一、前言
这篇博客来分析一下TCP数据传输中发生的粘包、拆包问题,我将描述一下这两种情况的概念,分析它们发生的原因,最后再来谈一谈解决方式。
二、正文
2.1 什么是粘包、拆包
由于TCP传输协议是面向字节流的传输协议,没有消息保护边界,所以发送方发送的多个数据包,接收方应用层不知如何区分,可能会被当成一个包来处理,这就是粘包;或者,发送方将一个打包分成多个小包发送,而接收方将它们当成多个包进行处理,这就是拆包。看下面这张图来具体理解一下:
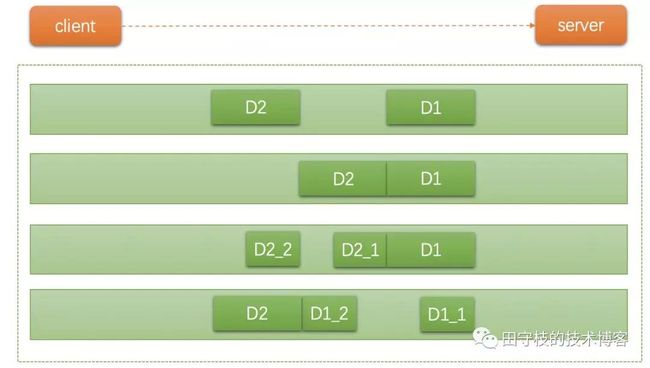
看上面这张图片,演示了TCP传输的四种情况:
- 客户端向服务器发送了两个包,两个数据包之间互不影响,这是正常的,我们不需要管;
- 客户端向服务器发送了两个包,但是两个包被并在了一起,当作一个包发送,这就是发生了粘包现象,服务器可能会将它们当成一个数据包处理;
- 客户端向服务器发送了两个包
D1和D2,但是D2的一部分与D1合并在了一起,发生了粘包,而D2另一部分被单独发送,也就是说D2被拆分成了两个小包,发生了拆包现象; - 第四种情况和第三种类似,只是顺序反了一下,
D1发生了拆包,而D1的后半部分与D2发生了粘包;
2.2 粘包发生的原因
(1)套接字缓冲区
应用层需要发送数据时,假设是基于TCP发送,则会将数据交给TCP套接字。数据被放入套接字发送缓存中,由于各种原因,往往不会立即发送,比如数据来的太快,还来不及发送。这就导致在发送缓存中,可能存在多个不同的数据包的字节并排在一起。当TCP需要发送数据时,会从发送缓存中读取一段字节,封装成TCP报文段发送出去,而读取的这些字节,可能属于多个数据包。
在接收端,TCP接收到的数据也会被放入套接字的接收缓冲区中,再由应用层进行读取。但是,应用层可能并不会立即读取缓冲区中的数据,或者来不及读取,此时就会造成多个数据包同时在缓冲区中。因为没有划定边界,所以应用层也无法将它们拆分开来,而是一同读取,这就会造成粘包。
(2)Nagle算法
TCP的发送方每次发送报文段,都希望能包含尽量多的字节,这样可以最大限度的利用网络带宽。假设发送方需要要向接收方发送一个字节的数据,经过运输层和网络层的封装后,将会为这一个字节加上40个字节的首部,这是一种非常浪费的情况,而Nagle算法正是为了减少这种情况。
Nagle算法是基本原则就是:在任意时刻,只能有一个未被确认的小段报文。未被确认就是已经发送,但是还没有接收到ACK的报文段,而小段报文指的是没有达到网络最大传输单元的报文段。使用Nagle算法时,会尽量地将一些小段凑成一个大段进行发送,而这就导致了粘包现象的发生。
2.3 拆包现象发生的原因
(1)最大报文段长度MSS、最大传输单元MTU
MSS表示一个TCP报文段能够承载数据的最大字节数,而MTU则是网络传输种能够接受的报文的最大长度。这两个概念说明网络传输中,每个报文能够承载的数据是有限的。TCP为了能将数据发送出去,且每个报文中的数据不超过MSS,会将一个大的数据包分为多个小段,为每个段加上首部后逐一发送,而这就造成了拆包。比如说,对于一张图片,一般都需要拆分成多个段进行发送。
(2)TCP滑动窗口
TCP采用了流水线的传输机制,而流水线传输中通过维护一个窗口来限制数据的发送,也可以叫做一个区间。只有序号落在窗口中的那些字节,才允许被发送。而窗口是动态变化的,它受到网络拥塞情况以及接收方缓冲区剩余空间的限制。如果当前要发送的数据包的长度,大于窗口中的剩余空间,那这个数据包就会被拆分,先发送一部分,这样也就造成了拆包。
2.4 如何解决粘包和拆包
这里需要强调一点,TCP协议可以保证数据完整,并且顺序地接收,但是并不帮助区分多个数据,因为它是面向字节流的传输协议。也就是说,要解决粘包、拆包问题的是应用层协议,应用层协议对字节进行拆分。
(1)定长协议
定长协议,顾名思义,就是应用层需要发送的每份数据,长度都是固定的。比如说,将数据长度定义为1024字节,所有不满足1024字节的数据,可以通过补0进行填充。而接收方每次读取1024字节,就可以正确区分每一份数据。
- 发送方:每次发送固定长度的数据,若数据长度不够,就使用其他字符填充;
- 接收方:每次读取固定字节的数据;
不过,稍微想想也知道,这种方式并不好,对数据进行填充,完全就是一种浪费带宽的行为,而且处理起来也麻烦。
(2)特殊字符分隔
我们可以为每一份数据,添加起始字符和结束字符,这样就可以区分了。
- 发送方:对数据的开始和结束分别加上相应的标记字符;
- 接收方:根据标记字符,逐个读取每一份数据;
当然,有时候我们并不确定应该选择哪个字符作为标记字符,因为不确定这个字符是否原本就在数据中包含。此时我们可以对数据进行转码,比如说将数据转成Base64编码,而Base64只有64种字符,然后我们就可以使用这64种之外的字符作为标记。
(3)变长协议
这种实现也是比较简单的,对于应用层的报文,可以将它分为报文头部以及报文体,而我们可以在报文头中指定当前报文中数据的长度,这样,接收方就能根据长度,正确地拆分多个粘在一起的数据了。
- 发送方:将发送的报文分为头部和实体,在头部中指明实体中数据的长度;
- 接收方:根据报文头部中的信息,正确地区分多个数据;
大部分应用层协议应该使用的都是这种方式,比如说HTTP协议,HTTP报文分为头部(header)以及实体(body),在HTTP协议的首部中,有一个Content-Length首部行,就是指明body中携带数据的字节数。
三、总结
最后在强调一遍,TCP可以保证完整,并且按序地接收字节,但是并不会帮忙拆分多个包的字节,真正做这个工作的是应用层的协议,应用层负责解决粘包和拆包。
四、参考
- https://mp.weixin.qq.com/s/H0mIhQ3dIlWKWkmlGFST9Q