2.抽样
抽样在我们数据分析的过程当中是经常操作的一种,那么为什么要进行抽样呢?
- 当我们的数据量很大,分析软件的处理会比较花费时间,而我们的工作并不能允许时间花费比较多,我们可以抽样
- 当我们要建模的时候,碰到数据不足或者说数据不平衡或者需要将数据分为训练集,测试集,验证集时,我们可以进行抽样
那么问题又来了,都有哪些抽样方法呢?
一般来说,有以下四种抽样方法
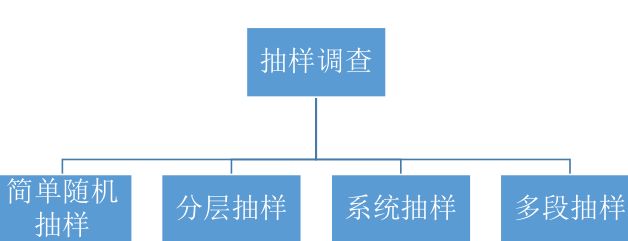
简单随机抽样(SPS)
从总体中不加任何分组、划类、排队等,完全随机的抽取调查单位。
特点:
每个样本单位被抽中的概率相等,样本的每个单位完全独立,彼此之
间无一定的关联性和排斥性。
简单随机抽样是其他各种抽样形式的基础。通常只是在总体单位之间
差异程度较小和数目较少时,才采用这种方法。
局限性:
当总体单位数很大时,就难以实现简单随机抽样,且抽样误差较大
分层抽样(STR)
也称类型抽样,总体分成不同的“层”,然后在每一层内进行抽样。
二种方法:
(1 1 )等数分配法
(2 2 )等比分配法
例:
企业按照大中小微型分类
对家庭收入分为高收入、中等收入、低收入等
分层抽样用的还是比较多的
系统抽样
也称等距抽样,其步骤如下:
(1 1 )按某一标志值的大小将总体单位进行排队并顺序编号
(2 2 )根据确定的抽样比例确定抽样间距
(3 3 )随机确定第一个样本单位
(4 4 )按顺序总总体等间距的抽取其余样本单位
系统抽样的随机性主要体现在第一个样本单位的选取上,因此一定要
保证抽取第一个样本单位的随机性
该方法适用于总体情况复杂,各单位之间差异较大,单位较多的情况。
多段抽样
将调查分成两个或两个以上的阶段进行抽样,第一阶段先将总体
按照一定的规范分成若干抽样单位,称之为一级抽样单位,再把抽中
的一级抽样单位分成若干个二级抽样单位,从抽中的二级抽样单位中
再分三级抽样单位等等,这样就形成一个多阶段抽样过程,分成若干
个阶段逐步进行。
例:从某省抽取 100 人组成样本单位
省 -- 》 市 --- 》 县 --》镇 --》--100人
抽样也分有放回和无放回
放回抽样
放回抽样又称重复抽样,每次从总体中随机的抽取一个样本单位,
观察登记其标准值后又放回总体中,如此进行N N 次的抽样方法,
特点:
在重复抽样的过程中,被抽取的总体单位总数始终保持不变,每一次
抽样中各总体单位被抽到的机会都相同,每次抽样结果相互独立;
每一总体单位都有被重复抽取的可能。
不放回抽样
不放回抽样也称不重复抽样,指被抽到的单位不再放回总体,
每次仅在余下的总体单位中抽取下一个样本的抽样方法。
特点:
任一总体单位都不会被重复抽到;
可以一次抽取所需要的样本单位数。
在实际应用中通常采用的都是不重复抽样方法
如果我们要实现这些抽样,在R中怎么实现呢?
- 简单随机抽样
#简单随机抽样:随机无重复抽取100个
set.seed(1000)
select <- sample(1:nrow(rfm_trad_flow),100)
sample <- rfm_trad_flow[select,]
sample <- dplyr::sample_n(rfm_trad_flow,100)
#简单随机抽样:随机有重复抽取100个
select <- sample(1:nrow(rfm_trad_flow),100,replace=T)
sample <- rfm_trad_flow[select,]
sample <- dplyr::sample_n(rfm_trad_flow,100,replace=T)
#简单随机抽样:随机选取10%个
set.seed(1000)
select <- sample(1:nrow(rfm_trad_flow),length(rfm_trad_flow)*0.1)
sample <- rfm_trad_flow[select,]
sample <- dplyr::sample_frac(rfm_trad_flow,0.1)
- 分层抽样
#以type为层进行分组,各抽100个样本
library(sampling)
@strata有层的意思
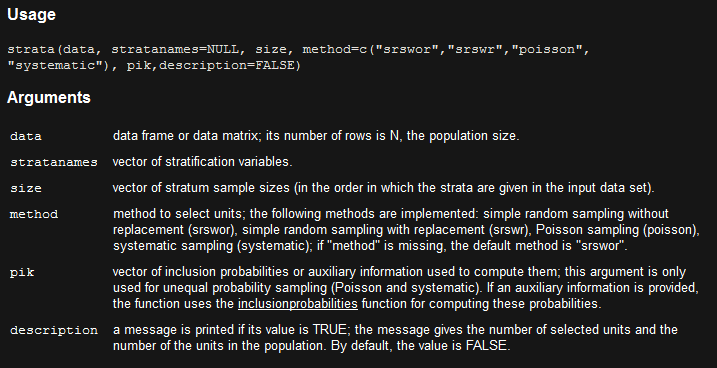
sample <- sampling::strata(rfm3,stratanames = "type",
size = rep(100,length(table(sample$type))),method = "srswor") #method可以指定抽样类型,具体看文档
samping::getdata(rfm3,sample)
> table(sample$type)
Normal Presented returned_goods Special_offer
100 100 100 100
#以type的各个level等比例抽取10%的样本出来
> library(caret)
> select <- createDataPartition(rfm_trad_flow$type,times = 1,p=0.1,list = F)
> sample <- rfm_trad_flow[select,]
> table(sample$type)
Normal Presented returned_goods Special_offer
1587 799 107 174
> nrow(sample)/nrow(rfm_trad_flow) #用createDataPartition可以将数据分成测试集和训练集
[1] 0.10003
对于类不平衡问题
http://mini.eastday.com/a/160902221514333.html
下列是一些具体的处理方法名称:
- 欠采样法(Undersampling)
该方法主要是对大类进行处理。它会减少大类的观测数来使得数据集平衡。这一办法在数据集整体很大时较为适宜,它还可以通过降低训练样本量来减少计算时间和存储开销。
欠采样法共有两类:随机(Random)的和有信息的(Informative)。
- 过采样法(Oversampling)
- 人工数据合成法(Synthetic Data Generation)
人工数据合成法是利用生成人工数据而不是重复原始观测来解决不平衡性。它也是一种过采样技术。
