[email protected] 2017-12-23 08:20
写在前面的废话
现在我们要开始搭建Hadoop集群了,Hadoop包含如下两部分:
- HDFS, 即Hadoop分布式文件系统
- YARN, 即第二代的MapReduce(MR2),解决了第一代MR的诸多问题,例如集群扩展困难(最多三四千台机器),单点故障,资源调度不灵活等.第一代MR只能实现MR算法,而YARN真正成为了一个计算平台,例如Spark也可以基于YARN运行
好了,Hadoop的资料以及最新发展情况,还是自己网上搜索学习吧.
重要说明
Hadoop默认是将一份数据复制两份存储在另外两台机器上,所以,一份数据在集群中存在三份,那么对集群内机器数量的要求就是五台:
- 一台主NameNode,存储集群的元数据
- 一台备NameNode,存储集群的元数据
- 三台DataNode,存储数据
可是我们在自己的台式机或笔记本上,在实在难以搭建和运行如此多的虚拟机,所以,我依然使用了三台虚拟机,把DataNode改为了一台.在Hadoop的配置中,也会有所体现,需要修改一个参数,使之默认数据备份数量为1.
开始
准备
要求集群内的每台机器都要
- 安装了JDK,并配置好了环境变量
- 具有内容一致的/etc/hosts文件(IP地址与主机名的映射)
- 安装了ZooKeeper,并已做好配置,可以正常启动
- 已下载了Hadoop软件包(本文使用hadoop-2.9.0.tar.gz这个包)
集群规划
| 主机名 | IP地址 | 安装软件 | 运行进程 |
|---|---|---|---|
| bd-1 | 192.168.206.132 | JDK,Hadoop,ZooKeeper | NameNode(Active),DFSZKFailoverController(zkfc),ResouceManager(Standby),QuorumPeerMain(ZooKeeper) |
| bd-2 | 192.168.206.133 | JDK,Hadoop,ZooKeeper | NameNode(Standby),DFSZKFailoverController(zkfc),ResouceManager(Active),QuorumPeerMain(ZooKeeper),Jobhistory |
| bd-1 | 192.168.206.134 | JDK,Hadoop,ZooKeeper | DataNode,NodeManager,JournalNode,QuorumPeerMain(ZooKeeper) |
安装(如无特殊说明,每台虚拟机均需做完下面的操作)
1. 在每台机器上解压和安装Hadoop软件包
在官网下载的hadoop-2.9.0.tar.gz文件依然放在每个libing用户家目录下的softwares目录下
[libing@bd-1 ~]$ ll softwares/
-rw-rw-r--. 1 libing libing 366744329 12月 11 22:49 hadoop-2.9.0.tar.gz
解压
[libing@bd-1 ~]$ tar -xzf softwares/hadoop-2.9.0.tar.gz -C /home/libing/
[libing@bd-1 ~]$ ll
总用量 36
drwxr-xr-x 9 libing libing 149 11月 14 07:28 hadoop-2.9.0
drwxr-xr-x. 8 libing libing 255 9月 14 17:27 jdk1.8.0_152
drwxrwxr-x. 2 libing libing 148 12月 20 20:09 softwares
-rwxrw-r-- 1 libing libing 151 12月 21 22:29 zkStartAll.sh
-rwxrw-r-- 1 libing libing 149 12月 21 22:37 zkStopAll.sh
drwxr-xr-x 12 libing libing 4096 12月 21 21:51 zookeeper-3.4.10
-rw-rw-r-- 1 libing libing 17810 12月 21 22:31 zookeeper.out
[libing@bd-1 ~]$ ll hadoop-2.9.0/
总用量 128
drwxr-xr-x 2 libing libing 194 11月 14 07:28 bin
drwxr-xr-x 3 libing libing 20 11月 14 07:28 etc
drwxr-xr-x 2 libing libing 106 11月 14 07:28 include
drwxr-xr-x 3 libing libing 20 11月 14 07:28 lib
drwxr-xr-x 2 libing libing 239 11月 14 07:28 libexec
-rw-r--r-- 1 libing libing 106210 11月 14 07:28 LICENSE.txt
-rw-r--r-- 1 libing libing 15915 11月 14 07:28 NOTICE.txt
-rw-r--r-- 1 libing libing 1366 11月 14 07:28 README.txt
drwxr-xr-x 3 libing libing 4096 11月 14 07:28 sbin
drwxr-xr-x 4 libing libing 31 11月 14 07:28 share
2. 配置系统环境变量
编辑/etc/profile文件
[libing@bd-1 ~]$ sudo vi /etc/profile
[sudo] libing 的密码:
