【GNN】WL-test:GNN 的性能上界
今天学习斯坦福大学同学 2019 年的工作《HOW POWERFUL ARE GRAPH NEURAL NETWORKS?》,这也是 Jure Leskovec 的另一大作。
我们知道 GNN 目前主流的做法都是通过迭代地对邻居进行聚合(aggreating)和转换(transforming)来更新节点的表示向量。而在这篇文章中,本文作者提出了一个可以用于分析 GNN 能力的理论框架,通过对目前比较流行的 GNN 变体(如 GCN、GraphSAGE 等)进行分析,其结果表明目前的 GNN 变体甚至无法区分某些简单的图结构。
本文作者设计了一个简单的架构 GIN(Graph Isomorphism Network),并证明该架构在目前所有 GNN 算法中最具表达能力,并且具有与 Weisfeiler-Lehman 图同构测试一样强大的功能。
读完这段介绍大家可能会有多疑问,包括但不限于:
- 为什么 GCN、GraphSAGEE 无法区分简单的图结构?
- 分析 GNN 捕获图结构的能力的理论框架是什么?
- Weisfeiler-Lehman 图同构测试是什么?
- 为什么提出的 GIN 要与 Weisfeiler-Lehman 图同构测试进行比较?
接下来,我们带着问题来阅读本篇文章。
1.Introduction
GNN 的许多变体都采用了不同的邻域聚合图级别的池化方案,虽然这些变体在节点分类、连接预测和图分类等任务中取得了 SOTA,但是这些 GNN 的设计主要是基于经验而谈,并没有很好的理论基础来分析 GNN 的性质和局限性。
于是,作者提出了一个理论框架用于分析 GNN 及相关变体的表达能力和区分不同图结构的表现力。该框架的灵感来源于 Weifeiler-Lehman 图同构测试(以下简称 WL-test),WL-test 非常强大,其可用于区分各种图结构。与 GNN 类似,WL-test 可以通过聚合邻居节点的特征向量来迭代给定的特征向量,但目前的 GNN 的表达能力都不如 WL-test。WL-test 之所以那么强主要原因在于单射聚合更新(injective aggregation update),所以如果要想获得与 WL-test 一样强的表现力,首先考虑对 GNN 的聚合方案对单射函数进行建模。
本文有以下贡献:
- 证明出 WL-test 是 GNN 的表达能力上限;
- 提出了一个可以用于分析 GNN 能力的理论框架;
- 设计了聚合函数和读出函数,使得 GNN 可与 WL-test 一样强大;
- 构建了一个与 WL-test 一样强大的架构——GIN;
2.Weisfeiler-Lehamn
为了让大家无痛学习,我们先写介绍一下 WL-test。
2.1 Graph Isomorphism
先来介绍下什么是同构图。
简单来说,如果图 G 1 G_1 G1 和 G 2 G_2 G2 的顶点和边数量相同,且边的连接性相同,则可以称这两个图为同构的。也可以认为, G 1 G_1 G1 的点是由 G 2 G_2 G2 中的点映射得到。
举一个简单例子,判断下面两个图是否是同构的:

其实上面两张图是同构的,映射关系为: A − 3 ; B − 1 ; C − 2 ; D − 5 ; E − 4 A-3; B-1; C-2; D-5; E-4 A−3;B−1;C−2;D−5;E−4。
这个还算比较简单,但是如果节点和边的数量都增加了,可能就没法一眼看出,更别说真实社交网络中几百万节点,几千条万条边的情况了。
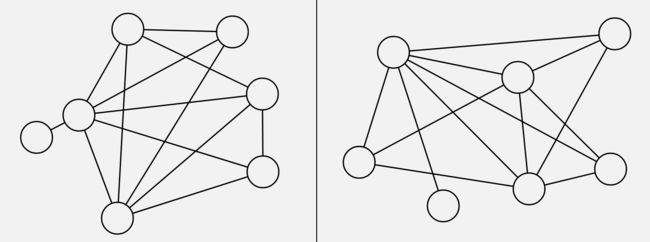
简单介绍下为什么要计算图同构:我们在分析社会网络、蛋白质、基因网络等通常会考虑彼此间的相似度问题,比如说,具有相似结构的分子可能具备相似的功能特性,因此度量图的相似度是图学习的一个核心问题。
而图同构问题通常被认为是 NP 问题,目前最有效的算法是 Weisfeiler-Lehman 算法,可以在准多项式时间内进行求解。
2.2 1-dimensional
WL 算法可以是 K-维的,K-维 WL 算法在计算图同构问题时会考虑顶点的 k 元组,如果只考虑顶点的自身特征(如标签、颜色等),那么就是 1-维 WL 算法。
介绍下 1-维 WL 算法,首先给出一个定义:
多重集(Multiset):一组可能重复的元素集合。例如:{1,1,2,3}就是一个多重集合。
Nino 大佬在她的论文 [ 2 ] ^{[2]} [2]中给出了一个很经典很形象的例子(不过要注意,这个例子其实从标签数量就可以判断两个图是非同构图了,这里只是以此举个例子。):
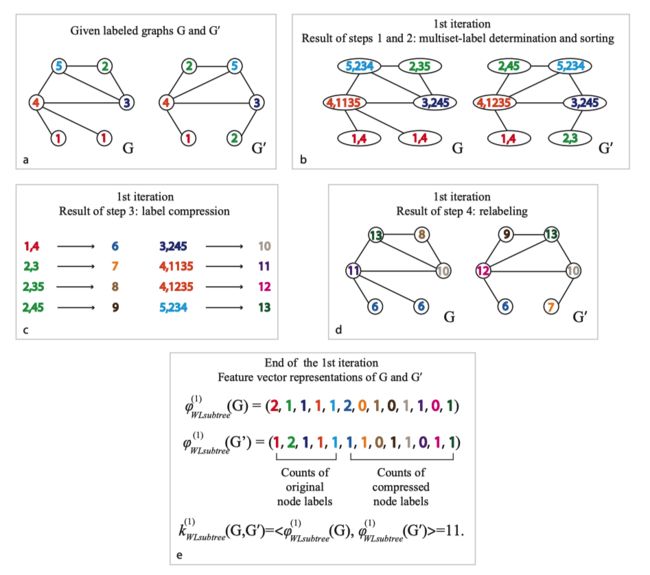
- a:给出两个标签 Label 的图 G , G ′ G,G^{'} G,G′;
- b:考虑节点邻域的标签,并对此排序。(4,1135 表示当前节点标签为 4,其领域节点标签排序后为 1135);
- c:对标签进行压缩映射;
- d:得到新标签;
- e:迭代 1 轮后,利用计数函数分别得到两张图的计数特征,得到图特征向量后便可计算图之间的相似性了。
直观上来看,WL-test 第 k 次迭代时节点的标号表示的是结点高度为 k 的子树结构:
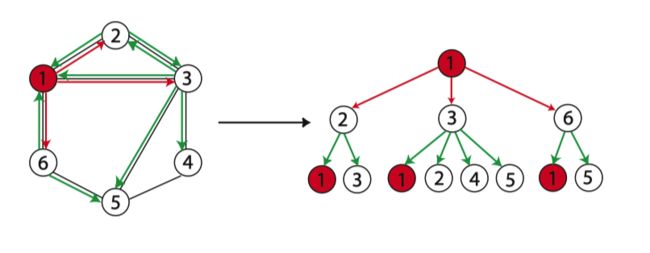
以节点 1 为例,右图是节点 1 迭代两次的子树。因此 WL-test 所考虑的图特征本质上是图中以不同节点为根的子树的计数。
给出伪代码:

分别为:聚合邻居节点标签;多重集排序;标签压缩;更新标签。
公式表示为:
a v k = f ( { h u k − 1 : u ∈ N ( v ) } ) h v k = H a s h ( h v k − 1 , a v k ) a^{k}_v = f(\{h^{k-1}_u : u \in N(v)\}) \\ h^{k}_v = \mathbf{Hash} (h^{k-1}_v, a^{k}_v) \\ avk=f({huk−1:u∈N(v)})hvk=Hash(hvk−1,avk)
看到这大家是不是想到了什么?是不是和 GCN、GraphSAGE 等 GNN 网络的公式差不多?都是分为两步:聚合和结合:
a v k = A G G R E G A T E k ( { h u k − 1 : u ∈ N ( v ) } ) h v k = C O M B I N E k ( h v k − 1 , a v k ) a^{k}_v = \mathbf{AGGREGATE}^{k}(\{h^{k-1}_u: u\in N(v) \}) \\ h^{k}_v = \mathbf{COMBINE}^{k} (h^{k-1}_v, a^{k}_v) \\ avk=AGGREGATEk({huk−1:u∈N(v)})hvk=COMBINEk(hvk−1,avk)
对于 GraphSAGE 来说:
a v k = M A T H ( { R e L U ( W ⋅ h u k − 1 ) : ∀ u ∈ N ( v ) } ) h v k = W ⋅ [ h v k − 1 , a v k ] a^{k}_v = \mathbf{MATH}(\{ \mathbf{ReLU}(W \cdot h^{k-1}_u): \forall u\in N(v) \}) \\ h^{k}_v = W \cdot [h^{k-1}_v, a^{k}_v ] \\ avk=MATH({ReLU(W⋅huk−1):∀u∈N(v)})hvk=W⋅[hvk−1,avk]
对于 GCN 来说:
a v k = M A T H ( { R e L U ( W ⋅ h u k − 1 ) : ∀ u ∈ N ( v ) } ) h v k = R e L U ( W ⋅ M E A N { h v k − 1 , ∀ u ∈ N ( v ) ∪ v } ) a^{k}_v = \mathbf{MATH}(\{ \mathbf{ReLU}(W \cdot h^{k-1}_u): \forall u\in N(v) \}) \\ h^{k}_v =\mathbf{ReLU} ( W \cdot\mathbf{MEAN}\big\{ h^{k-1}_v, \forall u \in N(v)\cup {v} \big\}) \\ avk=MATH({ReLU(W⋅huk−1):∀u∈N(v)})hvk=ReLU(W⋅MEAN{hvk−1,∀u∈N(v)∪v})
GNN 是通过递归更新每个节点的特征向量,从而捕获其周围网络结构和节点的特征,而 WL-test 也类似,那么 GNN 和 WL-test 之间又有什么关系呢?
