云平台及监控工具的部署流程
说在前面的话
云平台的基础搭建流程是一项基本但又必备的技能,从大四做毕业设计到研究生在实验室集群搭建hadoop及spark再到参与某为公司大型集群性能预测项目,可以说对于这一部分的搭建工作,真的是闭着眼不参考任何资料可以在很短时间内完成。
本篇博客将完整地介绍Hadoop+Spark+hive+Ganglia+Nagios+Nmon的搭建流程,涉及到的内容较多,因此打算分为两部分进行总结。本次先介绍基础的云平台的搭建。
效果预览
先贴上最终搭建完成后Web端的图吧。
Hadoop HDFS界面

Hadoop NM界面

Spark界面

Hive database查看

Hive 创建表

Hive 表查询

Ganglia整体集群监控图(以CPU为例)

Ganglia单节点CPU监控图

Ganglia对Hadoop的监控(以heartbeat为例)

Nagios对集群的整体预警效果
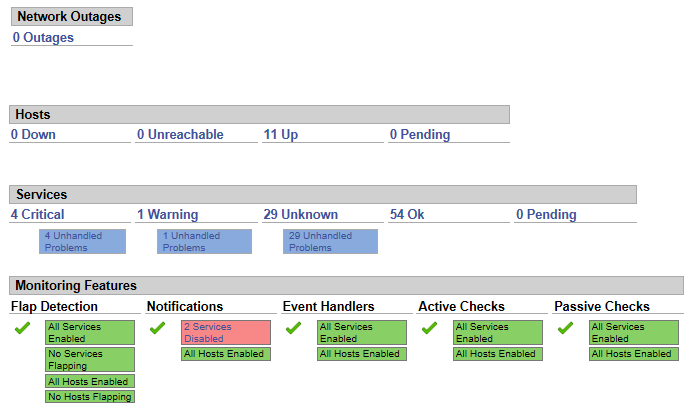
Nagios对单节点的预警效果

Nagios对各个主机服务及进程的预警效果

Nagios对各个主机健康情况的监控情况

生产环境下是需要使用各类监控工具对集群整体进行健康预警的。除此之外,其实有很多开源的项目可以集成这些工具,例如:Ambari等,国内腾讯华为也有相关的一些产品,不过貌似用于商业的,自己用的话Ambari是比较好的选择,另外就是传统的Ganglia和Nagios。
环境配置
我使用了实验室的十台DELL服务器进行搭建,配置不算太高,毕竟服务器年事已高,但10台一起还是能够应付了日常研究和学习的。因为需要环境的同态,所以事先全部进行CentOS6.5的重新安装。系统安装就不介绍啦,毕竟大家都是搞IT的。
软件环境:
Hadoop-2.7.3
Spark-2.1.0
Hive-2.1.1
Ganglia-3.7.1
Nagios-3.5.1
10台节点划分:1台master,9台数据节点
Hadoop+Spark部署
第一步 准备安装包
在Apache官网下载自己想要的版本,当然现在spark最新稳定版到2.2.0了,我们这里使用hadoop-2.7.3和spark-2.1.0. 下载.tgz的压缩包,Spark下载编译好的版本,如果自己要自己编译,也可以使用未编译版本,然后使用SBT或是Maven进行手动编译即可,这里我们直接使用编译版本spark-2.1.0-bin-hadoop2.7.tgz即可。除此之外,需要下载JDK-Linux, 1.8版本及以上都可以,还有Scala-Linux,2.11及以上都可以,同样进行相同目录的解压。
下载好后可使用FTP工具将压缩包上传到集群主节点(先在主节点将各种配置文件修改好后可以分发到各个数据节点)
我这里在主节点root用户下,进入/home/下创建了 /cluster 目录,用户安装全部所需的包。
将hadoop和spark压缩包解压至/home/cluster下,解压过后分别对应文件名:hadoop-2.7.3 和 spark-2.1.0
第二步 SSH免密码
网上其他帖子都先安装了ssh免密钥服务,其实只要还没有分发文件,什么时候配置这个都是可以的。
ssh服务提供一个各个机器之间方便访问以及通信的功能,试想一下,假如没有这样一个东东,那么我们的hadoop启动时就会弹出数次要求输入密码的提示,这都不算啥,你敢想象启动后发送心跳还得手动输密码有多烦不,因此,需要配置一下ssh。
配置方法网上都有,不过首先先进入~/.ssh目录下,将其内容全部清空,然后敲入 ssh-key gen -t RSA,然后一直回车即可,你会看到~/.ssh目录下会产生id_rsa , id_rsa.pub这俩文件,同样的操作在次节点执行一次,将次节点的id_rsa.pub通过scp命令发送到主节点(随便间隔文件夹先存着,如果要放入主节点的/.ssh目录下,请提前修改其他节点传过来的id_ras.pub的名字,例如修改为id_rsa_node01.pub即可)。与此同时,请先在主节点的/.ssh目录下手动创建一个authorized_key文件。( scp命令格式如下:)
scp ~/.ssh/id_rsa.pub root@sist01:~/sshkey/sist02_id_rsa.pub
(其中sist01是主节点,实例代码是从sist02中远程拷贝id_rsa.pub到主节点sist01中)
待全部拷贝到主节点后, 依次将次节点和主节点的这些id_rsa.pub的内容追加进主节点~/.ssh下的authorized_key文件中,追加内容的代码如下所示:
cat sshkey/id_rsa.pub>> ~/.ssh/authorized_keys
此时再次使用scp远程将我们追加后的authorized_key文件传到各个次节点的~/.ssh目录下
至此,你的ssh,不妨可以来测试一下,在主节点root下敲入·ssh sist02,首次会要求输入密码,连接到sist02后,敲入exit退回到sist01,再次ssh sist02此时就可以无密码访问啦。
第三步 配置Hadoop以及Spark
注意:
以下 配置均先在主节点下完成
3.1 Linux环境变量
我们需要配置的Linux系统文件有两个,因为我要在root下安装hadoop等,所以均在root下配置如下两个文件:
/etc/profile
/etc/hosts
