LSTM与BI-LSTM
文章目录
- 从RNN到LSTM
- LSTM模型结构剖析
- LSTM之遗忘门
- LSTM之输入门
- LSTM之细胞状态更新
- LSTM之输出门
- LSTM前向传播算法
- LSTM反向传播算法推导关键点
- BiLSTM
从RNN到LSTM
在RNN模型里,我们讲到了RNN具有如下的结构,每个序列索引位置t都有一个隐藏状态h(t)。
如果我们略去每层都有的 o ( t ) , L ( t ) , y ( t ) o^{(t)}, L^{(t)}, y^{(t)} o(t),L(t),y(t),则RNN的模型可以简化成如下图的形式:
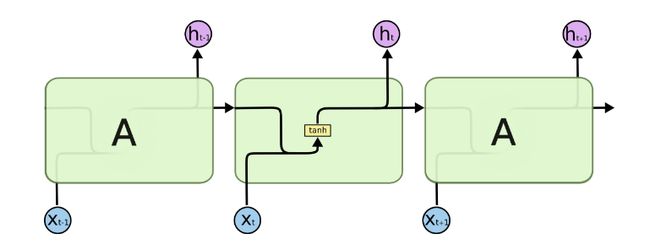
图中可以很清晰看出在隐藏状态 h ( t ) h^{(t)} h(t)由 x ( t ) x^{(t)} x(t)和 h ( t − 1 ) h^{(t-1)} h(t−1)得到。得到h(t)后一方面用于当前层的模型损失计算,另一方面用于计算下一层的 h ( t + 1 ) h^{(t+1)} h(t+1)。
由于RNN梯度消失的问题,大牛们对于序列索引位置t的隐藏结构做了改进,可以说通过一些技巧让隐藏结构复杂了起来,来避免梯度消失的问题,这样的特殊RNN就是我们的LSTM。由于LSTM有很多的变种,这里我们以最常见的LSTM为例讲述。LSTM的结构如下图:
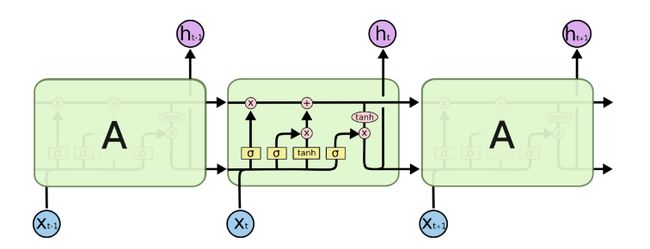
LSTM模型结构剖析
上面我们给出了LSTM的模型结构,下面我们就一点点的剖析LSTM模型在每个序列索引位置t时刻的内部结构。
从上图中可以看出,在每个序列索引位置t时刻向前传播的除了和RNN一样的隐藏状态h(t),还多了另一个隐藏状态,如图中上面的长横线。这个隐藏状态我们一般称为细胞状态(Cell State),记为 C ( t ) C^{(t)} C(t)。如下图所示:

除了细胞状态,LSTM图中还有了很多奇怪的结构,这些结构一般称之为门控结构(Gate)。LSTM在在每个序列索引位置t的门一般包括遗忘门,输入门和输出门三种。下面我们就来研究上图中LSTM的遗忘门,输入门和输出门以及细胞状态。
LSTM之遗忘门
遗忘门(forget gate)顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:
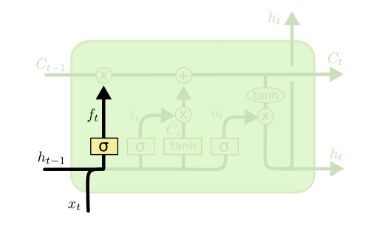
图中输入的有上一序列的隐藏状态 h ( t − 1 ) h^{(t-1)} h(t−1)和本序列数据 x ( t ) x^{(t)} x(t),通过一个激活函数,一般是sigmoid,得到遗忘门的输出 f ( t ) f^{(t)} f(t)。由于sigmoid的输出f(t)在[0,1]之间,因此这里的输出 f ( t ) f^{(t)} f(t)代表了遗忘上一层隐藏细胞状态的概率。用数学表达式即为:
f ( t ) = σ ( W f h ( t − 1 ) + U f x ( t ) + b f ) f^{(t)} = \sigma(W_fh^{(t-1)} + U_fx^{(t)} + b_f) f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
其中Wf,Uf,bf为线性关系的系数和偏倚,和RNN中的类似。σ为sigmoid激活函数。
LSTM之输入门
输入门(input gate)负责处理当前序列位置的输入,它的子结构如下图:

从图中可以看到输入门由两部分组成,第一部分使用了sigmoid激活函数,输出为i(t),第二部分使用了tanh激活函数,输出为a(t), 两者的结果后面会相乘再去更新细胞状态。用数学表达式即为:
i ( t ) = σ ( W i h ( t − 1 ) + U i x ( t ) + b i ) i^{(t)} = \sigma(W_ih^{(t-1)} + U_ix^{(t)} + b_i) i(t)=σ(Wih(t−1)+Uix(t)+bi)
a ( t ) = t a n h ( W a h ( t − 1 ) + U a x ( t ) + b a ) a^{(t)} =tanh(W_ah^{(t-1)} + U_ax^{(t)} + b_a) a(t)=tanh(Wah(t−1)+Uax(t)+ba)
