MapReduce学习笔记
笔记代码GitHub:https://github.com/hackeryang/Hadoop-Exercises
一、MapReduce应用
1.在使用IDE开发MapReduce应用时,在maven工程的pom.xml文件中需要加入对hadoop-client的依赖,它包含了和HDFS及MapReduce交互所需要的所有Hadoop client-side类,如下所示:
org.apache.hadoop
hadoop-client
2.6.0-mr1-cdh5.15.0
provided
Hadoop的各种配置文件在安装目录下的/etc/hadoop子目录中。不过实际开发场景中,建议的方案是把/etc/hadoop目录从Hadoop安装目录复制到另一个路径下,将*-site.xml配置文件也放在该位置,再把HADOOP_CONF_DIR环境变量设置为该路径。这样做的优点是,对配置文件的修改可以与Hadoop本身的配置隔离开来。
2.为了简化命令行方式运行作业,Hadoop自带一些辅助类。GenericOptionsParser类用来解释常用的Hadoop命令行选项,并根据需要为Configuration对象设置相应的值,但一般不直接使用这个类,而是实现Tool接口,通过ToolRunner运行应用,因为ToolRunner内部调用了GenericOptionsParser:

下面的代码例子是一个简单的Tool的实现,用来打印Tool的Configuration对象中所有属性的键值对:
package MapReduceApplication;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.util.Map;
public class ConfigurationPrinter extends Configured implements Tool { //打印一个Configuration对象中所有属性的键值对
static{
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
Configuration.addDefaultResource("yarn-default.xml");
Configuration.addDefaultResource("yarn-site.xml");
Configuration.addDefaultResource("mapred-default.xml");
Configuration.addDefaultResource("mapred-site.xml");
}
public int run(String[] strings) throws Exception {
Configuration conf=getConf();
for(Map.Entry entry:conf){
System.out.printf("%s=%s\n",entry.getKey(),entry.getValue());
}
return 0;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new ConfigurationPrinter(),args); //ToolRunner.run()负责在调用ConfigurationPrinter自身的run()之前,为Tool建立一个Configuration对象,ToolRunner还使用了GenericOptionsParser来获取命令行中指定的参数,然后在Configuration实例上进行设置
System.exit(exitCode);
}
} 其中ConfigurationPrinter是Configured的一个子类,Configured是Configurable接口的一个实现。Tool继承于Configurable所以需要实现Configurable的所有实现。run()方法通过Configurable的getConf()方法获取Configuration,然后重复执行,将每个属性打印到标准输出。static的静态代码部分确保核心配置以外的HDFS、YARN和MapReduce配置能被获取。
同时,GenericOptionsParser(用于解析命令行参数)也可以设置个别属性,例如写好上面代码并编译打包后,用下面的命令来设置属性:
hadoop jar /mnt/sda6/ConfigurationPrinter.jar MapReduceApplication.ConfigurationPrinter \
-D color=yellow | grep color-D选项用于将键color的属性设置为yellow,设置为-D的选项优先级高于配置文件里的相同属性,这样的用处是可以把默认属性放入配置文件中,然后在需要时用-D选项来覆盖,例如通过-D mapreduce.job.reduces=n来设置MapReduce作业中reducer的数量,这样会覆盖集群上或客户端配置文件中设置的reducer数量。可以通过上述代码形成的GenericOptionsParser和ToolRunner的命令行参数选项如下所示:

3.可以通过属性名称来判断该属性应该在哪里进行设置,例如yarn.nodemanager.resource.memory.mb用于改变运行作业的节点管理器可得到的内存容量,以yarn.nodemanager开头,可以知道需要在yarn-site.xml中设置。Namenode相关的HDFS属性名称都带dfs.namenode前缀,MapReduce用mapreduce前缀,例如mapreduce.job.name。
4.MRUnit是一个测试库,用于将已知的输入传递给mapper或者检查reducer的输出是否符合预期,测试例子如下所示:
package MapReduceApplication;
import java.io.IOException;
import Temperature.MaxTemperatureMapper;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.*;
public class MaxTemperatureMapperTest { //关于MaxTemperatureMapper的单元测试,传递一个天气记录作为mapper的输入,检查输出是否是读入的年份和气温
@Test
public void processesValidRecord() throws IOException,InterruptedException{
Text value=new Text("0043011990999991950051518004+68750+023550FM-12+0382"+
//Year ^^^^
"99999V0203201N00261220001CN9999999N9-00111+99999999999"); //Temperature ^^^^^
new MapDriver()
.withMapper(new MaxTemperatureMapper()) //指定mapper
.withInput(new LongWritable(0),value) //指定输入的键和值,由于mapper忽略输入key,因此输入key可以设置为任何值
.withOutput(new Text("1950"),new IntWritable(-11)) //期望输出的键值对
.runTest(); //执行测试
}
} 如果mapper没有输出期望的值,则MRUnit测试失败。不过与其在mapper中加入更多关于数据格式可能性的逻辑考虑,不如另外写个解析类来封装解析逻辑,解析类如下:
package MapReduceApplication;
import org.apache.hadoop.io.Text;
public class NcdcRecordParser { //解析NCDC格式的气温纪录,与MaxTemperatureMapper配合的解析类
private static final int MISSING_TEMPERATURE=9999;
private String year;
private int airTemperature;
private String quality;
public void parse(String record){
year=record.substring(15,19);
String airTemperatureString;
//Remove leading plus sign as parseInt doens't like them(pre-Java 7)
if(record.charAt(87)=='+'){
airTemperatureString=record.substring(88,92);
}else{
airTemperatureString=record.substring(87,92);
}
airTemperature=Integer.parseInt(airTemperatureString);
quality=record.substring(92,93);
}
public void parse(Text record){
parse(record.toString());
}
public boolean isValidTemperature(){ //通过温度数值是否丢失以及质量码是否匹配来确定温度数据是否有效
return airTemperature!=MISSING_TEMPERATURE && quality.matches("[01459]");
}
public String getYear(){
return year;
}
public int getAirTemperature(){
return airTemperature;
}
}
创建解析类的另一个好处是,mapper不需要因为数据格式的多种可能性而重写代码逻辑,单元测试可以直接针对解析类进行编写。由于有了解析类,mapper类本身被大大简化,如下所示:
package MapReduceApplication;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MaxTemperatureMapper extends Mapper { //与解析类NcdcRecordParser配合的mapper类
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //输入是一个键值对,Context实例用于输出内容的写入
parser.parse(value); //利用解析类中的方法解析温度数据
if(parser.isValidTemperature()){
context.write(new Text(parser.getYear()),new IntWritable(parser.getAirTemperature()));
}
}
} 在写reducer之前,可以用ReduceDriver写一个单元测试,如下所示:
package MapReduceApplication;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
import org.junit.Test;
import java.io.IOException;
import java.util.Arrays;
public class MaxTemperatureReducerTest {
@Test
public void returnsMaximumIntegerInValues() throws IOException,InterruptedException{
new ReduceDriver()
.withReducer(new MaxTemperatureReducer()) //指定reducer
.withInput(new Text("1950"),Arrays.asList(new IntWritable(10),new IntWritable(5))) //指定输入的键和值
.withOutput(new Text("1950"),new IntWritable(10)) //期望输出的键值对
.runTest(); //执行测试
}
} 接下来可以写用于输出最高温度值的reduer,如下所示:
package MapReduceApplication;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MaxTemperatureReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { //构建IntWritable的迭代器来找到最大值
int maxValue=Integer.MIN_VALUE;
for(IntWritable value:values){
maxValue=Math.max(maxValue,value.get());
}
context.write(key,new IntWritable(maxValue));
}
}
有了mapper和reducer,下一步是写一个作业驱动程序(job driver)用于运行MapReduce任务,如下所示:
package MapReduceApplication;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MaxTemperatureDriver extends Configured implements Tool {
public int run(String[] args) throws Exception {
if(args.length!=2){
System.err.printf("Usage: %s [generic options] 除了灵活的配置选项可以使应用程序实现Tool,还可以插入任意Configuration来增加可测试性。可以利用这点来编写测试程序,第一种方法是使用本地作业运行器,如下所示:
package MapReduceApplication;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import static org.hamcrest.CoreMatchers.is;
import static org.hamcrest.MatcherAssert.assertThat;
public class MaxTemperatureDriverTest { //测试作业驱动程序的输出是否满足预期
@Test
public void test() throws Exception{
Configuration conf=new Configuration(); //根据编辑好的xml配置文件创建Configuration实例
conf.set("fs.defaultFS","file:///"); //设置文件系统为本地文件系统
conf.set("mapreduce.framework.name","local"); //设置为使用本地作业运行器
conf.setInt("mapreduce.task.io.sort.mb",1); //设置mapreduce中间输出使用环形缓冲区缓存在本地内存的大小,默认为100M
Path input=new Path("/mnt/sda6/NCDC.txt");
Path output=new Path("/mnt/sda6/output");
FileSystem fs= FileSystem.getLocal(conf); //通过给定的配置权限确定要使用的本地文件系统
fs.delete(output,true); //删除上一次运行后的旧输出文件夹以免报错
MaxTemperatureDriver driver=new MaxTemperatureDriver();
driver.setConf(conf);
int exitCode=driver.run(new String[]{
input.toString(),output.toString()
});
assertThat(exitCode,is(0));
//checkOutput(conf,output); //逐行对比实际输出与预期输出
}
}
测试驱动程序的第二种方法是使用一个mini集群来运行它。Hadoop有一组测试类,名为MiniDFSCluster、MiniMRCluster和MiniYARNCluster,它以程序方式创建正在运行的集群。不同于本地作业运行器,它们允许在整个HDFS、MapReduce和YARN机器上运行调试。注意,mini集群上的节点管理器启动不同的JVM来运行任务,这会使调试更困难。也可以从命令行运行一个mini集群,如下所示:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-*-tests.jar minicluster5.本地作业运行器使用单JVM运行一个作业,在分布式环境中,作业的类必须打包为一个JAR文件并发送给集群。Hadoop通过setJarByClass()方法中设置的类来搜索类路径并自动找到该JAR文件。在maven项目中可以通过如下命令跳过测试阶段直接生成JAR文件:
mvn package -DskipTests启动任务的主类中一般最后一行会有waitForCompletion()方法,用于启动作业并检查进展情况,如果有任何变化,就输出一行map和reduce进度总结。输出包含很多有用的信息,在作业开始之前,打印作业ID。Hadoop2开始,MapReduce作业ID由YARN资源管理器创建的YARN应用ID生成,一个应用ID格式包含两部分:资源管理器(不是应用)开始时间和唯一标识此应用的由资源管理器维护的增量计数器。例如ID为application_1410450250506_0003的应用是资源管理器运行的第3个应用(0003,应用ID从1开始计数),时间戳1410450250506表示资源管理器开始时间。计数器的数字前面由0开始(如0003),以便于ID在目录列表中排序,但当计数器达到10000时,不能重新设置,会导致ID更长,这些ID就不能很好排序了。
将应用ID的application前缀换为job前缀就可以得到相应的作业ID,如job_1410450250506_0003。任务属于作业,任务ID是这样形成的:将作业ID的job前缀替换为task前缀,然后加上一个后缀表示是作业里的哪个任务,例如task_1410450250506_0003_m_000003表示ID为job_1410450250506_0003的作业的第4个map任务(000003,任务ID从0开始计数)。作业的任务ID在作业初始化时产生,因此任务ID的顺序不一定是任务执行的顺序。
任务有可能执行多次,所以为了标识相同任务执行的不同实例,任务尝试(task attempt)都会被指定一个唯一的ID,例如attempt_1410450250506_0003_m_000003_0表示正在运行的task_1410450250506_0003_m_000003任务的第一个尝试(0,任务尝试ID从0开始计数)。任务尝试在作业运行时根据需要分配,因此它们的顺序代表被创建运行的先后顺序。
application、job、task和task attempt的区别:对YARN来说,每次提交的一个程序为一个application,如果运行的是MapReduce程序,那么会被称作job,即如果MapReduce在YARN上运行程序,此时job与application是一个东西,所以MapReduce的Job id与Application id相同。MapReduce job根据涉及的mapper和reducer数量划分为多个task,task是离线计算的最小单位,一般一个128M的HDFS块被分为一个task,如果某个task失败,该task会在另一个节点上重新运行,变成task attempt。
6.Hadoop的Web界面用来浏览作业信息,对于跟踪任务运行进度、查找作业完成后的统计信息和日志很有帮助,默认在http://localhost:8088,如下所示:
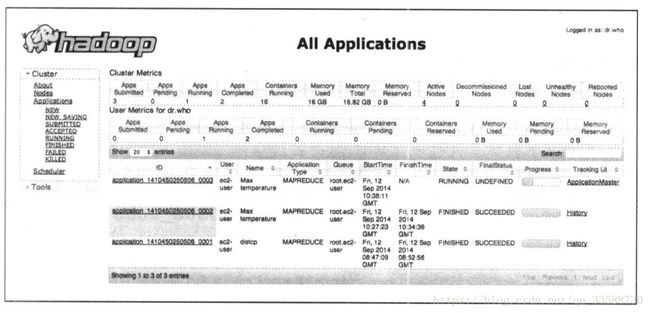
其中”Cluster Metrics”部分写出了集群的概要信息,包括当前集群上处于运行及其他不同状态应用的数量,集群上可用的资源数量(Memory Total)及节点管理器的相关信息。下侧的主表中列出了集群上所有曾经运行和正在运行的应用,资源管理器在同一时刻能够在内存中保存近10000个已完成的应用(通过设置yarn.resourcemanager.max-completed-applications),随后只能通过作业历史页面获取这些应用信息,作业历史是永久存储的。
作业历史指已完成的MapReduce作业的事件和配置信息,历史文件由MapReduce的application master存放在HDFS中,通过mapreduce.jobhistory.done-dir属性来设置存放目录。作业的历史文件会保存一周,随后被系统删除。历史日志包括作业、任务和尝试事件,所有这些信息以JSON格式存放在文件中。
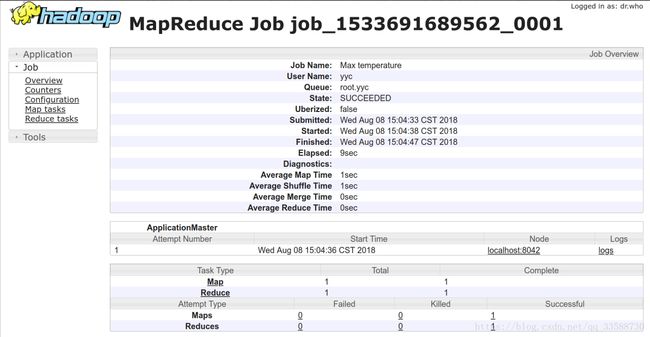
点击主表中最后一列“Tracking UI”里的链接“application master”进入正在运行作业的页面或者点击“History”链接进入已完成作业的历史页面,如下所示:

作业运行期间可以在这样的作业页面监控作业进度。底部的表表示map和reduce进度,“Total”显示该作业map和reduce的总数。其他列显示的是这些任务的状态:Pending为等待运行,Running为运行中,Complete为成功完成。表下侧的部分显示的是MapReduce任务中失败(Failed)和被终止(Killed)任务尝试的总数。左侧的导航栏“Job”菜单下的“Configuration”链接指向作业的统一配置文件,该文件包含了作业运行过程中生效的所有属性。
7.作业完成后,每个reducer都会产生一个输出文件,在输出目录下会有各个reducer生成的部分输出,命名为part-00000到part-000XX。这样的输出结果还可以作为另一个MapReduce作业的输入。可以使用hadoop fs命令的-getmerge选项来从指定目录下获取所有文件,并将它们合并到本地文件系统上的一个文件中:
hadoop fs -getmerge /output /mnt/sda6/result因为reduce的输出分区是无序的(使用了哈希分区函数),所以一般都需要对输出结果进行排序或R等后期处理操作:
sort /mnt/sda6/result | tail如果输出文件很小,另一种获取输出的方式是使用-cat选项将输出文件打印到控制台:
hadoop fs -cat /output/*8.在发现reduce输出的结果文件中部分数据异常的问题后,在调试一个作业的时候,应当第一反应想到是否可以使用计数器来获得需要找出事件发生来源的相关信息,如果需要使用日志或状态信息,计数器衡量出的问题严重程度也有帮助。将调试代码加入到mapper类的例子如下所示,没有放在reducer上是因为希望找到导致这些异常输出的数据源输入:
package MapReduceApplication;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MaxTemperatureMapper extends Mapper { //与解析类NcdcRecordParser配合的mapper类
enum Temperature{
OVER_100
}
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //输入是一个键值对,Context实例用于输出内容的写入
parser.parse(value); //利用解析类中的方法解析温度数据
if(parser.isValidTemperature()){
int airTemperature=parser.getAirTemperature();
if(airTemperature>1000){ //如果气温超过100,这里写1000是因为NCDC的温度数据格式中保留了小数点后一位
System.err.println("Temperature over 100 degrees for input: "+value); //输出一行到标准错误流以代表有问题的行
context.setStatus("Detected possibly corrupt record: see logs."); //更新map的状态信息,引导使用者查看日志
context.getCounter(Temperature.OVER_100).increment(1); //用enum类型的字段作为计数器统计气温超过100℃的记录数
}
context.write(new Text(parser.getYear()),new IntWritable(parser.getAirTemperature()));
}
}
}
重新编译并打包JAR包,在HDFS中用hadoop fs -mkdir命令创建/input目录并把NCDC数据通过hadoop fs -put命令放进去,如下所示:
hadoop fs -mkdir /input
hadoop fs -put /mnt/sda6/NCDC.txt /input然后,使用如下命令运行编写的MapReduce程序:
hadoop jar /mnt/sda6/MaxTemperatureMapper.jar \
MapReduceApplication.MaxTemperatureDriver /input /output
运行时或者运行完成后都可以通过http://localhost:8088查看应用和作业进度信息,如下所示:
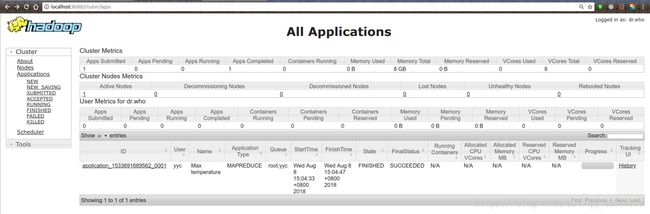
点击下侧应用记录表中最右侧“Tracking UI”一列中的“History”或“ApplicationMaster”链接,可以进入对应应用的详细追踪信息,如下所示:
在上图的作业页面中包含了一些查看作业中任务细节的链接,例如点击左侧导航栏的“Map tasks”链接,将进入一个列举了所有map任务信息的页面,由于上面的代码带有调试语句,运行时在任务的“Status”列中会显示调试信息,如下所示(自己跑的任务不够多就用书上的图):

表格中每个任务都有对应的链接,点击之后会进入任务尝试页面,该页面显示了当前任务的每个任务尝试,每个任务尝试页面都有链接指向日志文件和计数器,点击“Logs”列中某个任务尝试的“logs”链接,可以发现所记录的日志记录。如果点开“logs”链接显示“Aggregation is not enabled”,或者出现以下报错:
Failed while trying to construct the redirect url to the log server. Log Server url may not be configured
java.lang.Exception: Unknown container. Container either has not started or has already completed or doesn't belong to this node at all.
说明默认设置只能查看正在运行的作业的日志,如果作业已经结束会无法查看日志,为了查看已经结束的作业的日志,需要在yarn-site.xml配置文件中添加如下内容:
yarn.log-aggregation-enable
true
开启日志聚集功能,任务执行完之后,将日志文件自动上传到文件系统(如HDFS文件系统),否则通过namenode1:8088页面查看日志文件的时候,会报错
"Aggregation is not enabled. Try the nodemanager at namenode1:54951"
yarn.log-aggregation.retain-seconds
302400
日志文件保存在文件系统(如HDFS文件系统)的最长时间,不设置默认值是-1,即永久有效。这里配置的值是:7天 = 3600 * 24 * 7 = 302400
yarn.log.server.url
http://localhost:19888/jobhistory/logs
修改保存之后,需要在命令行中重启YARN(包括resourcemanager和nodemanager)和历史服务器,如下所示:
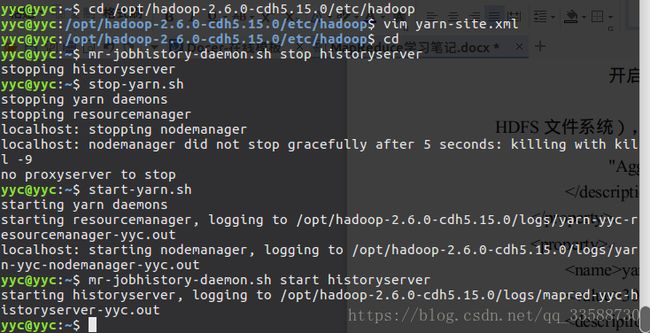
作业完成后,要查看自己定义的计数器的值,检查在整个数据集中有多少记录超过100度,可以通过Web页面或者命令行来查看计数器:
mapred job -counter job_1533691689562_0001 \
'MapReduceApplication.MaxTemperatureMapper$Temperature' OVER_100
其中-counter选项的输入参数包括作业ID、计数器组名(一般为类名)和计数器名称(enum名)。发现异常记录后,可以直接扔掉不正确的记录。
在下面的MRUnit测试中,可以检查对不合理的输入,上面定义过的计数器是否进行了更新:
@Test
public void parseMalformedTemperature() throws IOException,InterruptedException{
Text value=new Text("0335999999433181957042302005+37950+139117SAO +0004"+
//Year ^^^^
"RJSN V02011359003150070356999999433201957010100005+353"); //Temperature ^^^^^
Counters counters=new Counters();
new MapDriver()
.withMapper(new MaxTemperatureMapper())
.withInput(new LongWritable(0),value)
.withCounters(counters)
.runTest();
}
在NCDC温度数据中,引发问题的记录与其他行的格式是不同的,下面的改进版Mapper类使用的解析类(需要修改)忽略了那些没有首符号(+或-)气温字段的行,并且加入一个计数器统计因该原因而被忽略的记录数:
package MapReduceApplication;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MaxTemperatureMapper extends Mapper { //与解析类NcdcRecordParser配合的mapper类
enum Temperature{
MALFORMED
}
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //输入是一个键值对,Context实例用于输出内容的写入
parser.parse(value); //利用解析类中的方法解析温度数据
if(parser.isValidTemperature()){
int airTemperature=parser.getAirTemperature();
context.write(new Text(parser.getYear()),new IntWritable(airTemperature));
}else if(parser.isMalformedTemperature()){
System.err.println("Ignoring possibly corrupt input: "+value); //输出一行到标准错误流以代表有问题的行
context.getCounter(Temperature.MALFORMED).increment(1); //用enum类型的字段作为计数器统计忽略的没有首符号气温字段(+或-)的记录数
}
}
}
与mapper类配合的修改过的解析类如下所示:
package MapReduceApplication;
import org.apache.hadoop.io.Text;
public class NcdcRecordParser { //解析NCDC格式的气温纪录,与MaxTemperatureMapper配合的解析类
private static final int MISSING_TEMPERATURE=9999;
private String year;
private int airTemperature;
private String quality;
private boolean airTemperatureMalformed;
public void parse(String record){
year=record.substring(15,19);
airTemperatureMalformed=false;
//Remove leading plus sign as parseInt doens't like them(pre-Java 7)
if(record.charAt(87)=='+'){
airTemperature=Integer.parseInt(record.substring(88,92));
}else if(record.charAt(87)=='-'){
airTemperature=Integer.parseInt(record.substring(87,92));
}else{
airTemperatureMalformed=true;
}
quality=record.substring(92,93);
}
public void parse(Text record){
parse(record.toString());
}
public boolean isValidTemperature(){ //通过温度数值是否丢失以及质量码是否匹配来确定温度数据是否有效
return !airTemperatureMalformed && airTemperature!=MISSING_TEMPERATURE && quality.matches("[01459]");
}
public boolean isMalformedTemperature(){
return airTemperatureMalformed;
}
public String getYear(){
return year;
}
public int getAirTemperature(){
return airTemperature;
}
}
9.针对不同用户,Hadoop在不同的地方生成日志,在Streaming方式下,如果标准输出用于map或reduce,就不会出现在标准输出日志文件中,如下表所示:

YARN有一个日志聚合(log aggregation)服务,可以获得已完成应用的任务日志,并将其放入HDFS中,在那任务日志被存储在一个容器(container)文件中用于存档。如果该服务被启用(正如前面所说,在yarn-site.xml中将yarn.log-aggregation-enable设置为true),可以点击Web界面中的“logs”链接,或者使用mapred job -logs命令查看任务日志。默认情况下日志聚合服务是关闭的,此时依然可以通过访问节点管理器页面http://
用Apache Commons Logging API或其他能写入log4j的日志API可以将日志写入任务的系统日志文件中(syslog),如下所示:
package MapReduceApplication;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LoggingIdentityMapper extends Mapper { //使用Apache Commons Logging API将任务日志写到标准输出
private static final Log LOG= LogFactory.getLog(LoggingIdentityMapper.class);
@Override
@SuppressWarnings("unchecked") //该批注允许选择性地取消特定代码段中的警告,这里抑制了未检查操作的警告,例如使用List,ArrayList等未进行参数化产生的警告
protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
//Log to stdout file
System.out.println("Map key: "+key);
//Log to sysLog file
if(LOG.isDebugEnabled()){
LOG.debug("Map value: "+value);
}
context.write((KEYOUT)key,(VALUEOUT)value);
}
}
为了驱动这个Mapper类,还需要一个有main()函数的驱动主类,如下所示:
package MapReduceApplication;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class LoggingDriver extends Configured implements Tool { //驱动LoggingIdentityMapper类的主类
public int run(String[] args) throws Exception {
if(args.length!=2){
System.err.printf("Usage: %s [generic options] 默认的日志级别是INFO,因此DEBUG级别的消息不在syslog任务日志文件中出现,但需要看到这类消息的时候可以设置mapreduce.map.log.level或者mapreduce.reduce.log.level,例如,对mapper进行如下设置并用命令行运行JAR,输出到HDFS的/output/logging-out目录下(生成part-m-00000文件),以便能看到日志中的map值:
hadoop jar /mnt/sda6/LoggingDriver.jar MapReduceApplication.LoggingDriver \
-conf $HADOOP_HOME/etc/hadoop/mapred-site.xml \
-D mapreduce.map.log.level=DEBUG /input/NCDC.txt /output/logging-out
默认情况下,日志最短在3小时后删除,也可以在yarn-site.xml通过yarn.nodemanager.log.retain-seconds属性来设置删除的秒数。也可以在mapred-site.xml中用mapreduce.task.userlog.limit.kb属性为每个日志文件的最大规模设置一个阈值,默认为0表示无上限。
10.在远程调试时,集群上运行作业很难使用debugger,因为不知道哪个节点处理哪部分输入。可以用以下方法来调试:(1)在本地重现错误。对特定的输入,失败的任务通常总会失败,可以下载使任务失败的输入文件到本地然后在本地运行程序,再用VisualVM等调试。
(2)使用JVM调试选项。失败的常见原因是任务JVM中Java内存溢出。可以将mapred.child.java.opts设为包含-XX:HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=/path。该设置产生一个堆转储(heap dump),可以通过jhat或Eclipse Memory Analyzer等工具排查。
(3)使用任务分析。Java的profiler提供了很多JVM内部细节,Hadoop也提供了分析作业中部分任务的机制。
保存失败的任务尝试的中间结果文件对于以后检查很有用,可以在mapred-site.xml中将mapreduce.task.files.preserver.failedtasks属性设为true来保存失败的任务文件。另一个对调试有用的参数是yarn.nodemanager.delete.debug-delay-sec,是一个应用完成后,nodemanager删除该应用本地文件目录和日志目录的延迟时间,如果设置一个较大的值(600,即十分钟),那么在文件删除前有足够的时间查看。为了检查任务尝试文件,需要登录到任务失败节点并找到该任务尝试的目录,该目录由mapreduce.cluster.local.dir属性决定,一般task attempt的目录在如下位置:
![]()
11.为了尽量让作业运行的快一些,可以检查下表所示的内容:

启用Hadoop的分析功能只需要将属性mapreduce.task.profile属性设置为true即可,如下所示:
hadoop jar /mnt/sda6/LoggingDriver.jar MapReduceApplication.MaxTemperatureDriver \
-conf $HADOOP_HOME/etc/hadoop/mapred-site.xml \
-D mapreduce.task.profile=true \
/input/NCDC.txt /output
默认情况下会使用HPROF,一个JDK自带的分析工具,能提供程序的CPU和堆使用情况等。默认情况只有ID为0、1、2的map和reduce任务会被分析,可以设置mapreduce.task.profile.maps和mapreduce.task.profile.reduces两个属性来指定想要分析的任务ID范围。每个任务的分析输出和任务日志存放在nodemanager日志目录的userlogs子目录下,和syslog,stdout,stderr文件一起(通过http://
12.在实际需求更复杂时,应该考虑增加更多数量的作业,而不是增加作业代码本身的复杂度,对于更复杂的问题可以使用比MapReduce更高级的语言,例如Pig,Hive,Spark等,这样就不用处理到MapReduce作业的转换,而是集中精力分析正在执行的任务。Mapper一般执行输入格式解析、投影(选择相关字段)和过滤(去掉无关记录)。可以使用Hadoop自带的ChainMapper类库将多个mapper连接成一个mapper,结合ChainReducer,可以在一个MapReduce作业中运行一系列mapper,再运行一个reducer和另一个mapper链。
二、MapReduce工作机制
13.在Hadoop运行MapReduce作业时,总共有5个独立的实体运行:(1)客户端,用于提交MapReduce作业。(2)YARN资源管理器,负责协调集群上计算机资源的分配。(3)YARN节点管理器,负责启动和监视集群中机器上的计算容器(container)。(4)MapReduce的application master,负责协调运行MapReduce作业的任务,它和MapReduce任务在容器中运行,这些容器(封装了集群资源如CPU、内存、磁盘等,每个任务只能在Container中运行,并且只使用Container中的资源)由资源管理器分配并由节点管理器来管理。(5)HDFS,用于与其他实体间共享作业文件,五个部分如下图所示:
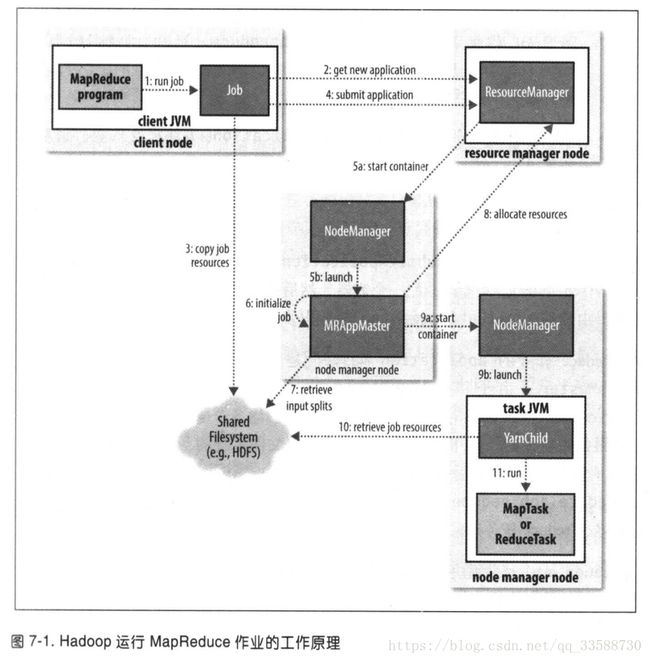
整个MapReduce作业的流程如下:
(1)Job的submit()方法创建一个内部的JobSummiter实例,并且调用submitJobInternal()方法。提交作业后,waitForCompletion()每秒查询作业进度,如果自上次报告后有改变,就把进度报告到控制台。作业完成后,成功会显示作业计数器,失败会将错误记录显示到控制台。
(2)JobSummiter向资源管理器请求(注册)一个新应用ID,用于MapReduce作业ID。并且检查作业的输出说明,例如如果上次任务的同名输出目录已存在,会报错。然后,计算作业的输入分片,如果分片由于输入路径不存在等无法计算,也报错。
(3)JobSummiter将运行作业所需资源(包括JAR,配置文件和计算得到的输入分片)复制到HDFS中一个以作业ID(job ID)命名的目录下。其中由mapreduce.client.submit.file.replication属性设置的默认JAR副本数为10个。
(4)JobSummiter通过调用资源管理器的submitApplication()方法提交作业。
(5)资源管理器收到调用它的submitApplication()消息后,便将请求传递给YARN调度器(scheduler)。调度器分配一个容器,然后节点管理器在资源管理器的管理下在容器中启动application master的进程。
(6)application master是一个Java应用程序,它的主类是MRAppMaster。application master对作业进行初始化,通过创建多个记录对象来保持对作业进度的跟踪。
(7)application master从HDFS接收在客户端计算过的输入分片,然后对每一个分片都创建一个map任务对象,以及由mapreduce.job.reduces属性(通过作业的setNumReduceTasks()方法设置)确定的多个reduce任务对象,任务ID在此时分配。如果作业很小,例如少于10个mapper而且只有一个reducer,同时输入大小小于一个HDFS块的作业(这几个值由mapreduce.job.ubertask.maxmaps、mapreduce.job.ubertask.maxreduces和mapreduce.job.ubertask.maxbytes设置),此时application master判断在新的容器中分配和运行任务的开销大于并行运行它们的开销,会选择和自己在同一个JVM上运行任务,这种作业称为uber任务,需要将mapreduce.job.ubertask.enable设置为true。最后,在任何任务运行之前,application master调用setupJob()方法设置OutputCommitter,FileOutputCommitter为默认值,表示将建立作业的最终输出目录及任务输出的临时工作空间。
(8)如果作业足够大,不适合作为uber任务运行,application master会为该作业中所有map任务和reduce任务向资源管理器请求容器。先为map任务发出请求,该请求优先级高于reduce任务请求,因为前者必须在后者的排序阶段启动之前完成,直到有5%的map任务完成时,为reduce任务的请求才会发出。请求为任务指定了内存需求和CPU数,默认情况下每个map任务和reduce任务都分配到1G内存和一个虚拟内核,这些值可以在每个作业上配置,可以通过以下四个属性设置:mapreduce.map.memory.mb、mapreduce.reduce.memory.mb、mapreduce.map.cpu.vcores和mapreduce.reduce.cpu.vcoresp.memory.mb。
(9)一旦资源管理器的调度器为任务分配了一个特定节点上的容器,application master通过与节点管理器通信来启动容器。
(10)该任务由主类为YarnChild的一个Java应用程序执行,位于执行任务节点的一个JVM上,因此用户自己写的map和reduce函数以及YarnChild中的任何缺陷不会影响到nodemanager。在它运行任务之前,首先将任务需要的资源本地化,包括作业的配置、JAR和所有来自HDFS的文件。
(11)最后,YarnChild运行map或reduce任务(父进程为application master)。每个任务都能执行搭建(setup)和提交(commit)操作,他们和任务本身在同一个JVM中运行,并由作业的OutputCommitter确定,对于基于文件的作业,提交操作将任务输出由临时位置迁移到最终位置。
14.当map或reduce任务运行时,每隔3秒钟通过umbilical接口向自己的application master报告进度和状态(包括计数器),application master会形成一个作业汇聚视图(aggregate view)。在作业期间,客户端每秒钟查询一次application master接收最新状态,轮询间隔通过mapreduce.client.progressmonitor.pollinterval设置。客户端也可以使用Job的getStatus()方法得到一个JobStatus的实例,包含作业的所有状态信息,如下所示:
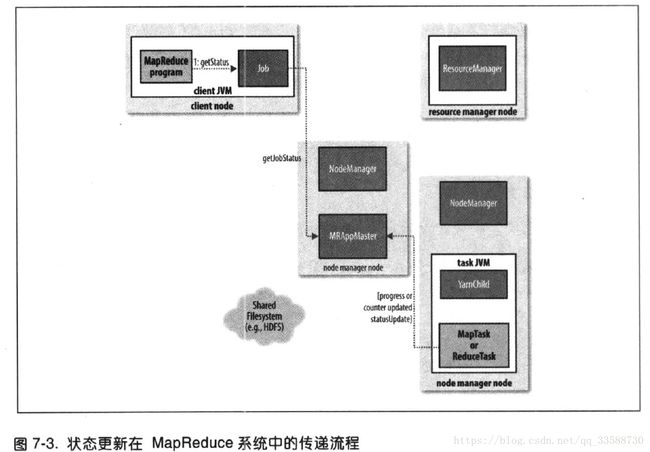
当application master收到作业最后一个任务已完成的通知后,便把作业的状态设置为“成功”。然后,在Job轮询状态时,便知道任务已完成,于是Job打印一条消息告知用户,然后从waitForCompletion()方法返回,Job的统计信息和计数值也在这个时候输出到控制台。最后,任务完成时,application master和任务容器清理其工作状态,这样中间输出将被删除,OutputCommitter的commitJob()方法会被调用,作业信息由历史服务器存档。
15.任务失败最常见的情况是map或reduce任务中的用户代码抛异常,这时任务JVM会在退出之前向其父application master发送错误报告,错误报告被记入用户日志。application master将此次任务尝试标记为failed,并释放容器使资源供其他任务使用。另一种失败情况是任务JVM突然退出,可能由于JVM软件缺陷导致MapReduce用户代码由于某些特殊原因造成JVM退出。这种情况下,节点管理器会注意到进程已经退出,并通知application master将此次任务尝试标记为失败。
一旦application master注意到已经有一段时间没收到进度更新(默认10分钟),会将任务标记为失败,在此之后任务JVM进程被杀死,超时间隔可以通过mapreduce.task.timeout设置,单位为毫秒。如果设置为0会关闭超时判定,任务永不被标记为超时失败。application master被告知一个任务尝试失败后,将重新调度该任务的执行,并避免在同一失败过的节点上重新调度该任务,如果一个任务失败4次,整个作业就失败不再重试,关于map和reduce任务的该值可以通过mapreduce.map/reduce.maxattempts属性控制。如果希望即使有任务失败,也能保留整个作业的部分结果,可以通过mapreduce.map/reduce.failures.maxpercent设置触发作业失败之前允许任务失败的最大百分比。被终止的任务尝试(task attempt)不会被计入任务运行尝试次数。
16.运行MapReduce application master的最多尝试次数由mapreduce.am.max-attempts属性控制,默认为2次。集群上运行的YARN application master最大尝试次数默认同样为2次,由yarn.resourcemanager.am.max-attempts属性控制,如果要增加MapReduce application master的尝试次数,也需要增加这个设置。恢复过程为:application master向资源管理器发送周期性心跳,当application master失败时,资源管理器将检测到该失败并在一个新的容器(由节点管理器管理)上开始新的master实例,对于MapReduce application master,将使用作业历史来恢复原状态。
MapReduce客户端向application master轮询进度报告,在作业初始化期间,客户端向资源管理器询问并缓存application master的地址,使其每次需要向application master查询时不必重载资源管理器。但如果application master运行失败,客户端在请求状态更新时超时,会重新向resourcemanager请求新的application master的地址。
如果节点管理器由于崩溃或运行缓慢而失败,资源管理器默认10分钟内(由yarn.resoucremanager.nm.liveness-monitor.expiry-interval-ms设置)没有收到源自节点管理器的心跳信息,将会停止该nodemanager,并将其从自己的节点池中移除以调度启用容器。曾在失败的nodemanager上运行并完成的map任务如果属于未完成的作业,application master会安排它们重新运行,因为失败节点上的中间输出可能无法被reduce任务访问。
如果应用程序的运行失败次数过高,节点管理器可能会被拉黑,即使节点管理器自己没失败过。每个应用的application master管理黑名单,对于MapReduce如果一个节点管理器上有3个任务失败,application master就会尽量将任务调度到不同节点上,该属性由mapreduce.job.maxtaskfailures.per.tracker设置。要注意的是,黑名单仅针对每个应用本身,别的应用可能依然会在故障节点上运行,即使该节点被过去别的应用的application master拉黑过。
17.如果是资源管理器挂掉非常严重,没有resourcemanager,作业和任务容器将无法启动,所有运行的作业都失败无法恢复。可以通过双机热备配置,运行一对资源管理器来预防这种单点故障。所有运行中的应用程序的信息备份在ZooKeeper或HDFS中,节点管理器信息没有备份在HDFS等状态存储区中。同样,任务由application master管理,所以任务也不是资源管理器状态的一部分。
当新资源管理器启动后,会从状态存储区中读取应用程序的信息,然后为集群中运行的所有应用程序重启application master。该行为不会被计为失败的应用程序尝试次数,因为应用程序不是因为程序代码错误失败,而是被系统强行终止的。
资源管理器从备机到主机的切换是由故障转移控制器(failover controller)处理的。默认的故障转移控制器是自动工作的,使用ZooKeeper的leader选举机制以确保同一时刻只有一个主资源管理器,它不一定是一个独立的进程,为配置方便默认情况嵌入在资源管理器中。客户端和节点管理器以轮询(round robin)方式尝试连接每一个资源管理器,直到找到主资源管理器,如果主资源管理器故障,它们会再次尝试直到备份资源管理器变为主资源管理器。
18.系统执行排序并将map输出作为输入传给reducer的过程为shuffle。过程如下所示:
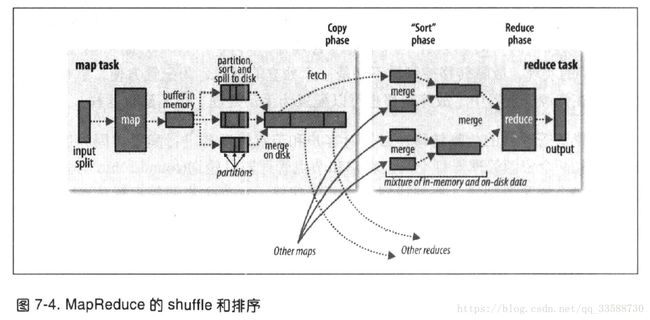
(1)在map端,每个map任务都有一个环形内存缓冲区用于存储任务输出。默认缓冲区大小为100MB,由mapreduce.task.io.sort.mb设置。一旦缓冲占用比例达到阈值(默认0.8即80%,由mapreduce.map.sort.percent设置),一个后台线程便开始把内容写入(spill)到磁盘(目录在mapreduce.cluster.local.dir属性设置处)。在写入磁盘过程中map输出继续写到缓冲区,如果缓冲区被填满,map会被暂停直到写入磁盘过程完成。
(2)在写入磁盘之前,线程首先根据数据要传给的reducer将数据划分为相应分区(partition)进行归类,每个分区包含键相同的特定键值对,包含特定类键的分区传给特定的reducer,例如reducer1接收1950年的温度数据,reducer2接收1951年的温度数据,也许多个map节点上都有1951和1952为键的两个分区,那么多个map节点上键为1950的map输出分区都传给reducer1的节点,键为1951的多个map输出分区都传给reducer2的节点。
(3)在每个分区中,后台线程按键在内存中排序,如果有combiner函数,就在排序后的输出上运行,可以减少写到磁盘上和传给reducer的数据。每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),在任务完成之前,溢出文件被合并为一个已分区且已排序的输出文件(partition和combiner都已在内存中运行),属性mapreduce.task.io.sort.factor控制一次最多合并多少流,默认为10。
如果至少存在3个溢出文件(mapreduce.map.combine.minspills属性设置),combiner会在输出文件写到磁盘之前再次执行。默认情况下,输出不压缩,但是将mapreduce.map.output.compress设置为true,就可以在将map输出写到磁盘过程中对它进行压缩,会使写磁盘速度更快,节约磁盘空间并减少传给reducer的数据量。
(4)在每个map任务完成时,会使用心跳机制通知application master。对于指定作业,application master知道map输出和主机位置的映射关系。reduce任务中的一个线程定期询问master获取map输出主机的位置,并开始复制map任务的输出,reduce任务有少量复制线程,因此可以并行取得map的输出,默认值为5个线程(mapreduce.reduce.shuffle.parallelcopies属性控制)。如果map输出很小,会被复制到reduce任务JVM的内存(mapreduce.reduce.shuffle.input.buffer.percent属性控制缓冲区百分比),否则map输出被复制到磁盘。一旦内存缓冲区达到阈值(mapreduce.reduce.shuffle.merge.percent)或达到map输出阈值(mapreduce.reduce.merge.inmem.threshold),则合并后写入到磁盘中。
(5)随着磁盘上副本增多,后台线程会将它们合并为更大的排好序的文件(一个reducer获得多个map节点上关于同类键的数据的多个分区,合并多个map节点的分区文件为一个),为了合并,压缩的map输出都必须在内存中被解压缩。复制完所有map输出后,reduce任务将合并map排序过的输出。合并因子mapreduce.task.io.sort.factor控制每次合并的输出文件数量,例如合并因子为10,有50个map输出,则合并5次,每次将10个文件合并为一个文件,形成5个中间文件。
(6)最后,把合并后的数据输入reduce函数执行reduce,最后输出直接写入到HDFS。
19.优化MapReduce的总原则是给shuffle过程尽量多提供内存空间。不过也需要平衡map和reduce函数能得到足够多的内存来运行,但不应该太多,例如在map中堆积数据。运行map和reduce任务的JVM内存使用大小由mapred.child.java.opts属性设置,任务节点上的内存应该尽可能设置的大些。在map端,可以通过避免多次溢出写磁盘来获得最佳性能,例如增加mapreduce.task.io.sort.mb的值。在reduce端,中间数据全部驻留在内存时,就能获得最佳性能。默认情况下是不可能的,因为所有内存一般都预留给reduce函数。但如果reduce函数内存需求不大,可以把mapreduce.reduce.merge.inmem.threshold设置为0,把mapreduce.reduce.input.buffer.percent设置为1.0或更低就可以提升性能。Hadoop默认使用4KB的缓冲区,可以在集群中通过设置io.file.buffer.size增加这个值。
20.任务执行环境的属性如下所示:
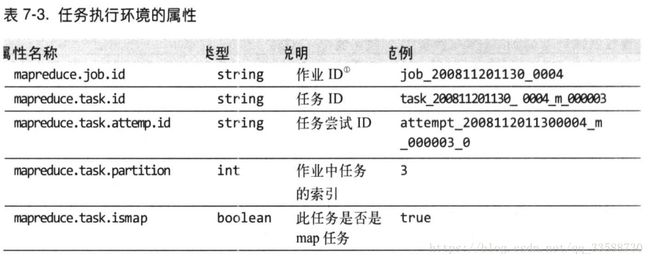
MapReduce将作业分解为任务,并行地执行任务以使作业的整体执行时间小于各个任务顺序执行的时间。在因为硬件老化或者软件配置错误等原因导致任务执行比预期缓慢的时候,Hadoop会检测并启动另一个相同的任务作为备份,即所谓任务的推测执行(speculative execution)。如果同时启动两个重复任务,它们会互相竞争,导致推测执行无法工作,对集群资源是种浪费。然而,调度器实际上跟踪作业中所有相同类型(map和reduce)任务的进度,并且仅启动运行速度明显低于平均水平的那部分任务的推测副本。一个任务完成后,任何正在运行的重复任务都会被终止,因此如果原任务在推测任务之前完成,终止推测任务,反之终止原任务。推测执行默认启用,可以基于集群、每个作业甚至单独为map和reduce任务启用该功能,相关属性表如下所示:
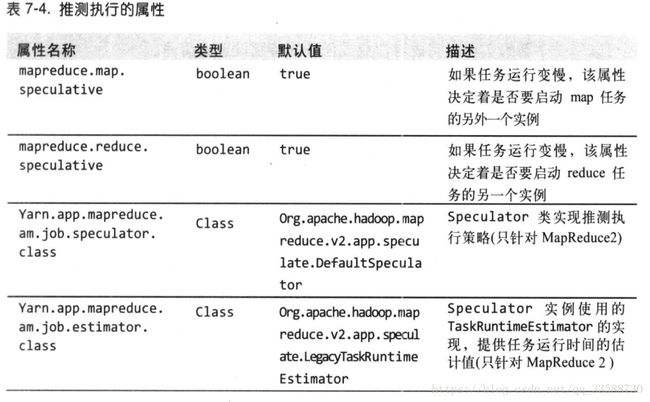
推测执行的目的是减少作业执行时间,但这是以集群效率为代价的,在繁忙集群中推测执行会减少整体吞吐量。一些集群管理员倾向于在集群上关闭推测执行,让用户自己根据个别作业需要而开启该功能。对于reduce任务,关闭推测执行是有益的,因为重复的reduce任务也要取得map输出,可能会大幅度增加集群上的网络传输。关闭推测执行的另一种情况是为了非幂等(nonidempotent)任务,即每次请求调用后任务的结果都不同,幂等性是无论调用多少次都不会有不同结果。
21.MapReduce使用一个提交协议来确保作业和任务完全成功或失败,该行为通过OutputCommitter实现,OutputCommitter由OutputFormat通过它的getOutputCommitter()方法确定,默认值为FileOutputCommitter,OutputCommitter的API如下:

setupJob()方法在作业运行前调用,通常用来执行初始化操作。当OutputCommitter设为FileOutputCommitter时,该方法创建最终的输出目录${mapreduce.output.fileoutputformat.outputdir},并为任务输出创建一个临时工作空间_temporary,作为最终输出目录的子目录。
如果作业成功则调用commitJob()方法,在默认基于文件的实现中,用于删除临时工作空间并在输出目录中创建一个名为_success的隐藏标志文件,以告知客户端该作业成功完成了。如果作业不成功,就通过状态对象调用abortJob(),意味该作业是否失败或终止,在默认实现中将删除作业的临时工作空间。
在任务级别的操作与此类似,任务执行前调用setupTask()方法,默认实现不做任何操作,因为针对任务输出命名的临时目录在写任务输出时才被创建。任务的提交阶段是可选的,可以通过needsTaskCommit()返回的false值来关闭。此时任务运行不需要提交协议,也不需要commitTask()或者abortTask()。当一个任务没有写任何输出时,FileOutputCommitter会跳过提交阶段。
如果任务成功,就调用commitTask(),在默认实现中将临时的任务输出目录(名字包含任务尝试ID以免同任务的不同尝试混淆)移动到最后的输出路径${mapreduce.output.fileoutputformat.outputdir}。否则调用abortTask(),删除临时任务输出目录。执行框架会保证一个任务在有多次任务尝试的情况下,只有一个任务尝试会被提交,例如第一个尝试失败提交稍后成功的尝试,或者两个任务尝试作为推测执行副本同时运行,提交先完成的并且取消另一个。
三、MapReduce类型与格式
22.MapReduce中,map和reduce函数遵循以下常规格式:

Reduce函数的输入类型必须与map函数的输出类型相同。如果使用combiner函数,它与reduce函数的形式相同,不同之处是它的输出类型是中间的键值对类型(K2与V2),这些中间值可以输入reduce函数。默认的输入格式是TextInputFormat,它产生的键类型是LongWritable(文件中每行开始的偏移量),值类型是Text。默认的mapper是Mapper类,它将输入的键和值原封不动地写到输出中。默认的partitioner是HashPartitioner,它对每条记录的键进行哈希操作以决定该记录应该属于哪个分区,每个分区由一个reduce任务处理,所以mapper节点上的分区种类数等于作业的reduce任务个数,具有相同键的记录将由同一个reduce任务处理。分区的计算方法如下,即键的哈希码逻辑与最大整数,结果再对分区数求余数:
key.hashCode() & Integer.MAX_VALUE % numPartitions
为了平衡reducer的个数与性能的关系,经验是目标reducer保持在每个运行5分钟左右,且至少产生一个HDFS块的输出比较合适。默认的reducer是Reducer类,也只是把所有输入写到输出中。默认的输出格式是TextOutputFormat,它将键和值转换成字符串并用制表符分隔开,然后一条记录一行进行输出。可设置的分隔符如下所示:
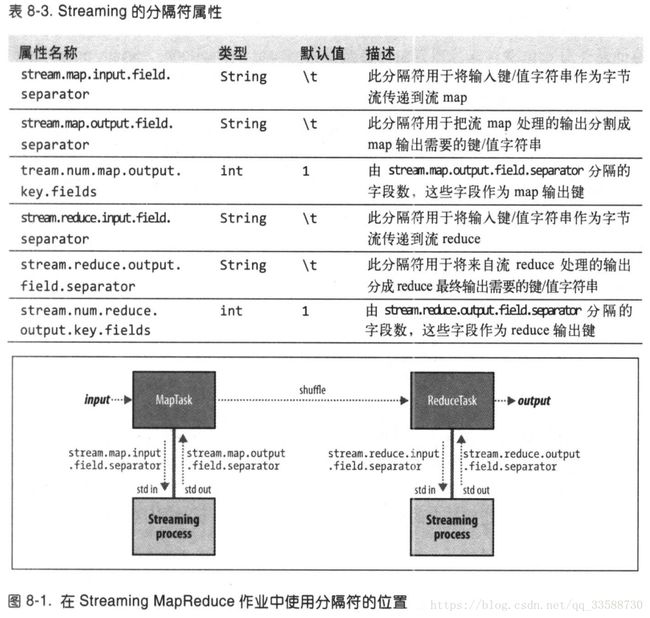
例如,如果stream.reduce.output.field.separator被设置为冒号,reduce的stream过程就把a:b行写入标准输出,其中Streaming的reducer就会知道a作为键,b作为值。
23.一个输入分片(split)就是一个由单个map操作来处理的输入块,每个map操作只处理一个输入分片,每个分片被划分为多条记录,每条记录就是一个键值对。输入分片在Java中表示为InputSplit接口,在org.apache.hadoop.mapreduce包中。InputSplit包含一个以字节为单位的长度和一组存储位置(即主机名)。由上可知,分片并不包含数据本身,而是指向数据的引用(reference)。存储位置可以让map任务尽量放在分片数据附近,而分片的大小用来排序分片,以便优先处理最大的分片,最小化作业运行时间。
开发者不需要直接处理InputSplit,它由InputFormat创建,负责创建输入分片并将它们分割成记录,API如下所示:

运行作业的客户端调用getSplits()计算分片,然后将它们发送到application master,application master使用其存储位置信息来调度map任务从而在集群上处理这些分片数据。Map任务把输入分片传给InputFormat的createRecordReader()方法来获得这个分片的RecordReader。RecordReader就像是记录的迭代器,map任务用一个RecordReader来生成记录的键值对,然后再传给map函数,查看Mapper的run()方法可以看到这些情况:

运行setup()之后,再重复调用Context上的nextKeyValue()为mapper产生键值对象。通过Context,键值从RecordReader中被检索出并传给map()方法,当reader读到流的结尾时,nextKeyValue()返回false,map任务运行cleanup()方法,然后结束。由于效率原因,RecordReader每次调用getCurrentKey()和getCurrentValue()时会返回同一个键值对象,只不过对象中的内容会因nextKeyValue()改变,而不是每个键值分一个对象。Reducer迭代器中的值对象也会被重复使用。
24.FileInputFormat是所有使用文件作为数据源的InputFormat实现的基类。它提供两个功能,一是用于指出作业的输入文件位置,二是为输入文件生成分片的代码实现,把分片分割为记录的作业由其子类来完成,如下所示:

FileInputFormat提供四类静态方法来设定Job的输入路径:

其中setInputPaths()方法可以覆盖前面几个方法在Job上设置的所有路径。当路径是目录时,表示包含该目录下所有文件都作为输入。但是,该目录下的内容不会被递归处理,如果目录下还包含子目录,也会被解释为文件从而产生错误。处理这个问题的方法有两种,第一种是使用一个文件glob(一个文件和目录的集合)或一个过滤器根据命名模式限定选择目录中的文件,第二种是将mapreduce.input.fileinputformat.input.dir.recursive设置为true从而强制对输入目录进行递归读取。
如果要排除特定文件,可以使用FileInputFormat的setInputPathFilter()方法设置一个过滤器,即使不设置过滤器,FileInputFormat也会使用一个默认过滤器来排除隐藏文件(名称以“.”和“_”开头的文件)。自定义的过滤器也是在默认过滤器基础上进行过滤,也就是依然只能看到非隐藏文件。
FileInputFormat只分割大文件,即超过HDFS块大小的文件(默认128MB)。分片通常与HDFS块大小一样,这些值的属性设置如下所示,其中因为map任务的数目默认情况下为1,所以分片默认最大值就是输入的大小,只有把它的值设置为小于块大小才有效果:

25.相对于大批量的小文件,Hadoop更适合处理少量的大文件。如果文件远小于HDFS的块大小,并且文件数量很多,一个map任务只能处理一个分片,那么一个文件就会有很多map任务,每次map操作都会造成额外开销。针对大量小文件可以使用CombineFileInputFormat,FileInputFormat为每个文件产生一个分片,而CombineFileInputFormat把多个文件打包到一个分片中以便每个mapper可以处理更多数据,决定哪些块放入同一个分片时,CombineFileInputFormat会考虑节点和机架的因素,因此在平常MapReduce作业中处理输入的速度不会下降。
不过,应当尽量避免有许多小文件的情况。因为MapReduce处理数据的最佳速度最好与数据在集群中的传输速度相同,而处理大量小文件将增加运行作业必须的寻址次数,在HDFS集群中存储大量小文件也会浪费namenode的内存。一个可以减少大量小文件的方法是使用顺序文件(sequence file)将这些小文件合并为一个或多个大文件,将文件名作为键,文件的内容作为值。
有两种方法可以保证输入文件不被切分。第一种是增加最小分片大小,将它设置大于要处理的最大文件大小,例如long.MAX_VALUE。第二种方法是使用FileInputFormat具体子类,并重写isSplitable()方法把返回值设为false,如下所示:
package MapReduceTypes;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
public class NonSplittableTextInputFormat extends TextInputFormat {
@Override
protected boolean isSplitable(JobContext context, Path file) {
return false;
}
}
26.有时mapper需要访问一个文件中的全部内容,即使不分割文件,依然需要一个RecordReader来读取文件内容作为record的值,如下代码为把整个文件作为一条记录的InputFormat:
package MapReduceTypes;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class WholeFileInputFormat extends FileInputFormat { //没有使用键所以为NullWritable,对于大量小文件改进的方法是继承CombineFileInputFormat
@Override
protected boolean isSplitable(JobContext context, Path filename) { //指定输入文件不被分片
return false;
}
@Override
public RecordReader createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { //返回定制的RecordReader实现
WholeFileRecordReader reader=new WholeFileRecordReader(); //依赖于WholeFileRecordReader类
reader.initialize(split,context); //初始化输入分片和配置
return reader;
}
}
上面代码依赖的定制RecordReader实现如下所示:
package MapReduceTypes;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class WholeFileRecordReader extends RecordReader { //WholeFileInputFormat的依赖类,负责将FileSplit转换成一条记录
private FileSplit fileSplit;
private Configuration conf;
private BytesWritable value=new BytesWritable();
private boolean processed=false; //用于表示记录是否被处理过
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.fileSplit=(FileSplit)split;
this.conf=context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if(!processed){ //如果文件没有处理过,就打开文件
byte[] contents=new byte[(int)fileSplit.getLength()]; //产生一个长度是文件长度的字节数组
Path file=fileSplit.getPath();
FileSystem fs=file.getFileSystem(conf);
FSDataInputStream in=null;
try{
in=fs.open(file);
IOUtils.readFully(in,contents,0,contents.length); //把文件的内容放入字节数组
value.set(contents,0,contents.length); //字节数组被传递到BytesWritable实例上设置数组
}finally{
IOUtils.closeStream(in);
}
processed=true;
return true; //表示成功读取记录
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return processed?1.0f:0.0f;
}
@Override
public void close() throws IOException {
//do nothing
}
}
假设有一个将若干个小文件打包成顺序文件的MapReduce作业,键是文件名,值是文件的内容,下面代码演示如何使用WholeFileInputFormat:
package MapReduceTypes;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class SmallFilesToSequenceFileConverter extends Configured implements Tool {
static class SequenceFileMapper extends Mapper {
private Text filenameKey;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
InputSplit split=context.getInputSplit();
Path path=((FileSplit)split).getPath(); //split原本是Context类型,需要强制转换
filenameKey=new Text(path.toString());
}
@Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
context.write(filenameKey,value);
}
}
public int run(String[] args) throws Exception {
Job job=JobBuilder.parseInputAndOutput(this,getConf(),args);
if(job==null){
return -1;
}
job.setInputFormatClass(WholeFileInputFormat.class); //输入格式是自己定制的WholeFileInputFormat,产生的键类型是NullWritable,值类型是BytesWritable
job.setOutputFormatClass(SequenceFileOutputFormat.class); //输出格式为sequence file
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setMapperClass(SequenceFileMapper.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new SmallFilesToSequenceFileConverter(),args);
System.exit(exitCode);
}
}
27.TextInputFormat是默认的InputFormat,每条记录是一行输入,键是LongWritable类型,存储该行在整个文件中的字节偏移量而不是行号,值是这行的内容,不包括任何行终止符(换行符和回车符),被打包为一个Text对象。文件按字节而不是按行切分为分片,每个分片单独处理,知道在分片内的行号很容易,要知道整个文件中的行号,可以先加上前几个分片的总偏移量,就可以获得该行在整个文件中的偏移量,再根据偏移量来计算行数。
文件的损坏可以表现为一个超长行,会导致内存溢出从而任务失败,通过将mapreduce.input.linerecordreader.line.maxlength设置为用字节数表示的、在内存范围内的值(适当超过输入数据中的行长),可以确保记录reader跳过太长的损坏的行。
输入的行数取决于输入分片的大小和行的长度。如果希望mapper收到固定行数的输入,需要将NLineInputFormat作为InputFormat使用,键值对与TextInputFormat相同,也为行的字节偏移量和行的数据本身。Mapreduce.input.lineinputformat.linespermap属性控制每个mapper正好收到N行输入。
28.针对MapReduce作业可能包含多种格式输入,需要不同的Mapper和InputFormat处理的情况,可以使用MultipleInputs类来处理,它允许为每条输入路径指定InputFormat和Mapper,例如:

这样如果不同的Mapper输出的类型相同,reduce不会发现输入是由不同的mapper产生的,因为reduce只看到聚集后的map输出。如果有多种输入格式而只有一个mapper,可以用addInputPath()的重载方法:
![]()
DBInputFormat这种输入格式用于使用JDBC从关系型数据库中读取数据,但是它最好只用于加载小量的数据集,过多的mapper读数据会使数据库受不了。如果需要与来自HDFS的大数据集链接,就需要使用MultipleInputs。与DBInputFomat对应的输出格式是DBOutputFormat,用于将输出数据(中等规模)转存到数据库。
29.默认的输出格式是TextOutputFormat,把每条记录写为文本行。默认键值对由制表符分割(可以设置mapreduce.output.textoutputformat.separator属性改变),键和值可以是任何类型,因为TextOutputFormat调用toString()将它们转换为字符串。可以使用NullWritable来省略输出的键或值,如果两者都省略相当于NullOutputFormat输出格式,什么也不输出。SequenceFileOutputFormat将它的输出写为一个顺序文件。如果输出需要作为后续MapReduce任务的输入,可以使用该输出格式,因为它的格式紧凑容易被压缩。
FileOutputFormat及其子类产生的文件放在输出目录下,每个reducer一个文件并且文件由分区号命名:part-r-00000,part-r-00001等。有时需要对输出文件名进行控制或每个reducer输出多个文件,此时需要使用MultipleOutputs类,这些文件的名称源于输出的键和值或者任意字符串,采用name-m-nnnnn的文件名用于map输出,name-r-nnnnn用于reduce输出,使用MultipleOutputs按照气象站划分数据的例子如下所示:
package MapReduceTypes;
import MapReduceApplication.NcdcRecordParser;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class PartitionByStationUsingMultipleOutputs extends Configured implements Tool { //将气象数据集分区到以气象站ID命名的文件
static class StationMapper extends Mapper{
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
context.write(new Text(parser.getYear()),value);
}
}
static class MultipleOutputsReducer extends Reducer {
private MultipleOutputs multipleOutputs;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
multipleOutputs=new MultipleOutputs(context); //构造MultipleOutputs实例
}
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for(Text value:values){
multipleOutputs.write(NullWritable.get(),value,key.toString()); //将气象站标识符作为文件名输出键值对
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
multipleOutputs.close();
}
}
public int run(String[] args) throws Exception {
Job job=JobBuilder.parseInputAndOutput(this,getConf(),args); //把打印使用说明的逻辑抽取出来并把输入输出路径设定放到这样一个帮助方法中,实现对run()方法的前几行进行简化
if(job==null){
return -1;
}
job.setMapperClass(StationMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setReducerClass(MultipleOutputsReducer.class);
job.setOutputKeyClass(NullWritable.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new PartitionByStationUsingMultipleOutputs(),args);
System.exit(exitCode);
}
}
四、MapReduce特性
30.任务计数器由其关联任务维护,定期发送给application master,任务计数器的值每次都是完整传输的,并非累加自上次传输后的计数值,防止因消息丢失引发错误。如果一个任务在作业执行期间失败,相关计数器的值也会减小。作业计数器也同样,但是作业计数器里的计数器值不会随着任务层次的变化而改变,例如TOTAL_LAUNCHED_MAPS统计作业执行过程中启动的map任务数,不会因有map任务失败而改变该计数器的值。
除了默认提供的计数器,MapReduce允许用户定制自己的计数器,计数器的值可在mapper或reducer中增加,计数器由一个Java枚举(enum)类型定义,以便对有关计数器分组。枚举类型的名称即为组的名称,枚举类型的字段就是计数器名称。下面的代码加上了统计缺失记录和气温质量代码的计数器:
package MapReduceProperties;
import MapReduceApplication.MaxTemperatureReducer;
import MapReduceApplication.NcdcRecordParser;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class MaxTemperatureWithCounters extends Configured implements Tool { //统计最高气温的作业,包括用计数器统计气温值缺失的记录、不规范的字段和质量代码
enum Temperature{
MISSING,
MALFORMED
}
static class MaxTemperatureMapperWithCounters extends Mapper {
private NcdcRecordParser parser=new NcdcRecordParser(); //解析NCDC格式的气温纪录,与MaxTemperatureMapperWithCounters配合的解析类,在同工程MapReduceApplication包内
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if(parser.isValidTemperature()){
int airTemperature=parser.getAirTemperature();
context.write(new Text(parser.getYear()),new IntWritable(airTemperature));
}else if(parser.isMalformedTemperature()){
System.err.println("Ignoring possibly corrupt input: "+value);
context.getCounter(Temperature.MALFORMED).increment(1); //如果发现一个不规范字段,不规范计数器加一
}else if(parser.isMissingTemperature()){
context.getCounter(Temperature.MISSING).increment(1); //如果发现一个丢失的温度记录,丢失温度记录的计数器加一
}
//dynamic counter
context.getCounter("TemperatureQuality",parser.getQuality()).increment(1); //统计对应质量代码的计数器加一,该方法第一个参数为计数器的组名称,第二个参数为计数器名称,组名称会在命令行输出结果进度的时候显示
}
}
public int run(String[] args) throws Exception {
Job job= JobBuilder.parseInputAndOutput(this,getConf(),args); //把打印使用说明的逻辑抽取出来并把输入输出路径设定放到这样一个帮助方法中,实现对run()方法的前几行进行简化
if(job==null){
return -1;
}
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MaxTemperatureMapperWithCounters.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
int exitCode= ToolRunner.run(new MaxTemperatureWithCounters(),args); //exitCode被赋予上面run()方法中最后job.waitForCompletion()的返回值
System.exit(exitCode);
}
}
编译生成JAR包并放到/mnt/sda6目录下,并把NCDC数据文件放到HDFS中/input目录后,利用如下命令进行运行:
hadoop jar /mnt/sda6/MaxTemperatureWithCounters.jar \
MapReduceProperties.MaxTemperatureWithCounters /input /output-counters
任务运行成功后,在终端命令行里会显示进度结果,其中部分带有计数器信息,如下所示:

在上面命令行中的部分进度输出结果可看到,getCounter(String groupName, String counterName)方法中第一个参数的“TemperatureQuality”是计数器的组名,会显示在进度输出里,第二个参数是计数器名称。在需要动态创建计数器的场合,可以使用传入String的getCounter()方法,因为Java中枚举类型字段必须在编译阶段就指定,无法使用传入枚举类型的getCounter()方法。
31.一般在作业运行完成,计数器的值稳定下来时再获取计数器的值,不过Java API支持在作业运行期间获取计数器的值,下面的例子展示如何统计整个数据集中气温信息缺失记录的比例:
package MapReduceProperties;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.util.*;
public class MissingTemperatureFields extends Configured implements Tool { //统计气温信息缺失记录所占的比例
public int run(String[] args) throws Exception {
if(args.length!=1){
JobBuilder.printUsage(this,"");
return -1;
}
String jobID=args[0];
Cluster cluster=new Cluster(getConf());
Job job=cluster.getJob(JobID.forName(jobID));
if(job==null){
return -1;
}
Counters counters=job.getCounters();
//通过枚举值来获取气温信息缺失的记录数和被处理的记录数
long missing=counters.findCounter(MaxTemperatureWithCounters.Temperature.MISSING).getValue();
long total=counters.findCounter(TaskCounter.MAP_INPUT_RECORDS).getValue();
System.out.printf("Records with missing temperature fields: %.2f%%\n",100.0*missing/total);
return 0;
}
public static void main(String[] args) throws Exception{
int exitCode=ToolRunner.run(new MissingTemperatureFields(),args);
System.exit(exitCode);
}
}
32.MapReduce可用于排序,对于有符号整数,要用顺序文件存储数据才能排序,下面的代码例子只包含map任务,各个map创建并输出一个块压缩的顺序文件,如下所示:
package MapReduceProperties;
import MapReduceApplication.NcdcRecordParser;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class SortDataPreprocessor extends Configured implements Tool { //将天气数据转换成SequenceFile格式
static class CleanerMapper extends Mapper{
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if(parser.isValidTemperature()){
context.write(new IntWritable(parser.getAirTemperature()),value); //IntWritalbe键代表气温,Text值为数据行
}
}
}
public int run(String[] args) throws Exception {
Job job= JobBuilder.parseInputAndOutput(this,getConf(),args); //把打印使用说明的逻辑抽取出来并把输入输出路径设定放到这样一个帮助方法中,实现对run()方法的前几行进行简化
if(job==null){
return -1;
}
job.setMapperClass(CleanerMapper.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0);
job.setOutputFormatClass(SequenceFileOutputFormat.class); //设置输出格式为SequenceFile
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class); //输出以Gzip方式压缩
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK); //默认是RECORD,每条记录压缩,但是以块形式压缩效果更好
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new SortDataPreprocessor(),args); //exitCode被赋予上面run()方法中最后job.waitForCompletion()的返回值
System.exit(exitCode);
}
}
打包成jar并准备好输入数据后,用如下命令创建块压缩的顺序文件:
hadoop jar /mnt/sda6/SortByTemperatureUsingTotalOrderPartitioner.jar \
MapReduceProperties.SortDataPreprocessor /input/NCDC.txt /input/ncdc/all-seq
默认情况下,MapReduce根据输入记录的键对数据集排序,下列代码例子是利用IntWritable键对顺序文件排序的变种:
package MapReduceProperties;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SortByTemperatureUsingHashPartitioner extends Configured implements Tool { //调用默认HashPartitioner按IntWritable键排序顺序文件
public int run(String[] args) throws Exception {
Job job= JobBuilder.parseInputAndOutput(this,getConf(),args); //把打印使用说明的逻辑抽取出来并把输入输出路径设定放到这样一个帮助方法中,实现对run()方法的前几行进行简化
if(job==null){
return -1;
}
job.setInputFormatClass(SequenceFileInputFormat.class); //设置输入格式为SequenceFile
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class); //设置输出格式为SequenceFile
SequenceFileOutputFormat.setCompressOutput(job,true); //设置对应作业的输出是否压缩为true
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class); //输出以Gzip方式压缩
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK); //默认是RECORD,每条记录压缩,但是以块形式压缩效果更好
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new SortByTemperatureUsingHashPartitioner(),args); //exitCode被赋予上面run()方法中最后job.waitForCompletion()的返回值
System.exit(exitCode);
}
}
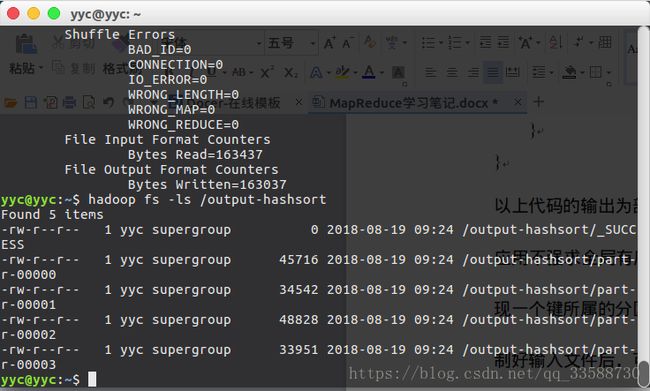
以上代码的输出为部分已排序,直接将多个文本文件连接起来无法保证全局有序。不过很多应用不强求全局有序,部分排序已经足够,通过使用map文件代替顺序文件,可以快速发现一个键所属的分区,然后在map文件分区中执行记录查找操作效率会更高。打包jar和复制好输入文件后,可以用如下命令运行程序,假设采用4个reducer运行,该指令产生4个已排序的输出文件:
hadoop jar /mnt/sda6/SortByTemperatureUsingHashPartitioner.jar \
MapReduceProperties.SortByTemperatureUsingHashPartitioner \
-D mapreduce.job.reduces=4 /input/all-seq /output-hashsort
可以看到确实产生了4个reduce输出文件,如下所示:
33.理想情况下,各个map分区所含记录数尽量大致相等,这样使作业的总体执行时间不会受制于个别reducer。为了更合理的给记录划较均匀的分区,遍历整个数据集知道数据的分布效率太低,可以通过对键空间进行采样,只查看一小部分键,获得键的近似分布即可。利用键进行全局排序的例子如下所示:
package MapReduceProperties;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.InputSampler;
import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class SortByTemperatureUsingTotalOrderPartitioner extends Configured implements Tool { //调用TotalOrderPartitioner按IntWritable键对顺序文件进行全局排序
public int run(String[] args) throws Exception {
Job job= JobBuilder.parseInputAndOutput(this,getConf(),args); //把打印使用说明的逻辑抽取出来并把输入输出路径设定放到这样一个帮助方法中,实现对run()方法的前几行进行简化
if(job==null){
return -1;
}
job.setInputFormatClass(SequenceFileInputFormat.class); //设置输入格式为SequenceFile
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class); //设置输出格式为SequenceFile
SequenceFileOutputFormat.setCompressOutput(job,true); //设置对应作业的输出是否压缩为true
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class); //输出以Gzip方式压缩
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK); //默认是RECORD,每条记录压缩,但是以块形式压缩效果更好
job.setPartitionerClass(TotalOrderPartitioner.class); //设置用于分区的类
InputSampler.Sampler sampler=new InputSampler.RandomSampler(0.1,10000,10); //以指定采样率均匀从一个数据集中选择样本,这里采样率为0.1,还有最大样本数和最大分区数,任意一个限制条件满足即停止采样
InputSampler.writePartitionFile(job,sampler); //创建一个顺序文件来存储定义分区的键
//Add to DistributedCache
Configuration conf=job.getConfiguration();
String partitionFile=TotalOrderPartitioner.getPartitionFile(conf); //为排序作业创建分区
URI partitionUri=new URI(partitionFile);
DistributedCache.addCacheFile(partitionUri,job.getConfiguration()); //job.addCacheFile(partitionUri); CDH的maven依赖中缺少该写法
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new SortByTemperatureUsingTotalOrderPartitioner(),args);
System.exit(exitCode);
}
}
除了RandomSampler也有其他的采样器,SplitSampler只采样一个分片中前n条记录,因为未在所有分片中广泛采样所以不适合已经排好序的数据。IntervalSample以一定间隔定期从分片中选择键,对于已排好序的数据是个更好的选择。但要注意,TotalOrderPartitioner只用于分区边界均不相同的时候,因此当键空间较小时,设置太大分区数可能会导致数据冲突。上面的代码运行可以使用如下命令,输出4个已经内部排好序的分区,且分区i中所有键都小于分区i+1中的键:
hadoop jar /mnt/sda6/SortByTemperatureUsingTotalOrderPartitioner.jar \
MapReduceProperties.SortByTemperatureUsingTotalOrderPartitioner \
-D mapreduce.job.reduces=4 /input/all-seq /output-totalsort
34.MapReduce在记录到达reducer前按键对记录排序,但键对应的值并没有排序。有时候需要获取按值排序的结果,这样要最大值放在输出的开头,就不用再遍历后面的输出以节省时间和开销。这种辅助排序方法有以下步骤:(1)定义包含键和值的组合键。(2)根据组合键对记录进行排序,即同时用键和值进行排序。(3)针对组合键进行分区和分组时只考虑键。分区和分组的区别在于,一个分区内的键值对都送给同一个reducer,而分组是根据键值对决定哪些键值对放在同一批次中供reduce()方法处理一次,一个组为一个reduce()批次。代码例子如下所示:
package MapReduceProperties;
import MapReduceApplication.NcdcRecordParser;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class MaxTemperatureUsingSecondarySort extends Configured implements Tool { //对键和值组成的组合键中的气温进行排序来找出最高气温
//自己定义的key类应该实现WritableComparable接口
public static class IntPair implements WritableComparable {
@Override
public String toString() {
return first+"\t"+second;
}
private int first;
private int second;
public IntPair(){ //无参构造函数一定要显示声明,因为框架会通过反射在内部生成该类对象,在KeyComparator中会用到
}
//设置组合键的前后两个值
public IntPair(int first,int second){
this.first=first;
this.second=second;
}
public int getFirst(){
return first;
}
public int getSecond(){
return second;
}
//反序列化,从流中的二进制转换成IntPair,因为继承了WritableComparable所以必须实现该方法
public void readFields(DataInput in) throws IOException {
first=in.readInt();
second=in.readInt();
}
//序列化,将IntPair转化成使用流传输的二进制,因为继承了WritableComparable所以必须实现该方法
public void write(DataOutput out) throws IOException {
out.writeInt(first);
out.writeInt(second);
}
//重载compareTo方法,进行组合键key的比较,分组后的二次排序会隐式调用该方法,因为继承了WritableComparable所以必须实现该方法
public int compareTo(IntPair o){
if(o instanceof IntPair){
int cmp=(first==o.first)?0:((first>o.first)?-1:1); //因为是倒序排列,最大的排在最前面,所以当大于时输出-1,与默认情况相反
if(cmp!=0) return cmp;
}
return (second==o.second)?0:((second>o.second)?-1:1);
}
}
static class MaxTemperatureMapper extends Mapper {
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if(parser.isValidTemperature()){
context.write(new IntPair(parser.getYearInt(),parser.getAirTemperature()),NullWritable.get()); //NullWritable.get()用于获取空值,不能像其他Writable一样用new NullWritable来获取
}
}
}
static class MaxTemperatureReducer extends Reducer {
