C#与数据结构--二叉树的遍历、图的遍历
6.2.2 二叉树的存储结构
二叉树的存储可分为两种:顺序存储结构和链式存储结构。
1. 顺序存储结构
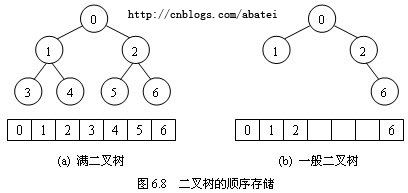
把一个满二叉树自上而下、从左到右顺序编号,依次存放在数组内,可得到图6.8(a)所示的结果。设满二叉树结点在数组中的索引号为i,那么有如下性质。
(1) 如果i = 0,此结点为根结点,无双亲。
(2) 如果i > 0,则其双亲结点为(i -1) / 2 。(注意,这里的除法是整除,结果中的小数部分会被舍弃。)
(3) 结点i的左孩子为2i + 1,右孩子为2i + 2。
(4) 如果i > 0,当i为奇数时,它是双亲结点的左孩子,它的兄弟为i + 1;当i为偶数时,它是双新结点的右孩子,它的兄弟结点为i – 1。
(5) 深度为k的满二叉树需要长度为2 k-1的数组进行存储。
通过以上性质可知,使用数组存放满二叉树的各结点非常方便,可以根据一个结点的索引号很容易地推算出它的双亲、孩子、兄弟等结点的编号,从而对这些结点进行访问,这是一种存储二叉满二叉树或完全二叉树的最简单、最省空间的做法。
为了用结点在数组中的位置反映出结点之间的逻辑关系,存储一般二叉树时,只需要将数组中空结点所对应的位置设为空即可,其效果如图6.8(b)所示。这会造成一定的空间浪费,但如果空结点的数量不是很多,这些浪费可以忽略。
一个深度为k的二叉树需要2 k-1个存储空间,当k值很大并且二叉树的空结点很多时,最坏的情况是每层只有一个结点,再使用顺序存储结构来存储显然会造成极大地浪费,这时就应该使用链式存储结构来存储二叉树中的数据。
1. 链式存储结构
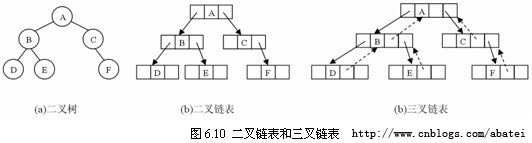
二叉树的链式存储结构可分为二叉链表和三叉链表。二叉链表中,每个结点除了存储本身的数据外,还应该设置两个指针域left和right,它们分别指向左孩子和右孩子(如图6.9(a)所示)。
当需要在二叉树中经常寻找某结点的双亲,每个结点还可以加一个指向双亲的指针域parent,如图6.9(b)所示,这就是三叉链表。

图6.10所示的是二叉链表和三叉链表的存储结构,其中虚线箭头表示parent指针所指方向。
二叉树还有一种叫双亲链表的存储结构,它只存储结点的双亲信息而不存储孩子信息,由于二叉树是一种有序树,一个结点的两个孩子有左右之分,因此结点中除了存放双新信息外,还必须指明这个结点是左孩子还是右孩子。由于结点不存放孩子信息,无法通过头指针出发遍历所有结点,因此需要借助数组来存放结点信息。图6.10(a)所示的二叉树使用双亲链表进行存储将得到图6.11所示的结果。由于根节点没有双新,所以它的parent指针的值设为-1。
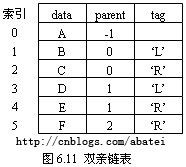
双亲链表中元素存放的顺序是根据结点的添加顺序来决定的,也就是说把各个元素的存放位置进行调换不会影响结点的逻辑结构。由图6.11可知,双亲链表在物理上是一种顺序存储结构。
二叉树存在多种存储结构,选用何种方法进行存储主要依赖于对二叉树进行什么操作来确定。而二叉链表是二叉树最常用的存储结构,下面几节给出的有关二叉树的算法大多基于二叉链表存储结构。
6.3 二叉树的遍历
二叉树遍历(Traversal)就是按某种顺序对树中每个结点访问且只能访问一次的过程。访问的含义很广,如查询、计算、修改、输出结点的值。树遍历本质上是将非线性结构线性化,它是二叉树各种运算和操作的实现基础,需要高度重视。
6.3.1 二叉树的深度优先遍历
|
图6.12二叉树的递归定义 |
|
D |
|
L |
|
R |
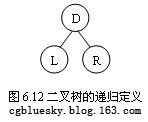
先左后右 先右后左
先序 DLR DRL
中序 LDR RDL
后序 LRD RLD
这里只讨论先左后右的三种遍历算法。
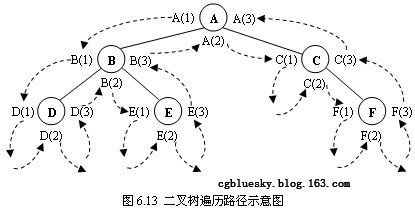
如图6.13所示,在沿着箭头方向所指的路径对二叉树进行遍历时,每个节点会在这条搜索路径上会出现三次,而访问操作只能进行一次,这时就需要决定在搜索路径上第几次出现的结点进行访问操作,由此就引出了三种不同的遍历算法。
