银行企业建设容器持久化存储的必要性以及难点剖析
http://www.talkwithtrend.com/Article/217329
1. 摘要:
随着以docker为代表的容器技术的发展,为应用的开发、测试、运维带来了巨大的便捷。容器技术不仅在互联网企业应用广泛,在传统银行业的IT中也发展迅速。很多银行都在建设以docker为容器技术支撑的PaaS平台,尝试一些新型应用的微服务框架和容器化改造。由于数据对于银行的重要性,不可避免的要解决容器的持久化数据存储问题。本文将结合某银行PaaS平台建设和运维过程中的实践案例,阐述容器持久化存储的必要性和难点。
2. 容器存储的实现方案
容器的特性决定了容器本身是非持久化的,容器被删除,其上的数据也一并删除。而其上承载的应用分为有状态和无状态。容器更倾向于无状态化应用,可水平扩展的,但并不意味所有的应用都是无状态的,特别是银行的应用,一些服务的状态需要保存比如日志等相关信息,因此需要持久化存储。容器存储大致有三种存储方案:
(1)原生云存储方案:按照纯粹的原生云的设计模式,持久化数据并不是存储在容器中,而是作为后端服务,例如对象存储和数据库即服务。这个方案可以确保容器和它们的数据持久化支持服务松耦合,同时也不需要那些会限制扩展的依赖。
(2)把容器作为虚拟机:利用容器带来的便携性的优点,一些用户将容器作为轻量虚拟机来使用。如果便携性是迁移到容器的原因之一,那么采用容器替代虚拟机来安装遗留应用是这种便携性的反模式。由于存储数据是紧耦合在容器上,便携性难以实现。
(3)容器持久化数据卷:在容器中运行的应用,应用真正需要保存的数据,可以写入持久化的Volume数据卷。在这个方案中,持久层产生价值,不是通过弹性,而是通过灵活可编程,例如通过设计的API来扩展存储。这个方案结合了持久层和或纯云原生设计模式。
Docker发布了容器卷插件规范,允许第三方厂商的数据卷在Docker引擎中提供数据服务。这种机制意味着外置存储可以超过容器的生命周期而独立存在。而且各种存储设备只要满足接口API标准,就可接入Docker容器的运行平台中。现有的各种存储可以通过简单的驱动程序封装,从而实现和Docker容器的对接。可以说,驱动程序实现了和容器引擎的北向接口,底层则调用后端存储的功能完成数据存取等任务。目前已经实现的Docker Volume Plugin中,后端存储包括常见的NFS,GlusterFS和块设备等。
3. 某银行容器平台的数据分类和存储
某银行已建成的容器管理平台数据主要分为:平台数据和应用数据。两大类数据均需要独立于容器外的持久化存储。
平台数据分类如下:
(1)应用建模数据:应用属性、节点、微服务编排、微服务运行管理策略等(创建于容器管理平台,存放于后台DB中);
(2) 集群管理数据:容器宿主机节点信息(包括高可用/等保/网络区域、IP、调度标签)(存放于后台DB);集群资源监控(容器管理平台动态生成,存放于后台DB);
(3)多租户管理数据:用户身份和租户信息、租户拥有的集群(创建于外部系统,存放于外部CMDB);用户在租户中的角色(创建于容器管理平台,存放于后台DB)。租户使用计量(容器管理平台动态生成,存放于后台DB);
(4)应用监控数据:应用容器信息(容器IP、所在宿主机) 、运行情况(健康情况、资源占用),由容器管理平台动态生成,存放于后台DB,外部系统通过接口获取应用容器信息和运行情况;事件监控(由平台动态生成,存放于的事件审计DB,并通过消息队列实时上报给外部系统);APM、NPM数据(由外部系统从容器集群获取,保存在外部DB中);
应用数据分类如下:
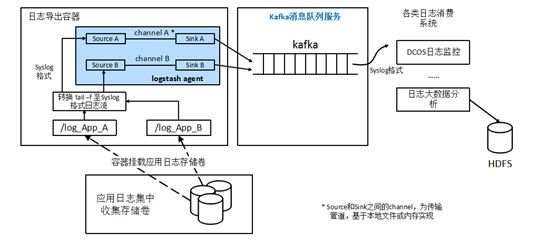
