从Spring及Mybatis框架源码中学习设计模式(创建型)
设计模式是解决问题的方案,从大神的代码中学习对设计模式的使用,可以有效提升个人编码及设计代码的能力。本系列博文用于总结阅读过的框架源码(Spring系列、Mybatis)及JDK源码中 所使用过的设计模式,并结合个人工作经验,重新理解设计模式。
本篇博文主要看一下创建型的几个设计模式,即,单例模式、各种工厂模式 及 建造者模式。
单例模式
目标
确保某个类只有一个实例,并提供该实例的获取方法。
实现方式
最简单的就是 使用一个私有构造函数、一个私有静态变量,以及一个公共静态方法的方式来实现。懒汉式、饿汉式等简单实现就不多BB咯,这里强调一下双检锁懒汉式实现的坑,以及枚举方式的实现吧,最后再结合spring源码 扩展一下单例bean的实现原理。
1. 双检锁实现的坑
/**
* @author 云之君
* 双检锁 懒汉式,实现线程安全的单例
* 关键词:JVM指令重排、volatile、反射攻击
*/
public class Singleton3 {
/**
* 对于我们初级开发来说,这个volatile在实际开发中可能见过,但很少会用到
* 这里加个volatile进行修饰,也是本单例模式的精髓所在。
* 下面的 instance = new Singleton3(); 这行代码在JVM中其实是分三步执行的:
* 1、分配内存空间;
* 2、初始化对象;
* 3、将instance指向分配的内存地址。
* 但JVM具有指令重排的特性,实际的执行顺序可能会是1、3、2,导致多线程情况下出问题,
* 使用volatile修饰instance变量 可以 避免上述的指令重排
* tips:不太理解的是 第一个线程在执行第2步之前就已经释放了锁吗?导致其它线程进入synchronized代码块
* 执行 instance == null 的判断?
*/
private volatile static Singleton3 instance;
private Singleton3(){
}
public static Singleton3 getInstance(){
if(instance == null){
synchronized(Singleton3.class){
if(instance == null){
instance = new Singleton3();
}
}
}
return instance;
}
}
2. 枚举实现
其它的单例模式实现往往都会面临序列化 和 反射攻击的问题,比如上面的Singleton3如果实现了Serializable接口,那么在每次序列化时都会创建一个新对象,若要保证单例,必须声明所有字段都是transient的,并且提供一个readResolve()方法。反射攻击可以通过setAccessible()方法将私有的构造方法公共化,进而实例化。若要防止这种攻击,就需要在构造方法中添加 防止实例化第二个对象的代码。
枚举实现的单例在面对 复杂的序列化及反射攻击时,依然能够保持自己的单例状态,所以被认为是单例的最佳实践。比如,mybatis在定义SQL命令类型时就使用到了枚举。
package org.apache.ibatis.mapping;
/**
* @author Clinton Begin
*/
public enum SqlCommandType {
UNKNOWN, INSERT, UPDATE, DELETE, SELECT, FLUSH;
}
实际范例
1. java.lang.Runtime
/**
* 每个Java应用程序都有一个单例的Runtime对象,通过getRuntime()方法获得
* @author unascribed
* @see java.lang.Runtime#getRuntime()
* @since JDK1.0
*/
public class Runtime {
/** 很明显,这里用的是饿汉式 实现单例 */
private static Runtime currentRuntime = new Runtime();
public static Runtime getRuntime() {
return currentRuntime;
}
/** Don't let anyone else instantiate this class */
private Runtime() {}
}
2. java.awt.Desktop
public class Desktop {
/**
* Suppresses default constructor for noninstantiability.