1. 先序遍历
若二叉树为非空,则过程为:
(1) 访问根节点。
(2) 先序遍历左子树。
(3) 先序遍历右子树。
图6.13中,先序遍历就是把标号为(1)的结点按搜索路径访问的先后次序连接起来,得出结果为:ABDECF。
2. 中序遍历
若二叉树为非空,则过程为:
(1) 按中序遍历左子树。
(2) 访问根结点。
(3) 按中序遍历右子树。
图6.13中,先序遍历就是把标号为(2)的结点按搜索路径访问的先后次序连接起来,得出结果为:DBEACF。
3. 后序遍历
若二叉树为非空,则过程为:
(1) 按后序遍历左子树。
(2) 按后序遍历右子树
(3) 访问根结点。
图6.13中,先序遍历就是把标号为(3)的结点按搜索路径访问的先后次序连接起来,得出结果为:DEBFCA。
【例6-1 BinaryTreeNode.cs】二叉树结点类
2 public class Node
3 {
4 // 成员变量
5 private object _data; // 数据
6 private Node _left; // 左孩子
7 private Node _right; // 右孩子
8 public object Data
9 {
10 get { return _data; }
11 }
12 public Node Left // 左孩子
13 {
14 get { return _left; }
15 set { _left = value; }
16 }
17 public Node Right // 右孩子
18 {
19 get { return _right; }
20 set { _right = value; }
21 }
22 // 构造方法
23 public Node( object data)
24 {
25 _data = data;
26 }
27 public override string ToString()
28 {
29 return _data.ToString();
30 }
31 }
32
Node类专门用于表示二叉树中的一个结点,它很简单,只有三个属性:Data表示结点中的数据;Left表示这个结点的左孩子,它是Node类型;Right表示这个结点的右孩子,它也是Node类型。
【例6-1 BinaryTree.cs】二叉树集合类
2 public class BinaryTree
3 { // 成员变量
4 private Node _head; // 头指针
5 private string cStr; // 用于构造二叉树的字符串
6 public Node Head // 头指针
7 {
8 get { return _head; }
9 }
10 // 构造方法
11 public BinaryTree( string constructStr)
12 {
13 cStr = constructStr;
14 _head = new Node(cStr[ 0 ]); // 添加头结点
15 Add(_head, 0 ); // 给头结点添加孩子结点
16 }
17 private void Add(Node parent, int index)
18 {
19 int leftIndex = 2 * index + 1 ; // 计算左孩子索引
20 if (leftIndex < cStr.Length) // 如果索引没超过字符串长度
21 {
22 if (cStr[leftIndex] != ' # ' ) // '#'表示空结点
23 { // 添加左孩子
24 parent.Left = new Node(cStr[leftIndex]);
25 // 递归调用Add方法给左孩子添加孩子节点
26 Add(parent.Left, leftIndex);
27 }
28 }
29 int rightIndex = 2 * index + 2 ;
30 if (rightIndex < cStr.Length)
31 {
32 if (cStr[rightIndex] != ' # ' )
33 { // 添加右孩子
34 parent.Right = new Node(cStr[rightIndex]);
