基于机器学习的入侵检测系统

导 语
在过去十年中,机器学习技术取得了快速进步,实现了以前从未想象过的自动化和预测能力。随着这一技术的发展促使研究人员和工程师为这些美妙的技术构思新的应用。不久,机器学习技术被用于加强网络安全系统。

网络安全性最常见的风险就是入侵,例如暴力破解、拒绝服务,甚至是网络内部的渗透。随着网络行为模式的变化,有必要切换到动态方法来检测和防止此类入侵。许多研究都致力于这一领域。
我们需要可修改、可重复、可扩展的数据集来学习和处理,以便能够轻松绕过基本入侵检测系统(IDS)的复杂攻击。这是机器学习能够发挥作用的地方,我们将在本文学习可用于构建健壮的IDS的各种机器学习技术。
什么是IDS?
“巨大的”网络攻击击败了雅虎。这是CNN的一段摘录,描述了有史以来的首次DoS(拒绝服务)攻击。
像这样的事件可能导致现代数字经济中数百万美元的损失。
确实存在入侵检测系统(IDS)以防止上述情况的组织。他们监控网络流量是否存在可疑活动,并在出现问题的时候发出警报。
IDS的类型
入侵检测系统可以使用不同类型的方法来检测可疑活动。它可以大致分为:
基于签名的入侵检测:这些系统将传入流量与已知的已知攻击模式数据库(称为签名)进行比较。检测新攻击很困难。供应系统的供应商会主动发布新名称。(类似于防病毒软件)
基于异常的入侵检测:它使用统计信息以不同的时间间隔形成网络的基线使用情况。引入它们是为了检测未知的攻击。该系统使用机器学习来创建模拟常规活动的模型,然后将新行为与现有模型进行比较。
IDS测不同地方的入侵。根据他们发现的地方,可以分为:
网络入侵检测(NIDS):它是一个战略性地(单个或多个位置)系统,用于监控所有网络流量。
主机入侵检测(HIDS):它在网络中连接到组织机构的Internet / Intranet的所有设备上运行。他们可以检测源自内部的恶意流量(例如,当恶意软件试图从组织中的主机传播到其他系统时)
IDS也可以根据它的行为进行分类:
活动:它也被称为入侵检测和防御系统。它会生成警报和日志以及更改配置以保护网络的命令。
被动:它只是检测恶意活动并生成警报或日志,但它不会采取任何行动。
在列出IDS的一般限制之后,我们将讨论使用机器学习的混合入侵系统。
传统IDS的局限性
几次真正的攻击远远少于虚假警报的数量,这导致真正的威胁经常被忽视。
噪声会通过产生高误报率严重降低IDS的能力。
基于签名的IDS需要不断的软件更新才能跟上新威胁。
IDS监控整个网络,因此容易受到网络主机的相同攻击。基于协议的攻击可能导致IDS失败。
网络IDS只能检测网络异常,这些异常限制了它可以发现的各种攻击。
所有入站和出站流量都通过它时,网络IDS可能会产生瓶颈。
主机IDS依赖于审计日志,任何攻击修改审计日志都会威胁到HIDS的完整性
IDS中的机器学习
在我们解决问题之前,有必要了解以下几点:
机器学习是一个研究领域,它使计算机能够从经验中学习和改进。机器学习侧重于开发可以使用数据发现特征的程序。
学习过程从观察或数据开始,以查找数据中的模式,并根据提供的示例做出更好的预测。主要目的是让计算机在没有人工协助的情况下学习,并相应的进行调整。
机器学习算法可大致分为:
监督机器学习算法:可以应用过去学到的东西来使用标记示例预测未来事件。算法分析称为训练数据集,用于生成推断函数以对输出值进行预测。经过充分的训练,系统可以为新的输入提供目标。该机器配备了一组新的示例,因此监督学习算法分析训练数据并从标记数据产生正确的结果。
无监督机器学习算法:当用于训练的信息既未标记也未分类时使用。无人值守学习研究系统如何推断函数来描述未标记数据的隐藏结构。这里的机器任务是根据模式,相似性和差异对未分类信息进行分组,而无需任何先前的训练数据。设备受到限制,结构不反映。