*/
private Desktop() {
peer = Toolkit.getDefaultToolkit().createDesktopPeer(this);
}
/**
* 由于对象较大,这里使用了懒汉式延迟加载,方式比较简单,直接把锁加在方法上。
* 使用双检锁方式实现的单例 还没怎么碰到过,有经验的小伙伴 欢迎留言补充
*/
public static synchronized Desktop getDesktop(){
if (GraphicsEnvironment.isHeadless()) throw new HeadlessException();
if (!Desktop.isDesktopSupported()) {
throw new UnsupportedOperationException("Desktop API is not " +
"supported on the current platform");
}
sun.awt.AppContext context = sun.awt.AppContext.getAppContext();
Desktop desktop = (Desktop)context.get(Desktop.class);
if (desktop == null) {
desktop = new Desktop();
context.put(Desktop.class, desktop);
}
return desktop;
}
}
Spring的单例bean是如何实现的?
Spring实现单例bean是使用map注册表和synchronized同步机制实现的,通过分析spring的 AbstractBeanFactory 中的 doGetBean 方法和DefaultSingletonBeanRegistry的getSingleton()方法,可以理解其实现原理。
public abstract class AbstractBeanFactory extends FactoryBeanRegistrySupport implements ConfigurableBeanFactory {
......
/**
* !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
* 真正实现向IOC容器获取Bean的功能,也是触发依赖注入(DI)功能的地方
* !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*/
@SuppressWarnings("unchecked")
protected <T> T doGetBean(final String name, final Class<T> requiredType, final Object[] args,
boolean typeCheckOnly) throws BeansException {
......
//创建单例模式bean的实例对象
if (mbd.isSingleton()) {
//这里使用了一个匿名内部类,创建Bean实例对象,并且注册给所依赖的对象
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
public Object getObject() throws BeansException {
try {
/**
* !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
* 创建一个指定的Bean实例对象,如果有父级继承,则合并子类和父类的定义
* 走子类中的实现
* !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
*/
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
//获取给定Bean的实例对象
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
......
}
}
/**
* 默认的单例bean注册器
*/
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
/** 单例的bean实例的缓存 */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);
/**
* 返回给定beanName的 已经注册的 单例bean,如果没有注册,则注册并返回
*/
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "'beanName' must not be null");
// 加锁,保证单例bean在多线程环境下不会创建多个
synchronized (this.singletonObjects) {
// 先从缓存中取,有就直接返回,没有就创建、注册到singletonObjects、返回
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while the singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
if (logger.isDebugEnabled()) {
logger.debug("Creating shared instance of singleton bean '" + beanName + "'");
}
beforeSingletonCreation(beanName);
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<Exception>();
}
try {
singletonObject = singletonFactory.getObject();
}
catch (BeanCreationException ex) {
if (recordSuppressedExceptions) {
for (Exception suppressedException : this.suppressedExceptions) {
ex.addRelatedCause(suppressedException);
}
}
throw ex;
}
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
afterSingletonCreation(beanName);
}
// 注册到单例bean的缓存
addSingleton(beanName, singletonObject);
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
}
简单工厂模式
个人理解
把同一系列类的实例化交由一个工厂类进行集中管控。与其说它是一种设计模式,倒不如把它看成一种编程习惯,因为它不符合“开闭原则”,增加新的产品类需要修改工厂类的代码。
简单实现
public interface Hero {
void speak();
}
public class DaJi implements Hero {
@Override
public void speak() {
System.out.println("妲己,陪你玩 ~");
}
}
public class LiBai implements Hero{
@Override
public void speak() {
System.out.println("今朝有酒 今朝醉 ~");
}
}
/** 对各种英雄进行集中管理 */
public class HeroFactory {
public static Hero getShibing(String name){
if("LiBai".equals(name))
return new LiBai();
else if("DaJi".equals(name))
return new DaJi();
else
return null;
}
}
这种设计方式只在我们产品的“FBM资金管理”模块有看到过,其中对100+个按钮类进行了集中管控,不过其设计结构比上面这种要复杂的多。
工厂方法模式
个人理解
在顶级工厂(接口/抽象类)中定义 产品类的获取方法,由具体的子工厂实例化对应的产品,一般是一个子工厂对应一个特定的产品,实现对产品的集中管控,并且符合“开闭原则”。
Mybatis中的范例
mybatis中数据源DataSource的获取使用到了该设计模式。接口DataSourceFactory定义了获取DataSource对象的方法,各实现类 完成了获取对应类型的DataSource对象的实现。(mybatis的源码都是缩进两个空格,难道国外的编码规范有独门派系?)
