一、概述
1.数据的逻辑结构与存储结构的基本概念;
2.算法的定义、基本性质以及算法分析的基本概念,包括采用大O形式表示时间复杂度和空间复杂度。
-
数据的逻辑结构
研究数据元素之间的客观联系
(1)数据元素之间具有的逻辑关系 (2)线性关系:如线性表、数组、堆栈、队列、串、文件等等 (3)非线性关系:树、二叉树、图、集合 -
数据的存储结构
研究具有某种逻辑关系的数据在计算机存储器内的存储方式
(1)具有某种逻辑结构的数据在计算机存储器中的存储方式(存储映像) (2)顺序存储结构:用一组地址连续的存储单元依次存放数据元素, 数据元素之间的逻辑关系通过元素的地址直接反映 (3)链式存储结构:用一组任意的存储单元依次存放数据元素,数据元素之间的逻辑关系通过指针 间接的反映 (4)索引存储结构:利用数据元素的索引关系来确定数据元素的存储位置,由数据元素本身与索引表两部分构成 优点:查找、插入、删除等操作的时间效率较高, 缺点:但存储空间开销较大 (5)散列存储结构:通过事先准备好的散列函数关系与处理冲突的方法来确定数据元素的存储位置 优点:查找、插入、删除等操作的时间效率较高 缺点:确定好的散列关系比较困难 -
算法
研究如何在数据的各种关系(逻辑和物理的)的基础上对数据实施一系列有效的基本操作
算法的定义: (1)算法是用来解决某个特定课题的指令的集合 (2)算法是人们组织起来准备加以实施的一系列有限的基本步骤 算法的性质: (1)输入、输出、有穷性、确定性、有效性 算法分析: (1)算法分析是指对算法质量优劣的评价,算法分析的目的是改进算法的质量,前提是被分析的算法必须正确 (2)除正确性外,从三个方面分析一个算法: 依据算法编写的程序在计算机中运行时间多少的度量,称为时间复杂度 依据算法编写的程序在计算机中占存储空间多少的度量,称为空间复杂度 几种常见的复杂度表现形式: O(log2n)
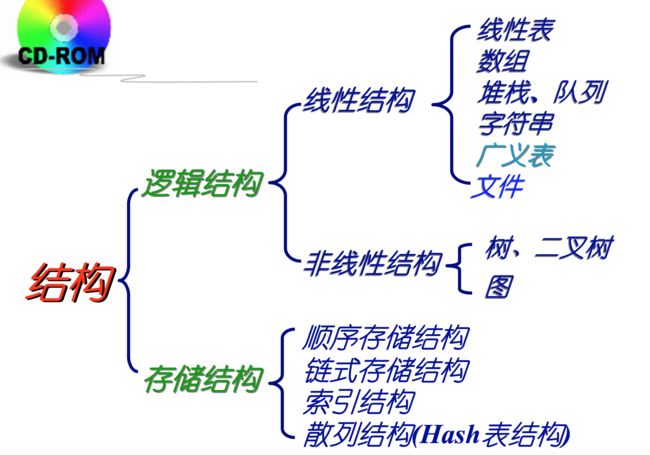
image.png
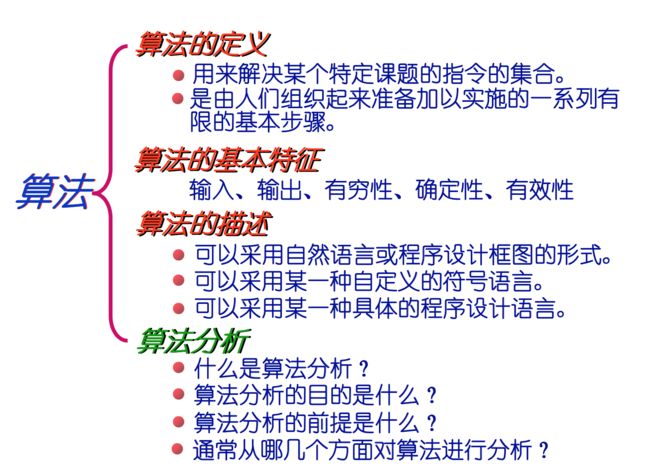
image.png
二、线性表
1.线性关系、线性表的定义,线性表的基本操作;
2.线性表的顺序存储结构与链式存储结构(包括单(向)链表、循环链表和双向链表)的构造原理;
3.在以上两种存储结构的基础上对线性表实施的基本操作,包括顺序表的插入与删除、链表的建立、插入与删除、查找等操作对应的算法设计(含递归算法的设计)。
- 线性关系
(1) 当1
有一个直接前驱元素, 有且仅有一个直接后继元素。
(3) 数据元素之间的先后顺序为“一对一”的 关系。 - 线性表的定义
(1)数据元素之间具有的逻辑关系为线性关系的数据元素集合称为 线性表 ,
n为线性表的长度,长度为0的线性表称为空表。 - 线性表的顺序存储结构构造原理
用一组地址连续的存储单元依次存储线性用一组地址连续的存储单元依次存储线性表的数据元素,
数据元素之间的逻辑关系通过数据元素的存储位置直接反映。 - 线性表的链式存储结构构造原理
用一组地址任意的存储单元(连续的或不连续的)依次存储表中各个数据元素,
数据元素之间的逻辑关系通过指针间接地反映出来。 - 循环链表
循环链表 是指链表中最后那个链结点 的指针域存放指向链表最前面那个结点的指针 ,整个链表形成一个环。 - 双向链表
所谓双向链表是指链表的每一个结点中除了数据域以外设置两个指针域,
其中之一指向结点的直接前驱结点,另外一个指向结点的直接后继结点。
1.确定元素item在长度为n的线性表中的位置
int locate (elemtype A[], int n, elemtype item){
int i;
for (i=0;i2.在长度为n的线性表A的第i个位置上插入一个新的数据元素item
int insert (elemtype A[], int &n, int i, elemtype item){
int j;
if (n === maxSize || i< 1 || i>n+1){ //n+1是7,
return -1
}
for (j=n-1;j3.删除长度为n的线性表A的第i个数据元素
//数组:1,2,3,4,5 n是5,i是3
int delete (elemtype A[],int &n,int i){
int j
if (i<1 || i>n){
return -1
}
for (j=i;j<=n;j++){
A[j-1] = A[j]
}
n--;
return 1
}
4.已经长度为n的线性表A采用顺序存储结构,并且数据元素按值大小非递减排列,
写一算法,在该线性表中插入一个数据元素item,使得线性表仍然保持按值非递减排列
// 1,2,3,3,4,5,8,8 插入6
/*1,2,3,4,5,.:递增排列
9,8,7,6,5.:递减排列
1,2,3,3,4,5,8,8,.:非递减排列
9,8,7,7,6,5,5,2,1,.:非递增排列*/
int insertsord (elemtype A[], int &n, elemtype item){
int i,j;
if (item >= A[n-1])
A[n] = item;
else {
i=0;
while (item>=A[i])
i++;
for (j=n-1;n>=i;j--){
A[j+1] = A[j];
}
}
n++;
}
5.求线性链表的长度
//非递归算法
int length(LinkList list){
LinkList p = list;