##2.3 Upper limit of GNN performance
结论也在文章的开头说了,WL-test 是 GNN 的性能上界。我们这里来证明一下。
直观来说,一个好的 GNN 的算法仅仅会在两个节点具有相同子树结构的情况下才会将其映射到同一位置。由于子树结构是通过节点邻域递归定义的,所以我们可以将分析简化为这样一个问题:GNN 是否会映射两个邻域(multiset)到相同的 Representation?一个好的 GNN 永远不会将两个不同领域映射得到相同的 Representation。即,聚合模式必须是单射。因此,我们可以将 GNN 的聚合方案抽象为一类神经网络可以表示的多重集函数,并分析其是否是单射。
引理 1:对任意两个非同构图 G 1 G_1 G1 和 G 2 G_2 G2,如果存在一个图神经网络 $A:\mathcal{G} \rightarrow \mathbf{R}^d $ 将图 G 1 G_1 G1 和 G 2 G_2 G2 映射到不同的 Embedding 向量中,那么通过 WL-test 也可以确定 G 1 G_1 G1 和 G 2 G_2 G2 是非同构图。
其证明方法用的是反证法:假设在迭代 k 此后,图神经网络有可以判断,但 WL 判断。那么在第 0 到 k-1 的迭代过程中, G 1 G_1 G1 和 G 2 G_2 G2 都需要具有相同 Multiset(如果是不同的 Multiset 会得到唯一的新标签)。这也间接说明 G 1 G_1 G1 和 G 2 G_2 G2 的在之前的迭代过程中除了自身节点相同外,邻居节点也相同,而 GNN 的聚合过程中,AGGREGATE 和 COMBINE 函数都是不变的,即对于相同的输入会得到相同的输出,所以会一直保持一种迭代状态: h v i = h v i + 1 h_v^{i}=h_v^{i+1} hvi=hvi+1,GNN 的 READOUT 函数对顺序不敏感,所以最终会得到 G 1 G_1 G1 和 G 2 G_2 G2 两图同构,与条件出现了矛盾。
3.GIN
由引理 1 可知,WL-test 是 GNN 的性能上界,那么是否存在一个与 WL-test 性能相当的 GNN 呢?答案是肯定的。
定理 1:设 GNN 有 A : G → R d A:\mathcal{G}\rightarrow \mathbb{R}^d A:G→Rd ,多于可以通过 WL-test 判断的两个图 G 1 G_1 G1 和 G 2 G_2 G2,在 GNN 层数多的情况下,满足以下情况时,GNN 也可以判断两个图:
a)GNN 的节点聚合和更新函数通过以下公式进行迭代:
h v k = ϕ ( h v k − 1 , f ( { h u k − 1 : u ∈ N ( v ) } ) ) h_v^k = \phi(h_v^{k-1},f(\{h_u^{k-1}:u\in N(v) \})) \\ hvk=ϕ(hvk−1,f({huk−1:u∈N(v)}))
其中,f 作用在 multisets 上, ϕ \phi ϕ 为单射函数。
b)GNN 作用在 multiset 的 READOUT 函数也是单射的。
证明就不证了,感兴趣的可以去看论文附录。
通过定理 1 我们看出 GNN 和 WL-test 的主要区别在于单射函数中。顺利成章的,作者设计一个满足单射函数的图同构网络(Graph Isomorphism Network,以下简称 GIN)。
3.1 AGGREGATE
为了构建出单射的多重集聚合函数,作者提出了一个深度多重集(Deep Multiset),旨在通过神经网络来的对通用的多重集函数进行参数化。
