序
无利不起早。1月23日4:30起来赶高铁去上海,就是为了听邓辉和孙鸣老师的课。邓辉老师讲了两个主题《设计的价值与未来》和《从问题到系统》,孙鸣老师讲的是《正确性驱动建模:用TLA+设计系统》,都非常精彩。
解决问题的途径
必须用新技术吗?
知乎上有一个讨论“为什么有不少互联网公司在面对开发中的问题时,会倾向于使用新技术解决?"的帖子,我看大多数回复都是说新技术的价值以及为什么要用新技术。这里不要纠结“新技术”的定义,新出现的新理论、新方法、新工具、新语言等都是这里讨论的新技术范畴。我认为作者抛出的这个问题还得仔细分析,首先”开发中的问题“必须都要新技术来解决吗?
比如解决并发的问题就非得用go吗?Erlang这种支持电信级高并发、容错的语言已经30多年的历史,不能算是新技术吧?退一步说,”开发中的问题“用现有的语言比如java就不能解决吗?这里面不可避免的夹杂着“喜新厌旧”、“装逼”的人性的因素。DevOps被炒得烂的差不多的时候,现在又开始AIOps了,然而DevOps我们搞好了么?
曹冲称象的故事可以给我们很多启发。首先要搞清楚为啥要用新技术,即要问自己新的技术是否能解决目前的问题,大部分问题是因为没有把握问题的本质导致。新的技术,开始或许会简单,但是随着问题的深入,后面遇到新的问题,那么问题固有的困难是什么?这些固有的困难是与编程语言无关的。

图1是我们看到过各种技术,不是说这些技术不好,也不是说下面的就比上面的技术更有效,比如我就比较喜欢TDD(测试驱动开发)的技术,也喜欢领域驱动的技术。这里列出这些技术的目的是想问一下,xxx系统要解决的问题必须要用这些“时髦”的技术吗?“一寸长一寸强,一寸短一寸险”,各个技术都有各自的优缺点,我们在解决问题时需要综合考虑,达到一种平衡。
何时用新技术?
不是不用新技术,而是不能不经研究而随便用新技术。历史上有很多使用新技术很好的解决问题的故事。
为了研究“动量的变化率”,弄清楚速度就能满足牛顿的要求,而速度是位置的变化率。对这个问题的研究,使他掌握了揭开变化率及其度量的全部秘密的万能钥匙--微分学,由变化率产生的“怎样计算一个速度每时每刻都在变化的运动质点在给定时间内跑过的全部距离”的问题又使牛顿掌握了积分学。最后,牛顿又发现了微分学和积分学的密切联系,这就是“微积分学的基本定理”,微积分学的创立,极大地推动了数学的发展,过去很多用初等数学无法解决的问题,运用微积分,这些问题往往迎刃而解。