35 // 递归调用Add方法给右孩子添加孩子节点
36 Add(parent.Right, rightIndex);
37 }
38 }
39 }
40 public void PreOrder(Node node) // 先序遍历
41 {
42 if (node != null )
43 {
44 Console.Write(node.ToString()); // 打印字符
45 PreOrder(node.Left); // 递归
46 PreOrder(node.Right); // 递归
47 }
48 }
49 public void MidOrder(Node node) // 中序遍历
50 {
51 if (node != null )
52 {
53 MidOrder(node.Left); // 递归
54 Console.Write(node.ToString()); // 打印字符
55 MidOrder(node.Right); // 递归
56 }
57 }
58 public void AfterOrder(Node node) // 后继遍历
59 {
60 if (node != null )
61 {
62 AfterOrder(node.Left); // 递归
63 AfterOrder(node.Right); // 递归
64 Console.Write(node.ToString()); // 打印字符
65 }
66 }
67 }
68
BinaryTree是一个二叉树的集合类,它属于二叉链表,实际存储的信息只有一个头结点指针(Head),由于是链式存储结构,可以由Head指针出发遍历整个二叉树。为了便于测试及添加结点,假设BinaryTree类中存放的数据是字符类型,第5行声明了一个字符串类型成员cStr,它用于存放结点中所有的字符。字符串由满二叉树的方式进行构造,空结点用‘#’号表示(参考本章“二叉树存储结构”这一小节中的“顺序存储结构”)。图6.13所示的二叉树可表示为:“ABCDE#F”。
11~16行的构造方法传入一个构造字符串,并在Add()方法中根据这个字符串来构造二叉树中相应的结点。需要注意,这个构造方法只用于测试。
17~39行的Add()方法用于添加结点,它的第一个参数parent表示需要添加孩子结点的双亲结点,第二个参数index表示这个双亲结点的编号(编号表示使用顺序存储结构时它在数组中的索引,请参考本章“二叉树存储结构”这一小节中的“顺序存储结构”)。添加孩子结点的方法是先计算孩子结点的编号,然后通过这个编号在cStr中取出相应的字符,并构造新的孩子结点用于存放这个字符,接下来递归调用Add()方法给孩子结点添加它们的孩子结点。注意,这个方法只用于测试。
40~48行代码的PreOrder()方法用于先序遍历,它的代码跟之前所讲解的先序遍历过程完全一样。
49~57行代码的MidOrder()方法用于中序遍历。
58~66行代码的AfterOrder()方法用于后序遍历。
以上三个方法都使用了递归来完成遍历,这符合二叉树的定义。
【例6-1 Demo6-1.cs】二叉树深度优先遍历测试
2 class Demo6_1
3 {
4 static void Main( string [] args)
5 { // 使用字符串构造二叉树
6 BinaryTree bTree = new BinaryTree( " ABCDE#F " );
7 bTree.PreOrder(bTree.Head); // 先序遍
8 Console.WriteLine();
9 bTree.MidOrder(bTree.Head); // 中序遍
10 Console.WriteLine();
11 bTree.AfterOrder(bTree.Head); // 后序遍
12 Console.WriteLine();
13 }
14 }
15
运行结果:
ABDECF
DBEACF
DEBFCA
6.3.2 二叉树的宽度优先遍历
之前所讲述的二叉树的深度优先遍历的搜索路径是首先搜索一个结点的所有子孙结点,再搜索这个结点的兄弟结点。是否可以先搜索所有兄弟和堂兄弟结点再搜索子孙结点呢?