引理 2:设 X \mathcal{X} X 可数,那么会存在一个函数 $f:\mathcal{X}\rightarrow \mathbb{R}^n $ 使得对于任意有限多重集 X ⊂ X X\subset \mathcal{X} X⊂X 都有 $h(X)=\sum_{x\in X}f(x) $。此外,任意一个多重集函数 g 可以被分解为 g ( X ) = ϕ ( ∑ x ∈ X f ( x ) ) g(X)=\phi(\sum_{x\in X }f(x)) g(X)=ϕ(∑x∈Xf(x))。
作者给出的引理 2 指出了求和聚合器实际上也可以表示为多重集上的单射函数。
推论 1:设 X \mathcal{X} X 可数,那么存在一个函数 f : X → R n f:\mathcal{X}\rightarrow \mathbb{R}^n f:X→Rn,对于任意实数 ε \varepsilon ε 和任意有限多重集 c ∈ X , X ∈ X c \in \mathcal{X}, X \in \mathcal{X} c∈X,X∈X 都有 h ( x , X ) = ( w + ε ) ⋅ f ( c ) + ∑ x ∈ X f ( x ) h(x,X)=(w+\varepsilon )\cdot f(c) + \sum_{x\in X}f(x) h(x,X)=(w+ε)⋅f(c)+∑x∈Xf(x) 。此外,任意函数 g 都可分解为 g ( c , X ) = φ ( ( 1 + ε ) ⋅ f ( c ) + ∑ x ∈ X f ( x ) ) g(c,X)=\varphi \Big ((1+\varepsilon) \cdot f(c)+\sum_{x\in X}f(x) \Big ) g(c,X)=φ((1+ε)⋅f(c)+∑x∈Xf(x))。
引入多层感知机来学习函数 f , φ f,\varphi f,φ,便可得到 GIN 最终的基于 SUM+MLP 的聚合函数:
h v k = M L P k ( ( 1 + ε k ) ⋅ h v k − 1 + ∑ u ∈ N ( v ) h u k − 1 ) h_v^k = \mathbf{MLP}^k\Big((1+\varepsilon^k)\cdot h_v^{k-1} + \sum_{u\in N(v)}h_u^{k-1} \Big) \\ hvk=MLPk((1+εk)⋅hvk−1+u∈N(v)∑huk−1)
- MLP 可以近似拟合任何函数;
- 第一次迭代时,如果输入的是 One-hot 编码,在求和前不需要用 MLP,因为 Ont-hot 向量求和后依旧是单射的;
3.2 READOUT
我们知道 READOUT 函数的作用是将图中节点的 Embedding 映射成整张图的 Embedding。于是作者提出了基于 SUM+CONCAT 的 READOUT 函数,对每次迭代得到的所有节点的特征求和得到该轮迭代的图特征,然后再拼接起每一轮迭代的图特征来得到最终的图特征:
h G = C O N C A T ( S U M ( { h v k ∣ v ∈ G } ) ∣ k = 0 , . . , K ) h_G = \mathbf{CONCAT} \Big(\mathbf{SUM}\big(\{ h_v^k | v\in G \} \big) | k=0,..,K \Big) hG=CONCAT(SUM({hvk∣v∈G})∣k=0,..,K)
4.Comparation
这一节我们分析下为什么诸多 GNN 变体没有 GIN 能力强,其实也就是分析下 GNN 变体不满足单射的原因。
4.1 Layer