也有因为技术的局限性失败的例子。写给程序员的范畴论(英文原文)中举了一个例子,法国的博韦有一座未完工的哥特式教堂,它的设计企图在高度与采光方面击败所有的教堂,但是建造中却出现了一系列的崩塌。当时不得不用钢梁木柱临时做成支撑架构来阻止崩塌,但于事无补,因为很多东西在设计上就是错的。这个例子说明,有些事情必须要使用新的技术、工具才能完成,所以学习和应用新技术也是很重要的。
当我们在解决问题的过程中,发现解决的问题缺少相应的技术和工具时,这时就需要研究、创造新的技术和工具。
什么是设计
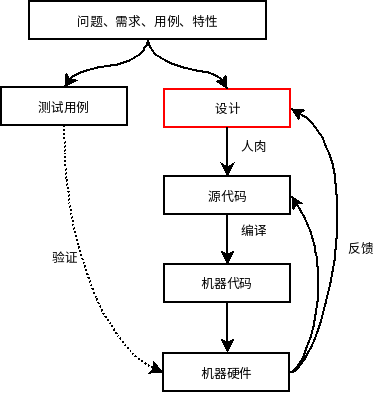
图2是我们开发的整个过程中设计所处的位置。从问题、需求、用例、特性到设计,然后根据设计通过人肉生成源代码,再把源代码编译成机器代码,最后到机器硬件执行,另一边是通过测试用例验证执行的结果是否正确。这里考虑两个问题:
- 写测试用例时你在想什么?
- 做设计时你在想什么?
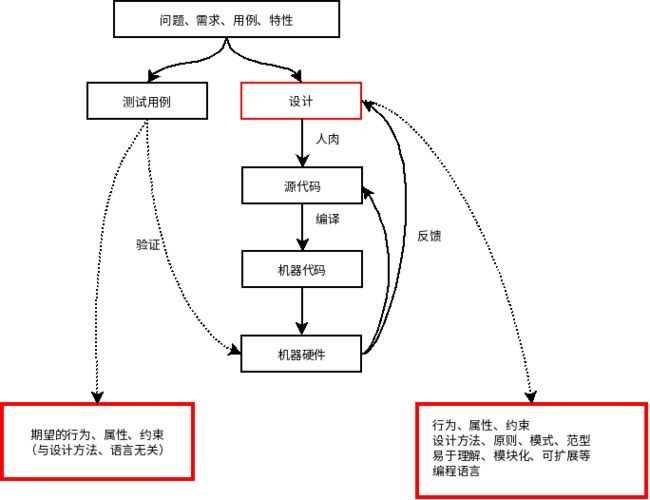
考虑图中测试、设计是一个什么过程。我们知道,写测试用例时,是先把期望的行为、属性、约束表达出来,然后验证系统运行的行为是否和期望的一致,这个过程与设计方法和语言是没有关系的。从这个角度来理解TDD时,你应该能够明白它的好处,因为它也是面向问题约束的,迫使你考虑系统的属性和约束。再来看设计,设计也是针对系统的行为、属性和约束进行的,在设计过程中会采用一系列的设计方法、原则和模式等,而且还有考虑设计的可理解性、模块化和可扩展性等,最后还要考虑使用的编程语言。有些过程是因为有人的参与才引入的,而且带有主观性。比如说可理解性,你说两行代码好理解还是十行代码好理解?这个是说不清楚的,但是如果是一万行肯定不好理解。
其实设计方法、可理解性等都是为了产生可执行的代码服务的。那么设计方法、设计原则、设计模式又是为了什么呢?
设计的价值