由于二叉树结点分属不同的层次,因此可以从上到下、从左到右依次按层访问每个结点。它的访问顺序正好和之前所述二叉树顺序存储结构中的结点在数组中的存放顺序相吻合。如图6.13中的二叉树使用宽度优先遍历访问的顺序为:ABCDEF。
这个搜索过程不再需要使用递归,但需要借助队列来完成。
(1) 将根结点压入队列之中,开始执行步骤(2)。
(2) 若队列为空,则结束遍历操作,否则取队头结点D。
(3) 若结点D的左孩子结点存在,则将其左孩子结点压入队列。
(4) 若结点D的右孩子结点存在,则将其右孩子结点压入队列,并重复步骤(2)。
【例6-2 BinaryTreeNode.cs.cs】二叉树结点类,使用例6-1同名文件。
【例6-2 LevelOrderBinaryTree.cs】包含宽度优先遍历方法的二叉树集合类
打开例6-1的【BinaryTree.cs】文件,在BinaryTree类中添加如入方法后另存为LevelOrderBinaryTree.cs文件。
2 {
3 Queue queue = new Queue(); // 声明一个队例
4 queue.Enqueue(_head); // 把根结点压入队列
5 while (queue.Count > 0 ) // 只要队列不为空
6 {
7 Node node = (Node)queue.Dequeue(); // 出队
8 Console.Write(node.ToString()); // 访问结点
9 if (node.Left != null ) // 如果结点左孩子不为空
10 { // 把左孩子压入队列
11 queue.Enqueue(node.Left);
12 }
13 if (node.Right != null ) // 如果结点右孩子不为熔
14 { // 把右孩子压入队列
15 queue.Enqueue(node.Right);
16 }
17 }
18 }
【例6-2 Demo6-2.cs】二叉树宽度优先遍历测试
2 class Demo6_2
3 {
4 static void Main( string [] args)
5 { // 使用字符串构造二叉树
6 BinaryTree bTree = new BinaryTree( " ABCDE#F " );
7 bTree.LevelOrder();
8 }
9 }
运行结果:ABCDEF
8.2 图的存储结构
图的存储结构除了要存储图中各个顶点的本身的信息外,同时还要存储顶点与顶点之间的所有关系(边的信息),因此,图的结构比较复杂,很难以数据元素在存储区中的物理位置来表示元素之间的关系,但也正是由于其任意的特性,故物理表示方法很多。常用的图的存储结构有邻接矩阵、邻接表、十字链表和邻接多重表。
8.2.1 邻接矩阵表示法
对于一个具有n个顶点的图,可以使用n*n的矩阵(二维数组)来表示它们间的邻接关系。图8.10和图8.11中,矩阵A(i,j)=1表示图中存在一条边(Vi,Vj),而A(i,j)=0表示图中不存在边(Vi,Vj)。实际编程时,当图为不带权图时,可以在二维数组中存放bool值,A(i,j)=true表示存在边(Vi,Vj),A(i,j)=false表示不存在边(Vi,Vj);当图带权值时,则可以直接在二维数组中存放权值,A(i,j)=null表示不存在边(Vi,Vj)。
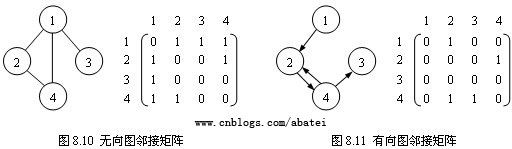
图8.10所示的是无向图的邻接矩阵表示法,可以观察到,矩阵延对角线对称,即A(i,j)= A(j,i)。无向图邻接矩阵的第i行或第i列非零元素的个数其实就是第i个顶点的度。这表示无向图邻接矩阵存在一定的数据冗余。
图8.11所示的是有向图邻接矩阵表示法,矩阵并不延对角线对称,A(i,j)=1表示顶点Vi邻接到顶点Vj;A(j,i)=1则表示顶点Vi邻接自顶点Vj。两者并不象无向图邻接矩阵那样表示相同的意思。有向图邻接矩阵的第i行非零元素的个数其实就是第i个顶点的出度,而第i列非零元素的个数是第i个顶点的入度,即第i个顶点的度是第i行和第i列非零元素个数之和。
由于存在n个顶点的图需要n2个数组元素进行存储,当图为稀疏图时,使用邻接矩阵存储方法将出现大量零元素,照成极大地空间浪费,这时应该使用邻接表表示法存储图中的数据。
8.2.2 邻接表表示法
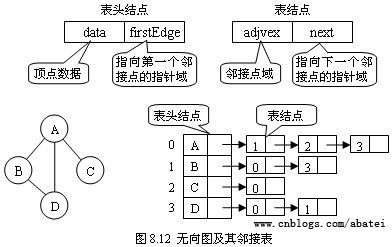
图的邻接矩阵存储方法跟树的孩子链表示法相类似,是一种顺序分配和链式分配相结合的存储结构。邻接表由表头结点和表结点两部分组成,其中图中每个顶点均对应一个存储在数组中的表头结点。如这个表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。如图8.12所示,表结点存放的是邻接顶点在数组中的索引。对于无向图来说,使用邻接表进行存储也会出现数据冗余,表头结点A所指链表中存在一个指向C的表结点的同时,表头结点C所指链表也会存在一个指向A的表结点。
