Java数据结构与算法 day08 树结构实际应用(一)
文章目录
- 第10章 树结构实际应用
- 堆排序
- 大顶堆和小顶堆图解说明
- 堆排序的思路图解与实现
- 赫夫曼树
- 赫夫曼树的基本介绍
- 赫夫曼树创建步骤图解与实现
第10章 树结构实际应用
本章源码:https://github.com/name365/Java-Data-structure
堆排序
大顶堆和小顶堆图解说明
堆排序基本介绍
1.堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。 2.堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆, 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系。 3.每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆 4.大顶堆举例说明

对堆中的结点按层进行编号,映射到数组中就是下面这个样子:

大顶堆特点:arr[i] >= arr[2*i+1] && arr[i] >= arr[2*i+2] // i 对应第几个节点,i从0开始编号7
- 小顶堆举例说明

小顶堆:arr[i] <= arr[2*i+1] && arr[i] <= arr[2*i+2] // i 对应第几个节点,i从0开始编号
综上:一般升序采用大顶堆,降序采用小顶堆
堆排序的思路图解与实现
堆排序基本思想
1.将待排序序列构造成一个大顶堆
2.此时,整个序列的最大值就是堆顶的根节点。
3.将其与末尾元素进行交换,此时末尾就为最大值。
4.然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
可以看到在构建大顶堆的过程中,元素的个数逐渐减少,最后就得到一个有序序列了.
要求:给你一个数组 {4,6,8,5,9} , 要求使用堆排序法,将数组升序排序。
堆排序步骤图解说明:
步骤一:构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。原始的数组[4,6,8,5,9]
- 假设给定无序序列结构如下 :
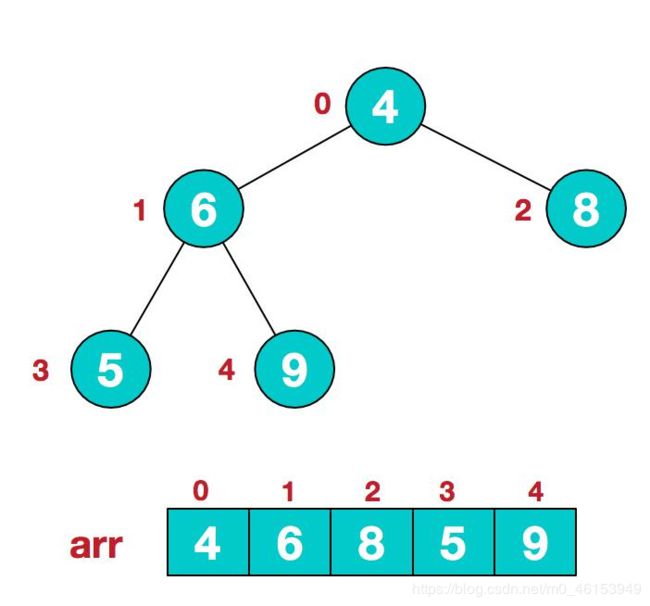
- 此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
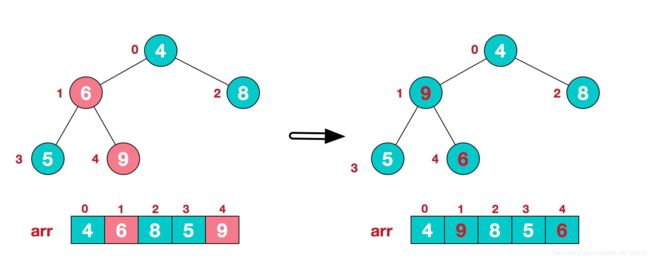
- 找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。

- 这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。

- 此时,就将一个无序序列构造成了一个大顶堆。
步骤二:将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
- 将堆顶元素9和末尾元素4进行交换 。