添加如下内容
# Added for Hadoop
HADOOP_HOME=/home/libing/hadoop-2.9.0
export HADOOP_HOME
HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CONF_DIR
YARN_HOME=${HADOOP_HOME}
export YARN_HOME
YARN_CONF_DIR=${HADOOP_CONF_DIR}
export YARN_CONF_DIR
PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export PATH
使之马上生效
[libing@bd-1 ~]$ source /etc/profile
检查验证
[libing@bd-1 ~]$ env | grep HADOOP
HADOOP_HOME=/home/libing/hadoop-2.9.0/
HADOOP_CONF_DIR=/home/libing/hadoop-2.9.0/etc/hadoop
[libing@bd-1 ~]$ env | grep YARN
YARN_HOME=/home/libing/hadoop-2.9.0/
YARN_CONF_DIR=/home/libing/hadoop-2.9.0/etc/hadoop
[libing@bd-1 ~]$ echo $PATH
/home/libing/zookeeper-3.4.10/bin:/usr/local/jdk//bin:/home/libing/zookeeper-3.4.10/bin:/usr/local/jdk//bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/libing/.local/bin:/home/libing/bin:/home/libing/hadoop-2.9.0/bin:/home/libing/hadoop-2.9.0/sbin
配置HDFS
1. 配置环境变量设置脚本
进入Hadoop的配置文件路径,并修改hadoop-env.sh文件
[libing@bd-1 ~]$ cd ~/hadoop-2.9.0/etc/hadoop/
[libing@bd-1 hadoop]$ vi hadoop-env.sh
将该行
export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/local/jdk/
个人认为其实这里不改也行,毕竟我们以前都设置好JAVA_HOME环境变量了.
2. 修改core-site.xml
继续修改core-site.xml文件,在
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/home/libing/hadoop-2.9.0/hdpdata/
需要手动创建hdpdata目录
ha.zookeeper.quorum
bd-1:2181,bd-2:2181,bd-3:2181
ZooKeeper地址,用逗号隔开
保存并退出vi
3. 修改hdfs-site.xml
继续修改hdfs-site.xml文件,在
dfs.nameservices
ns
指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致
dfs.ha.namenodes.ns
nn1,nn2
ns命名空间下有两个NameNode,逻辑代号,随便起名字,分别是nn1,nn2
dfs.namenode.rpc-address.ns.nn1
bd-1:9000
nn1的RPC通信地址
dfs.namenode.http-address.ns.nn1
bd-1:50070
nn1的http通信地址
dfs.namenode.rpc-address.ns.nn2
bd-2:9000
nn2的RPC通信地址
dfs.namenode.http-address.ns.nn2
bd-2:50070
nn2的http通信地址
dfs.namenode.shared.edits.dir
qjournal://bd-3:8485/ns
指定NameNode的edits元数据在JournalNode上的存放位置
dfs.journalnode.edits.dir
/home/libing/hadoop-2.9.0/journaldata
指定JournalNode在本地磁盘存放数据的位置
dfs.ha.automatic-failover.enabled
true
开启NameNode失败自动切换
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
配置失败自动切换实现方式,使用内置的zkfc
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
配置隔离机制,多个机制用换行分割,先执行sshfence,执行失败后执行shell(/bin/true),/bin/true会直接返回0表示成功
dfs.ha.fencing.ssh.private-key-files
/home/libing/.ssh/id_rsa
使用sshfence隔离机制时需要ssh免登陆
dfs.ha.fencing.ssh.connect-timeout
30000
配置sshfence隔离机制超时时间
dfs.replication
1
设置block副本数为1(因为我们的DataNode虚拟机只有一台)
dfs.block.size
134217728
设置block大小是128M
保存并退出vi