首先,大部分 GNN 变体的层数都比较少,大部分都只有一层。单层感知机的行为就像是线性映射,此时 GNN 层对退化为简单的对领域特征求和。虽然我们可以证明在有偏执项和足够多的输出维度的情况下,单层感知机是可以完成多重集的单射的,但这种映射无法捕获图结构的相似性。并且对于单层感知机来说,有时会出现数据拟合严重不足的情况,其拟合能力无法与 MLP 相提并论,并且在测试精度上往往比具有 MLP 的 GNN 表现更差。
4.2 Structures
其次,对于 sum 操作来说,mean 和 max 池化操作可能会混淆某些结构,以下图为例:
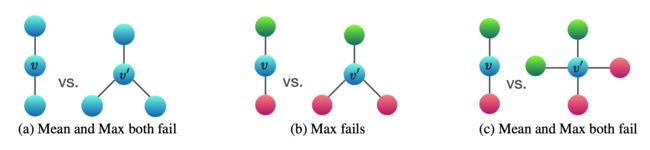
设节点以颜色为标签,即 r g b。
- 对于图 a 来说,max 和 mean 池化操作无法区分其结构,聚合邻居节点后最终标签都为 b,而对于 sum 操作来说 可以得到 2b 和 3b;
- 对于图 b 来说,max 操作无法区分,而 mean 和 sum 可以区分;
- 对于图 c 来说,max 和 mean 都无法区分,而 sum 依然可以区分。
由此可见,max 和 min 并不满足单射性,故其性能会比 sum 差一点。
4.3 Information
那么 sum 、mean 和 max 三者分别可以捕捉到什么信息呢?以下图为例子:
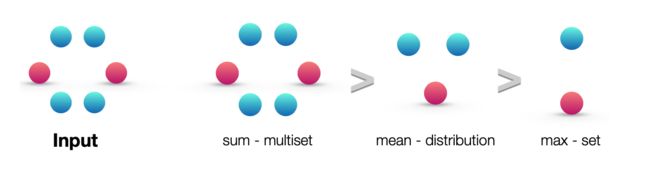
- sum 可以捕捉到全部到所有的标签及其数量,mean 只能学习到标签的相对分布信息(标签比例),max 则偏向于学习具有代表性的信息(标签集合);
- sum 可以学到网络结构信息,而其他不可以。
5.Experiments
简单看一下实验部分。
下图为不同条件 GNN 的拟合能力,可以看到 GIN 的最终结果还是比较接近于 ML 的:

再看一下泛化能力:
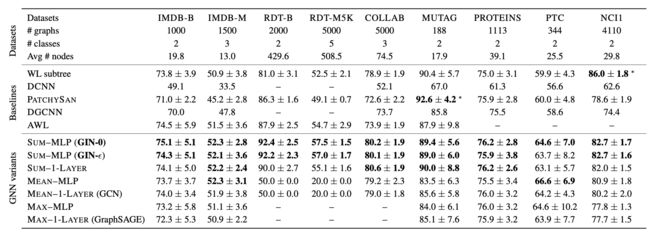
- GIN-0 比 GIN- ε \varepsilon ε 的性能稍微好一点,可能是因为模型简单的缘故;
- GIN 和 SUM-GNN 可以捕捉到图结构,所以效果不错;
6.Conclusion
总结:本文首先证明了 WL-test 是目前所有 GNN 的性能上界,并通过分析目前 GNN 出现的问题提出了构建有效的 GNN 的方法,即使用单射函数,同时也利用 MLP 拟合单射函数设计出一个新的架构模型 GIN,并通过实验证明 GIN 的性能逼近 WL-test。
7.Others
本篇文章只介绍了一维的 WL-test,其他的维度的暂时没有介绍。
在一维 WL-test 中,下面这两张图是非同构的,但是在二维 WL-test 中下面这两图是同构的。
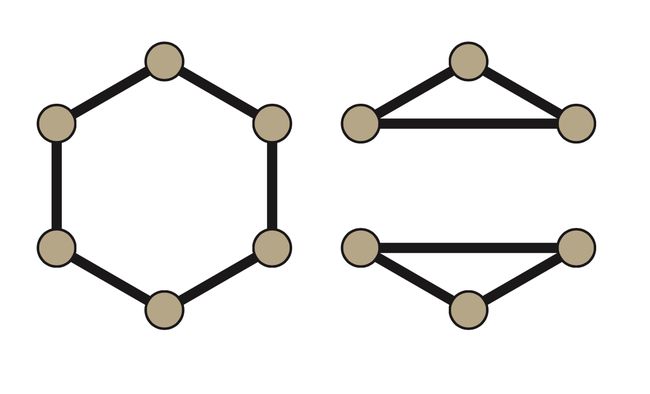
有学者证明出 WL-test 的维度最多为 3 维 [ 4 ] ^{[4]} [4],感兴趣的同学可以自己去探索。
8.Reference
- 《HOW POWERFUL ARE GRAPH NEURAL NETWORKS?》
- 《Weisfeiler-Lehman Graph Kernels》
- 《Combinatorial Properties of the Weisfeiler-Leman Algorithm》
- 《The Weisfeiler-Leman Dimension of Planar Graphs is at most 3》
- 《GIN 图同构网络 ICLR 2019 论文详解》
- 《weihua916/powerful-gnns》
关注公众号跟踪最新内容:阿泽的学习笔记。