- 重新调整结构,使其继续满足堆定义。

- 再将堆顶元素 8 与末尾元素 5 进行交换,得到第二大元素 8。

- 后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序。
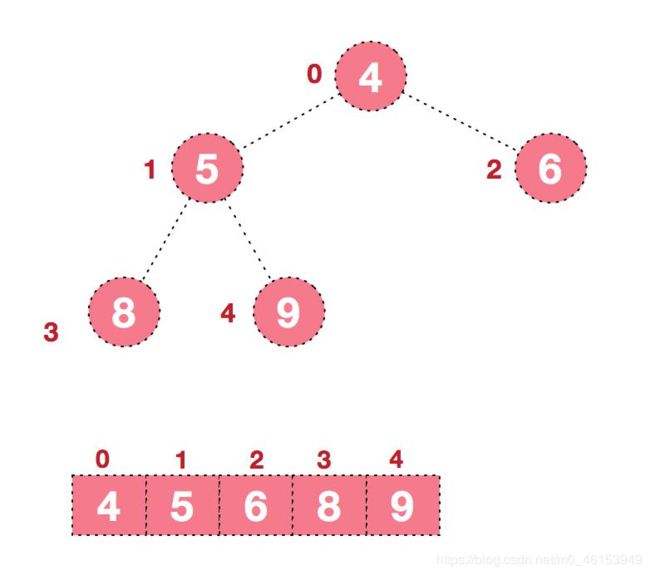
对上述思路进行总结:
1.将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
2.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
3.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤, 直到整个序列有序。
核心代码说明:
public static void adHeap(int arr[],int i,int length){
int temp = arr[i]; //先取出当前元素的值,保存在临时变量
//说明:
//1. j = i * 2 + 1 j 是 i结点的左子结点
for(int j = i * 2 + 1;j < length;j = j * 2 + 1){
if(j+1 < length && arr[j] < arr[j+1]){ //说明左子节点的值小于右子节点的值
j++; //j指向右子节点
}
if(arr[j] > temp){ //如果子节点大于父结点
arr[i] = arr[j]; //将较大的值赋给当前节点
i = j; //让i指向j,继续循环
}else{
break;
}
//当for 循环结束后,已经将以 i 为父结点的树的最大值,放在了最顶(局部)
arr[i] = temp; //将temp值放到调整后的位置
}
}
初始情况:
arr = {4,6,8,5,9}
当 i = 1 时:

首先,当temp=arr[i] ==> temp=6;进入for循环,j=i*2+1 ==> j=3,
进入if判断,执行j++,即j指向右子节点,j=4;
arr[j] ==> arr[4] 即: arr[j]为9,
此时,arr[j] > temp ==> 9 > 6,进入判断

此时,子节点大于父节点,
而此时 i=1,j=4,即arr[i]=arr[j]进行赋值,arr[i] = arr[j] ==> arr[1]=9,将6替换成9。
i=j ==> i=4 ,继续让i指向j,因为节点可能下面还有节点,继续执行循环.