4. 创建目录hdpdata和journaldata
[libing@bd-1 hadoop]$ mkdir ~/hadoop-2.9.0/hdpdata
[libing@bd-1 hadoop]$ mkdir ~/hadoop-2.9.0/journaldata
配置YARN
1. 修改yarn-site.xml
修改yarn-site.xml文件,在
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yarn-ha
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
bd-1
yarn.resourcemanager.webapp.address.rm1
${yarn.resourcemanager.hostname.rm1}:8088
HTTP访问的端口号
yarn.resourcemanager.hostname.rm2
bd-2
yarn.resourcemanager.webapp.address.rm2
${yarn.resourcemanager.hostname.rm2}:8088
yarn.resourcemanager.zk-address
bd-1:2181,bd-2:2181,bd-3:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/data/hadoop/yarn-logs
yarn.log-aggregation.retain-seconds
259200
保存并退出vi
2. 修改mapred-site.xml
先从模板复制一份mapred-site.xml
[libing@bd-1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
修改mapred-site.xml文件,在
mapreduce.framework.name
yarn
指定mr框架为yarn方式
mapreduce.jobhistory.address
bd-2:10020
历史服务器端口号
mapreduce.jobhistory.webapp.address
bd-2:19888
历史服务器的WEB UI端口号
mapreduce.jobhistory.joblist.cache.size
2000
内存中缓存的historyfile文件信息(主要是job对应的文件目录)
保存并退出vi
修改slaves文件
slaves文件保存了datanode节点,亦nodemanager节点所在主机的名称,,根据我们的集群规划,添加以下内容
bd-3
配置bd-1至所有主机(包括它自己)的ssh免密登录
之前我们已经通过将公钥文件内容添加到目标机器的authorized_keys文件中的方法,做过该配置了.
另外,还可以使用命令 ssh-copy-id -i 主机名来完成该操作.
配置bd-2至所有主机(包括它自己)的ssh免密登录
同上
启动(严格按照顺序)
1. 启动journalnode(在bd-3虚拟机上启动)
启动并使用jps命令验证
[libing@bd-3 hadoop-2.9.0]$ /home/libing/hadoop-2.9.0/sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/libing/hadoop-2.9.0/logs/hadoop-libing-journalnode-bd-3.out
[libing@bd-3 hadoop-2.9.0]$ jps
1616 Jps
1565 JournalNode
1022 QuorumPeerMain
2. 在bd-1上格式化HDFS
在命令行执行
/home/libing/hadoop-2.9.0/bin/hdfs namenode -format
输出的一大堆信息中,如下这一行表示格式化成功
17/12/25 12:56:41 INFO common.Storage: Storage directory /home/libing/hadoop-2.9.0/hdpdata/dfs/name has been successfully formatted.
格式化成功后,会在core-site.xml文件中的hadoop.tmp.dir指定的路径下产生dfs目录,将该目录拷贝到bd-2虚拟机的相同路径下
[libing@bd-1 hadoop]$ ll ~/hadoop-2.9.0/hdpdata
总用量 0
drwxrwxr-x 3 libing libing 18 12月 25 12:56 dfs
[libing@bd-1 hadoop]$ scp -r ~/hadoop-2.9.0/hdpdata/dfs libing@bd-2:/home/libing/hadoop-2.9.0/hdpdata/
VERSION 100% 218 92.0KB/s 00:00
seen_txid 100% 2 0.9KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 12.0KB/s 00:00
fsimage_0000000000000000000 100% 322 60.2KB/s 00:00
3. 在bd-1上执行格式化ZKFC操作
在命令行中执行
[libing@bd-1 hadoop]$ /home/libing/hadoop-2.9.0/bin/hdfs zkfc -formatZK
输出的一大堆信息中,如下这一行表示格式化成功
17/12/25 13:08:53 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK.