对文件的修改使用vim file_name命令
hosts文件中将集群中所有所节点的主机名和ip配置进去,例如:
sist01 192.168.xxx.xxx
sist02 192.168.xxx.xxx
.....
profile文件中需要添加解压后的JDK,Scala,spark和hadoop的路径等信息。
可以参考我的profile文件(只需将路径换为自己的路径即可):
## JAVA
export JAVA_HOME=/home/hadoop/softwares/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
## HADOOP
export HADOOP_HOME=/home/hadoop/softwares/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
## scala
export SCALA_HOME=/home/hadoop/softwares/scala-2.11.7
export PATH=$PATH:$SCALA_HOME/bin
## spark
export SPARK_HOME=/home/hadoop/softwares/spark-2.1.0
export PATH=$PATH:$SPARK_HOME/bin
配置结束后,需要在root下敲入source /etc/profile使配置立即生效。
此时分别敲入java -version scala -version查看是否显示版本号,验证是否安装成功。
同时敲入hadoop,如果打印出一大堆信息,那么证明成功。
3.2 配置Hadoop
我们需要配置hadoop-2.7.3/etc/hadoop/目录下的如下几个文件。同样可以使用vim命令来修改,或是使用WinSCP工具来本地远程修改。(建议还是vim吧,毕竟保持linux的熟悉度还是重要的)
core-site.xml
hdfs-site.xml
mapred-site.xml
slaves
yarn-site.xml
hadoop-env.sh
注意:如果文件夹下上述文件是.template结尾,那么就用cp file_name.template file_name复制一份出来即可。
配置前,需要创建hadoop tmp临时目录以及pid的存放目录。pid可以不配置,默认放在系统tmp下,但是一般生产集群都是有自己的pid文件夹,有利于集群的高可用。
自己找个目录,mkdir hadooptmp创建该文件夹,进入hadooptmp目录,接着分别创建name、data、local、log、pid文件夹。
core-site.xml中我的配置如下:
fs.defaultFS
hdfs://主节点ip:9000
hadoop.tmp.dir
/home/hadoop/hadooptmp/tmp
hadoop.native.lib
true
io.file.buffer.size
131072
hadoop.native.lib
true
hdfs-site.xml:
dfs.namenode.http-address
主节点ip:50070
dfs.namenode.secondary.http-address
主节点ip:50090
dfs.namenode.name.dir
/home/hadoop/hadooptmp/name
dfs.datanode.data.dir
/home/hadoop/hadooptmp/data
dfs.replication
3
dfs.webhdfs.enabled
true
dfs.client.block.write.replace-datanode-on-failure.enable
true
dfs.permissions
false
mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
主节点ip:10020
mapreduce.jobhistory.webapp.address
主节点ip:19888
mapreduce.jobhistory.done-dir
/jobhistory/done
mapreduce.jobhistory.intermediate-done-dir
/jobhistory/done_intermediate
mapreduce.job.reduce.slowstart.completedmaps
1
mapreduce.jobhistory.max-age-ms
2419200000 %保存4周
mapred-default.xml
其中我们配置了日志聚合,打开了jobhistory server,并设置日志保存4周。日志聚合全部在HDFS中的目录下,因此正如上述配置的目录:/jobhistory/done、/jobhistory/done_intermediate,都将在启动hadoop后手动创建好后再启动history server。
slaves:
写入全部的次节点的hostname,分行即可,不需要逗号,例如:
sist02
sist03
......
yarn-site.xml
yarn.resourcemanager.hostname
主机点hostname
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
主节点ip:8032
