Instagram个性化推荐工程中三个关键技术是什么?

作者 | Ivan Medvedev,Haotian Wu,Taylor Gordon
译者 | 陆离
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】近期,Facebook 在博客上分享了第一篇详细介绍 Explore 系统关键技术,以及 Instagram 是如何为用户提供个性化内容的文章。本文就这些关键技术进行介绍,给从事或对相关工作感兴趣的开发者们分享一些想法或经验。
每个月,有超过一半的 Instagram 社区会访问 Explore 推荐系统,查找感兴趣的图片、视频和 Stories。Explore 能在高达数十亿选项中实时地推荐大家最关注的内容,这背后离不开机器学习的支撑,也必然要面对不少机器学习技术方面的挑战,更是迫切地需要新的解决方案。
我们通过创建一系列自定义的查询语言、轻量级建模技术以及支持高速实验的工具来应对遇到的问题。这些系统不仅支持 Explore 系统的数据规模,同时还能大大提高开发工程师们的效率。总的来说,这些解决方案代表了一个人工智能系统,这个系统基于一个高效的三部分排序漏斗,可提取650亿个特征,每秒可做出9000万个模型预测。

一、开发Explore系统的基础创建模块
在正式构建一个可以处理每天上传到 Instagram 上大量照片和视频的推荐引擎之前,开发团队先开发了一些基础的工具来解决三个非常重要的需求:
(1)在一定数据规模上进行快速实验的能力;
(2)在用户的兴趣广度上获得更多的信息;
(3)还需要一种高效计算的方法来确保推荐结果质量高还新颖。
要满足这些需求,关键就是下面将要为大家介绍的 Instagram 团队自定义的技术。
二、3 个自定义技术
1、用一种新的领域特定语言 IGQL 来进行快速迭代
构建效果最优的推荐算法是团队一直不断努力研究的工作之一。根据任务不同,可能选择的系统会有很大的区别,有的模型算法可以有效地识别长期兴趣,而另一种算法在新内容上的推荐效果更好,所以短发团队要不断开发迭代不同的算法,而在工程中实际需要的方法是既能尝试新想法,也能轻松将可落地的方法应用到大规模系统中,同时不用担心计算资源的影响(如CPU和内存的限制)。基于此,团队创建并发布了一种自定义的指定域元语言——IGQL,它可以提供正确的抽象级别,并将所有算法组装到某一位置中。
IGQL语言是一种针对在推荐系统中检索候选对象然后进行优化的特定领域语言。它的执行在C++中进行了优化,有助于同时对延迟和计算资源最小化。在测试新的研究思路时,发现它还具有可扩展性和易用性。IGQL是静态验证的,也是一种高级语言。工程师们可以用 Python 写推荐算法,并在 C++ 中快速而高效地执行。
user.let(seed_id=user_id).liked(max_num_to_retrieve=30).account_nn(embedding_config=default).posted_media(max_media_per_account=10).filter(non_recommendable_model_threshold=0.2).rank(ranking_model=default).diversify_by(seed_id, method=round_robin)
在上面的代码片段中,大家可以看到 IGQL 是如何给那些还没有广泛使用该语言的工程师们提供高可读性的,它有助于以一种原则性的方法来组合多个推荐过程和算法。例如,我们可以在查询中通过使用组合器规则来输出多个子查询输出的加权混合体,从而优化候选对象生成器的集成。通过调整子查询输出的权重,我们可以找到最佳用户体验的组合。
IGQL语言使执行复杂推荐系统中常见的任务变得更加简单,例如构建组合器规则的嵌套树。IGQL 让工程师们将工作重点聚焦在推荐背后的机器学习技术和业务逻辑,而不是组织工作,比如为每个查询获取候选对象的实际数量。它还高度提供了代码的重用性。例如,应用一个 ranker 就像在 IGQL 查询中添加一行规则那么简单。同时在多个地方添加 ranker 也很容易,比如排名帐户和这些帐户发布的媒体排名。
2、个性化目录排名的账户嵌入
用户在 Instagram 上公开分享达几十亿的高质量媒体内容,这些内容对 Explore 系统是非常合适的。对于Explore上众多有意思的社区来说,保持一个清晰且不断发展的目录样式分类法是具有挑战性的,这些主题五花八门,基于内容的模型很难全面了解这样基于多种兴趣类型的社区。
由于Instagram上拥有大量基于特定主题并且已关注兴趣的账户,比如Devon rex cats或者vintage tractors,我们创建了一个检索管道,它关注的是账户级别的信息,而不是媒体级别的信息。通过构建帐户嵌入,我们能够更有效地识别哪些帐户在受关注的部分彼此相似。我们使用类似于word2vec的嵌入式框架 ig2vec 来推断帐户嵌入。通常,word2vec嵌入式框架是根据一个单词在训练语料库中跨语句的上下文来学习它的表示。Ig2vec 将用户的帐户ID(例如,用户喜欢的媒体帐户)视为句子中的一个单词序列。