4. 在bd-1上启动HDFS
在命令行执行
[libing@bd-1 hadoop]$ /home/libing/hadoop-2.9.0/sbin/start-dfs.sh
Starting namenodes on [bd-1 bd-2]
bd-2: starting namenode, logging to /home/libing/hadoop-2.9.0/logs/hadoop-libing-namenode-bd-2.out
bd-1: starting namenode, logging to /home/libing/hadoop-2.9.0/logs/hadoop-libing-namenode-bd-1.out
bd-3: starting datanode, logging to /home/libing/hadoop-2.9.0/logs/hadoop-libing-datanode-bd-3.out
Starting journal nodes [bd-3]
bd-3: journalnode running as process 1565. Stop it first.
Starting ZK Failover Controllers on NN hosts [bd-1 bd-2]
bd-2: starting zkfc, logging to /home/libing/hadoop-2.9.0/logs/hadoop-libing-zkfc-bd-2.out
bd-1: starting zkfc, logging to /home/libing/hadoop-2.9.0/logs/hadoop-libing-zkfc-bd-1.out
5. 在bd-2上启动YARN
在命令行执行
[libing@bd-2 ~]$ /home/libing/hadoop-2.9.0/sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/libing/hadoop-2.9.0/logs/yarn-libing-resourcemanager-bd-2.out
bd-3: starting nodemanager, logging to /home/libing/hadoop-2.9.0/logs/yarn-libing-nodemanager-bd-3.out
同时,在bd-1上单独启动一个ResourceManager作为备份节点,在命令行执行
[libing@bd-1 logs]$ /home/libing/hadoop-2.9.0/sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/libing/hadoop-2.9.0/logs/yarn-libing-resourcemanager-bd-1.out
6. 在bd-2上启动JobHistoryServer
在命令行执行
[libing@bd-2 ~]$ /home/libing/hadoop-2.9.0/sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/libing/hadoop-2.9.0/logs/mapred-libing-historyserver-bd-2.out
7. 验证
访问NameNode(主)的web页面: http://192.168.206.132:50070
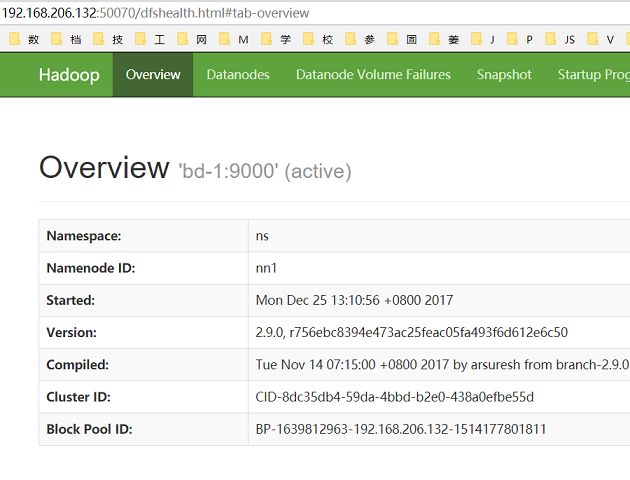
访问NameNode(备)的web页面: http://192.168.206.133:50070

访问ResourceManager的web页面: http://192.168.206.133:8088
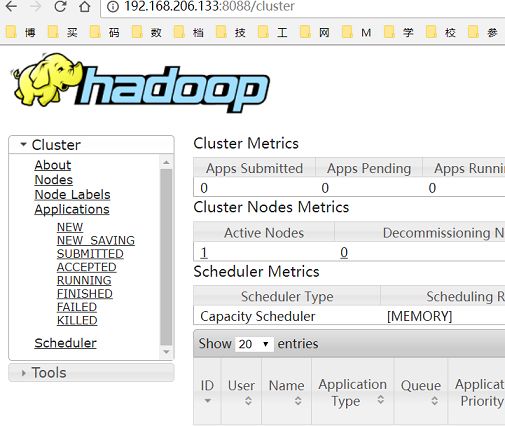
访问历史日志JobHistoryServer的web页面: http://192.168.206.133:19888
在每台虚拟机的命令行执行jps命令,查看进程(可以与集群规划进行对比验证)
bd-1虚拟机
[libing@bd-1 ~]$ jps
1604 QuorumPeerMain
5593 Jps
4893 NameNode
5198 DFSZKFailoverController
5455 ResourceManager
bd-2虚拟机
[libing@bd-2 ~]$ jps
2992 ResourceManager
2818 DFSZKFailoverController
3286 Jps
2712 NameNode
1049 QuorumPeerMain
bd-3虚拟机
[libing@bd-3 ~]$ jps
2208 DataNode
2311 JournalNode
2457 NodeManager
1050 QuorumPeerMain
2606 Jps
集群验证
1. 验证HDFS是否正常工作及HA高可用
在bd-1虚拟机的命令行执行
[libing@bd-1 ~]$ cd
[libing@bd-1 ~]$ echo HELLO > HELLO.TXT
[libing@bd-1 ~]$ hadoop fs -mkdir /HELLO
[libing@bd-1 ~]$ hadoop fs -put ./HELLO.TXT /HELLO
[libing@bd-1 ~]$ hadoop fs -ls /HELLO
Found 1 items
-rw-r--r-- 1 libing supergroup 6 2017-12-25 13:59 /HELLO/HELLO.TXT
[libing@bd-1 ~]$ hadoop fs -cat /HELLO/HELLO.TXT
HELLO
查看NameNode的主备状态
[libing@bd-1 ~]$ hdfs haadmin -getAllServiceState
bd-1:9000 active
bd-2:9000 standby
在bd-1虚拟机(NameNode主节点)上关闭NameNode
[libing@bd-1 ~]$ hadoop-daemon.sh stop namenode
