R TALK | 旷视研究院范浩强&周舒畅: AI计算机摄影的原理、应用与硬件设计

「R TALK」是一个深度学习专栏,由北京智源-旷视联合实验室推出,旨在通过一场场精彩纷呈的深度学习演讲,展示旷视研究院的学术分享及阶段性技术成果,抛砖引玉,推陈出新,推动中国乃至全球领域深度学习技术的发展。这是「R Talk」第 11 期分享。
目录
引言
AI计算摄影的原理、应用
超分辨率问题
图像降噪
噪声
降噪
视频
AI计算摄影的硬件设计
精确性与计算速率
计算机架构回应深度学习
大型神经网络
小型神经网络
软硬协同
视频回顾
往期回顾
引言
本次R TALK是一次联合分享,由旷视研究院手机与移动终端算法负责人范浩强和旷视研究院集成电路算法负责人周舒畅带大家踏上一场AI计算摄影之旅,分享的主题是「AI计算摄影的原理、应用与硬件设计」,范浩强负责计算摄影的原理、应用部分,周舒畅负责计算摄影的硬件设计部分。
AI计算摄影的原理、应用
大家好,我是范浩强。感谢大家收听这次分享。首先,我们看下计算摄影在做什么。举个例子,晴朗天气下的夜空总是令人心驰神往,总能为一个加班到深夜的人带来一丝感动。
 旷视研究员拍摄的夜空
旷视研究员拍摄的夜空
面对如此美景,我们经常会忍不住掏出手机,记录住这美丽的瞬间;可是如何才能拍得更加清晰呢?为什么一些手机只把月亮拍成一张白色的饼,另一些手机却很好地还原了本来的细节呢?这就是计算机摄影学的超分辨率问题。

超分辨率问题
明白这个问题,要从手机是如何拍摄图像说起。光通过镜头打到相机的图像传感器,传感器获得了一系列原始的测量值。在这个过程中,这些测量值本身和我们最终看到的图像是不同的。
如下图(中)显示,这些测量值并不是每个像素都具有R\G\B三个通道,而是只记录其中一个的信息,所以,在拿到这些原始数据之后,设备的图像处理器会对其进行处理,最终得到我们看到的图像。下图(右)是用一款出厂设置的手机拍摄的月亮。

可知,虽然这款手机拍出了月亮的大体形状,但是却丢失了表面的大量纹理细节。那么有没有不同的算法,重建出画质更好的图像呢?这便是计算机摄影学尝试解决的一个问题。算法本身的好坏与差异最终会反映到图像的质量上,通过研究更好的算法,我们可以让拍摄的画面更加精美。
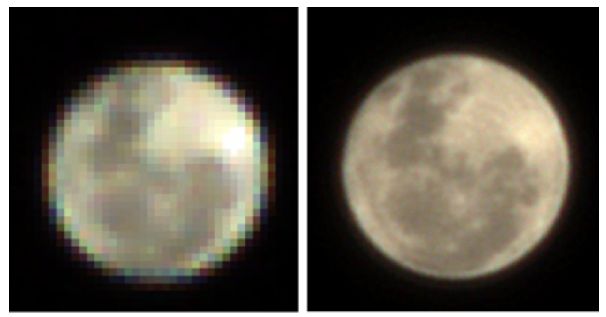
上图左边依然是前面那个月亮,只不过呈现的是相机原始测量值(RAW图)结果。可以发现,相机原始拍摄的月亮甚至比手机图像处理器处理过的画面细节更丰富。
究其原因是手机的图像处理器并没有针对这样的场景进行优化;上图右边是旷视研究员专门针对月亮开发的图像重建算法,经过对原始测量值的一系列叠加和对齐之后,恢复了这张高分辨率的图像。
因此,计算机摄影学的工作内容即是通过算法对相机本身的得到的测量值进行操作,使得重建出的图像比其它方法得到的图像拥有更好的性质,比如更好的动态范围、更佳的信噪比、更高的分辨率。
图像降噪
噪声

由于目前的主流传感器会产生较大噪声,比如热噪声、光子噪声、电压值读取产生的噪声,相应地,计算机摄影学的主要工作便是通过算法尽可能降低上述噪声对画面的影响,还原出更高质量的图像。
这里存在一个有趣的问题,上述的热噪声与光子噪声存在于任何的图像系统,包括人眼,但为什么人们从来没有在眼睛里看见这些噪声呢?这是因为大脑已有一个强大的视觉处理系统,对噪声进行自动过滤。那么如何进行降噪呢?
降噪
为了更好地解释下述的降噪方法,这里做一个视觉实验。请判断下方添加了噪声的画面的具体内容是什么?

