CVPR 2020 | 旷视研究院提出优化领域自适应物体检测性能的类别正则化框架

IEEE 国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 大会官方论文结果公布,旷视研究院 16 篇论文被收录(其中含6篇 Oral 论文),研究领域涵盖物体检测与行人再识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D 感知,GAN 与图像生成,计算机图形学,语义分割,细粒度图像,对抗样本攻击等众多领域,取得多项领先的技术研究成果,这与已开放/开源的旷视 AI 生产力平台 Brain++ 密不可分。
本文是旷视 CVPR 2020 论文系列解读第15篇,旷视研究院基于领域自适应 Faster R-CNN 系列模型提出了一个类别正则化框架,以提升自适应检测的性能。研究人员研究了多标签分类 CNN 的弱局部定位能力,和图像级与物体级预测之间的类别一致性,发现对与物体相关的局部区域进行对齐以及对困难物体的对齐能够很好提升模型整体的效果。

论文名称:Exploring Categorical Regularization for Domain Adaptive Object Detection
论文链接:https://arxiv.org/abs/2003.09152
论文代码:https://github.com/Megvii-Nanjing/CR-DA-DET
目录
导语
简介
方法
本文框架总览
图像类别正则化
类别一致性正则化
实验
性能结果
结论
参考文献
往期解读
导语
作为计算机视觉领域相当重要的一项任务,物体检测虽然在近来取得了一系列进展,但是该领域 SOTA 模型的训练依然需要依赖大量边界框标签,这限制了模型的泛化能力,使其无法在新环境中进行有效的检测。同时,由于对图像中的物体进行边界框标注的工作成本高昂,因此一般来说,要在一个新环境中获得足够的被标注图像是不现实的。
对此,无监督的领域自适应学习(unsupervised domain adaptation)方法就成为了一个解决上述困境的途径。它能够使物体检测器从源域(标签丰富)迁移并适应目标域(不带标签)。就当前来看,利用域分类器来计算域间差异,并以对抗学习的形式来训练域分类器和特征提取器,是一种有效的办法。
在众多领域自适应检测方法中,领域自适应 Faster R-CNN(DA Faster R-CNN)最具代表性,它以对抗学习的方式整合了 Faster R-CNN。为了回应域迁移问题,它用对抗学习将跨域的图像和跨域的实例分布分别进行了对齐。
最近关于 DA Faster R-CNN 的系列进展发现,完全基于图像层面的对齐会让系统强制对齐背景中不可迁移的信息,而物体检测任务在根本上会关注目标物体周围的局部区域。不过,尽管物体层面的对齐可以实现对两个域中物体预选框的匹配,但现有的工作依然无法从得分过低的预选区中识别出那些难以对齐的物体。
简介
针对该问题,旷视研究院提出了一个全新的类别正则化框架,以支持 DA Faster R-CNN 系列模型在跨域检测中对齐困难的区域和重要物体。也正因如此,执行检测的 backbone 才能更准确地在两个域中对目标物体都完成激活(参见图1),实现更好的自适应物体检测性能。

图1 DA Faster R-CNN backbone(第二行)和与本文框架结合的DA Faster R-CNN backbone(第三行)就第一行图像给出的激活图结果
总体来说,本文框架由两个正则化模块构成,即图像级类别正则化(image-level categorical regularization,ICR),和类别一致性正则化(categorical consistency regularization,CCR),参见图 2。
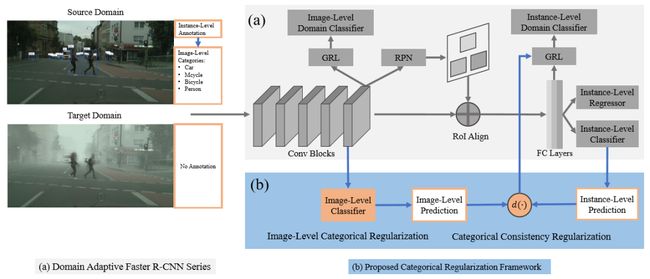
图2 本文类别正则化框架总览
对ICR而言,研究人员为 backbone 连接了一个图像的多标签分类器,并在源域用类别监督(categorical supervision)来训练它。这种分类方式让backbone能够从图像的整体层面习得物体的概念,而不会被源域中不可迁移的背景信息分布所影响。它可以让系统在图像层面隐性地对齐两个不同域间的重要区域。
对CCR而言,研究人员关注的是由分类器给出的图像预测与检测器给出的物体预测间的一致性。然后将该类别一致性作为一个正则化因子(regularization factor),在物体对齐过程中,提升难以对齐的物体在目标域中的权重。
实验结果显示,本文框架在关于跨域的重要区域对齐问题上较当前方法更为优越。让执行检测的 backbone 可以更精准地对跨域的目标物体进行激活,如图1,从而实现优秀的自适应检测效果。另外,本文框架灵活且泛化性强,不依赖具体算法来进行图像或物体的对齐。
方法
本文框架总览
图2可视化了本文提出的类别正则化框架。总体来说,本文框架通过类别正则化对 DA Faster R-CNN 系列检测器进行了两个方面的改进,即图像级的类别正则化(ICR)和类别一致性正则化(CCR)。另外,由于 ICR 模块不依赖于 CCR,因此它可以独立整合到 DA Faster R-CNN 检测器上,只进行图像级的对齐工作。
图像类别正则化
提出图像级类别正则化(ICR)模块,目的是为了获得稀疏但与类别信息相关的重要图像区域。研究人员以弱监督的方式实现了这一功能,让模型可以习得关于目标物体有区分力度的特征,而不受到源域中不可迁移背景分布的影响。
尽管标准的 Faster R-CNN 可以学习到目标物体,但是它会倾向于拟合训练数据中的背景信息,因为训练过程要求对大量感兴趣区域进行采样。由于源域背景的模式是不可迁移的,因此直接进行图像层面的对齐可能会给在目标域中的激活带来噪声,如图1。
为此,如图 2b 所示,研究人员为检测 backbone 连接了一个图像级标签分类器,并以监督的方式在源域中进行训练。具体来说,研究人员会在检测backbone最后一层卷积的输出上进行全局平均池化,然后将池化后的特征输入一个1×1卷积的多标签分类器,用标准交叉熵多标签损失来训练分类器:

图像级类别监督会促进检测 backbone 习得具体类别的特征,激活与这类物体相关的区域。因此,这使得研究人员能够用一个图像对齐模型来对齐两个域中的重要区域。同时,由于在该图像标签分类器的训练过程不涉及来自背景的监督信息,因此模型拟合源域中不可迁移背景信息的风险在很大程度上得到了控制。
类别一致性正则化
除了ICR外,研究人员还设计了一个类别一致性正则化模块(CCR),来在目标域中自动搜索难以对齐的物体。提出该模块的动机在于:首先,现有的物体对齐模型在对齐时有可能会被大量的低分值背景proposal所主导,因为它们无法在目标域中识别出难以识别的前景物体;其次,backbone连接的图像标签分类器以及物体检测head互为补充,因为前者会对图像的整体语境进行分析,而后者则专注在感兴趣的目标区域特征上。
因此,研究人员用图像与物体预测间的类别一致性来衡量对具体目标的分类难度。直观上看,如果图像分类器预测认为目标图像中没有人,而检测head却将某个具体目标分类为“人”,则可以认为该目标对于当前检测模型来说是一个虽困难,但重要的样本。因此,研究人员将该一致性作为正则化因子,在物体对齐过程中,提升那些难以对齐的样本在目标域中的权重。
实验
通过将本文框架与DA Faster R-CNN以及SOTA模型SW Faster R-CNN结合(后称为DA-Faster、SW-Faster),研究人员分析了本文提出的两个模组的性能。此外,文章还分别只用源域图像和经过标注的目标域图像对Faster R-CNN进行了训练,称为Faster R-CNN(Source)和Faster R-CNN(Oracle)。
性能结果
对天气的适应性。由于在真实场景中,物体检测任务可能会在不同的天气条件下进行,因此研究人员测试了本文方法从晴天到大雾天的适应性。实验使用 Cityscapes 的训练集和 Foggy Cityscapes 的验证集来作为源域和目标域。

表1 对天气变化的适应性
表1展示了对比结果,可以发现,本文提出的类别正则化框架能够分别对 DA-Faster 和 SW-Faster 检测器带来 1.4% 和 2.6% Map 的性能提升。值得一提的是,本文提出的 CCR 模块可以大大提升模型对一些困难类别如“火车”的检测效果。从而很好地验证了提升目标域前景中困难物体权重对物体对齐的重要性。
对不同场景的适应性。在物体检测的实际应用中,场景结构往往也会发生快速地变化,比如自动驾驶场景。因此,研究人员研究了本文框架在对场景适应问题上的性能。实验使用 Cityscapes 的训练集作为源域,BDD100K 的子集作为目标域。进一步,实验在两个数据集上,就7个常见类别的结果进行了分析。
 表2 对不同场景的适应性
表2 对不同场景的适应性
如表2所示,可以发现在领域自适应检测器和 oracle 检测器之间,存在显著的性能差异,这表明场景结构的变化对领域自适应检测器的性能影响十分显著。然而即便在这样的条件下,本文框架依然能够给 DA-Faster 和 SW-Faster 分别带来1.3%和1.6%的性能提升。同样的,类似于在天气适应性实验中的发现,本文提出的 CCR 模块能够很好的改善对诸如卡车这类困难物体的检测性能。
对非类似域的适应性。这里,研究人员将天气适应性和场景适应性两个任务都视为在类似域之间的适应问题。为了检验本文框架在非类似域上的适应性,研究人员开展了从真实图像到艺术图像的非类似域(dissimilar domain)适应实验。
为此,将 Pascal VOC 作为源域,Clipart1k 作为目标域。Clipart1k 包含了 1k 张卡通图像,其中有存在 20 类在 PASCAL VOC 中也出现的物体。Clipart1k 中所有图像都既用于训练(不带标签),也用于测试,因此对于该数据集,不存在 oracle 检测器。