public interface DataSourceFactory {
// 设置DataSource的属性,一般紧跟在DataSource初始化之后
void setProperties(Properties props);
// 获取DataSource对象
DataSource getDataSource();
}
public class JndiDataSourceFactory implements DataSourceFactory {
private DataSource dataSource;
@Override
public DataSource getDataSource() {
return dataSource;
}
@Override
public void setProperties(Properties properties) {
try {
InitialContext initCtx;
Properties env = getEnvProperties(properties);
if (env == null) {
initCtx = new InitialContext();
} else {
initCtx = new InitialContext(env);
}
if (properties.containsKey(INITIAL_CONTEXT)
&& properties.containsKey(DATA_SOURCE)) {
Context ctx = (Context) initCtx.lookup(properties.getProperty(INITIAL_CONTEXT));
dataSource = (DataSource) ctx.lookup(properties.getProperty(DATA_SOURCE));
} else if (properties.containsKey(DATA_SOURCE)) {
dataSource = (DataSource) initCtx.lookup(properties.getProperty(DATA_SOURCE));
}
} catch (NamingException e) {
throw new DataSourceException("There was an error configuring JndiDataSourceTransactionPool. Cause: " + e, e);
}
}
}
public class UnpooledDataSourceFactory implements DataSourceFactory {
protected DataSource dataSource;
// 在实例化该工厂时,就完成了DataSource的实例化
public UnpooledDataSourceFactory() {
this.dataSource = new UnpooledDataSource();
}
@Override
public DataSource getDataSource() {
return dataSource;
}
}
public class PooledDataSourceFactory extends UnpooledDataSourceFactory {
// 与UnpooledDataSourceFactory的不同之处是,其初始化的DataSource为PooledDataSource
public PooledDataSourceFactory() {
this.dataSource = new PooledDataSource();
}
}
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String username, String password)
throws SQLException;
}
DataSource最主要的几个实现类内容都比较多,代码就不贴出来咯,感兴趣的同学可以到我的源码分析专题中看到详细解析,地址:
https://github.com/doocs/source-code-hunter
tips:什么时候该用简单工厂模式?什么时候该用工厂方法模式呢?
个人认为,工厂方法模式符合“开闭原则”,增加新的产品类不用修改代码,应当优先考虑使用这种模式。如果产品类结构简单且数量庞大时,还是使用简单工厂模式更容易维护些,如:上百个按钮类。
抽象工厂模式
个人理解
设计结构上与“工厂方法”模式很像,最主要的区别是,工厂方法模式中 一个子工厂只对应一个具体的产品,而抽象工厂模式中,一个子工厂对应一组具有相关性的产品,即,存在多个获取不同产品的方法。这种设计模式也很少见人用,倒是“工厂方法”模式见的最多。
简单实现
public abstract class AbstractFactory {
abstract protected AbstractProductA createProductA();
abstract protected AbstractProductB createProductB();
}
public class ConcreteFactory1 extends AbstractFactory {
@Override
protected AbstractProductA createProductA() {
return new ProductA1();
}
@Override
protected AbstractProductB createProductB() {
return new ProductB1();
}
}
public class ConcreteFactory2 extends AbstractFactory {
@Override
protected AbstractProductA createProductA() {
return new ProductA2();
}
@Override
protected AbstractProductB createProductB() {
return new ProductB2();
}
}
public class Client {
public static void main(String[] args) {
AbstractFactory factory = new ConcreteFactory1();
AbstractProductA productA = factory.createProductA();
AbstractProductB productB = factory.createProductB();
...
// 结合使用productA和productB进行后续操作
...
