OCR
OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
Tesseract(识别引擎)
简介
Tesseract是一款由HP实验室开发由Google维护的开源OCR引擎,当时在1995年已经成为OCR业内最准确的三款识别引擎之一,后开源并委托Google对其进行改进、优化,特点是开源,免费,支持多语言,多平台。
Tesseract目前已作为开源项目发布在Google Project,它与Leptonica图片处理库结合,可以读取各种格式的图像并将它们转化成超过60种语言的文本。同时,与Microsoft Office Document Imaging(MODI)相比,其还可以不断训练其他库,使图像转换文本的能力不断增强。
项目地址:https://github.com/tesseract-ocr/tesseract
一、下载并安装OCR字符识别库Tesseract
1)下载
地址:https://digi.bib.uni-mannheim.de/tesseract/
下载对应版本:tesseract-ocr-w64-setup-v5.0.0.20190623.exe
2)安装
勾选额外的语言(中文):展开Additional language data(download) --> 勾选Chinese


安装路径:C:\ProgramData\Tesseract-OCR(注意:安装路径不要出现中文)

3)配置环境变量
Path --> 编辑 --> 新建 --> C:\ProgramData\Tesseract-OCR
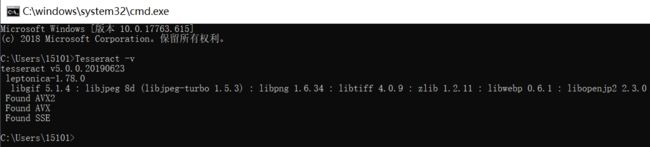
4)验证
Tesseract -v
二、安装Python包
pip install Pillow==5.2.0 pip install pytesseract==0.2.4
三、OCR识别
import pytesseract from PIL import Image image = Image.open('Text.png') code = pytesseract.image_to_string(image,lang='chi_sim') print(code)


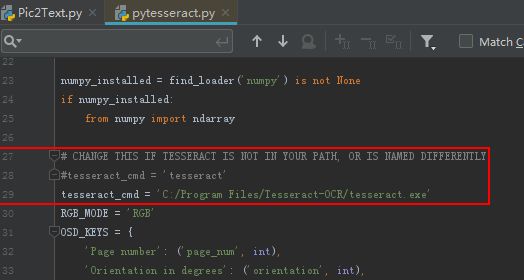
问题:未找到Tesseract-OCR安装路径

解决:在C:\Anaconda3\Lib\site-packages\pytesseract目录下,修改pytesseract.py