其中 W i , U i , b i , W a , U a , b a , W_i, U_i, b_i, W_a, U_a, b_a, Wi,Ui,bi,Wa,Ua,ba,为线性关系的系数和偏倚,和RNN中的类似。σ为sigmoid激活函数。
LSTM之细胞状态更新
在研究LSTM输出门之前,我们要先看看LSTM之细胞状态。前面的遗忘门和输入门的结果都会作用于细胞状态C(t)。我们来看看从细胞状态C(t−1)如何得到C(t)。如下图所示:
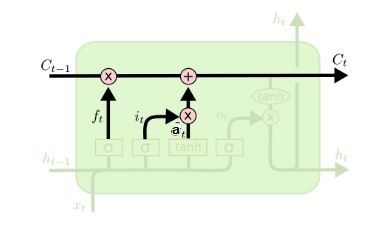
细胞状态 C ( t ) C^{(t)} C(t)由两部分组成,第一部分是 C ( t − 1 ) C^{(t-1)} C(t−1)和遗忘门输出 f ( t ) f^{(t)} f(t)的乘积,第二部分是输入门的 i ( t ) i^{(t)} i(t)和 a ( t ) a^{(t)} a(t)的乘积,即:
C ( t ) = C ( t − 1 ) ⊙ f ( t ) + i ( t ) ⊙ a ( t ) C^{(t)} = C^{(t-1)} \odot f^{(t)} + i^{(t)} \odot a^{(t)} C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
其中,⊙为Hadamard积,在DNN中也用到过
LSTM之输出门
有了新的隐藏细胞状态C(t),我们就可以来看输出门了,子结构如下:
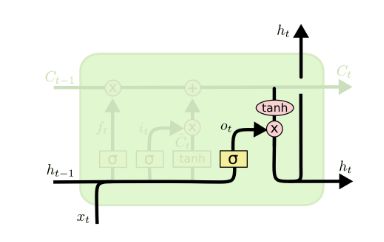
从图中可以看出,隐藏状态 h ( t ) h^{(t)} h(t)的更新由两部分组成,第一部分是o(t), 它由上一序列的隐藏状态 h ( t − 1 ) h^{(t-1)} h(t−1)和本序列数据 x ( t ) x^{(t)} x(t),以及激活函数sigmoid得到,第二部分由隐藏状态C(t)和tanh激活函数组成, 即:
o ( t ) = σ ( W o h ( t − 1 ) + U o x ( t ) + b o ) o^{(t)} = \sigma(W_oh^{(t-1)} + U_ox^{(t)} + b_o) o(t)=σ(Woh(t−1)+Uox(t)+bo)
h ( t ) = o ( t ) ⊙ t a n h ( C ( t ) ) h^{(t)} = o^{(t)} \odot tanh(C^{(t)}) h(t)=o(t)⊙tanh(C(t))
LSTM前向传播算法
现在我们来总结下LSTM前向传播算法。LSTM模型有两个隐藏状态 h ( t ) , C ( t ) h^{(t)}, C^{(t)} h(t),C(t),模型参数几乎是RNN的4倍,因为现在多了 W f , U f , b f , W a , U a , b a , W i , U i , b i , W o , U o , b o W_f, U_f, b_f, W_a, U_a, b_a, W_i, U_i, b_i, W_o, U_o, b_o Wf,Uf,bf,Wa,Ua,ba,Wi,Ui,bi,Wo,Uo,bo这些参数。
前向传播过程在每个序列索引位置的过程为:
1)更新遗忘门输出:
f ( t ) = σ ( W f h ( t − 1 ) + U f x ( t ) + b f ) f^{(t)} = \sigma(W_fh^{(t-1)} + U_fx^{(t)} + b_f) f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
2)更新输入门两部分输出:
i ( t ) = σ ( W i h ( t − 1 ) + U i x ( t ) + b i ) i^{(t)} = \sigma(W_ih^{(t-1)} + U_ix^{(t)} + b_i) i(t)=σ(Wih(t−1)+Uix(t)+bi)
a ( t ) = t a n h ( W a h ( t − 1 ) + U a x ( t ) + b a ) a^{(t)} = tanh(W_ah^{(t-1)} + U_ax^{(t)} + b_a) a(t)=tanh(Wah(t−1)+Uax(t)+ba)
3)更新细胞状态:
C ( t ) = C ( t − 1 ) ⊙ f ( t ) + i ( t ) ⊙ a ( t ) C^{(t)} = C^{(t-1)} \odot f^{(t)} + i^{(t)} \odot a^{(t)} C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
4)更新输出门输出:
o ( t ) = σ ( W o h ( t − 1 ) + U o x ( t ) + b o ) o^{(t)} = \sigma(W_oh^{(t-1)} + U_ox^{(t)} + b_o) o(t)=σ(Woh(t−1)+Uox(t)+bo)
h ( t ) = o ( t ) ⊙ t a n h ( C ( t ) ) h^{(t)} = o^{(t)} \odot tanh(C^{(t)}) h(t)=o(t)⊙tanh(C(t))
5)更新当前序列索引预测输出:
y ^ ( t ) = σ ( V h ( t ) + c ) \hat{y}^{(t)} = \sigma(Vh^{(t)} + c) y^(t)=σ(Vh(t)+c)
LSTM反向传播算法推导关键点
有了LSTM前向传播算法,推导反向传播算法就很容易了, 思路和RNN的反向传播算法思路一致,也是通过梯度下降法迭代更新我们所有的参数,关键点在于计算所有参数基于损失函数的偏导数。
在RNN中,为了反向传播误差,我们通过隐藏状态 h ( t ) h^{(t)} h(t)的梯度 δ ( t ) \delta^{(t)} δ(t)一步步向前传播。在LSTM这里也类似。只不过我们这里有两个隐藏状态 h ( t ) h^{(t)} h(t)和C(t)。这里我们定义两个δ,即:
δ h ( t ) = ∂ L ∂ h ( t ) \delta_h^{(t)} = \frac{\partial L}{\partial h^{(t)}} δh(t)=∂h(t)∂L
δ C ( t ) = ∂ L ∂ C ( t ) \delta_C^{(t)} = \frac{\partial L}{\partial C^{(t)}} δC(t)=∂C(t)∂L
为了便于推导,我们将损失函数L(t)分成两块,一块是时刻t位置的损失l(t),另一块是时刻t之后损失L(t+1),即:
L ( t ) = { l ( t ) + L ( t + 1 ) if t < τ l ( t ) if t = τ L(t) = \begin{cases} l(t) + L(t+1) & \text{if} \, t < \tau \\ l(t) & \text{if} \, t = \tau\end{cases} L(t)={l(t)+L(t+1)l(t)ift<τift=τ
而在最后的序列索引位置τ的 δ h ( τ ) \delta_h^{(\tau)} δh(τ)和 δ C ( τ ) \delta_C^{(\tau)} δC(τ)为:
δ h ( τ ) = ( ∂ O ( τ ) ∂ h ( τ ) ) T ∂ L ( τ ) ∂ O ( τ ) = V T ( y ^ ( τ ) − y ( τ ) ) \delta_h^{(\tau)} =(\frac{\partial O^{(\tau)}}{\partial h^{(\tau)}})^T\frac{\partial L^{(\tau)}}{\partial O^{(\tau)}} = V^T(\hat{y}^{(\tau)} - y^{(\tau)}) δh(τ)=(∂h(τ)∂O(τ))T∂O(τ)∂L(τ)=VT(y^(τ)−y(τ))
接着我们由 δ C ( t + 1 ) , δ h ( t + 1 ) \delta_C^{(t+1)},\delta_h^{(t+1)} δC(t+1),δh(t+1)反向推导 δ h ( t ) , δ C ( t ) \delta_h^{(t)}, \delta_C^{(t)} δh(t),δC(t)
δ h ( t ) \delta_h^{(t)} δh(t)的梯度由本层t时刻的输出梯度误差和大于t时刻的误差两部分决定,即:
δ h ( t ) = ∂ L ∂ h ( t ) = ∂ l ( t ) ∂ h ( t ) + ( ∂ h ( t + 1 ) ∂ h ( t ) ) T ∂ L ( t + 1 ) ∂ h ( t + 1 ) = V T ( y ^ ( t ) − y ( t ) ) + ( ∂ h ( t + 1 ) ∂ h ( t ) ) T δ h ( t + 1 ) \delta_h^{(t)} =\frac{\partial L}{\partial h^{(t)}} =\frac{\partial l(t)}{\partial h^{(t)}} + ( \frac{\partial h^{(t+1)}}{\partial h^{(t)}})^T\frac{\partial L(t+1)}{\partial h^{(t+1)}} = V^T(\hat{y}^{(t)} - y^{(t)}) + (\frac{\partial h^{(t+1)}}{\partial h^{(t)}})^T\delta_h^{(t+1)} δh(t)=∂h(t)∂L=∂h(t)∂l(t)+(∂h(t)∂h(t+1))T∂h(t+1)∂L(t+1)=VT(y^(t)−y(t))+(∂h(t)∂h(t+1))Tδh(t+1)
整个LSTM反向传播的难点就在于 ∂ h ( t + 1 ) ∂ h ( t ) \frac{\partial h^{(t+1)}}{\partial h^{(t)}} ∂h(t)∂h(t+1)这部分的计算。仔细观察,由于 h ( t ) = o ( t ) ⊙ t a n h ( C ( t ) ) h^{(t)} = o^{(t)} \odot tanh(C^{(t)}) h(t)=o(t)⊙tanh(C(t)) 在第一项o(t)中,包含一个h的递推关系,第二项tanh(C(t))就复杂了,tanh函数里面又可以表示成:
C ( t ) = C ( t − 1 ) ⊙ f ( t ) + i ( t ) ⊙ a ( t ) C^{(t)} = C^{(t-1)} \odot f^{(t)} + i^{(t)} \odot a^{(t)} C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
tanh函数的第一项中,f(t)包含一个h的递推关系,在tanh函数的第二项中,i(t)和a(t)都包含h的递推关系,因此,最终 ∂ h ( t + 1 ) ∂ h ( t ) \frac{\partial h^{(t+1)}}{\partial h^{(t)}} ∂h(t)∂h(t+1)这部分的计算结果由四部分组成。即:
Δ C = o ( t + 1 ) ⊙ [ 1 − t a n h 2 ( C ( t + 1 ) ) ] \Delta C = o^{(t+1)} \odot [1-tanh^2(C^{(t+1)})] ΔC=o(t+1)⊙[1−tanh2(C(t+1))]
∂ h ( t + 1 ) ∂ h ( t ) = W o T [ o ( t + 1 ) ⊙ ( 1 − o ( t + 1 ) ) ⊙ t a n h ( C ( t + 1 ) ) ] + W f T [ Δ C ⊙ f ( t + 1 ) ⊙ ( 1 − f ( t + 1 ) ) ⊙ C ( t ) ] + W a T { Δ C ⊙ i ( t + 1 ) ⊙ [ 1 − ( a ( t + 1 ) ) 2 ] } + W i T [ Δ C ⊙ a ( t + 1 ) ⊙ i ( t + 1 ) ⊙ ( 1 − i ( t + 1 ) ) ] \frac{\partial h^{(t+1)}}{\partial h^{(t)}} = W_o^T [o^{(t+1)} \odot (1-o^{(t+1)}) \odot tanh(C^{(t+1)})] + W_f^T [\Delta C \odot f^{(t+1)} \odot (1-f^{(t+1)}) \odot C^{(t)}] + W_a^T \{ \Delta C \odot i^{(t+1)} \odot [1-(a^{(t+1)})^2] \} + W_i^T [\Delta C \odot a^{(t+1)} \odot i^{(t+1)} \odot (1-i^{(t+1)})] ∂h(t)∂h(t+1)=WoT[o(t+1)⊙(1−o(t+1))⊙tanh(C(t+1))]+WfT[ΔC⊙f(t+1)⊙(1−f(t+1))⊙C(t)]+WaT{ΔC⊙i(t+1)⊙[1−(a(t+1))2]}+WiT[ΔC⊙a(t+1)⊙i(t+1)⊙(1−i(t+1))]
而 δ C ( t ) \delta_C^{(t)} δC(t)的反向梯度误差由前一层 δ C ( t + 1 ) \delta_C^{(t+1)} δC(t+1)的梯度误差和本层的从 h ( t ) h^{(t)} h(t)传回来的梯度误差两部分组成,即:
δ C ( t ) = ( ∂ C ( t + 1 ) ∂ C ( t ) ) T ∂ L ∂ C ( t + 1 ) + ( ∂ h ( t ) ∂ C ( t ) ) T ∂ L ∂ h ( t ) = ( ∂ C ( t + 1 ) ∂ C ( t ) ) T δ C ( t + 1 ) + δ h ( t ) ⊙ o ( t ) ⊙ ( 1 − t a n h 2 ( C ( t ) ) ) = δ C ( t + 1 ) ⊙ f ( t + 1 ) + δ h ( t ) ⊙ o ( t ) ⊙ ( 1 − t a n h 2 ( C ( t ) ) ) \delta_C^{(t)} =(\frac{\partial C^{(t+1)}}{\partial C^{(t)}} )^T\frac{\partial L}{\partial C^{(t+1)}} + (\frac{\partial h^{(t)}}{\partial C^{(t)}} )^T\frac{\partial L}{\partial h^{(t)}}= (\frac{\partial C^{(t+1)}}{\partial C^{(t)}} )^T\delta_C^{(t+1)} + \delta_h^{(t)} \odot o^{(t)} \odot (1 - tanh^2(C^{(t)})) = \delta_C^{(t+1)} \odot f^{(t+1)} + \delta_h^{(t)} \odot o^{(t)} \odot (1 - tanh^2(C^{(t)})) δC(t)=(∂C(t)∂C(t+1))T∂C(t+1)∂L+(∂C(t)∂h(t))T∂h(t)∂L=(∂C(t)∂C(t+1))TδC(t+1)+δh(t)⊙o(t)⊙(1−tanh2(C(t)))=δC(t+1)⊙f(t+1)+δh(t)⊙o(t)⊙(1−tanh2(C(t)))
有了 δ h ( t ) \delta_h^{(t)} δh(t)和 δ C ( t ) \delta_C^{(t)} δC(t), 计算这一大堆参数的梯度就很容易了,这里只给出Wf的梯度计算过程,其他的 U f , b f , W a , U a , b a , W i , U i , b i , W o , U o , b o , V , c U_f, b_f, W_a, U_a, b_a, W_i, U_i, b_i, W_o, U_o, b_o,V, c Uf,bf,Wa,Ua,ba,Wi,Ui,bi,Wo,Uo,bo,V,c的梯度大家只要照搬就可以了。
∂ L ∂ W f = ∑ t = 1 τ [ δ C ( t ) ⊙ C ( t − 1 ) ⊙ f ( t ) ⊙ ( 1 − f ( t ) ) ] ( h ( t − 1 ) ) T \frac{\partial L}{\partial W_f} =\sum\limits_{t=1}^{\tau} [\delta_C^{(t)} \odot C^{(t-1)} \odot f^{(t)}\odot(1-f^{(t)})] (h^{(t-1)})^T ∂Wf∂L=t=1∑τ[δC(t)⊙C(t−1)⊙f(t)⊙(1−f(t))](h(t−1))T
BiLSTM
前向的LSTM与后向的LSTM结合成BiLSTM。
我们对“我爱中国”这句话进行编码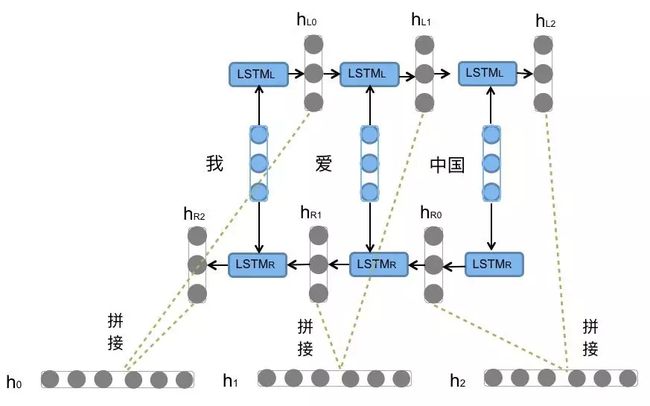
前向的依次输入“我”,“爱”,“中国”得到三个向量{ h L 0 , h L 1 , h L 2 h_{L0},h_{L1},h_{L2} hL0,hL1,hL2}。后向的依次输入“中国”,“爱”,“我”得到三个向量{ h R 0 , h R 1 , h R 2 h_{R0},h_{R1},h_{R2} hR0,hR1,hR2}。最后将前向和后向的隐向量进行拼接得到{ [ h L 0 , h R 2 ] [ h L 1 , h R 1 ] , [ h L 2 , h R 0 ] [h_{L0},h_{R2}][h_{L1},h_{R1} ], [h_{L2},h_{R0} ] [hL0,hR2][hL1,hR1],[hL2,hR0]},即{ h 0 , h 1 , h 2 h_0,h_1,h_2 h0,h1,h2}。