几乎没有人能够只看这张图来获得答案。然而通过将画面区域放大,露出更多的细节,可以知道这原来是一个人的脸部区域。

获得这个脸部区域关于其周围像素的关系后,再来回看这张图,便能容易地指出其表达的内容,以及眼睛、鼻子、耳朵的具体位置。这说明,即便是人类也需要通过训练,把握了更多的上下文像素之间的关系后,才能做出有效的视觉理解判断。由此可知,视觉系统其实利用了像素之间的相关性,把图像从噪声中恢复出来。
图像降噪领域有很多经典工作,其中一个是BM3D算法,其大致步骤是,首先将图像进行块匹配,对齐成一个个图像3D叠,然后再将数据映射到变换域,最后再利用图像有关的先验信息,对图像信号本身进行变换或裁剪。例如在BM3D中一般会在变换域上对信号进行shrinkage操作,把接近零的值变为零,之后再通过反变换重建图像。

这里可以发现,降噪真正的关键是,关于图像的先验信息。通过这个先验,可以在某个空间里对图像进行操作,使其朝自然图像的先验方向靠近,以实现降噪的效果。BM3D之所以强大就在于其利用了一个很好的先验——在时空上对齐的图像叠在变换域上是稀疏的,这是自然图像的特性。
当然,除了稀疏性之外,自然图像还有着很多其它的先验信息,可是它们总是有效吗?

上图(右)效果来自手工设计的降噪算法,可以看到墙上的纹理很难恢复,因为无论从稀疏性还是连续性来表达这些纹理都存在挑战;上图(左)是基于神经网络恢复的图像,可以发现它给人的感觉会更加自然。

因此,近年来图像降噪领域也发生了范式转变,人们不再指定用什么先验,而是尝试收集带噪声和不带噪声的图像对,然后再通过卷积神经网络来进行学习,习得一个隐式的降先验, 实现对噪声图像的降噪。相对于传统的显式先验降噪,基于神经网络的方法能够在性能和灵活性上均获得显著的效果提升。
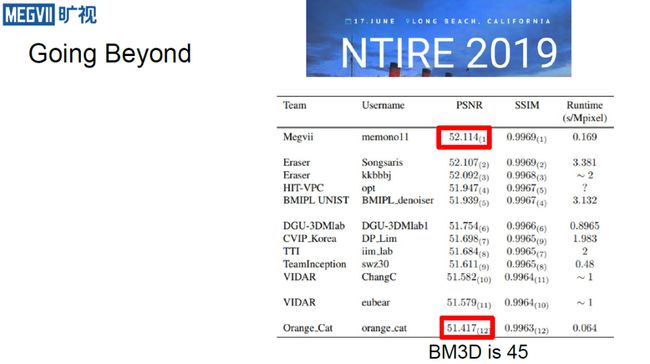
以2019 NTIRE Benchmark为例,可以发现多数上榜的算法都基于神经网络,其峰值信噪比(PSNR)最高可达52.1(由旷视技术实现),而最低也有有51.4。在这个数据集上,BM3D排在第45名。
由此可知,自然图像中的很多先验信息并不能完全依靠变换域上的稀疏性来表达。相比完全依靠人工探索、挖掘、设计先验的方法,基于神经网络的深度学习方法可以很好地把潜在的先验挖掘和利用起来。

这里介绍一个旷视基于降噪算法推出的产品——超清夜景2.0,它可使手机夜晚拍摄时噪点更低,画面更亮,画质实现巨大提升,目前已广泛应用于多款主流机型。图(左)是不使用超清夜景功能拍摄的画面,可以发现其中暗部细节严重丢失,和图(右)开启了超清夜景功能的图像形成鲜明对比。