@Override
protected void reduce(IntPair key, Iterable values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static class FirstPartitioner extends Partitioner { //创建自定义partitioner以按照组合键的首字段即年份进行分区,保证同一年的记录会被发送到同一个reducer中
@Override
public int getPartition(IntPair key, NullWritable value, int numPartitions) {
//multiply by 127 to perform some mixing
return Math.abs(key.getFirst()*127)%numPartitions;
}
}
public static class KeyComparator extends WritableComparator { //对组合键进行降序排序
protected KeyComparator(){
super(IntPair.class,true); //调用父类WritableComparator的构造函数
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1=(IntPair)w1;
IntPair ip2=(IntPair)w2;
return ip1.compareTo(ip2);
}
}
public static class GroupComparator extends WritableComparator{ //按年份对键进行分组,只取键的首字段进行比较,按照年份升序排序
protected GroupComparator(){
super(IntPair.class,true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1=(IntPair)w1;
IntPair ip2=(IntPair)w2;
return Integer.compare(ip1.getFirst(),ip2.getFirst());
}
}
@Override
public int run(String[] args) throws Exception {
Job job= JobBuilder.parseInputAndOutput(this,getConf(),args); //把打印使用说明的逻辑抽取出来并把输入输出路径设定放到这样一个帮助方法中,实现对run()方法的前几行进行简化
if(job==null){
return -1;
}
job.setMapperClass(MaxTemperatureMapper.class);
job.setPartitionerClass(FirstPartitioner.class); //设置用于分区的类
job.setSortComparatorClass(KeyComparator.class); //设置用于排序的comparator类
job.setGroupingComparatorClass(GroupComparator.class); //设置用于分组的comparator类
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(IntPair.class);
job.setOutputValueClass(NullWritable.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new MaxTemperatureUsingSecondarySort(),args); //exitCode被赋予上面run()方法中最后job.waitForCompletion()的返回值
System.exit(exitCode);
}
}
打包jar和放置好输入文件后,用如下命令运行程序和查看输出结果:
hadoop jar /mnt/sda6/MaxTemperatureUsingSecondarySort.jar \
MapReduceProperties.MaxTemperatureUsingSecondarySort /input/NCDC.txt /output
hadoop fs -cat /output/part-* | sort | head
35.MapReduce也支持大型数据集之间的连接(join)操作,但从头写相关代码很棘手,更推荐使用Hive或Spark等更高级的框架。如果一个数据集很大(如天气和温度记录),而另一个数据集很小(如气象站名称等元数据),可以把小数据集分发到集群中每一个节点中,与大数据集放在一起实现连接。连接操作如果由mapper执行,则成为“map端连接”,如果由reducer执行则称为“reduce端连接”。连接操作如图所示:
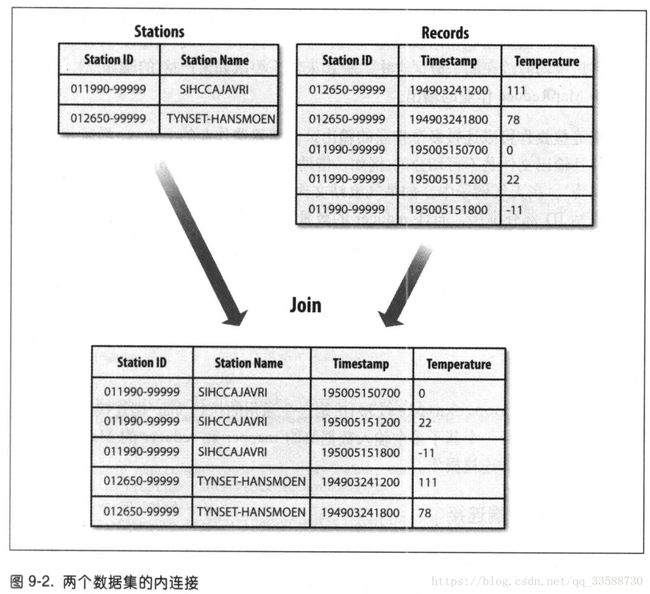
如果是两个大规模输入数据集之间的map端连接,会在数据到达map函数之前就执行连接操作。为了达到目的,各map的输入数据必须先分区并以特定方式排序,各输入数据集被划分为相同数量的分区,并均按相同的键排序。同一个键的所有记录都会放在同一分区中。Map端连接操作可以连接多个作业的输出,只要这些作业的reducer数量相同、键相同并且输出文件是不可切分的(如可进行gzip压缩)。利用org.apache.hadoop.mapreduce.join包中的CompositeInputFormat类来运行一个map端连接。
由于reduce端连接不要求输入数据集符合特定结构,因此reduce端连接比map端连接常用。但两个数据集都需经过shuffle过程,所以reduce端连接的效率会低一些。基本思路是mapper为各个记录标记源,并使用连接键作为map输出键,使键相同的记录放在同一个reducer中。数据集输入源往往有多种格式,可以使用MultipleInputs类解析和标注多个源。例如,总共有两个输入源,一个是气象站的记录,一个是天气记录,气象站记录的解析类如下所示:
package MapReduceProperties;
import org.apache.hadoop.io.Text;
public class NcdcStationMetadataParser {
private String stationId;
private String stationName;
public boolean parse(String record){
if(record.length()<42){ //header
return false;
}
String usaf=record.substring(0,6); //stationID横杠前六位数字
String wban=record.substring(7,12); //stationID横杠后五位数字
stationId=usaf+"-"+wban;
stationName=record.substring(14,42);
try{
Integer.parseInt(usaf); //USAF identifiers are numeric
return true;
}catch(NumberFormatException e){
return false;
}
}
public boolean parse(Text record){
return parse(record.toString());
}
public String getStationId(){
return stationId;
}
public String getStationName(){
return stationName;
}
}
用于标记和区分气象站数据集的mapper类如下所示:
package MapReduceProperties;
import HadoopIO.TextPair;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class JoinStationMapper extends Mapper { //在reduce端连接中,标记气象站数据集的mapper
private NcdcStationMetadataParser parser=new NcdcStationMetadataParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if(parser.parse(value)){
context.write(new TextPair(parser.getStationId(),"0"),new Text(parser.getStationName())); //TextPair的第二个字段标记为0以区分它是气象站记录
}
}
}
用于标记和区分天气记录数据集的mapper类如下所示:
package MapReduceProperties;
import HadoopIO.TextPair;
import MapReduceApplication.NcdcRecordParser;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class JoinRecordMapper extends Mapper { //在reduce端连接中标记天气数据集的mapper
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
context.write(new TextPair(parser.getStationId(),"1"),value); //TextPair的第二个字段标记为1以区分它是天气记录
}
}
Reducer先接收气象站数据集记录,再接收天气数据集记录,连接两种已标记的数据集的reducer如下所示:
package MapReduceProperties;
import HadoopIO.TextPair;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class JoinReducer extends Reducer { //用于连接已标记的气象站数据集和天气记录数据集的reducer
@Override
protected void reduce(TextPair key, Iterable values, Context context) throws IOException, InterruptedException {
Iterator iter=values.iterator(); //迭代部分中,为了提高效率对象被重复使用,因此下一行的语句很关键,如果没有该语句,stationName就会指向上一条记录的值
Text stationName=new Text(iter.next());
while(iter.hasNext()){
Text record=iter.next();
Text outValue=new Text(stationName.toString()+"\t"+record.toString());
context.write(key.getFirst(),outValue); //输出的键为气象站ID,值为气象站名称和天气记录
}
}
}
实际将两个数据集连接在一起通过驱动类来完成,如下所示:
package MapReduceProperties;
import HadoopIO.TextPair;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JoinRecordWithStationName extends Configured implements Tool { //对天气记录和气象站名称进行连接操作
public static class KeyPartitioner extends Partitioner{
@Override
public int getPartition(TextPair key, Text value, int numPartitions) {
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions; //利用哈希值作为分区计算函数的一部分,根据组合键的第一个字段(气象站ID)进行分区
}
}
@Override
public int run(String[] args) throws Exception {
if(args.length!=3){
JobBuilder.printUsage(this," 36.“边数据”(side data)是作业所需的额外只读数据,用于辅助处理主数据集,可以将边数据存放在HDFS上并在任务运行时及时将边数据文件复制到任务节点以供使用,使用主数据集并查询边数据的例子如下所示:
package MapReduceProperties;
import MapReduceApplication.MaxTemperatureReducer;
import MapReduceApplication.NcdcRecordParser;
import MapReduceTypes.JobBuilder;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.File;
import java.io.IOException;
public class MaxTemperatureByStationNameUsingDistributedCacheFile extends Configured implements Tool { //查找各气象站的最高气温并显示气象站名称,气象站文件是辅助气温主数据集的边数据,存放在HDFS上
static class StationTemperatureMapper extends Mapper{
private NcdcRecordParser parser=new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if(parser.isValidTemperature()){
context.write(new Text(parser.getStationId()),new IntWritable(parser.getAirTemperature())); //mapper输出气象站ID和气温数据键值对
}
}
}
static class MaxTemperatureReducerWithStationLookup extends Reducer { //除了查找最高气温,还需要缓存的边数据文件的配合来查找气象站名称
private NcdcStationMetadata metadata;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
metadata=new NcdcStationMetadata();
metadata.initialize(new File("station-fixed-width.txt")); //解析类从HDFS存放的边数据文件中读取并解析出气象站ID与名称保存到解析类内的HashMap中,文件路径与任务的工作目录相同
}
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
String stationName=metadata.getStationName(key.toString()); //将mapper输出的键与解析类NcdcStationMetadata中存储的边数据文件中的键相对照解析出气象站名称(值)
int maxValue=Integer.MIN_VALUE;
for(IntWritable value:values){
maxValue=Math.max(maxValue,value.get());
}
context.write(new Text(stationName),new IntWritable(maxValue)); //reducer输出气象站名称和温度最大值键值对
}
}
@Override
public int run(String[] args) throws Exception {
Job job= JobBuilder.parseInputAndOutput(this,getConf(),args);
if(job==null){
return -1;
}
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(StationTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducerWithStationLookup.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
int exitCode= ToolRunner.run(new MaxTemperatureByStationNameUsingDistributedCacheFile(),args);
System.exit(exitCode);
}
}
打包jar和放好输入文件后,可以用如下命令来运行:
hadoop jar /<目录>/hadoop-examples.jar \
MapReduceProperties.MaxTemperatureByStationNameUsingDistributedCacheFile \
-files /input/ncdc/metadata/stations-fixed-width.txt /input/ncdc/all /output
其中-files参数指定会用到的边数据文件,也可以使用-archives参数指定存档文件(如JAR、ZIP、tar和gzipped tar文件等),这些文件会被自动解压或解档到任务节点。-libjars参数会把JAR添加到mapper和reducer任务的类路径中。当用户启动一个作业,Hadoop会把这三个参数所指定的文件复制到HDFS中,在任务运行之前,节点管理器将文件从HDFS复制到对应节点的磁盘缓存使任务能访问文件。
除了在命令行中指定参数,也可以在代码中使用Job的API来进行相关设置,两种方式比较如下所示:

Nodemanager为缓存中的文件各维护一个计数器来统计这些文件的被使用情况。当任务将运行时,该任务使用的所有文件的对应计数器加1,当任务执行完毕后,这些计数器值减1。仅当文件不再使用中(即计数为0),才可以删除该文件。当节点缓存容量超过一定范围(默认10GB)时,需要根据最近最少使用原则删除文件来腾出空间,该阈值通过yarn.nodemanager.localizer.cache.target-size-mb设置。