【Graph Neural Network】GCN: 算法原理,实现和应用
半年前写过一系列关于Graph Embedding技术的介绍文章,
【Graph Embedding】DeepWalk:算法原理,实现和应用
【Graph Embedding】LINE:算法原理,实现和应用
【Graph Embedding】Node2Vec:算法原理,实现和应用
【Graph Embedding】SDNE:算法原理,实现和应用
【Graph Embedding】Struc2Vec:算法原理,实现和应用
简单来说,Graph Embedding技术一般通过特定的策略对图中的顶点进行游走采样进而学习到图中的顶点的相似性,可以看做是一种将图的拓扑结构进行向量表示的方法。
然而现实世界中,图中的顶点还包含若干的属性信息,如社交网络中的用户画像信息,引文网络中的文本信息等,对于这类信息,基于GraphEmbedding的方法通常是将属性特征拼接到顶点向量中提供给后续任务使用。
本文介绍的GCN则可以直接通过对图的拓扑结构和顶点的属性信息进行学习来得到任务结果。
GCN算法原理
首先,如果想要完整了解GCN的理论基础,我们还需要去了解空间域卷积,谱图卷积,傅里叶变换,Laplacian算子这些,本文不涉及这些内容,感兴趣的同学可以自行查阅相关资料。
我们现在先记住一个结论,GCN是谱图卷积的一阶局部近似,是一个多层的图卷积神经网络,每一个卷积层仅处理一阶邻域信息,通过叠加若干卷积层可以实现多阶邻域的信息传递。
每一个卷积层的传播规则如下:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)}=\sigma(\tilde D^{-\frac{1}{2}}\tilde A \tilde D^{-\frac{1}{2}} H^{(l)}W^{(l)} ) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中
-
A ~ = A + I N \tilde A=A+I_N A~=A+IN是无向图G的邻接矩阵加上自连接(就是每个顶点和自身加一条边), I N I_N IN是单位矩阵。
-
D ~ \tilde D D~是 A ~ \tilde A A~的度矩阵,即 D ~ i i = ∑ j A ~ i j \tilde D_{ii}=\sum_j\tilde A_{ij} D~ii=∑jA~ij
-
H ( l ) H^{(l)} H(l)是第 l l l层的激活单元矩阵, H 0 = X H^{0}=X H0=X
-
W ( l ) W^{(l)} W(l)是每一层的参数矩阵
简单解释下,GCN的每一层通过邻接矩阵 A A A和特征矩阵 H ( l ) H^{(l)} H(l)相乘得到每个顶点邻居特征的汇总,然后再乘上一个参数矩阵 W ( l ) W^{(l)} W(l)加上激活函数 σ \sigma σ做一次非线性变换得到聚合邻接顶点特征的矩阵 H ( l + 1 ) H^{(l+1)} H(l+1)。
之所以邻接矩阵 A A A要加上一个单位矩阵 I N I_N IN,是因为我们希望在进行信息传播的时候顶点自身的特征信息也得到保留。
而对邻居矩阵 A ~ \tilde A A~进行归一化操作 D ~ − 1 2 A ~ D ~ − 1 2 \tilde D^{-\frac{1}{2}}\tilde A \tilde D^{-\frac{1}{2}} D~−21A~D~−21是为了信息传递的过程中保持特征矩阵 H H H的原有分布,防止一些度数高的顶点和度数低的顶点在特征分布上产生较大的差异。
GCN的实现
GCN卷积层实现
output = tf.matmul(tf.sparse_tensor_dense_matmul(A, features), self.kernel)
if self.bias:
output += self.bias
act = self.activation(output)