视频
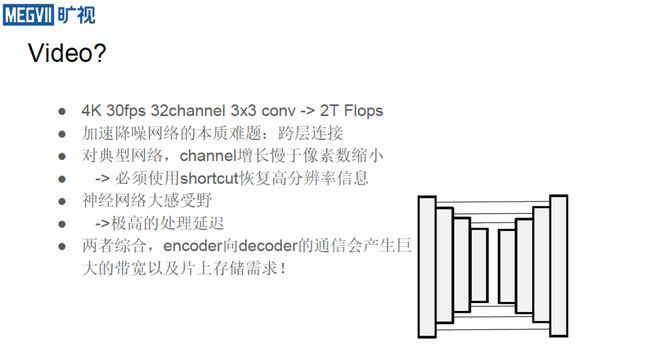
上面介绍的是拍照场景下的降噪问题,那么在视频方面如何做呢?视频处理过程中的一个重要问题是数据的吞吐量很大。这里做一个简单计算,假设需要以30fps处理一个4K视频,用3×3的conv来解出32个通道,这时会发现,仅仅一层就会消耗2TFlops的算力。
此外,相较于分类任务,由于网络需要有大量的跨层连接,图像降噪的网络更难被硬件加速。在典型的网络设计中,随着pooling操作往后延长,需要一边降低图像分辨率一边增加通道的厚度。
但是,一般来说通道厚度的增长速度会小于像素缩小的速度,即随着网络的处理越往后进行,它其实是在丢失高分辨率信息;为了恢复这些高分辨率信息,一般采用所谓的shortcut(跳跃连边)方法。
从硬件执行的视角来看,shortcut 本质上是从编码器向解码器发送信息的过程,是一种通信操作。它分辨率高,总吞吐率要求大,导致了硬件中需要一个海量的带宽才有可能把这些shortcut信息完全从编码器传到解码器。
此外,不同于普通算法,神经网络的感受野天生很大,这也会对硬件加速器的设计产生极大的挑战。当然这一切对于昂贵的计算硬件不是问题,可是端上是否存在廉价的解决方案呢?这部分将由旷视集成电路算法研究负责人周舒畅来给大家分享。
AI计算摄影的硬件设计
大家好,我是周舒畅,经过范浩强的上述分享,大家会发现一个有意思的事情,就是他开发了一个网络,而我要让这个网络跑得尽可能快,当发现实在无法很好提速之后,我会反馈给他,告诉他需要网络调整。如此反复,就会形成如下图一般互相描绘、优化的状态,这也是典型的软硬协同设计的过程。

精确性与计算速率
回到上面的问题“在端上是否存在廉价的解决方案?”,要回答它,需要首先讨论关于精确性和计算速率的基本问题。即对于神经网络而言,随着网络变大,通道增加,精度会有所上升,但达到一定程度后会饱和;当精度下降时则会突然陷入无法学习的情况(Death Zone)。
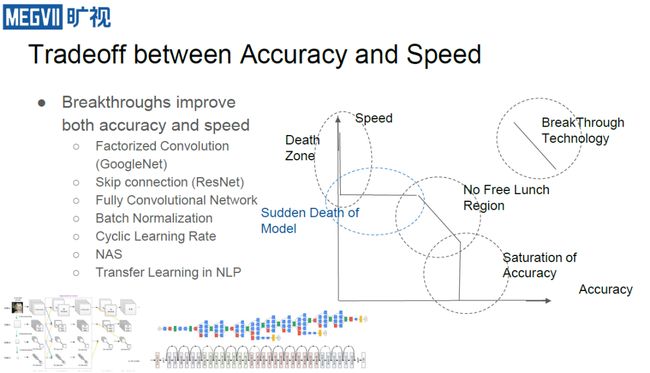
精度饱和与Death Zone之间存在一个没有免费午餐的领域,这里我们只要增加计算量,精度就可以提升一点。这也是当前硬件设计所关注的范围,即如何才能使硬件对网络带来的性能折扣依然处于没有免费午餐的阶段,并在这个阶段里尽可能提升模型的性能,实现高性能功耗比。
计算机架构回应深度学习
对于应用来说,这样的硬件性能提升有什么用处呢?以旷视南京研究院在商品细粒度识别方面的工作为例。