stopping namenode
此时,http://192.168.206.132:50070已不可访问,而http://192.168.206.133:50070中的namenode状态已是active.
再次运行bd-1虚拟机上的NameNode
[libing@bd-1 ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /home/libing/hadoop-2.9.0/logs/hadoop-libing-namenode-bd-1.out
这时再次查看NameNode的主备状态
[libing@bd-1 ~]$ hdfs haadmin -getAllServiceState
bd-1:9000 standby
bd-2:9000 active
要注意bd-1上的NameNode变成了备,而bd-2依然保持为主.
2. 验证YARN是否正常工作
为demo程序wordcount运行创建所需的输入文件,并放入HDFS中
[libing@bd-1 ~]$ cd
[libing@bd-1 ~]$ mkdir wordcount
[libing@bd-1 ~]$ cd wordcount/
[libing@bd-1 wordcount]$ echo "Hello World Bye World" > file01
[libing@bd-1 wordcount]$ cat file01
Hello World Bye World
[libing@bd-1 wordcount]$ echo "Hello Hadoop Goodbye Hadoop" > file02
[libing@bd-1 wordcount]$ cat file02
Hello Hadoop Goodbye Hadoop
[libing@bd-1 wordcount]$ hadoop fs -mkdir /wordcount
[libing@bd-1 wordcount]$ hadoop fs -mkdir /wordcount/input
[libing@bd-1 wordcount]$ hadoop fs -put file01 /wordcount/input
[libing@bd-1 wordcount]$ hadoop fs -put file02 /wordcount/input
[libing@bd-1 wordcount]$ hadoop fs -ls /wordcount/input
Found 2 items
-rw-r--r-- 1 libing supergroup 22 2017-12-25 16:34 /wordcount/input/file01
-rw-r--r-- 1 libing supergroup 28 2017-12-25 16:34 /wordcount/input/file02
运行wordcount程序
[libing@bd-1 wordcount]$ hadoop jar ~/hadoop-2.9.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /wordcount/input /wordcount/output
17/12/25 16:36:05 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
17/12/25 16:36:05 INFO input.FileInputFormat: Total input files to process : 2
17/12/25 16:36:06 INFO mapreduce.JobSubmitter: number of splits:2
17/12/25 16:36:07 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address
17/12/25 16:36:07 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
17/12/25 16:36:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514190080786_0001
17/12/25 16:36:08 INFO impl.YarnClientImpl: Submitted application application_1514190080786_0001
17/12/25 16:36:08 INFO mapreduce.Job: The url to track the job: http://bd-2:8088/proxy/application_1514190080786_0001/
17/12/25 16:36:08 INFO mapreduce.Job: Running job: job_1514190080786_0001
17/12/25 16:36:17 INFO mapreduce.Job: Job job_1514190080786_0001 running in uber mode : false
17/12/25 16:36:17 INFO mapreduce.Job: map 0% reduce 0%
17/12/25 16:36:27 INFO mapreduce.Job: map 100% reduce 0%
17/12/25 16:36:35 INFO mapreduce.Job: map 100% reduce 100%
17/12/25 16:36:37 INFO mapreduce.Job: Job job_1514190080786_0001 completed successfully
17/12/25 16:36:37 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=79
FILE: Number of bytes written=614164
