显然,分解容易(一分为二),组合难。
快速排序
刚刚分析过了,快速排序是枢轴记录划分,也就是分解难,但是组合易。 A[1…k-1] ≤ A[k] ≤ A[k+1…n]

因为这些细节一般只影响常数因子的大小,不改变量级。求解时,先忽略细节,然后再决定其是否重要!
分析的方法
替换法
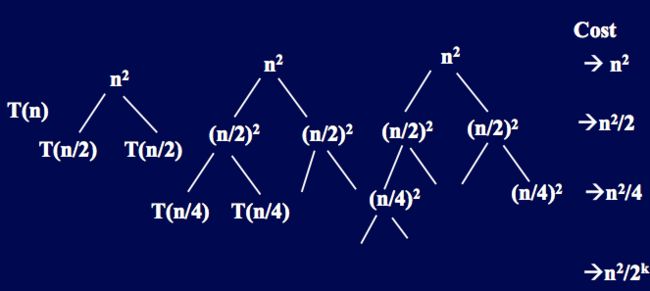
The master method(通用法,万能法)
可迅速求解
递归通俗的说就是一个函数调用函数自己(本身),这个调用过程叫递归,递归是一把双刃剑(有时方便,有时不好),如果需要处理重复的需要多次计算的问题,通常可以选择用递归或者循环两种方式,但是递归的执行效率不如循环语句。
注意:必须设置终止递归的条件检测,否则慎用。
void up_and_down(int);//函数原型声明
int main() { up_and_down(1);//调用递归函数
system("pause");
return 0; }
void up_and_down(int n) { printf("level%d, n地址=%p\n", n, &n); if (n < 4) { up_and_down(n + 1); } printf("LEVEL%d, n地址=%p\n", n, &n); }
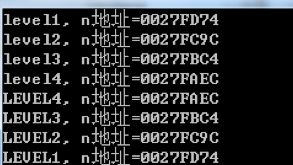
首先,main函数用参数1调用递归函数,递归函数形参n=1,打印语句level1……然后,n<4,故函数本身使用参数n+1=2,第二次调用自己,这样就打印了level2……
以此类推,当执行到第四级调用,n=4,if失效,不再调用函数,而是执行了第二句打印,先输出LEVEL4……此时第四级调用结束,控制权返回给了主调函数,也就是第三级主调函数,此函数中上一句是if语句,已经执行完毕,然后继续执行第二句打印语句,输出LEVEL3……第三级调用结束,返回控制权给调用函数(也就是第二级主调函数),然后第二级函数开始继续执行,以此类推,打印LEVEL2,1……
递归的基本原理
每一级递归都使用自己这一级的私有变量n,同级调用时的地址和返回的地址是一样的。好好揣摩!
这是函数自己在一层层的往深度调用自己,然后一层层的往回返,每到一层,就继续执行接下来的语句(故调用开始的地址和返回的地址一样),而每一级递归都是用自己的局部变量。也就是第一级的n不同于第二级的n,这样子,函数逐步调用然后逐步返回直到main函数里。
递归函数里,递归语句之前的语句和各级被调的递归函数执行顺序一致,而递归语句之后的语句和被调的递归函数执行顺序相反(这一特点针对涉及反向顺序的编程问题很有用)
递归函数必须包含可以终止的条件,因为递归可以替代循环,故必须有终止
尾递归
最简单的递归:递归语句放到函数末尾,恰在return语句前,叫做tail recursion(尾递归),因为出现在函数尾部,作用相当于一条循环语句。
//计算阶乘(递归和循环) #include#include //计算阶乘 int factorial(int); int loopFactorial(int); int main() { int num; printf("输入1-12的整数,q退出\n"); while (scanf_s("%d", &num)) { if (num < 0) { printf("error!输入1-12的整数!"); } else if (num > 12) { printf("输入1-12的整数!"); } else { printf("\n%d的阶乘=%d", num, factorial(num)); printf("\n%d的阶乘=%d", num, loopFactorial(num)); } printf("\n输入1-12的整数"); } system("pause"); return 0; }
//循环计算阶乘 int factorial(int n) { int temp; for (temp = 1; n > 1; n--) { temp *= n; } return temp; }
//使用递归计算阶乘 int loopFactorial(int n) { int temp; if (n > 0) { temp = n * loopFactorial(n - 1);//属于尾递归,如n>0那么这就是最后一句 } else { temp = 1;//必须要有递归结束判断条件! } return temp; }
注意:整型范围,32位机器,int类型最大到21多亿,再大的话,就要用long long或者double类型,一般来说,选择循环比较好些,递归每次调用都要有自己的变量集合,占据内存大,每次都要存储新的变量集合到堆栈,这样速度慢,但是递归(最简单的是尾递归)比较简单。一些情况还是要用。
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!