但此时 j=4 ,经过循环赋值语句,j=9,temp=6,不符合判断条件,直接执行 arr[i] = temp ==> arr[4]=6;
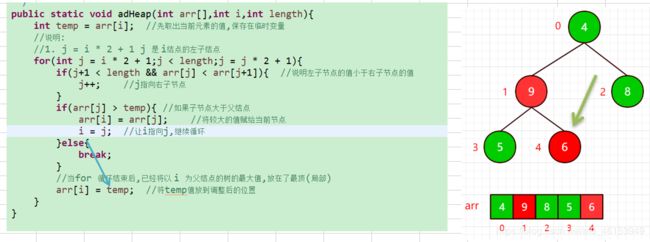
上述过程代码化实现:
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
//要求:将数组进行升序排序
int arr[] = {4,6,8,5,9};
headSort(arr);
}
//编写一个堆排序的方法
public static void headSort(int arr[]){
System.out.println("堆排序:");
//分布完成
adHeap(arr,1,arr.length);
System.out.println("第一次:" + Arrays.toString(arr)); //4,9,8,5,6
adHeap(arr,0,arr.length);
System.out.println("第二次:" + Arrays.toString(arr)); //9,6,8,5,4
}
//将一个数组(二叉树),调整成一个大顶堆
/**
* 功能: 完成 将 以 i 对应的非叶子结点的树调整成大顶堆
* 举例: int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adHeap => 得到 {4, 9, 8, 5, 6}
* 如果我们再次调用 adHeap 传入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5,4}
* @Description
* @author subei
* @date 2020年6月8日上午10:29:31
* @param arr 待调整的数组
* @param i 非叶子结点的索引
* @param length 表示对多少个元素进行调整
*/
public static void adHeap(int arr[],int i,int length){
int temp = arr[i]; //先取出当前元素的值,保存在临时变量
//说明:
//1. j = i * 2 + 1 j 是 i结点的左子结点
for(int j = i * 2 + 1;j < length;j = j * 2 + 1){
if(j+1 < length && arr[j] < arr[j+1]){ //说明左子节点的值小于右子节点的值
j++; //j指向右子节点
}
if(arr[j] > temp){ //如果子节点大于父结点
arr[i] = arr[j]; //将较大的值赋给当前节点
i = j; //让i指向j,继续循环
}else{
break;
}
//当for 循环结束后,已经将以 i 为父结点的树的最大值,放在了最顶(局部)
arr[i] = temp; //将temp值放到调整后的位置
}
}
}
最终完整代码实现如下:
import java.util.Arrays;
public class HeapSort2 {
public static void main(String[] args) {
//要求:将数组进行升序排序
int arr[] = {4,6,8,5,9};
headSort(arr);
}
//编写一个堆排序的方法
public static void headSort(int arr[]){
System.out.println("堆排序:");
int temp = 0;
//完成我们最终代码
//1.将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆
for(int i=arr.length / 2 - 1;i >= 0;i--){
adHeap(arr,i,arr.length);
}
System.out.println("步骤一的数组排序结果=" + Arrays.toString(arr));
//2.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
//3.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
for(int j=arr.length - 1;j >0 ;j--){
//交换
temp=arr[j];
arr[j]=arr[0];
arr[0]=temp;
adHeap(arr, 0, j);
}
System.out.println("最后的数组排序结果=" + Arrays.toString(arr));
}
//将一个数组(二叉树),调整成一个大顶堆
/**
* 功能: 完成 将 以 i 对应的非叶子结点的树调整成大顶堆
* 举例: int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adHeap => 得到 {4, 9, 8, 5, 6}
* 如果我们再次调用 adHeap 传入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5,4}
* @Description
* @author subei
* @date 2020年6月8日上午10:29:31
* @param arr 待调整的数组
* @param i 非叶子结点的索引
* @param length 表示对多少个元素进行调整
*/
public static void adHeap(int arr[],int i,int length){
int temp = arr[i]; //先取出当前元素的值,保存在临时变量
//说明:
//1. j = i * 2 + 1 j 是 i结点的左子结点
for(int j = i * 2 + 1;j < length;j = j * 2 + 1){
if(j+1 < length && arr[j] < arr[j+1]){ //说明左子节点的值小于右子节点的值
j++; //j指向右子节点
}
if(arr[j] > temp){ //如果子节点大于父结点
arr[i] = arr[j]; //将较大的值赋给当前节点