通过应用 word2vec 中的相同技术,我们可以预测一个人在 Instagram 上所提供的会话中可能与之交互的帐户。如果一个人在同一个会话中与一系列的Instagram帐户进行交互,那么与来自不同范围的随机帐户序列相比,它更有可能是部分一致的。这有助于我们识别出与此相关的账户。
我们定义了两个帐户之间的间隔度量,这是在嵌入训练中使用的同一个度量,通常是余弦距离或点积。基于此,我们做了一个KNN(k-NearestNeighbor,K最近邻)查找,以找到在嵌入中任何帐户的局部相似帐户。我们的嵌入版本覆盖了数百万个账户,并且使用 Facebook 最先进的最近邻检索引擎 FAISS,作为支持检索的基础架构。
对于嵌入的每一个版本,我们都训练了一个分类器,只能根据嵌入来预测一组帐户的主题。通过将预测主题与保留集里的帐户的手工标记主题进行比较,我们可以评估嵌入是如何获取主题相似度的。
检索与特定用户之前所表示过感兴趣的帐户类似的帐户,有助于我们以一种简单而有效的方式为每个人缩小到一个更小的、个性化的排名清单。因此,我们能够利用最先进的和计算密集型的机器学习模型为每个Instagram社区用户服务。
3、用模型蒸馏法预选相关候选对象
在使用了 ig2vec 根据个人兴趣确定最相关的账户之后,我们需要一种对每个用户来说都新鲜又有趣的方式来为这些账户进行排名。这需要为每个人在他们每次滑动 Explore 的页面时预测最相关的媒体。
例如,通过一个深度神经网络为每一个滑动操作评估500个媒体片段,这需要大量的资源。然而,我们为每个用户评估的帖子越多,我们就越有可能从他们的清单上找到最好的、最个性化的媒体。
为了能够最大化每个排序请求的媒体数量,我们引入了排序蒸馏模型,帮助我们在使用更复杂的排序模型之前进行候选对象的预选。我们的方法是训练一个超轻量级的模型,从中学习并尽可能地接近主要的排名模型。我们从更复杂的排名模型中记录具有特征和输出的输入候选对象。然后基于这些记录数据,用有限的特征集和一个更简单的神经网络模型结构对蒸馏模型进行训练并复制结果。其目标函数是对 NDCG(Normalized Discounted Cumulative Gain,归一化折损累计增益)排名损失超过主要排名模型的产出进行优化。我们使用蒸馏模型排名靠前的作为后期高性能排名模型的排名候选对象。
通过建立蒸馏模型的模拟行为,可以最大限度地减少调整多个参数和在不同的排名阶段维护多个模型的需要。利用这一技术,我们可以有效地评估更大的一组媒体,以便在控制计算资源的同时,在每个排名请求中可以找到最相关的媒体。
三、如何构建 Explore 的推荐系统
利用IGQL语言、账户嵌入方法和上述的蒸馏技术,将Explore系统分为两个主要阶段:候选对象生成阶段(也称为寻源阶段)和排名阶段。
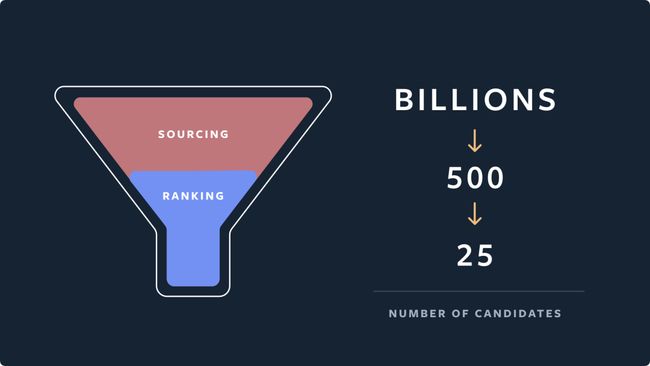 Explore推荐系统概述
Explore推荐系统概述
1、候选对象的生成
首先,我们利用人们以前在 Instagram 账户上的行为数据(例如,“喜欢”或“收藏”的某个账户中的媒体)来确定人们可能感兴趣的一些账户,我们称之为种子账户。这些种子账户通常只是 Instagram 上类似或具有相同兴趣的账户的一小部分。我们使用帐户嵌入技术来确定类似于种子帐户的帐户。最后,基于这些帐户,我们可以找到他们发布过的或是曾经参与过的媒体。
 上图显示了Instagram Explore推荐系统的典型来源
上图显示了Instagram Explore推荐系统的典型来源
人们在Instagram上使用账户和媒体的方式有很多种(例如,关注、喜欢、评论、收藏和分享)。也有不同的媒体类型(如照片、视频、Stories和直播),这就意味着我们可以使用类似的方案构建各种各样的来源。通过使用IGQL语言,这个过程会变得非常的简单,不同的候选源只是表示为不同的IGQL子查询。
通过不同类型的来源,我们能够为普通访问者找到上万个符合条件的候选对象。我们希望确保推荐的内容既安全又适用于Explore上包括全球各种年龄段的社区。通过使用各种信息,筛选出可以确定为不符合推荐条件的内容,然后再为每个人建立符合条件的清单。除了阻止可能违反政策的内容和错误信息外,还可以利用机器学习系统来帮助检测和过滤垃圾邮件等内容。
然后,对于每一个排名的请求,为一个普通用户确定数千个符合条件的媒体,从符合条件的清单中抽取出500个候选对象,然后将这些候选对象发送到下游的排名阶段。
2、候选对象排名
500名候选对象的排名架构是一个三阶段的排名基础架构,辅助在排名相关性和计算效率之间权衡取舍。这三个排名阶段如下:
第一阶段:蒸馏模型模仿其它两个阶段的组合,具有最小的特征,从500个候选对象中选出150个最高质量和最相关的候选对象;
第二阶段:一个轻量级的神经网络模型,具有全套密集的特征,选择50个最高质量和最相关的候选对象;
第三阶段:具有全套密集和稀疏特征的一个深度神经网络模型。选出25个最高质量和最相关的候选对象(Explore 的第一页);