半监督机器学习算法:利用未标记的数据进行训练 - 混合使用标记较少的数据和大量未标记的数据。
半监督学习介于无监督学习和监督学习之间:当你没有足够的标签数据来产生准确的模型,或者你缺乏获得更多的半监督技术的能力/资源时,可以使用这些学习训练数据的大小。
机器学习评估IDS
无监督学习算法可以“学习”网络的典型模式,并且可以在没有任何标记数据集的情况下报告异常。它可以检测新类型的入侵,但很容易出现误报警。因此,前面只讨论了一种无监督算法K均值聚类。为了减少误报,可以引入标记数据集,并教网络中正常数据包和攻击数据包之间的差异来构建受监督的机器学习模型。受监督的模型可以灵活的处理已知的攻击,并且还可以识别这些攻击的变化。将讨论标准监督算法(贝叶斯网络、随机森林、随机树、MLP、决策表)。
数据集
开始使用机器学习模型的最重要和繁琐的过程是获得可靠的数据。我们使用KDD Cup 1999数据来构建能够区分入侵或攻击以及有价值的连接的预测模型。该数据库包含一组标准数据,其中包括在军事网络环境中模拟的各种干预措施。它由4,898,431个实例和41个属性组成。
每个连接都标记为正常或攻击,只有一种特定的攻击类型。每个连接记录包含大约100个字节。
攻击分为四大类:
DOS:拒绝服务
R2L:远程计算机的未授权访问
U2R:未经授权访问本地root权限
探测:监视和另一次探测
每个组都有各种攻击,共有21种类型的攻击。
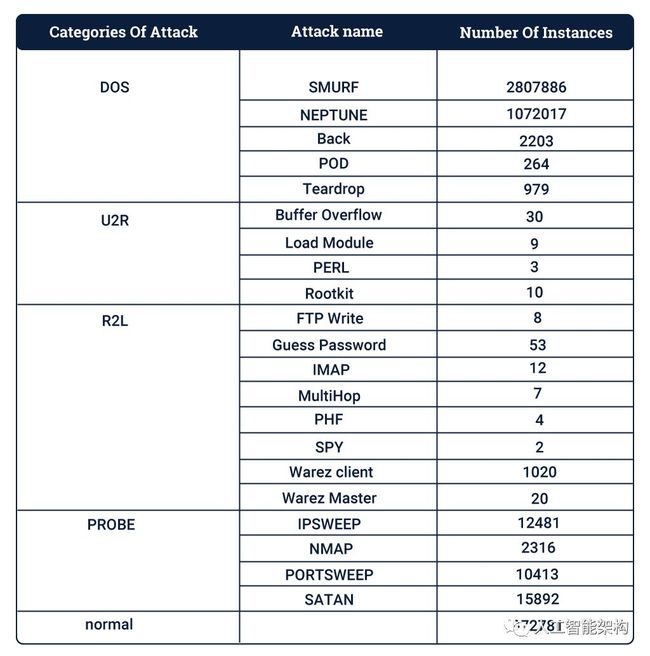
KDD集摘要
使用基于TCP/IP实现的任何连接收集的分类为必要信息的属性也如下所示:
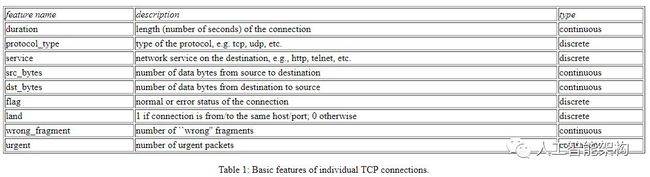
必须先处理数据,然后才能在机器学习算法中使用。这意味着必须选择功能,有些元素很容易找到;其他人必须通过试验和运行测试找到。使用数据集的所有功能并不一定能保证IDS的最佳性能。它可能会增加计算成本以及系统的错误率。这是因为某些功能是冗余的,或者对于区分不同的类没有用。
该数据集的主要贡献是引入专家建议属性,有助于理解不同类型攻击的行为,包括检测DOS、PROBE、R2L和U2R的基本特征。以下是域知识建议的一些内容功能列表。
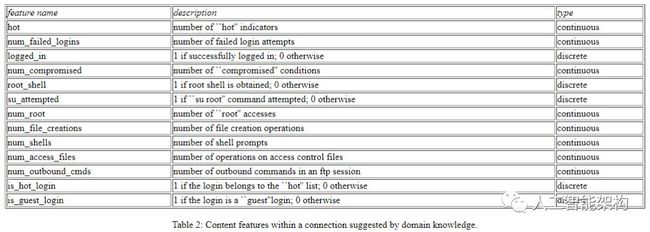
专家特色
其他几个数据集也在这里提及:
ISCX 2012数据集由加拿大网络安全研究所收集(标记为)
CTU-13数据集于2011年在捷克共和国CTU大学捕获(未标记)
机器学习算法概述
K-Means聚类
如上所述,K-Means聚类是一种无监督学习技术。它是最简单和最流行的机器学习算法之一。它在数据中查找组,其中组的数量有变量K表示。算法根据数据集的特征将数据点分配给K组之一。数据点基于特征的相似性进行聚类。
贝叶斯网络
贝叶斯网络是一种概率图形模型。它旨在通过在有向图的边缘上绘制依赖关系来利用条件依赖性。它假设所有未通过边连接的节点都是有条件独立的,并在创建有向非循环图时利用这一事实。
随机森林分类器
随机森林是一个集合分类器,这意味着它结合了许多算法用于分类目的。它们在随机数据子集上创建多个决策树。然后汇总每棵树的总票数以决定测试的类别,或者它为各个树的贡献分配权重。
多层感知器(MLP)
MLP是前馈神经网络。它至少包含三层:输入层、隐藏层和输出层。在训练期间,调整权重或参数以最小化分类中的误差。在每个隐藏节点中引入非线性。反向传播用于相对于误差进行那些权重和偏差调整。
执行
将使用Python及其广泛的库来使用IDS。在我们开始申请之前,需要安装Pandas、numpy、scipy。如果你使用的是Ubuntu shell,请使用