i = j; //让i指向j,继续循环
}else{
break;
}
//当for 循环结束后,已经将以 i 为父结点的树的最大值,放在了最顶(局部)
arr[i] = temp; //将temp值放到调整后的位置
}
}
}
对上述堆排序进行速度测试:
import java.text.SimpleDateFormat;
import java.util.Date;
public class HeapSort2 {
public static void main(String[] args) {
//要求:将数组进行升序排序
//创建要给80000个的随机的数组
int[] arr = new int[8000000];
for (int i = 0; i < 8000000; i++) {
arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数
}
System.out.println("排序前");
Date data1 = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date1Str = simpleDateFormat.format(data1);
System.out.println("排序前的时间是=" + date1Str);
headSort(arr);
Date data2 = new Date();
String date2Str = simpleDateFormat.format(data2);
System.out.println("排序后的时间是=" + date2Str);
}
//编写一个堆排序的方法
public static void headSort(int arr[]){
System.out.println("堆排序:");
int temp = 0;
//完成我们最终代码
//1.将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆
for(int i=arr.length / 2 - 1;i >= 0;i--){
adHeap(arr,i,arr.length);
}
//2.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
//3.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
for(int j=arr.length - 1;j >0 ;j--){
//交换
temp=arr[j];
arr[j]=arr[0];
arr[0]=temp;
adHeap(arr, 0, j);
}
}
//将一个数组(二叉树),调整成一个大顶堆
/**
* 功能: 完成 将 以 i 对应的非叶子结点的树调整成大顶堆
* 举例: int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adHeap => 得到 {4, 9, 8, 5, 6}
* 如果我们再次调用 adHeap 传入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5,4}
* @Description
* @author subei
* @date 2020年6月8日上午10:29:31
* @param arr 待调整的数组
* @param i 非叶子结点的索引
* @param length 表示对多少个元素进行调整
*/
public static void adHeap(int arr[],int i,int length){
int temp = arr[i]; //先取出当前元素的值,保存在临时变量
//说明:
//1. j = i * 2 + 1 j 是 i结点的左子结点
for(int j = i * 2 + 1;j < length;j = j * 2 + 1){
if(j+1 < length && arr[j] < arr[j+1]){ //说明左子节点的值小于右子节点的值
j++; //j指向右子节点
}
if(arr[j] > temp){ //如果子节点大于父结点
arr[i] = arr[j]; //将较大的值赋给当前节点
i = j; //让i指向j,继续循环
}else{
break;
}
//当for 循环结束后,已经将以 i 为父结点的树的最大值,放在了最顶(局部)
arr[i] = temp; //将temp值放到调整后的位置
}
}
}
赫夫曼树
赫夫曼树的基本介绍
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree), 还有的书翻译为霍夫曼树。 赫夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
赫夫曼树几个重要概念和举例:
1.路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1
2.结点的权及带权路径长度:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
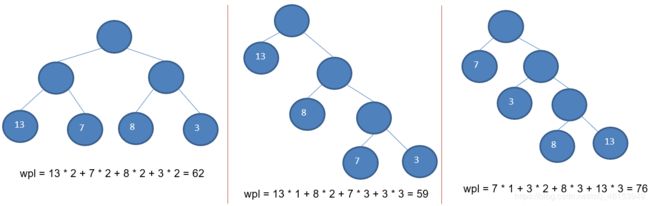
3.树的带权路径长度:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL(weighted path length) ,权值越大的结点离根结点越近的二叉树才是最优二叉树。
4.WPL最小的就是赫夫曼树
赫夫曼树创建步骤图解与实现
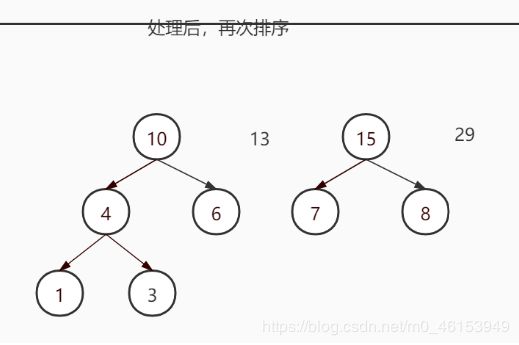
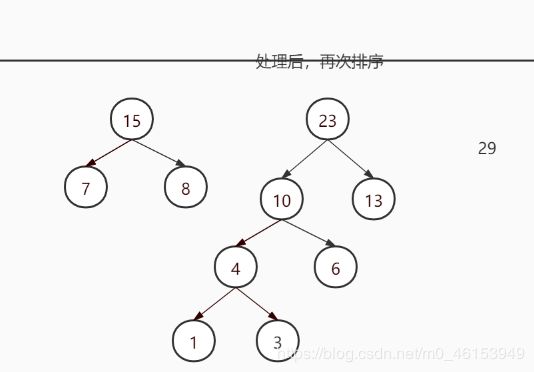
要求:给你一个数列 {13, 7, 8, 3, 29, 6, 1},要求转成一颗赫夫曼树.
构成赫夫曼树的步骤:
从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树
取出根节点权值最小的两颗二叉树
组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和