在这个场景中,如果希望识别更多商品同时保证精度,则需要硬件有足够的算力保障,然而在硬件性能受限的移动设备上做到这点很难,因为计算性能功耗比是很严重的问题。

为了应对这个挑战,可以首先在算法层对概念进行突破;然后在硬件层面,将算法翻译为机器能运行的内容,形成指令集ISA,进一步用图编译器和执行引擎让算法真正跑起来。当然除此之外,最后还需要控制硬件的成本。
如果要深入整个计算架构,则会发现看起来十分简单的步骤其实需要很多努力才能实现。
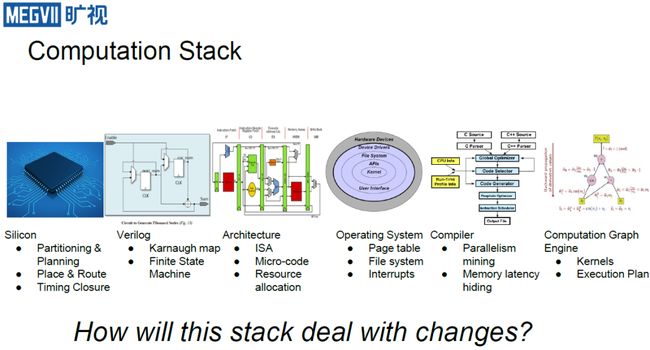
如上图,可以发现其实每个层次都有很多需要关注的不同要素,如在计算图环节,人们会关注如何设计计算的流程以使得效率更高;在编译器环节,人们会关注并行度发掘与各式各样内存延迟的隐藏;在操作系统环节,由于深度学习处理的信息量很大,因此普遍需要更大的页表等等。
大型神经网络
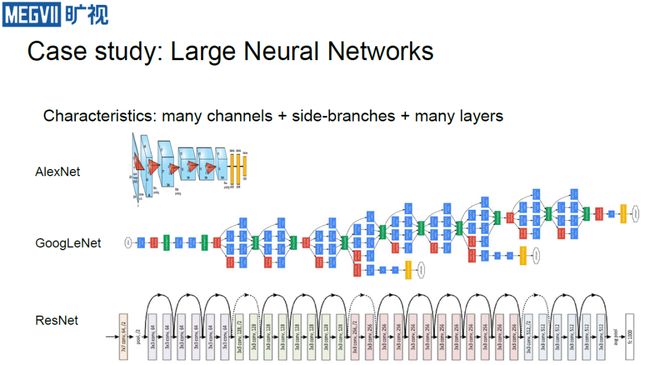
那么,如何让上述计算系统应对神经网络的挑战呢?以大型神经网络为例(如上图所示),它们往往channel很多,GoogleNet之后甚至还有很多网络带有旁支;ResNet之后网路层数也加深不少。这给硬件的多个层面带来了挑战:

图计算层,因为有多种具体算法和调度方法可选,因此会进行大量的静态分析与动态profiling来支持优化;
编译器层,传统编译器有个SIMD,即在一条指令下可以操作16个数,而在神经网络时代,由于channel很多,因此需要让SIMD操作成百上千甚至上万个数;操作系统层,即前面介绍的需要大页表问题;
体系结构层,这里可能会引入一些大数据量的指令,类似于SIMD,即一操作就是一大堆数,或者这里还可能一个被称为脉动阵列的东西;
最底层,则会用一大块片上缓存来确保数据不会总是导到内存上,延长处理时间。
小型神经网络

对于小型网络而言,由于这些网络普遍运行于算力有限的芯片上,所以人们会对其专门进行设计,通过减少channel,引入1×1卷积等操作来实现计算力要求低且精度也有保障的效果。这里选取两个代表:
一个是上面的MobileNet,由于它没有上述的shortcut,所以对硬件计算非常友好,但同时也带来了弊端,让MobileNet很难量化;
另一个是旷视研究院研发的ShuffleNet,它引入了一个channel shuffle操作,来中和其内部因为卷积分组所带来的数据隔阂问题。由于之前的硬件都没有针对shuffle操作进行优化,所以对其的专门设计可以进一步提高网络运行的速度。
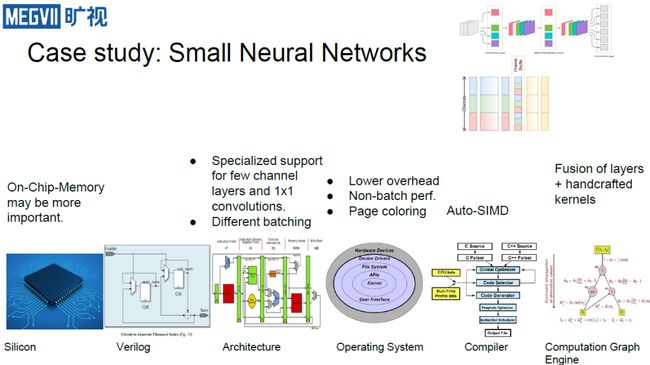
那么这些小网络对于硬件有什么影响呢?
在计算引擎层,因为channel变少,处理的数据量也会降低,计算图引擎则会强调层之间的融合以及核的手写,尽量让它们能够拼成一批来操作;
在操作系统层,大家都知道Amadahl定律,即在计算量很大时,overhead都被隐藏了,但随着现在计算量变小,则其中很多小操作的占比会上升,因此需要减少操作系统中这些操作的消耗。
在体系结构层,对于shuffleNet而言,由于它有shuffle、1×1卷积操作,因此需要专门优化。对于1×1卷积而言,由于它比较接近原来的计算方式,所以改变不大。然而对于MobileNet所引入的Depthwise 卷积就不太友好,计算量不大还需要把数据全部遍历一遍,因此只有重新专门优化;
在最底层,片上内存则变得更为重要,因为它可能从以前的几十MB降为了几百KB,因此如何高效利用它们就成了关键。
软硬协同