在这一领域,SMOTE法(Synthetic Minority Oversampling Technique)是有效而常用的方法。该算法基于特征空间(而不是数据空间)生成与小类观测相似的新数据(译者注:总体是基于欧氏距离来度量相似性,在特征空间生成一些人工样本,更通俗地说是在样本点和它近邻点的连线上随机投点作为生成的人工样本
- 代价敏感学习法(Cose Sensitive Learning)
除此之外,我们还有其他的比较前沿的方法来处理不平衡样本。比如基于聚类的采样法(Cluster based sampling),自适应人工采样法(adaptive synthetic sampling),边界线SMOTE(border line SMOTE),SMOTEboost,DataBoost-IM,核方法等。这些方法的基本思想和前文介绍的四类方法大同小异。
library(ROSE)
data(hacide)
prop.table(table(hacide.train$cls))
#不均衡类的情况
library(rpart)
treeimb <- rpart(cls~.,data=hacide.train)
pred.treeimb <- predict(treeimb,newdata = hacide.test)
##看看这个模型的预测精度,
##ROSE包提供了名为accuracy.meas()的函数,
##它能用来计算准确率,召回率和F测度等统计量。
accuracy.meas(hacide.test$cls,pred.treeimb[,2],threshold = 0.5)
roc.curve(hacide.test$cls,pred.treeimb[,2],plotit = T)
#过采样
table(hacide.train$cls)
#N代表最终平衡数据集包含的样本点,本例中我们有980个原始负类样本,所以我们要通过过采样法把正类样本也补充到980个,数据集共有1960个观测
data_balanced_over <- ovun.sample(cls~.,data = hacide.train,method = "over",
N=1960)$data
table(data_balanced_over$cls)
over_treeimb <- rpart(cls~.,data=data_balanced_over)
over_pred.treeimb <- predict(over_treeimb,newdata = hacide.test)
accuracy.meas(hacide.test$cls,over_pred.treeimb[,2])
#欠采样
##欠采样是无放回的
table(hacide.train$cls)
data_balanced_under <- ovun.sample(cls~.,data=hacide.train,
method = "under",
N=40,seed=1)$data
table(data_balanced_under$cls)
#同时对大类进行欠采样,对小类进行过抽样
##p代表新生成数据集中正类的比例
data_balanced_both <- ovun.sample(cls~.,data=hacide.train,
method = "both",N=1000,p=0.5,
seed = 1)$data
table(data_balanced_both$cls)
#人工合成
##欠采样会损失信息,过采样容易导致过拟合,
##因而ROSE包也提供了ROSE()函数来合成人工数据,它能提供关于原始数据的更好估计
data.rose <- ROSE(cls~.,data = hacide.train,seed = 1)$data
table(data.rose$cls)
# 训练决策树
tree.rose <- rpart(cls ~ ., data = data.rose)
tree.over <- rpart(cls ~ ., data = data_balanced_over)
tree.under <- rpart(cls ~ ., data = data_balanced_under)
tree.both <- rpart(cls ~ ., data = data_balanced_both)
#在测试集上做预测
pred.tree.rose <- predict(tree.rose, newdata = hacide.test)
pred.tree.over <- predict(tree.over, newdata = hacide.test)
pred.tree.under <- predict(tree.under, newdata = hacide.test)
pred.tree.both <- predict(tree.both, newdata = hacide.test)
#评估精度
roc.curve(hacide.test$cls,pred.tree.rose[,2])
roc.curve(hacide.test$cls,pred.tree.both[,2])
roc.curve(hacide.test$cls,pred.tree.over[,2])
roc.curve(hacide.test$cls,pred.tree.under[,2])
#这个包为我们提供了一些基于holdout和bagging的模型评估方法,这有助于我们判断预测结果是否有太大的方差。
##extr.pred参数是一个输出预测结果为正类的列的函数。
ROSE.holdout <- ROSE.eval(cls ~ .,
data = hacide.train,
learner = rpart,
method.assess = "holdout",
extr.pred = function(obj)obj[,2],
seed = 1)
ROSE.holdout
ROSE.boot <- ROSE.eval(cls ~ .,
data = hacide.train,
learner = rpart,
method.assess = "BOOT", #自助法
extr.pred = function(obj)obj[,2],
seed = 1)
ROSE.boot