- 再将这颗新的二叉树,以根节点的权值大小 再次排序, 不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树


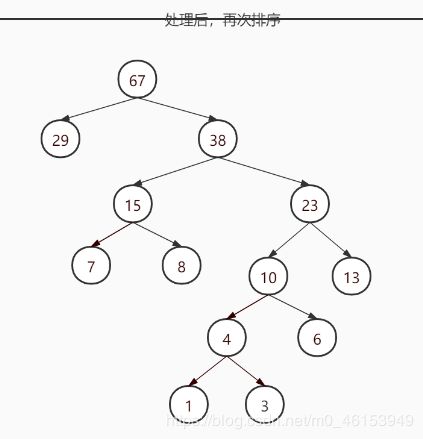
赫夫曼树创建代码实现
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class HuffTreeTest {
public static void main(String[] args) {
int arr[] = { 13, 7, 8, 3, 29, 6, 1 };
Node root = creatHFTree(arr);
preOrder(root);
}
// 前序遍历方法
public static void preOrder(Node root) {
if (root != null) {
root.preOrder();
} else {
System.out.println("这是一个空树。无法遍历");
}
}
// 创建赫夫曼树的方法
public static Node creatHFTree(int[] arr) {
// 第一步,为了操作方法
// 1.遍历 arr 数组
// 2.将arr的每个元素构成一个Node
// 3.将Node 放入到ArrayList中
List<Node> nodes = new ArrayList<Node>();
for (int value : arr) {
nodes.add(new Node(value));
}
// int count = 0; //统计处理次数
// 处理的过程是循环的过程
while (nodes.size() > 1) {
// 排序:从小到大排序
Collections.sort(nodes);
// System.out.println("第" + count + "次排序后的结果:nodes = " + nodes);
// 取出根节点权值最小的两颗二叉树
// (1)取出权值最小的结点(二叉树)
Node leftNode = nodes.get(0);
// (1)取出权值另一个最小的结点(二叉树)
Node rightNode = nodes.get(1);
// (3)构建一个新的二叉树
Node parents = new Node(leftNode.value + rightNode.value);
parents.left = leftNode;
parents.right = rightNode;
// (4)从ArrayList删除处理过的二叉树
nodes.remove(leftNode);
nodes.remove(rightNode);
// (5)将parent加入到nodes
nodes.add(parents);
// count++;
// System.out.println("第" + count + "次处理后的结果:" + nodes);
}
// 返回赫夫曼树的root结点
return nodes.get(0);
}
}
// 创建结点类
// 为了让Node 对象持续排序Collections集合排序
// 让Node 实现Comparable接口
class Node implements Comparable<Node> {
int value; // 结点权值
Node left; // 指向左子结点
Node right; // 指向右子结点
public Node(int value) {
this.value = value;
}
@Override
public String toString() {
return "Node [value=" + value + "]";
}
@Override
public int compareTo(Node o) {
// 表示从小到大排序
return this.value - o.value;
}
// 前序遍历
public void preOrder() {
// 当前结点
System.out.println(this);
// 左子结点
if (this.left != null) {
this.left.preOrder();
}
// 右子结点
if (this.right != null) {
this.right.preOrder();
}
}
}