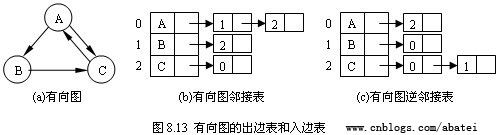
有向图的邻接表有出边表和入边表(又称逆邻接表)之分。出边表的表结点存放的是从表头结点出发的有向边所指的尾顶点;入边表的表结点存放的则是指向表头结点的某个头顶点。如图8.13所示,图(b)和(c)分别为有向图(a)的出边表和入边表。
以上所讨论的邻接表所表示的都是不带权的图,如果要表示带权图,可以在表结点中增加一个存放权的字段,其效果如图8.14所示。

【注意】:观察图8.14可以发现,当删除存储表头结点的数组中的某一元素,有可能使部分表头结点索引号的改变,从而导致大面积修改表结点的情况发生。可以在表结点中直接存放指向表头结点的指针以解决这个问题(在链表中存放类实例即是存放指针,但必须要保证表头结点是类而不是结构体)。在实际创建邻接表时,甚至可以使用链表代替数组存放表头结点或使用顺序表存代替链表存放表结点。对所学的数据结构知识应当根据实际情况及所使用语言的特点灵活应用,切不可生搬硬套。
【例8-1 AdjacencyList.cs】图的邻接表存储结构
using System.Collections.Generic;
public class AdjacencyList < T >
{
List < Vertex < T >> items; // 图的顶点集合
public AdjacencyList() : this ( 10 ) { } // 构造方法
public AdjacencyList( int capacity) // 指定容量的构造方法
{
items = new List < Vertex < T >> (capacity);
}
public void AddVertex(T item) // 添加一个顶点
{ // 不允许插入重复值
if (Contains(item))
{
throw new ArgumentException( " 插入了重复顶点! " );
}
items.Add( new Vertex < T > (item));
}
public void AddEdge(T from, T to) // 添加无向边
{
Vertex < T > fromVer = Find(from); // 找到起始顶点
if (fromVer == null )
{
throw new ArgumentException( " 头顶点并不存在! " );
}
Vertex < T > toVer = Find(to); // 找到结束顶点
if (toVer == null )
{
throw new ArgumentException( " 尾顶点并不存在! " );
}
// 无向边的两个顶点都需记录边信息
AddDirectedEdge(fromVer, toVer);
AddDirectedEdge(toVer, fromVer);
}
public bool Contains(T item) // 查找图中是否包含某项
{
foreach (Vertex < T > v in items)
{
if (v.data.Equals(item))
{
return true ;
}
}
return false ;
}
private Vertex < T > Find(T item) // 查找指定项并返回
{
foreach (Vertex < T > v in items)
{
if (v.data.Equals(item))
{
return v;
}
}
return null ;
}
// 添加有向边
private void AddDirectedEdge(Vertex < T > fromVer, Vertex < T > toVer)
{
if (fromVer.firstEdge == null ) // 无邻接点时
{
fromVer.firstEdge = new Node(toVer);
}
else
{
Node tmp, node = fromVer.firstEdge;
do
{ // 检查是否添加了重复边
if (node.adjvex.data.Equals(toVer.data))
{
throw new ArgumentException( " 添加了重复的边! " );
}
tmp = node;
node = node.next;
} while (node != null );
tmp.next = new Node(toVer); // 添加到链表未尾
}
}