(1)应用日志:应用在容器中运行动态生成的数据,存储在容器平台管理的外置存储中,结合一定的日志规范并通过logstash传递给外部的kafaka队列,日志分析和监控,并保存在外部数据库中,如下图:
(2)应用生成数据:应用产生的相关数据,如大数据的相关应用,数据经过流处理和解析器解析后,最终将结构化的数据存储在应用的DB中;
4. 某银行容器平台的存储管理
某银行已建成的容器管理平台,容器是以运行时挂载逻辑卷的方式使用存储资源。存储资源分为以下两类:
(1)原生的本地存储管理:容器宿主机本地硬盘,创建容器时指定文件存储路径与本地文件系统路径的映射关系,适合磁盘IO要求较高,迁移要求不高的应用(例如大数据应用);
(2)平台提供的共享式存储管理,PaaS平台之外的共享存储,预先通过容器平台的存储驱动在共享存储系统创建逻辑卷,创建容器时挂载,适合迁移要求高、不同的容器之间数据共享和重用等要求;原理如下图:

PaaS平台提供volume plugin,对接共享存储,并通过容器启动参数指定为卷驱动:docker run –volume-driver=XXXX -v hostVol:/internalVol
容器使用共享式存储的过程:
(1)通过–volume-driver指定volume plugin
(2)Volume plugin和共享存储系统对接,负责在共享存储上创建卷,并挂载到本地容器宿主机,通过本地目录hostVol访问
(3)通过容器启动参数-v,容器将宿主机的本地目录hostVol挂载到容器内部,容器通过内部目录internalVol读写
(4)Volume plugin负责在共享存储上进行卷的创建/删除/挂载/卸载全过程
(5)每台容器宿主机上都需要安装存储驱动(volume plugin)。当容器宿主机被添加到容器集群时,由管理平台自动向容器宿主机推送安装存储驱动
根据该银行业务需求,容器平台的共享存储驱动需要支持以下方式使用共享存储:直接连接存储设备方式,需要支持的共享存储类型包括:CEPH,NFS,通过连接第三方存储驱动方式,需要支持的第三方存储驱动包括:Cinder,通过连接Cinder,实现更多异构存储方案的支持。
5. 容器持久化存储的问题与思考
在某银行容器平台的建设过程中,对容器持久化存储有以下几点思考:
(1)扩展性和弹性问题:在只有几十或几百容器的环境里,持久化存储实现架构可能并不会成为一个问题。但是一旦增长到成千上万的容器规模时,大量容器都是临时运行并且不断迁移,它们所依赖的持久化存储如果是紧耦合到特定容器宿主机的话将会极大地影响到整个容器架构的可扩展和弹性伸缩能力。试想一下构建一个大型云原生应用所使用的容器宿主机依赖于SAN存储来实现持久化,可扩展能力会被牢牢限制在可以连接到相同的SAN存储卷的服务器数量。或者使用共享文件系统来实现持久化,从一个容器挂载一个卷所需的时间通常要比新起一个容器更久一些。这就产生了一个容器里快速拉起一个应用的需求与挂载持久化存储层必需的耗时两者之间的相互冲突。
(2)行为模式:银行用户把应用从虚拟机迁移到了容器,为什么无法得到容器理应带来的全部收益。通过更多的持久化存储选择,是否已经偏离了像12要素这样的云原生应用的设计模式。传统的存储模式及解决方案的依赖可能恰恰是加深了对云原生设计的反模式。
(3)监控:容器持久化存储的实现往往要依赖于容器外部的数据存储,而对于磁盘IO要求比较高的应用会直接用宿主机的本地磁盘,容器内部只能看到持久化存储数据已用空间,并不能看到外部数据盘的大小。当容器数量不多并设置相应的规则可以监控外部数据盘,但当容器数量过多并用到了不同的外部存储卷,针对于单个容器精细化的持久化数据存储监控可能就会成为问题。