int n=0;
while(p!=null){
p=p->link;
n++;
}
return n;
}
//递归算法
int length (LinkList list){
if (list!=null){
return 1+length(list->link)
} else {
return 0
}
}
一个递归的定义可以用递归过程求解,也可以用非递归过程求解,但单从运行时间来看,通常递归过程比非递归过程______。
A.相同
B.较慢
C.较快
D.无法确定
答案 :B.较慢
[解析] 递归采用的是栈堆积的方式进行运算,每一次调用递归,内存都不断堆积,直到最后才求解,因此占用内存大,计算量成倍增加。所以递归过程较慢。
6.建立一个线性链表
LinkList create(int n){
LinkList p ,r , list=null;
datatype a;
for (i=1;i<=n;i++){
read(a);
p=(LinkList)malloc(sizeof(LNode));
p->data = a;
p->link=Null;
if (list=null){
list=p;
} else {
r->link=p;
}
r=p;
}
return list;
}
7.在非空线性链表的第一个结点前插入一个数据信息为item的新节点
void insertlink(LinkList &list,elemtype item){
p=(LinkList)malloc(sizeof(LNode));
p->data = item;
p->link=list;
list=p;
}
8.在线性表中由指针q指的链节点之后插入一个数据信息为item的链节点
void inserlink2(LinkList &list,LinkList q,elemtype item){
LinkList p ;
p=(LinkList)malloc(sizeof(LNode));
p->data = item;
if (list == null){
list = p;
p-link= Null;
} else {
p->link = q->link;
q->link = p;
}
}
9.从非空线性链表中删除q指的链结点,设q的直接前驱结点由r指出
void deletelink (LinkList &list, LinkList q, LinkList r){
if (q==list){
list = q->link;
} else {
r->link=q->link;
}
free(q);
}
10.从非空线性链表中删除a指的链结点,设q的直接前驱结点由r指出
void deletelink2 (LinkList &list,LinkList q){
LinkList r;
if (q==list){
list = list->link;
free(q);
} else {
r=list;
while(r->link!=q && r->link!=Null){
r=r->link;
}
if (r->link!=Null){
r->link=q->link;
free(q);
}
}
}
插入/删除操作只需要修改指针,不必移动元素,操作的时间效率较高,无论位于链表的何处,无论链表的长度如何,插入和删除的操作时间都是O(1);查找的时间效率为O(N)
1.求循环链表的长度
int legth(LinkList list){
LinkList p =list;
int n = 0;
do {
p=p->link;
n++;
} while(p!=list);
return n;
}
2.已知n个人(不妨分别以编号1,2,3...n代表)围坐在一张圆桌周围,编号为k的人从1开始报数,数到m的那个人出列,他的下一个人
又从1开始继续报数,数到m的那个人出列,...以此重复下去,直到圆桌周围的人全部出列,直到圆桌周围只剩下一个人。
void josephu (int n, int m, int k){
LinkList list,p,r;
int i;
//创建一个无头循环链表ua
list = null;
for (i=1;i<=n;i++){
p=(LinkList)malloc(sizeof(LNode));
p->data = i;
if (list == null){
list = p;
} else {
r->link = p;
}
r = p;
}
p->link = list;
//找到第一个点
p=list;
for (i=1;ilink;
}
//循环删除结点
while(p->link!=p){
for (i=1;i<=m-1;i++){
r=p;
p->link = p;
}
r->link = p->link;
printf("%3d\n",p->data );
free(p);
p=r->link;
}
printf("%3d\n",p->data );
}
习题:
1.链表中的每一个链结点所占用的存储单元____
A.不必连续 B.一定连续 C.部分连续 D.连续与否无所谓
2.与单向链表相比,双向链表的优点之一是_____
A.插入、删除操作更简单 B.可以进行随机访问
C.可以省略头结点指针 D.顺序访问相邻结点更灵活
3.若list是带头结点的循环链表的头结点指针,则该链表最后的那个链结点的指针域存放的是___
A.list的地址 B.list的内容 C.list指的链结点的值 D.链表第一个链结点的地址