从上图可以看出,从问题内在的行为、约束和属性到产生源代码之间有一个鸿沟,目前是不能自动完成的。我们根据系统的行为、约束和属性选择一些设计方法、原则、模式等,来指导设计方案,形成文字、图示和原型,然后经手工翻译成源代码,而设计方案的可理解性、模块化和可扩展性等是为人设计的,与产生源代码无关。所以设计方法、设计原则、设计模式这些过程都是为了“半自动化”的产生代码。设计->开发->测试,最后发现问题再反馈到设计,这个迭代循环的过程,实际是一种人参与的强化学习的过程(是不是听着很熟悉^^)。

靠人参与的东西一般都有瓶颈,一旦这些能够自动化,那么原来人们引以为傲的技术都将不值一提。
系统的行为、约束和属性是严格、精确、抽象和简洁的,源代码也是严格、精确、具体的,如果能把设计的过程自动化,从系统的行为、约束和属性能够直接生成源码,那么就能消除由人的参与引入的瓶颈,现有的设计方法、原则、模式等都不再需要,更不用考虑什么易理解、模块化、可扩展等问题(当然,一大批程序员就不再需要了)。
设计的未来
AlphaGo的启发
我们经常说设计是一门艺术,一般当我们对某项技术还没有搞清楚时都会说它是艺术。围棋也一样,至今已有四千多年的历史,一直是智慧、艺术的象征,在AI领域被认为是最具挑战的棋类游戏。而当AlphaGo击败人类职业围棋选手时,在全世界引起巨大的轰动,而由此引发的人类对人工智能的恐慌更是前所未有。难道人类几千年来积累下的智慧在冷冰冰的机器面前就如此不堪一击吗?作为一个程序员,并不应该有太多恐慌。人类是有智慧的,能驾驭在某方面能力远远超越自己的东西。人不会飞,但是能造出飞机;人的力气不够大,但是可以造出拖拉机、挖土机;人走的慢,但是能造出汽车。如此看来,人类与AlphaGo、AlphaGo Zero比赛下围棋,与人类和汽车、飞机比赛谁跑的快有何区别呢?但是人工智能的发展确实会让某些单一技能的职业消失。
回归到我们的正题,对于设计来讲,从AlphaGo我们能得到那些启发呢?
AlphaGo在技术上其实并没有创新,主要还是工程实践上的优化,其核心框架主要是
- MCTS(蒙特卡罗树搜索,统计学方法)
- 深度神经网络(空间太大,模拟启发)
- UCB(置信区间,随机选择概率低的点,鼓励创新)
其中深度神经网络是最可能被取代的,它是一种具体的模拟启发的方法,而其它两种是数学方法。
是否可以用AlphaGo的思路解决软件开发的问题?生成源代码的规则是否可以自动化?
来看一下AlphaGo解决问题的特征。首先,和其它棋类一样,围棋的目标很明确,有明确的判断输赢的标准,基于这个判断标准就可以给出走棋的好坏;其次, 有生成完整棋局的规则,围棋棋局的可能性在 10170数量级,比宇宙中的原子数量为1080还要多的多,也就是说围棋的搜索空间太大,不能靠穷举的方式,如何在减少搜索空间的前提下又保证解的最优是考虑的核心问题,深度神经网络就是解决空间太大的问题,而为了像人一样,有时需要出"奇招",以便寻找创新,这个是UCB策略的作用。
在解决软件开发的问题时,我们是否也可以找到类似的方法?前面讨论设计问题的时候,我们了解到,从设计、开发到测试再反馈到设计这样一个迭代循环过程,实际是一种人参与的强化学习的过程。也就是说在庞大的解的空间逐渐逼近最优解的过程,我们需要找到把人参与的过程规则化、自动化的方法。
从这些特征给我启发:
- 严格、精确的系统规格说明(目标)
- 行为、属性、约束 - 程序导出、变换(生成规则)
- 语义模型
- 抽象-精化(Abstraction-Refinement)
- Equational Reasoning
几个例子
下面几个例子来理解前面讲的目标和生成规则。
Genetic Programming(遗传编程)
遗传编程(GP)是机器学习的一种,开始于一群由随机生成的千百万个计算机程序组成的"人群",根据一个程序完成给定的任务的能力来确定某个程序的适合度,应用达尔文的自然选择(适者生存)确定胜出的程序。这里“合适度”就是评价程序好坏的标准,而其生成规则则是利用交叉、变异、评估等操作,是一种自动随机产生搜索程序的方法,所以最终产生的程序可能完全出乎人的预料。对于生物的“优胜劣汰”中的“胜”就是交给大自然来选择,能生存下来的就是“胜者”。而遗传编程中很难找到这样一种通用的评估函数。不管怎样,遗传编程已经成功地应用于许多不同的领域,而且在近几年中得到了更深入的研究。

上图是遗传编程的流程图,个体(individual)程序一般用树型结构表示,并且有不同类型的基因组成。下图是一个称为" two-offspring crossove"的例子。

