参考内容:
python数据挖掘与机器学习实战.方魏.机械工业出版社.2019.05
机器学习基础:从入门到求职.胡欢武.电子工业出版社.2019.03
1. 何为机器学习?
机器学习: 通俗地讲就是让机器来实现学习的过程,让机器拥有学习的能力,从而改善系统自身的性能。对于机器而言,这里的“学习”指的是从数据中学习,从数据中产生“模型”的算法,即“学习算法”。有了学习算法,只要把经验数据提供给它,它就能够基于这些数据产生模型,在面对新的情况时,模型能够提供相应的判断,进行预测。机器学习实质是基于数据集的,通过对数据集的研究,找出数据集中数据之间的联系和数据的真实含义。

2. 机器学习的前世今生
机器学习属于人工智能中一个较为“年轻”的分支,大致可以分为以下3个发展阶段。
- 第一阶段:20世纪50年代中期到60年代中期,这一时期处于萌芽时期。人们试图通过软件编程来操控计算机完成一系列的逻辑推理功能,进而使计算机具有一定程度上类似于人类的智能思考能力。然而这一时期计算机所推理的结果远远没有达到人们对机器学习的期望。通过进一步研究发现,只具有逻辑推理能力并不能使机器智能。研究者们认为,使机器拥有人工智能的前提,必须是拥有大量的先验知识。
- 第二阶段:20世纪60年代中期到80年代中期,这一时期处于发展时期。人们试图利用自身思维提取出来的规则教会计算机执行决策行为,主流之力便是各式各样的“专家系统”。然而这些系统总会面临“知识稀疏”的问题,即面对无穷无尽的知识与信息,人们无法总结出万无一失的规律。因此,让机器自主学习的设想自然地浮出水面。基于20世纪50年代对于神经网络的研究,人们开始研究如何让机器自主学习。
- 第三阶段:20世纪80年代至今,机器学习达到了一个繁荣时期。由于这一时期互联网大数据及硬件GPU的出现,使得机器学习突破了瓶颈期。机器学习开始呈现“爆炸”式发展趋势,逐渐成为了一门独立的热门学科,并且被应用到各个领域中。各种机器学习算法不断涌现,而利用深层次神经网络的深度学习也得到了进一步发展。同时,机器学习的蓬勃发展还促进了其他分支的出现,如模式识别、数据挖掘、生物信息学和自动驾驶等。
3. 机器学习的常用算法
机器学习的思想并不复杂,它仅仅是对人类生活、学习过程的一个模拟。而在这整个过程中,最关键的是数据。任何通过数据训练的学习算法的相关研究都属于机器学习,目前常见的机器学习算法有:
- 线性回归(Linear Regression)
- 逻辑回归(Logistic Regression)
- K均值(K-Means,基于原型的目标函数聚类方法)
- 决策树(Decision Trees,运用概率分析的一种图解法)
- 随机森林(Random Forest,运用概率分析的一种图解法)
- PCA(Principal Component Analysis,主成分分析)
- SVM(Support VectorMachine,支持向量机)
- ANN(Artificial Neural Networks,人工神经网络)
- 朴素贝叶斯
4.机器学习的分类
4.1 按照学习方式类
按学习方式来分类,机器学习可分为有监督学习、无监督学习和强化学习等。
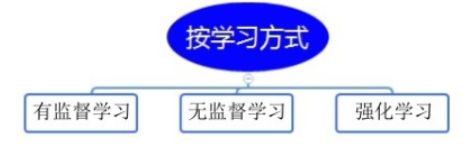
4.1.1 监督学习
监督学习(Supervised Learning) 表示机器学习的数据是带标记的,这些标记可以包括数据类别、数据属性及特征点位置等。这些标记作为预期效果,不断修正机器的预测结果。具体实现过程是:通过大量带有标记的数据来训练机器,机器将预测结果与期望结果进行比对;之后根据比对结果来修改模型中的参数,再一次输出预测结果;然后将预测结果与期望结果进行比对,重复多次直至收敛,最终生成具有一定鲁棒性的模型来达到智能决策的能力。 * 常见的监督学习有分类和回归:
- 分类(Classification): 是将一些实例数据分到合适的类别中,它的预测结果是离散的。
- 回归(Regression): 是将数据归到一条“线”上,即为离散数据生产拟合曲线,因此其预测结果是连续的。

4.1.2 无监督学习
无监督学习(Unsupervised Learning) 表示机器学习的数据是没有标记的。机器从无标记的数据中探索并推断出潜在的联系。常见的无监督学习有聚类和降维:
- 聚类(Clustering): 由于事先不知道数据类别,因此只能通过分析数据样本在特征空间中的分布,例如基于密度或基于统计学概率模型等,从而将不同数据分开,把相似数据聚为一类。
- 降维(Dimensionality Reduction): 是将数据的维度降低。例如描述一个西瓜,若只考虑外皮颜色、根蒂、敲声、纹理、大小及含糖率这6个属性,则这6个属性代表了西瓜数据的维度为6。进一步考虑降维的工作,由于数据本身具有庞大的数量和各种属性特征,若对全部数据信息进行分析,将会增加训练的负担和存储空间。因此可以通过主成分分析等其他方法,考虑主要影响因素,舍弃次要因素,从而平衡准确度与效率。