上述代码片段对应的就是 H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)}=\sigma(\tilde D^{-\frac{1}{2}}\tilde A \tilde D^{-\frac{1}{2}} H^{(l)}W^{(l)} ) H(l+1)=σ(D~−21A~D~−21H(l)W(l)),只不过多了一个偏置项。
GCN的实现
def GCN(adj_dim, num_class, feature_dim, dropout_rate=0.5, l2_reg=0, feature_less=True, ):
Adjs = [Input(shape=(None,), sparse=True)]
if feature_less:
X_in = Input(shape=(1,), )
emb = Embedding(adj_dim, feature_dim, embeddings_initializer=Identity(1.0), trainable=False)
X_emb = emb(X_in)
H = Reshape([X_emb.shape[-1]])(X_emb)
else:
X_in = Input(shape=(feature_dim,), )
H = X_in
H = GraphConvolution(16, activation='relu', dropout_rate=dropout_rate, l2_reg=l2_reg)(
[H] + Adjs)
Y = GraphConvolution(num_class, activation='softmax', dropout_rate=dropout_rate, l2_reg=0)(
[H] + Adjs)
model = Model(inputs=[X_in] + Adjs, outputs=Y)
return model
这里feature_less的作用是告诉模型我们是否有额外的顶点特征输入,当feature_less为True的时候,我们直接输入一个单位矩阵作为特征矩阵,相当于对每个顶点进行了onehot表示。
GCN应用
本例中的训练,评测和可视化的完整代码在下面的git仓库中,后面还会陆续更新一些其他GNN算法
https://github.com/shenweichen/GraphNeuralNetwork
这里我们使用引文网络数据集Cora进行测试,Cora数据集包含2708个顶点, 5429条边,每个顶点包含1433个特征,共有7个类别。
按照论文的设置,从每个类别中选取20个共140个顶点作为训练,500个顶点作为验证集合,1000个顶点作为测试集。DeepWalk从全体顶点集合中进行采样,最后使用同样的140个顶点训练一个LR模型进行分类。
节点分类任务结果
| 方法 | 准确率 |
|---|---|
| DeepWalk | 0.70 |
| DeepWalk + feature | 0.78 |
| GCN(feature_less) | 0.68 |
| GCN | 0.81 |
从分类任务结果可以看到,在使用较少训练样本的条件下GCN的效果是高于DeepWalk的,而不含顶点特征的GCN的效果则会变差很多。
不含顶点特征的GCN相当于仅仅在学习图的拓扑结构,而对于图的拓扑结构的学习GraphEmbedding方法也能做到,这也说明了GCN的优势在于能够同时融入图的拓扑结构和节点的特征进行学习。
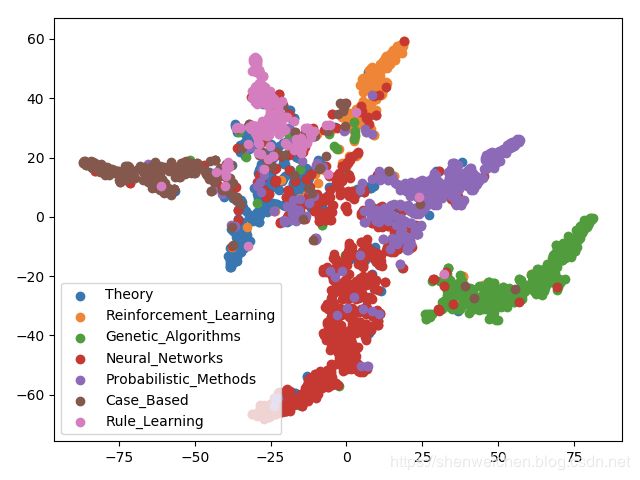
节点向量可视化
从对得到的节点向量的可视化结果来看,GCN得到的向量相比于DeepWalk产出的向量确实更加能够将同类的顶点聚集在一起,不同类的顶点区分开来。
- DeepWalk可视化

- GCN可视化
参考资料
- Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[J]. arXiv preprint arXiv:1609.02907, 2016.(https://arxiv.org/pdf/1609.02907)
想要了解更多关于GraphEmbedding算法的同学,欢迎大家关注我的公众号 浅梦的学习笔记,关注后回复“加群”一起参与讨论交流!
. . . . . . . 