1sudo pip install numpy scipy pandas
首先需要对数据集进行预处理。需要下载数据集,并将其解压缩到你将编写程序的文件夹中。
数据集应采用.csv格式,python可以轻松读取。
1# Import pandas2import pandas as pd3# reading csv file4dataset = pd.read_csv("filename.csv")
2import pandas as pd
3# reading csv file
4dataset = pd.read_csv("filename.csv")
前面提到的机器学习算法都存在于奇妙的scipy库中。你可以按照以下步骤通过不同的模型快速运行数据集:
K-MEANS
1import numpy as np2from sklearn.cluster import KMeans3print(dataset.describe()) # to view the summary of the dataset loaded4kmeans = KMeans(n_clusters=2) # You want cluster the threats into 5: Normal, DOS,PROBE, R2L and U2R5kmeans.fit(X)6prediction = kmeans.predict(dataset[0]) # predicts the type for the first entryimport numpy as np
2from sklearn.cluster import KMeans
3print(dataset.describe()) # to view the summary of the dataset loaded
4kmeans = KMeans(n_clusters=2) # You want cluster the threats into 5: Normal, DOS,PROBE, R2L and U2R
5kmeans.fit(X)
6prediction = kmeans.predict(dataset[0]) # predicts the type for the first entry
随机森林
1#Import Random Forest Model2from sklearn.ensemble import RandomForestClassifier3#Create a Gaussian Classifier4clf=RandomForestClassifier(n_estimators=50)5#Train the model using the training dataset6clf.fit(dataset,dataset[:,LAST_COLUMN]) #LAST_COLUMN is the index of the column with the labelled type of threat or normal7pred=clf.predict(dataset)#Import Random Forest Model
2from sklearn.ensemble import RandomForestClassifier
3#Create a Gaussian Classifier
4clf=RandomForestClassifier(n_estimators=50)
5#Train the model using the training dataset