由上可知,由于存在很多复杂的挑战,这就需要多方人员一起协同才能有效实现硬件加速的效果。在这个过程中,不同的人会有不同的诉求。神经网络设计者希望硬件的体系结构尽可能可解释。因为为了保障其设计的模型能够在实际运行过程中足够可靠,他们不希望由于硬件体系结构的问题,导致模型性能产生很大的波动;另外他们还希望有更好的profiler,能够高效用于网络运行时分析与问题诊断,并希望硬件能够支持稀疏矩阵与动态运算。
系统架构师则希望批量操作的延迟要恒定,规则的内存访问模式能够服从局部性且有很多重用。内存和计算使用流水线化,且操作符不能过多。对于编译器与操作系统专家而言,其在整个流程中的位置让其容易成为“甩锅”对象,因为网络设计者和系统架构师都可能会认为进一步的优化问题应该交给编译器与操作系统。因此他们需要有一个能有效协调网络设计者和系统架构师的方法。如果实在行不通,则需要对每个困难操作都尽可能地准备一套方案。
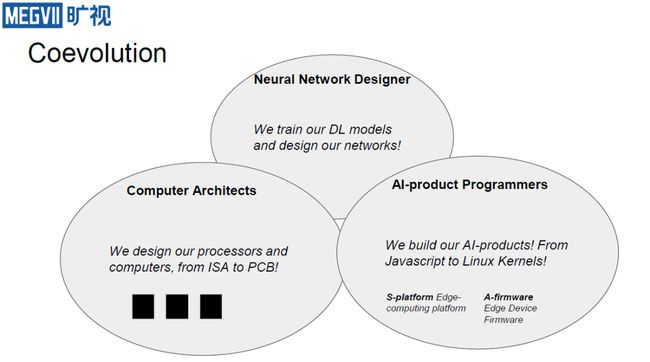
在大家的协同努力下,最终我们希望让那些过去只能在服务器上运行的功能也能够在端上得到部署。

以上是今天的分享,谢谢大家,欢迎加入旷视研究院!
---------R Talker 介绍-------
范浩强毕业于清华大学交叉信息学院(姚班),在旷视研究院带领研究组负责手机与智能终端相关的算法研发。他自8年前加入旷视以来,陆续涉猎人脸识别、活体检测、3D重建、计算摄影等多个方向,拿下多项比赛第一,学术文章发表于CVPR、ICCV、AAAI等会议。技术应用于旷视的多项产品。
周舒畅为旷视研究院IC组组长,清华电子系2000级,博士毕业于中科院计算所,主要研究方向为体系结构与视觉交叉。为AAAI/IJCAI/IPDPS/TIP/JMLR审稿人,曾获NeuIPS 2017 Learning to Run Challenge第二名,美国国家标准技术研究所NIST TRAIT 2016 OCR冠军。
入群交流
欢迎加入旷视AI摄影技术交流群

或添加微信号“farman7230”申请入群
视频回顾
PPT下载
在旷视研究院微信公众号后台回复关键词“计算摄影与硬件设计”以获取PPT。
往期回顾
R Talk | 旷视首席科学家孙剑:云、端、芯上的视觉计算
R Talk | 旷视研究院目标检测概述:Beyond RetinaNet and Mask R-CNN
R Talk | 旷视研究院姚聪博士:深度学习时代的文字检测与识别技术
R Talk | 旷视南京研究院魏秀参:细粒度图像分析综述
R Talk | 旷视研究院张祥雨:高效轻量级深度模型的研究与实践
R Talk | 旷视研究院张弛:行人重识别及其应用
R Talk | 旷视研究院危夷晨:不确定性学习在视觉识别中的应用
R Talk | 旷视成都研究院负责人刘帅成:图像对齐及其应用
R Talk | 旷视研究院SLAM组负责人刘骁:三维视觉与机器人
R TALK | 旷视研究院周而进:距离对齐技术在人脸识别中的应用
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