yarn.resourcemanager.scheduler.address
主节点ip:8030
yarn.resourcemanager.resource-tracker.address
主节点ip:8031
yarn.resourcemanager.admin.address
主节点ip:8033
yarn.resourcemanager.webapp.address
主节点ip:8088
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/transfered/logs
yarn.log.server.url
http://主节点ip:19888/jobhistory/logs
yarn.nodemanager.disk-health-checker.min-healthy-disks
0.0
yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage
100.0
yarn.nodemanager.disk-health-checker.enable
false
yarn.nodemanager.local-dirs
/home/hadoop/hadooptmp/local
yarn.nodemanager.log-dirs
/home/hadoop/hadooptmp/log
其中配置的/transfered/logs同样是在HDFS中创建,用于日志聚合。
hadoop-env.sh:
找到如下PID配置项,修改为自己预先创建的pid路径:
export HADOOP_SECURE_DN_PID_DIR=/home/hadoop/softwares/pid
修改java路径为自己的JDK路径:
export JAVA_HOME=/home/hadoop/softwares/jdk1.8.0_65
到这里,hadoop的配置文件就全部完成。
3.3 Spark文件配置
Spark需要配置的文件为/spark-2.1.0/conf/下的几个文件:
slaves
spark-env.sh
spark-default.conf
同样cp命令复制.template文件
slaves:
次节点的全部hostname,与hadoop中的slaves配置相同
spark-env.sh最后添加如下配置:
export SCALA_HOME=/home/hadoop/softwares/scala-2.11.7
export HADOOP_CONF_DIR=/home/hadoop/softwares/hadoop-2.7.3/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/software/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=主节点ip
export SPARK_MASTER_HOST=主节点hostname
export JAVA_HOME=/home/hadoop/softwares/jdk1.8.0_65
export HADOOP_HOME=/home/hadoop/softwares/hadoop-2.7.3
export SPARK_DIST_CLASSPATH=$(/home/hadoop/softwares/hadoop-2.7.3/bin/hadoop classpath)
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
export SPARK_LOCAL_DIRS=/home/hadoop/softwares/spark-2.1.0
export MASTER=spark://主节点hostname:7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_MASTER_PORT=7077
#export SPARK_WORKER_MEMORY=5g
#export SPARK_WORKER_CORES=4
#export SPARK_WORKER_INSTANCES=1
#export SPARK_EXECUTOR_MEMORY=5g
#export SPARK_DRIVER_MEMORY=2g
上面注视调的配置可以根据自己的集群进行修改,不做配置的话会按照默认配置。
spark-default.conf最后添加如下配置:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://主节点ip:9000/historyforSpark
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.yarn.historyServer.address http://主节点ip:9000:18080
spark.history.fs.logDirectory hdfs://主节点ip:9000:9000/historyforSpark
至此Spark配置完毕。
3.4 分发文件到此节点
一个个进行SCP将上述全部文件拷贝到次节点太繁琐,所以提供一个脚本,用于批处理远程拷贝(可兼容拷贝文件夹):
#/usr/bin/sh
SOURCEFILE=$1
TARGETDIR=$2