public override string ToString() // 仅用于测试
{ // 打印每个节点和它的邻接点
string s = string .Empty;
foreach (Vertex < T > v in items)
{
s += v.data.ToString() + " : " ;
if (v.firstEdge != null )
{
Node tmp = v.firstEdge;
while (tmp != null )
{
s += tmp.adjvex.data.ToString();
tmp = tmp.next;
}
}
s += " /r/n " ;
}
return s;
}
// 嵌套类,表示链表中的表结点
public class Node
{
public Vertex < T > adjvex; // 邻接点域
public Node next; // 下一个邻接点指针域
public Node(Vertex < T > value)
{
adjvex = value;
}
}
// 嵌套类,表示存放于数组中的表头结点
public class Vertex < TValue >
{
public TValue data; // 数据
public Node firstEdge; // 邻接点链表头指针
public Boolean visited; // 访问标志,遍历时使用
public Vertex(TValue value) // 构造方法
{
data = value;
}
}
}
AdjacencyList
l Vertex类中包含了一个visited成员,它的作用是在图遍历时标识当前节点是否被访问过,这一点在稍后会讲到。
l 邻接点指针域adjvex直接指向某个表头结点,而不是表头结点在数组中的索引。
AdjacencyList
由于一条无向边的信息需要在边的两个顶点分别存储信息,即添加两个有向边,所以58~78行代码的私有方法AddDirectedEdge()方法用于添加一个有向边。新的邻接点信息即可以添加到链表的头部也可以添加到尾部,添加到链表头部可以简化操作,但考虑到要检查是否添加了重复边,需要遍历整个链表,所以最终把邻接点信息添加到链表尾部。
【例8-1 Demo8-1.cs】图的邻接表存储结构测试
class Demo8_1
{
static void Main( string [] args)
{
AdjacencyList < char > a = new AdjacencyList < char > ();
// 添加顶点
a.AddVertex( ' A ' );
a.AddVertex( ' B ' );
a.AddVertex( ' C ' );
a.AddVertex( ' D ' );
// 添加边
a.AddEdge( ' A ' , ' B ' );
a.AddEdge( ' A ' , ' C ' );
a.AddEdge( ' A ' , ' D ' );
a.AddEdge( ' B ' , ' D ' );
Console.WriteLine(a.ToString());
}
}
A:BCD
B:AD
C:A
D:AB
本例存储的表如图8.12所示,结果中,冒号前面的是表头结点,冒号后面的是链表中的表结点。
8.3 图的遍历
和树的遍历类似,在此,我们希望从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍历(TraversingGraph)。如果只访问图的顶点而不关注边的信息,那么图的遍历十分简单,使用一个foreach语句遍历存放顶点信息的数组即可。但如果为了实现特定算法,就需要根据边的信息按照一定顺序进行遍历。图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础。
图的遍历要比树的遍历复杂得多,由于图的任一顶点都可能和其余顶点相邻接,故在访问了某顶点之后,可能顺着某条边又访问到了已访问过的顶点,因此,在图的遍历过程中,必须记下每个访问过的顶点,以免同一个顶点被访问多次。为此给顶点附设访问标志visited,其初值为false,一旦某个顶点被访问,则其visited标志置为true。
图的遍历方法有两种:一种是深度优先搜索遍历(Depth-First Search 简称DFS);另一种是广度优先搜索遍历(Breadth_First Search 简称BFS)。
8.3.1 深度优先搜索遍历
图的深度优先搜索遍历类似于二叉树的深度优先搜索遍历。其基本思想如下:假定以图中某个顶点Vi为出发点,首先访问出发点,然后选择一个Vi的未访问过的邻接点Vj,以Vj为新的出发点继续进行深度优先搜索,直至图中所有顶点都被访问过。显然,这是一个递归的搜索过程。