}
}
JDK中的范例
JDK的javax.xml.transform.TransformerFactory组件使用了类似“抽象工厂”模式的设计,抽象类TransformerFactory定义了两个抽象方法newTransformer()和newTemplates()分别用于生成Transformer对象 和 Templates对象,其两个子类进行了不同的实现,源码如下(版本1.8)。
public abstract class TransformerFactory {
public abstract Transformer newTransformer(Source source)
throws TransformerConfigurationException;
public abstract Templates newTemplates(Source source)
throws TransformerConfigurationException;
}
/**
* SAXTransformerFactory 继承了 TransformerFactory
*/
public class TransformerFactoryImpl
extends SAXTransformerFactory implements SourceLoader, ErrorListener {
@Override
public Transformer newTransformer(Source source) throws TransformerConfigurationException {
final Templates templates = newTemplates(source);
final Transformer transformer = templates.newTransformer();
if (_uriResolver != null) {
transformer.setURIResolver(_uriResolver);
}
return(transformer);
}
@Override
public Templates newTemplates(Source source) throws TransformerConfigurationException {
......
return new TemplatesImpl(bytecodes, transletName,
xsltc.getOutputProperties(), _indentNumber, this);
}
}
public class SmartTransformerFactoryImpl extends SAXTransformerFactory {
public Transformer newTransformer(Source source) throws TransformerConfigurationException {
if (_xalanFactory == null) {
createXalanTransformerFactory();
}
if (_errorlistener != null) {
_xalanFactory.setErrorListener(_errorlistener);
}
if (_uriresolver != null) {
_xalanFactory.setURIResolver(_uriresolver);
}
_currFactory = _xalanFactory;
return _currFactory.newTransformer(source);
}
public Templates newTemplates(Source source) throws TransformerConfigurationException {
if (_xsltcFactory == null) {
createXSLTCTransformerFactory();
}
if (_errorlistener != null) {
_xsltcFactory.setErrorListener(_errorlistener);
}
if (_uriresolver != null) {
_xsltcFactory.setURIResolver(_uriresolver);
}
_currFactory = _xsltcFactory;
return _currFactory.newTemplates(source);
}
}
建造者模式
个人理解
该模式主要用于将复杂对象的构建过程分解成一个个简单的步骤,或者分摊到多个类中进行构建,保证构建过程层次清晰,代码不会过分臃肿,屏蔽掉了复杂对象内部的具体构建细节,其类图结构如下所示。
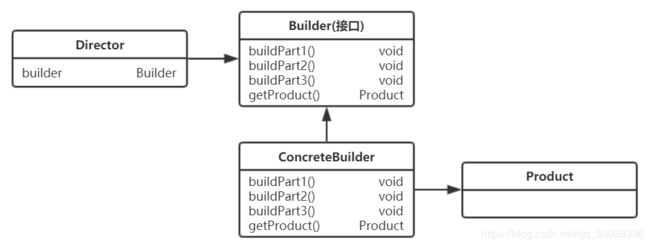
该模式的主要角色如下:
- 建造者接口(Builder):用于定义建造者构建产品对象的各种公共行为,主要分为 建造方法 和 获取构建好的产品对象;
- 具体建造者(ConcreteBuilder):实现上述接口方法;
- 导演(Director):通过调用具体建造者创建需要的产品对象;
- 产品(Product):被建造的复杂对象。
其中的导演角色不必了解产品类的内部细节,只提供需要的信息给建造者,由具体建造者处理这些信息(这个处理过程可能会比较复杂)并完成产品构造,使产品对象的上层代码与产品对象的创建过程解耦。建造者模式将复杂产品的创建过程分散到不同的构造步骤中,这样可以对产品创建过程实现更加精细的控制,也会使创建过程更加清晰。每个具体建造者都可以创建出完整的产品对象,而且具体建造者之间是相互独立的, 因此系统就可以通过不同的具体建造者,得到不同的产品对象。当有新产品出现时,无须修改原有的代码,只需要添加新的具体建造者即可完成扩展,这符合“开放一封闭” 原则。
典型的范例 StringBuilder和StringBuffer
相信在拼SQL语句时大家一定经常用到StringBuffer和StringBuilder这两个类,它们就用到了建造者设计模式,源码如下(版本1.8):
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
/**
* Creates an AbstractStringBuilder of the specified capacity.