hosts="sist02 sist03 sist04 sist05 sist06 sist07 sist08 sist09 sist10"
for host in $hosts
do
echo $host;
scp -r $SOURCEFILE root@$host:$TARGETDIR;
done
使用上述脚本,修改脚本中的hostname即可。
使用方法:
./scptool.sh (要拷贝的文件夹或文件名) (远程节点的目录)
依次将 Scala/ ,JDK/, Spark-2.1.0/, Hadoop-2.7.3/, hadooptmp/,/etc/hosts, /etc/profile进行远程拷贝,记得每台机子都要敲入source \etc\profile使文件生效。
每台机子确认一下java scala hadoop都生效,按照前文所说的方法进行验证。(此处如果节点较多也可自行写脚本进行查看)
第四步 启动Hadoop和Spark
4.1 hadoop启动
主节点
hadoop namenode -format
运行结束后,在打印的日志倒数几行如果出现了format successful,则说明格式化正确。
此时可以启动hadoop集群啦!
使用命令:
start-all.sh
jps查看各个进程是否都正常启动。浏览器登录http://主节点ip:50070查看HDFS详细信息,里面顺便查看datanode一栏,看看自己所有的次节点是否都被正常启动。
此时先不要开启jobhistory server。
需要先在HDFS上创建日志聚合目录,也就是上文所提到的那几个目录。使用命令:
hadoop fs -mkdir /name
以此创建好,进入hadoop-2.7.3/sbin下,敲入如下命令:
./mr-jobhistory-daemon.sh start historyserver
浏览器登录http://主节点ip:19888查看historyserver是否正常启动。
恭喜你,Hadoop部署成功!!
4.2 spark启动
启动前,先在HDFS创建historyforSpark目录,用于存放spark history server的日志。
随后,进入spark-2.1.0/sbin下输入以下命令启动spark
./start-all.sh
jps查看主节点下master进行是否正常。浏览器登录http://主节点ip:8080查看各节点是否正常。
紧接着敲入一下命令来启动spark的history server
./start-history-server.sh
jps查看进程是否正常,登录http://主节点ip:18888查看是否正常启动。
恭喜你Spark也启动成功!!!
问题解决
1、如果启动不成功,不管是进程启动不全还是全部都没起起来,先检查防火墙是否关闭!在检查selinux是否设置为disabled。方法如下
临时关闭selinux:
setenforce 0 //设置SELinux 成为permissive模式
彻底禁用selinux:
使用root用户,vim /etc/sysconfig/selinux,将SELINUX=enforcing修改成SELINUX=disabled。
重启后才能生效。
临时关闭防火墙:
service iptables stop
永久关闭防火墙:
chkconfig iptables off
2、如果不存在上述问题,需要视情况而定!列举一些情况:
- 如果报错信息透漏出时间不同步的情况,则说明各台节点的时间不相同,如果服务器没有联网,则最简单的办法可以使用ntp来手动同步,同样适用于联网服务器,当然有网的话可以网上直接同步。ntp安装及使用如下:
1、yum install -y ntpdate 安装ntp服务
2、service ntpd stop 关闭时间服务器
3、ntpdate us.pool.ntp.org 更新时间
4、service ntpd start 开启
5、date 查看时间
- 如果依然是时间类似的问题,上述方法未能解决的话,可能是同步后各个节点的时间戳依旧没能同步,此时可以先停掉全部进程,然后删除各个节点下hadooptmp下所有子目录下的全部文件,注意不要删除文件,只需要删除data、name、tmp等目录下的全部东西即可。可用如下批量删除脚本:
/usr/bin/sh
SOURCEFILE=$1
rm -rf /home/hadoop/hadooptmp/data/*;
rm -rf /home/hadoop/hadooptmp/name/*;
rm -rf /home/hadoop/hadooptmp/tmp/*;
rm -rf /home/hadoop/softwares/hadoop-2.7.3/logs/*;
rm -rf /home/hadoop/softwares/spark-2.1.0/logs/*;
rm -rf /home/hadoop/hadooptmp/nmlocal/*
rm -rf /home/hadoop/hadooptmp/nmlog/*
删除完后,重新format namenode,再看看是否还有问题。
- 如果出现权限问题,请注意启动hadoop的用户须和安装hadoop的用户是同一个用户。
- 如果是文件夹权限问题,无论是本次的tmp、name等还是HDFS上的日志聚合文件,都可以手动更改权限为755来解决。
我的博客 : https://NingSM.github.io
转载请注明原址,谢谢。