如果第一阶段蒸馏模型按照排名顺序模仿其它的两个阶段,那么如何确定下两个阶段中最相关的内容呢?例如预测人们在每一个媒体上的个人行为,无论是像“喜欢”和“收藏”这样的积极行为,还是像“不看这样的帖子(SFPLT)”这样的消极行为。在系统中使用了多任务多标签(MTML,multi-task multi-label)神经网络来预测这些行为事件。共享的多层感知器(MLP,multilayer perceptron)允许获取来自不同用户行为的常见信号。
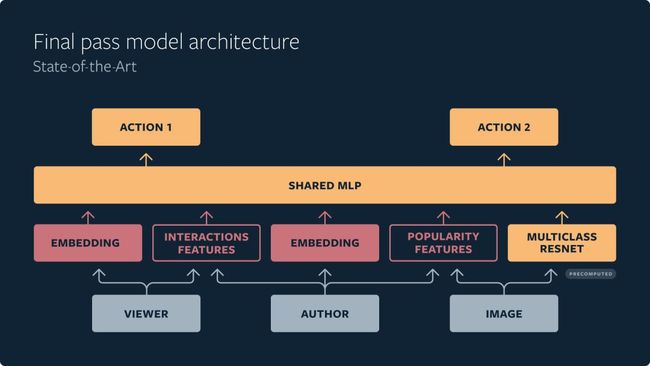 当前的最后阶段模型架构示例
当前的最后阶段模型架构示例
在系统中使用了一个称为值模型的代数公式来组合不同事件的预测结果,进而来获取不同信号在决定内容是否相关方面的突出程度。还使用了一个加权的预测值之和,比如[w_like * P(Like) + w_save * P(Save) - w_negative_action * P(Negative Action)],举例说明,如果一个用户在 Explore 系统中“收藏”了一个帖子的重要程度高于他们选择“喜欢”操作的帖子,那么“收藏”操作的权重应该更高。
Explore 推荐系统如何成为一个可以发现并找到大家兴趣和爱好?这就要提到在值模型中加入的一个简单的探索式规则,来提高内容的多样性,并通过添加惩罚条件来降低来自同一作者或同一个种子帐户的帖子排名,因此在Explore系统中看不到来自同一个人或同一个种子帐户的多个帖子。随着你停止了排名的处理,并且遇到更多来自同一个作者的帖子,这一惩罚会更加严重。
根据每个排名候选对象最终的值模型得分,对最相关的内容进行排名。离线重播工具,以及贝叶斯优化工具,也都有助于在系统设计的过程中进行高效而又频繁地值模型调整。
总结
构建 Explore 推荐系统最令人兴奋的部分就是寻找新的、有趣的方式来帮助我们发现 Instagram 上有趣的和相关的内容。通过不断地改进 Explore 系统,给购物帖子和IGTV视频等新型的内容添加类似于 Stories 和入口点这样的媒体格式。
Instagram 应用本身和存储的规模都要求我们建立一种具备快速实验和高开发率的机制,以便更加可靠地为每个用户推荐 Instagram 上最好的内容。自定义的工具和系统为建立和扩展 Instagram Explore 系统所必需的持续学习和迭代提供了坚实的基础。
原文链接:
https://ai.facebook.com/blog/powered-by-ai-instagrams-explore-recommender-system
(*本文为AI科技大本营整理文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
开幕倒计时4天,6.6 折票限时特惠(立减1400元)倒计时 1 天,学生票仅 599 元!| 2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,十余场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。

推荐阅读
IEEE分享 | 机器学习在领英的规模化应用
从YARN迁移到k8s,滴滴机器学习平台二次开发是这样做的
阿里正式开源通用算法平台Alink,“双11”将天猫推荐点击率提升4%
最新单步目标检测框架,引入双向网络,精度和速度均达到不错效果
拒绝成为比尔·盖茨的“万维网之父”,又要干大事!
测试小白必读!从0基础做到「大厂测试」,要掌握什么技能?
科技公司最爱的50款开源工具,你都用过吗?
OceanBase 的前世今生
骚操作!程序员将简历做成游戏,边看边玩还能通关!HR……
如何判断一家互联网公司要倒闭了?
把700元的单片机改造成以太坊节点, 9步get起新技能!

你点的每个“在看”,我都认真当成了AI