*/
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
// 这里完成了对复杂String的构造,将str拼接到当前对象后面
str.getChars(0, len, value, count);
count += len;
return this;
}
}
/**
* @since JDK 1.5
*/
public final class StringBuilder extends AbstractStringBuilder
implements java.io.Serializable, CharSequence {
public StringBuilder() {
super(16);
}
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
}
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
}
/**
* @since JDK 1.0
*/
public final class StringBuffer extends AbstractStringBuilder
implements java.io.Serializable, CharSequence {
/**
* toString返回的最后一个值的缓存。在修改StringBuffer时清除。
*/
private transient char[] toStringCache;
public StringBuffer() {
super(16);
}
/**
* 与StringBuilder建造者最大的不同就是,增加了线程安全机制
*/
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
}
Mybatis中的范例
MyBatis 的初始化过程使用了建造者模式,抽象类 BaseBuilder 扮演了“建造者接口”的角色,对一些公用方法进行了实现,并定义了公共属性。XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder 等实现类扮演了“具体建造者”的角色,分别用于解析mybatis-config.xml配置文件、映射配置文件 以及 SQL节点。Configuration 和 SqlSessionFactoryBuilder 则分别扮演了“产品” 和 “导演”的角色。即,SqlSessionFactoryBuilder 使用了 BaseBuilder建造者组件 对复杂对象 Configuration 进行了构建。
BaseBuilder组件的设计与上面标准的建造者模式是有很大不同的,BaseBuilder的建造者模式主要是为了将复杂对象Configuration的构建过程分解的层次更清晰,将整个构建过程分解到多个“具体构造者”类中,需要这些“具体构造者”共同配合才能完成Configuration的构造,单个“具体构造者”不具有单独构造产品的能力,这与StringBuilder及StringBuffer是不同的。
个人理解的构建者模式 其核心就是用来构建复杂对象的,比如 mybatis 对 Configuration 对象的构建。当然,我们也可以把 对这个对象的构建过程 写在一个类中,来满足我们的需求,但这样做的话,这个类就会变得及其臃肿,难以维护。所以把整个构建过程合理地拆分到多个类中,分别构建,整个代码就显得非常规整,且思路清晰,而且 建造者模式符合 开闭原则。其源码实现如下。
public abstract class BaseBuilder {
/**
* Configuration 是 MyBatis 初始化过程的核心对象并且全局唯一,
* MyBatis 中几乎全部的配置信息会保存到Configuration 对象中。
* 也有人称它是一个“All-In-One”配置对象
*/
protected final Configuration configuration;
/**
* 在 mybatis-config.xml 配置文件中可以使用标签定义别名,
* 这些定义的别名都会记录在该 TypeAliasRegistry 对象中
*/
protected final TypeAliasRegistry typeAliasRegistry;
/**
* 在 mybatis-config.xml 配置文件中可以使用标签添加自定义
* TypeHandler,完成指定数据库类型与 Java 类型的转换,这些 TypeHandler
* 都会记录在 TypeHandlerRegistry 中
*/
protected final TypeHandlerRegistry typeHandlerRegistry;
/**
* BaseBuilder 中记录的 TypeAliasRegistry 对象和 TypeHandlerRegistry 对象,
* 其实是全局唯一的,它们都是在 Configuration 对象初始化时创建的
*/
public BaseBuilder(Configuration configuration) {
this.configuration = configuration;
this.typeAliasRegistry = this.configuration.getTypeAliasRegistry();
this.typeHandlerRegistry = this.configuration.getTypeHandlerRegistry();
}
}
public class XMLConfigBuilder extends BaseBuilder {
/** 标识是否已经解析过 mybatis-config.xml 配置文件 */
private boolean parsed;
/** 用于解析 mybatis-config.xml 配置文件 */
private final XPathParser parser;
/** 标识 配置的名称,默认读取 标签的 default 属性 */
private String environment;
/** 负责创建和缓存 Reflector 对象 */
private final ReflectorFactory localReflectorFactory = new DefaultReflectorFactory();
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 在 mybatis-config.xml 配置文件中查找节点,并开始解析
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
// 解析节点
propertiesElement(root.evalNode("properties"));
// 解析节点
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
// 解析节点
typeAliasesElement(root.evalNode("typeAliases"));
// 解析节点
pluginElement(root.evalNode("plugins"));
// 解析节点
objectFactoryElement(root.evalNode("objectFactory"));
// 解析节点
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
// 解析节点
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
// 解析节点