6clf.fit(dataset,dataset[:,LAST_COLUMN]) #LAST_COLUMN is the index of the column with the labelled type of threat or normal
7pred=clf.predict(dataset)
NAIVE BAYES NETWORK
1from sklearn.naive_bayes import GaussianNB2#Create a Gaussian Naive Bayes Classifier3gnb = GaussianNB()4gnb.fit(dataset,dataset[:,LAST_COLMN])5pred=predict(gnb,dataset[0])from sklearn.naive_bayes import GaussianNB
2#Create a Gaussian Naive Bayes Classifier
3gnb = GaussianNB()
4gnb.fit(dataset,dataset[:,LAST_COLMN])
5pred=predict(gnb,dataset[0])
MULTI_LAYER PERCEPTRON
1From sklearn.neural_network import MLPClassifier2#Create a Multi-Layer Perceptron3clf = MLPClassifier(solver='lbfgs', alpha=1e-5,4hidden_layer_sizes=(5, 2), random_state=1)5clf.fit(dataset,dataset[:,LAST_COLMN])6pred=clf.predict(dataset[0]);import MLPClassifier
2#Create a Multi-Layer Perceptron
3clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
4hidden_layer_sizes=(5, 2), random_state=1)
5clf.fit(dataset,dataset[:,LAST_COLMN])
6pred=clf.predict(dataset[0]);
结 果
为了衡量机器学习模型的准确性,我们使用各种参数。此处使用的指标包括平均准确度、误报率和误差率。K-Means被排除在该度量之外,因为它是无监督算法。
平均准确度定义为正确分类的数据点与数据点总数的比率。
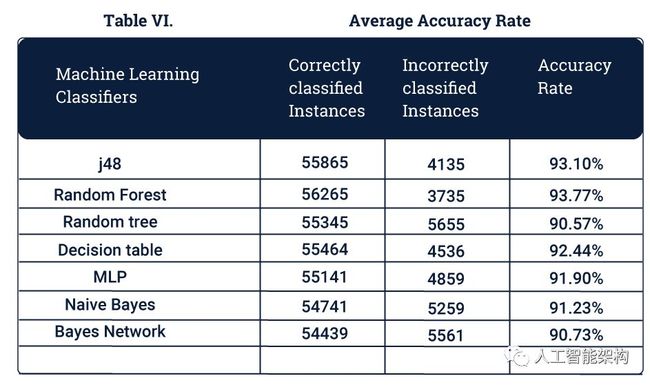
误报是那些应该作为威胁返回的情况,但实际并不是。

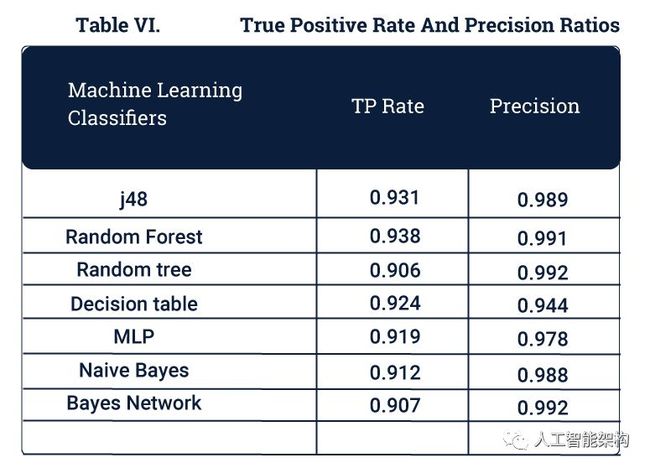
下面给出了一些其他指标比较:
精确和真实的积极
精确度是感知威胁与总威胁的比率。
真正的积极因素是威胁并正确识别为威胁的数据包。
如何使你的业务受益
所有当前的IDS都在转向机器学习技术,以应对不断增加的网络安全威胁。这不仅使入侵检测过程自动化,而且还具有惊人的准确性。企业可以使用这些结果来定位攻击源,阻止进一步的尝试并优化其网络。另一个重要的优势是公司不必为特定的专有签名付费以保护自己免受新攻击。
结 语
IDS正在使用本文中讨论的许多机器学习技术:
●K-means
●贝叶斯网络
●随机森林分类器
●多层感知器
不同的技术在各种指标中表现更好。IDS应根据要求提供最有效的解决方案。有一件事是肯定的,任何公司现在或在不久的将来都不会采用这些技术,这会危及数据或服务器。建议保证安全,采用机器学习。

长按二维码 ▲
订阅「架构师小秘圈」公众号
如有启发,帮我点个在看,谢谢↓