4.1.3 强化学习
强化学习(Reinforcement Learning) 是带有激励机制的,具体来说,如果机器行动正确,将施予一定的“正激励”;如果行动错误,同样会给出一个惩罚(也可称为“负激励”)。因此,在这种情况下,机器将会考虑如何在一个环境中行动才能达到激励的最大化,具有一定的动态规划思想。
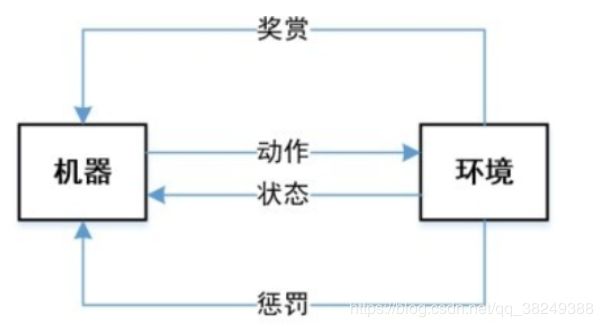
例如:
- 在贪吃蛇游戏中,贪吃蛇需要通过不断吃到“食物”来加分。为了不断提高分数,贪吃蛇需要考虑在自身位置上如何转向才能吃到“食物”,这种学习过程便可理解为一种强化学习。
- 强化学习最为火热的一个应用就是谷歌AlphaGo的升级品——AlphaGo Zero。相较于AlphaGo,AlphaGoZero舍弃了先验知识,不再需要人为设计特征,直接将棋盘上黑、白棋子的摆放情况作为原始数据输入到模型中,机器使用强化学习来自我博弈,不断提升自己从而最终出色完成下棋任务。
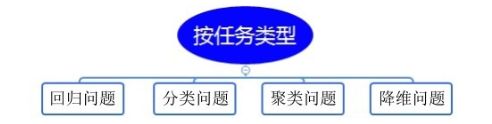
4.2 按任务类型分类
按任务类型分类,机器学习可分为回归问题、分类问题、聚类问题和降维问题等。
4.2.1 回归问题
回归问题: 就是利用数理统计中的回归分析技术,来确定两种或两种以上变量之间依赖关系。例如下图,股票波动情况预测,实线表示的是某只股票随时间变量的实际波动情况,而虚线是基于线性回归模型进行回归预测得到的结果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PBYMijzS-1586274092922)(attachment:image.png)]](http://img.e-com-net.com/image/info8/f8ee6b37f93142c4b7cb3b0a081b0157.jpg)
4.2.2 分类问题
分类问题是机器学习中最常见的一类任务,比如我们常说的图像分类、文本分类等。

4.2.3 聚类问题
聚类问题: 又称群分析,目标是将样本划分为紧密关系的子集或簇。简单来讲就是希望利用模型将样本数据集聚合成几大类,算是分类问题中的一种特殊情况,聚类问题的常见应用:市场细分、社群分析等。
4.2.4 降维问题
降维: 是指采用某种映射方法,将原高维空间中的数据点映射到低维空间。可能是原始高维空间中包含冗余信息或噪声,需要通过降维将其消除;也可能是某些数据集的特征维度过大,训练过程比较困难,需要通过降维来减少特征的量。常用的降维模型有主成分分析(PCA)和线性判别分析(LDA)等。

5. 开发机器学习的一般步骤
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CpEYyslB-1586274092925)(attachment:image.png)]](http://img.e-com-net.com/image/info8/ae543c163d9e4585b19064ed5bb9bdba.jpg)
(1)收集数据。
收集所需的数据,方法如:网络爬虫、问卷调查获取的信息、一些设备发送过来的数据,以及从物联网设备获取的数据等。
(2)准备输入数据。
得到数据之后,要确保得到的数据格式符合要求,如某些算法要求特征值需要使用特定的格式。
(3)分析输入的数据。
查看输入的数据是否有明显的异常值,如某些数据点和数据集中的其他值存在明显的差异。通过一维、二维或者三维图形化展示数据是个不错的方法,但是得到的数据特征值都不会低于三个,无法一次图形化展示所有特征。可以通过数据的提炼,压缩多维特征至二维或者一维。
(4)训练算法。
机器学习算法从这一步才算真正开始。需要考虑算法是使用监督学习算法还是无监督学习算法。如果使用无监督学习算法,由于不存在目标变量值,因而也不需要训练算法,所有与算法相关的内容都在第(5)步。
(5)测试算法。
这一步将实际使用第(4)步机器学习得到的知识信息。为了评估算法,必须测试算法工作的效果。对于监督学习,必须已知用于评估算法的目标变量值;对于无监督学习,也必须通过其他的评测手段来检测算法的成功率。如果不满意预测结果,则返回至第(4)步。
( 6)使用算法。
这一步是将机器学习算法转化为应用程序,执行实际任务。 下一节: 机器学习相关的工程实践问题
下一节: Machine Learning -- 机器学习相关的工程实践问题