表3 对非类似域的适应性
如表3结果所示,本文框架对 DA-Faster 和 SW-Faster 模型都实现了显著的性能提升,且还超过了近来新取得 SOTA 效果的一阶段物体自适应检测器(表中第二行)。

图5 使用 t-SNE 可视化的图像特征和物体特征分布情况
如图5,研究人员对 PASCAL VOC(蓝色点)和 Clipart1k(红色点)中样本在特征空间上的分布情况作了可视化分析。第一行是对检测 backbone 的输出进行全局平均池化后得到的整体图像特征;而第二行展示的是来自不同域的 3 对物体的特征分布情况,同时研究人员也对特征匹配最差的区域进行了放大。
可以发现,使用了本文方法的跨域同类物体特征会聚集得更紧密,且精确的物体对齐也使得图像对齐的性能更上一层楼。
结论
在本文中,旷视研究院基于领域自适应 Faster R-CNN 系列模型提出了一个类别正则化框架,以提升自适应检测的性能。研究人员研究了多标签分类 CNN 的弱局部定位能力,和图像级与物体级预测之间的类别一致性,发现对与物体相关的局部区域进行对齐以及对困难物体的对齐能够很好提升模型整体的效果。
一系列实验结果证明本文框架能够显著提升现有领域自适应 Faster R-CNN 检测器的性能,并在公开基准数据集上取得了 SOTA 结果。
入群交流
欢迎加入旷视南京研究院技术交流群

或添加 helloworld0079 回复“3”入群
参考文献
Yimu Wang, Ren-Jie Song, Xiu-Shen Wei, and Lijun Zhang. An Adversarial Domain Adaptation Network for Cross-Domain Fine-Grained Recognition. In WACV, pages 1228-1236, 2020.
Yuhua Chen, Wen Li, Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Domain adaptive Faster R-CNN for object detection in the wild. In CVPR, pages 3339–3348, 2018.
Zhenwei He and Lei Zhang. Multi-adversarial Faster-RCNN for unrestricted object detection. In ICCV, pages 6668–6677, 2019.
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, pages 91–99, 2015.
Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, and Kate Saenko. Strong-weak distribution alignment for adaptive object detection. In CVPR, pages 6956–6965, 2019.
Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In CVPR, pages 7167–7176, 2017.
Xinge Zhu, Jiangmiao Pang, Ceyuan Yang, and Jianping Shi. Adapting object detectors via selective cross-domain alignment. In CVPR, pages 687–696, 2019.
往期解读
CVPR 2020 | 旷视研究院提出PVN3D:基于3D关键点投票网络的单目6DoF位姿估计算法
CVPR 2020 | 旷视研究院提出SAT:优化解决半监督视频物体分割问题
CVPR 2020 | 旷视研究院提出新方法,优化解决遮挡行人重识别问题
CVPR 2020 Oral | 旷视研究院提出Circle Loss,革新深度特征学习范式
CVPR 2020 Oral | 旷视研究院提出双边分支网络BBN:攻坚长尾分布的现实世界任务
CVPR 2020 Oral | 旷视研究院提出针对语义分割的动态路径选择网络
CVPR 2020 | 旷视研究院提出数据不确定性算法 DUL,优化人脸识别性能
CVPR 2020 Oral | 旷视研究院提出密集场景检测新方法:一个候选框,多个预测结果
CVPR 2020 | 旷视研究院提出UnrealText,从3D虚拟世界合成逼真的文字图像
CVPR 2020 Oral | 旷视研究院提出对抗攻击新方法DaST:无需真实数据训练替身模型
CVPR 2020 Oral | 旷视研究院提出注意力归一化AN,优化图像生成任务性能
CVPR 2020 | 旷视研究院提出SQE:多场景MOT参数自优化度量指标
CVPR 2020 | 旷视研究院探究优化场景文字识别的「词汇依赖」问题
CVPR 2020 | 旷视研究院提出新型人-物交互检测框架,实现当前最佳
传送门
实习工作投递简历: [email protected]
欢迎大家关注如下 旷视研究院 官方微信号????