现以图8.15为例说明深度优先搜索过程。假定V1是出发点,首先访问V1。因V1有两个邻接点V2、V3均末被访问过,可以选择V2作为新的出发点,访问V2之后,再找V2的末访问过的邻接点。同V2邻接的有V1、V4和V5,其中V1已被访问过,而V4、V5尚未被访问过,可以选择V4作为新的出发点。重复上述搜索过程,继续依次访问V8、V5 。访问V5之后,由于与V5相邻的顶点均已被访问过,搜索退回到V8,访问V8的另一个邻接点V6。接下来依次访问V3和V7,最后得到的的顶点的访问序列为:V1 → V2 → V4 → V8 → V5 → V6 → V3 → V7。
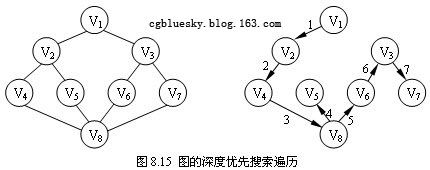
下面根据上一节创建的邻接表存储结构添加深度优先搜索遍历代码。
【例8-2 DFSTraverse.cs】深度优先搜索遍历
打开【例8-1 AdjacencyList.cs】,在AdjacencyList
36 {
37 InitVisited(); // 将visited标志全部置为false
38 DFS(items[ 0 ]); // 从第一个顶点开始遍历
39 }
40 private void DFS(Vertex < T > v) // 使用递归进行深度优先遍历
41 {
42 v.visited = true ; // 将访问标志设为true
43 Console.Write(v.data + " " ); // 访问
44 Node node = v.firstEdge;
45 while (node != null ) // 访问此顶点的所有邻接点
46 { // 如果邻接点未被访问,则递归访问它的边
47 if ( ! node.adjvex.visited)
48 {
49 DFS(node.adjvex); // 递归
50 }
51 node = node.next; // 访问下一个邻接点
52 }
53 }
98 private void InitVisited() // 初始化visited标志
99 {
100 foreach (Vertex < T > v in items)
101 {
102 v.visited = false ; // 全部置为false
103 }
104 }
【例8-2 Demo8-2.cs】深度优先搜索遍历测试
class Demo8_2
{
static void Main( string [] args)
{
AdjacencyList < string > a = new AdjacencyList < string > ();
a.AddVertex( " V1 " );
a.AddVertex( " V2 " );
a.AddVertex( " V3 " );
a.AddVertex( " V4 " );
a.AddVertex( " V5 " );
a.AddVertex( " V6 " );
a.AddVertex( " V7 " );
a.AddVertex( " V8 " );
a.AddEdge( " V1 " , " V2 " );
a.AddEdge( " V1 " , " V3 " );
a.AddEdge( " V2 " , " V4 " );
a.AddEdge( " V2 " , " V5 " );
a.AddEdge( " V3 " , " V6 " );
a.AddEdge( " V3 " , " V7 " );
a.AddEdge( " V4 " , " V8 " );
a.AddEdge( " V5 " , " V8 " );
a.AddEdge( " V6 " , " V8 " );
a.AddEdge( " V7 " , " V8 " );
a.DFSTraverse();
}
}
运行结果:
V1 V2 V4 V8 V5 V6 V3 V7
本例参照图8-15进行设计,运行过程请参照对图8-15所作的分析。
8.3.2 广度优先搜索遍历
图的广度优先搜索遍历算法是一个分层遍历的过程,和二叉树的广度优先搜索遍历类同。它从图的某一顶点Vi出发,访问此顶点后,依次访问Vi的各个未曾访问过的邻接点,然后分别从这些邻接点出发,直至图中所有已有已被访问的顶点的邻接点都被访问到。对于图8.15所示的无向连通图,若顶点Vi为初始访问的顶点,则广度优先搜索遍历顶点访问顺序是:V1 → V2 → V3 → V4 → V5 → V6 → V7 → V8。遍历过程如图8.16的所示。

和二叉树的广度优先搜索遍历类似,图的广度优先搜索遍历也需要借助队列来完成,例8.3演示了这个过程。
【例8-3 BFSTraverse.cs】广度优先搜索遍历