Specification As Abstraction
抽象的本质
有了严格、精确的系统规格说明,还需要给出其语义模型,然后通过抽象、精化,再进行等价推理,就可以从规格说明导出程序。
先来看这样一段代码:
if currentLocation() == Korea then
say "안녕하세요"
else
say "Hello"
fi
你应该很快就能看明白,这个是在用两种不同的方式说“你好”。if后面是根据当前所处的国家来进行选择说英语还是韩语。想一下,if后面不仅仅可以根据国家来区分,还可以有很多其它的条件,从外部的行为来看,好像就是有时在说韩语,有时在说英语,至于条件的内容并不是我们关心的,就像这样:
if ??? then
say "안녕하세요"
else
say "Hello"
fi
再进一步把说的内容抽象,我们不单单可以打招呼,可以是任何其它事情,即我们不再关注具体的内容,可能是P也可能是Q:
if ??? then P else Q fi
是否可以再抽象一点?比如,可以简化为
P + Q
这样是不是很抽象,可以表达的内容更多?
关于语义的抽象可以总结以下几点:
- 用不确定性忽略无关的行为
- 用状态变迁关系表达语义
状态变迁是初始状态到所有可能结束状态的集合。 - 状态是变量到值的映射
简单来说抽象的本质就是不确定性。以前有个故事说有个人进京赶考,问一个算命先生自己能考第几名,先生没有说任何话,只是伸出一根手指头。这可厉害了,考个第一说的也对,考个最后也对,看到抽象的威力了吧:)
语义模型就是系统行为的集合,抽象是这个集合大小的度量,越抽象,行为集合越大,我们说程序A是程序B的抽象,可以记做:
从规格说明导出程序
-
一个简单的语言

-
语义定义

假如我们要用这个语言实现如下的规格说明,如何做?

-
句法的精化计算

-
程序推导
根据上面的精化计算规则:

程序是推导出来的,其正确性是有保证的。这个过程还需要深入阅读相关书籍才能完全明白,文章最后列出了一些书籍。
Caculating a Compiler
(这部分功力不到,修炼后再详细说明^^)
一个简单语言的编译器
语法和语义
data Expr = Val Int | Add Expr Expr
eval :: Expr -> Int
eval (Val n) = n
eval (Add x y) = eval x + eval y
规格说明
comp :: Expr -> Code
comp' :: Expr -> Code -> Code
exec :: Code -> Stack -> Stack
exec (comp e) s = eval e : s
exec (comp' e c) = exec c (eval e : s)
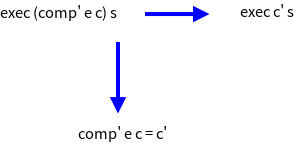
exec (comp' (Val n) c) s
= {specification of comp'}
exec c (eval (Val n) : s)
= {applying eval}
exec c (n : s)
exec c' s = exec c (n : s)
PUSH :: Int > Code -> Code
exec (PUSH n c) s = exec c (n : s)
exec c (n : s)
= {unapplying exec}
exec (PUSH n c) s
comp' (Val n) c = PUSH n c
data Code
= HALT | PUSH Int Code | ADD Code
comp :: Expr -> Code
comp e = comp' e HALT
comp' :: Expr -> Code -> Code
comp' (Val n) c = PUSH n c
comp' (Add x y) c
= comp' x (comp' y (ADD c))
exec :: Code -> Stack -> Stack
exec HALT s = s
exec (PUSH n c) s = exec c (n : s)
exec (ADD c) (m : n : s)
= exec c (n + m : s)
通过这些例子我们相信程序的自动导出是有可能的,加上机器学习,就可以有效、快速的生成源代码。
我们该如何做
面向未来的学习
-
系统规格说明
- 离散数学 - TLA+, Alloy - 清晰、严格的思考和表达 - 可运行、可调试、自动穷举验证的设计 -
程序语言理论
- 语义学 - 类型系统 - 编译和解释 -
抽象和组合
- Denotational Semantics - Category Theory
如何对待工作
-
认真对待测试用例
- 清晰、严格思考表达 - 系统行为、属性 -
维护老系统,认真分析解决每一个Bug
- 深入理解系统的行为、属性和约束 - 收益要远大于用新技术、新语言开发新系统 -
以全局的眼光和理论的态度学习“流行”技术
- 问题、团队、成本、收益等 - 规范、稳定、可控的代码人肉生成
推荐读物
-
Specifying Systems

-
Essentials of Programming Languages

-
Software Abstractions: Logic, Language, and Analysis

-
Denotational semantics: A methodology for language development

-
Types and Programming Languages

-
Category Theory for Programmers
