的注释和无关的代码会引起混乱。要仔细地写注释,并让它们跟上时代;要切除那些已遭废弃的代码。还有就是如果某些东西看起来奇怪,以至于不像对的,那么它极有可能就是错的。
以下Java代码将打印出什么?
public class Test1 { private static Random rnd = new Random(); public static void main(String[] args) { StringBuffer word = null; switch (rnd.nextInt(2)) { case 1: word = new StringBuffer('P'); case 2: word = new StringBuffer('G'); default: word = new StringBuffer('M'); } word.append('a'); word.append('i'); word.append('n'); System.out.println(word); } }
乍一看,这个程序可能会在一次又一次的运行中,以相等的概率打印出Pain,Gain 或 Main。看起来该程序会根据随机数生成器所选取的值来选择单词的第一个字母:0 选M,1 选P,2 选G。 它实际上既不会打印Pain,也不会打印Gain。也许更令人吃惊的是,它也不会打印Main,并且它的行为不会在一次又一次的运行中发生变化,它总是在打印ain。 一个bug 是所选取的随机数使得switch 语句只能到达其三种情况中的两种。Random.nextInt(int)的规范描述道:“返回一个伪随机的、均等地分布在从0(包括)到指定的数值(不包括)之间的一个int 数值”。这意味着表达式rnd.nextInt(2)可能的取值只有0和1,Switch语句将永远也到不了case 2 分支,这表示程序将永远不会打印Gain。nextInt 的参数应该是3 而不是2。这是一个相当常见的问题。 第二个bug 是在不同的情况(case)中没有任何break 语句。不论switch 表达式为何值,该程序都将执行其相对应的case 以及所有后续的case。因此,尽管每一个case 都对变量word 赋了一个值,但是总是最后一个赋值胜出,覆盖了前面的赋值。最后一个赋值将总是最后一种情况(default),即 M。这表明该程序将总是打印Main,而从来不打印Pain或Gain。在switch的各种情况中缺少break语句是非常常见的错误。 最后一个bug 是表达式new StringBuffer('M')可能没有做你希望它做的事情。你可能对StringBuffer(char)构造器并不熟悉,这很容易解释:它压根就不存在。StringBuffer 有一个无参数的构造器,一个接受一个String 作为字符串缓冲区初始内容的构造器,以及一个接受一个int 作为缓冲区初始容量的构造器。在本例中,编译器会选择接受int 的构造器,通过拓宽原始类型转换把字符数值'M'转换为一个int 数值77。换句话说,new StringBuffer('M')返回的是一个具有初始容量77 的空的字符串缓冲区。该程序余下的部分将字符a、i 和n 添加到了这个空字符串缓冲区中,并打印出该缓冲区那总是ain 的内容。为了避免这类问题,不管在什么时候,都要尽可能使用熟悉的惯用法和API。如果你必须使用不熟悉的API,那么请仔细阅读其文档。在本例中,程序应该使用常用的接受一个String 的StringBuffer 构造器。 修改: public class Test1 { private static Random rnd = new Random(); public static void main(String[] args) { StringBuffer word = null; switch (rnd.nextInt(3)) { case 1: word = new StringBuffer("P"); break; case 2: word = new StringBuffer("G"); break; default: word = new StringBuffer("M"); break; } word.append('a'); word.append('i'); word.append('n'); System.out.println(word); } } 尽管这个程序订正了所有的bug,它还是显得过于冗长了。下面是一个更优雅的版本: private static Random rnd = new Random(); public static void main(String[] args) { System.out.println("PGM".charAt(rnd.nextInt(3)) + "ain"); } 下面是一个更好的版本。尽管它稍微长了一点,但是它更加通用: public class Test1 { public static void main(String[] args) { String a[] = { "Main", "Pain", "Gain" }; System.out.println(randomElement(a)); } private static Random rnd = new Random(); private static String randomElement(String[] a) { return a[rnd.nextInt(a.length)]; } } 总结一下:首先,要当心Java随机数产生器的特点。其次,牢记在 switch 语句的每一个 case中都放置一条 break 语句。第三,要使用常用的惯用法和 API,并且当模糊的时候,一定要参考相关的文档。第四,一个 char 不是一个 String,而是更像一个 int
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!