打开【例8-2 DFSTraverse.cs】,在AdjacencyList
55 {
56 InitVisited(); // 将visited标志全部置为false
57 BFS(items[ 0 ]); // 从第一个顶点开始遍历
58 }
59 private void BFS(Vertex < T > v) // 使用队列进行广度优先遍历
60 { // 创建一个队列
61 Queue < Vertex < T >> queue = new Queue < Vertex < T >> ();
62 Console.Write(v.data + " " ); // 访问
63 v.visited = true ; // 设置访问标志
64 queue.Enqueue(v); // 进队
65 while (queue.Count > 0 ) // 只要队不为空就循环
66 {
67 Vertex < T > w = queue.Dequeue();
68 Node node = w.firstEdge;
69 while (node != null ) // 访问此顶点的所有邻接点
70 { // 如果邻接点未被访问,则递归访问它的边
71 if ( ! node.adjvex.visited)
72 {
73 Console.Write(node.adjvex.data + " " ); // 访问
74 node.adjvex.visited = true ; // 设置访问标志
75 queue.Enqueue(node.adjvex); // 进队
76 }
77 node = node.next; // 访问下一个邻接点
78 }
79 }
80 }
【例8-3 Demo8-3.cs】广度优先搜索遍历测试
class Demo8_3
{
static void Main( string [] args)
{
AdjacencyList < string > a = new AdjacencyList < string > ();
a.AddVertex( " V1 " );
a.AddVertex( " V2 " );
a.AddVertex( " V3 " );
a.AddVertex( " V4 " );
a.AddVertex( " V5 " );
a.AddVertex( " V6 " );
a.AddVertex( " V7 " );
a.AddVertex( " V8 " );
a.AddEdge( " V1 " , " V2 " );
a.AddEdge( " V1 " , " V3 " );
a.AddEdge( " V2 " , " V4 " );
a.AddEdge( " V2 " , " V5 " );
a.AddEdge( " V3 " , " V6 " );
a.AddEdge( " V3 " , " V7 " );
a.AddEdge( " V4 " , " V8 " );
a.AddEdge( " V5 " , " V8 " );
a.AddEdge( " V6 " , " V8 " );
a.AddEdge( " V7 " , " V8 " );
a.BFSTraverse(); // 广度优先搜索遍历
}
}
运行结果:
V1 V2 V3 V4 V5 V6 V7 V8
运行结果请参照图8.16进行分析。
8.3.3 非连通图的遍历
以上讨论的图的两种遍历方法都是相对于无向连通图的,它们都是从一个顶点出发就能访问到图中的所有顶点。若无向图是非连通图,则只能访问到初始点所在连通分量中的所有顶点,其他连通分量中的顶点是不可能访问到的(如图8.17所示)。为此需要从其他每个连通分量中选择初始点,分别进行遍历,才能够访问到图中的所有顶点,否则不能访问到所有顶点。为此同样需要再选初始点,继续进行遍历,直到图中的所有顶点都被访问过为止。
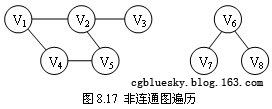
上例的代码只需对DFSTraverse()方法和BFSTraverse()方法稍作修改,便可以遍历非连通图。
{
InitVisited(); // 将visited标志全部置为false
foreach (Vertex < T > v in items)
{
if ( ! v.visited) // 如果未被访问
{
DFS(v); // 深度优先遍历
}
}
}
public void BFSTraverse() // 广度优先遍历
{
InitVisited(); // 将visited标志全部置为false
foreach (Vertex < T > v in items)
{
if ( ! v.visited) // 如果未被访问
{
BFS(v); // 广度优先遍历
}
}
}