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=244
HDFS: Number of bytes written=41
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=16229
Total time spent by all reduces in occupied slots (ms)=5116
Total time spent by all map tasks (ms)=16229
Total time spent by all reduce tasks (ms)=5116
Total vcore-milliseconds taken by all map tasks=16229
Total vcore-milliseconds taken by all reduce tasks=5116
Total megabyte-milliseconds taken by all map tasks=16618496
Total megabyte-milliseconds taken by all reduce tasks=5238784
Map-Reduce Framework
Map input records=2
Map output records=8
Map output bytes=82
Map output materialized bytes=85
Input split bytes=194
Combine input records=8
Combine output records=6
Reduce input groups=5
Reduce shuffle bytes=85
Reduce input records=6
Reduce output records=5
Spilled Records=12
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=462
CPU time spent (ms)=3290
Physical memory (bytes) snapshot=543043584
Virtual memory (bytes) snapshot=6245363712
Total committed heap usage (bytes)=262721536
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=50
File Output Format Counters
Bytes Written=41
查看输出结果
[libing@bd-1 wordcount]$ hadoop fs -ls /wordcount/output
Found 2 items
-rw-r--r-- 1 libing supergroup 0 2017-12-25 16:36 /wordcount/output/_SUCCESS
-rw-r--r-- 1 libing supergroup 41 2017-12-25 16:36 /wordcount/output/part-r-00000
[libing@bd-1 wordcount]$ hadoop fs -cat /wordcount/output/part-r-00000
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
验证ResourceManager的HA高可用
查看bd-2的ResourceManager(主)的网页(http://192.168.206.133:8088/cluster/cluster),可以看到有如下信息
Cluster ID: 1514190080786
ResourceManager state: STARTED
ResourceManager HA state: active
ResourceManager HA zookeeper connection state: CONNECTED
查看bd-1的ResourceManager(备)的网页(http://192.168.206.132:8088/cluster/cluster),可以看到有如下信息
Cluster ID: 1514191475551
ResourceManager state: STARTED
ResourceManager HA state: standby
ResourceManager HA zookeeper connection state: CONNECTED
关闭bd-2上的ResourceManager
[libing@bd-2 ~]$ yarn-daemon.sh stop resourcemanager
stopping resourcemanager
可以发现bd-2的网页(http://192.168.206.133:8088/)已不再可访问.而bd-1的网页(http://192.168.206.132:8088/cluster/cluster)中的信息已变为
Cluster ID: 1514191923489
ResourceManager state: STARTED
ResourceManager HA state: active
ResourceManager HA zookeeper connection state: CONNECTED
注意,"ResourceManager HA state"已经由"standby"变为了"active".
再次启动bd-2上的ResourceManager
[libing@bd-2 ~]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/libing/hadoop-2.9.0/logs/yarn-libing-resourcemanager-bd-2.out
分别查看bd-1和bd-2的ResourceManager网页,可以发现bd-1的ResourceManager仍为"active",而重新启动后的bd-2的ResourceManager变为"standby".