environmentsElement(root.evalNode("environments"));
// 解析节点
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
// 解析节点
typeHandlerElement(root.evalNode("typeHandlers"));
// 解析节点
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
}
public class XMLMapperBuilder extends BaseBuilder {
private final XPathParser parser;
private final MapperBuilderAssistant builderAssistant;
private final Map<String, XNode> sqlFragments;
private final String resource;
public void parse() {
// 判断是否已经加载过该映射文件
if (!configuration.isResourceLoaded(resource)) {
// 处理节点
configurationElement(parser.evalNode("/mapper"));
// 将 resource 添加到 Configuration.loadedResources 集合中保存,
// 它是 HashSet 类型的集合,其中记录了已经加载过的映射文件
configuration.addLoadedResource(resource);
// 注册 Mapper 接口
bindMapperForNamespace();
}
// 处理 configurationElement() 方法中解析失败的节点
parsePendingResultMaps();
// 处理 configurationElement() 方法中解析失败的节点
parsePendingCacheRefs();
// 处理 configurationElement() 方法中解析失败的 SQL 语句节点
parsePendingStatements();
}
private void configurationElement(XNode context) {
try {
// 获取节点的 namespace 属性,若 namespace 属性为空,则抛出异常
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 设置 MapperBuilderAssistant 的 currentNamespace 字段,记录当前命名空间
builderAssistant.setCurrentNamespace(namespace);
// 解析节点
cacheRefElement(context.evalNode("cache-ref"));
// 解析节点
cacheElement(context.evalNode("cache"));
// 解析节点,(该节点 已废弃,不再推荐使用)
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析节点
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析节点
sqlElement(context.evalNodes("/mapper/sql"));
// 解析
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
}
public class XMLStatementBuilder extends BaseBuilder {
private final MapperBuilderAssistant builderAssistant;
private final XNode context;
private final String requiredDatabaseId;
public void parseStatementNode() {
// 获取 SQL 节点的 id 以及 databaseId 属性,若其 databaseId属性值与当前使用的数据库不匹配,
// 则不加载该 SQL 节点;若存在相同 id 且 databaseId 不为空的 SQL 节点,则不再加载该 SQL 节点
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
// 根据 SQL 节点的名称决定其 SqlCommandType
String nodeName = context.getNode().getNodeName();
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// 在解析 SQL 语句之前,先处理其中的节点
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
// 处理节点
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// Parse the SQL (pre: and were parsed and removed)
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String resultType = context.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
String resultMap = context.getStringAttribute("resultMap");
String resultSetType = context.getStringAttribute("resultSetType");
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
if (resultSetTypeEnum == null) {
resultSetTypeEnum = configuration.getDefaultResultSetType();
}
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
String resultSets = context.getStringAttribute("resultSets");
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
}
public class SqlSessionFactoryBuilder {
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
// 读取配置文件
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
// 解析配置文件得到 Configuration 对象,然后用其创建 DefaultSqlSessionFactory 对象
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
}
有被“读过哪些知名的开源项目源码?”这种问题所困扰过吗?加入我们,一起通读互联网公司主流框架及中间件源码,成为强大的“源码猎人”,目前开放的有 Spring 系列框架、Mybatis 框架、Netty 框架,及Redis中间件等,让我们一起开拓新的领地,揭开这些源码的神秘面纱。本项目主要用于记录框架及中间件源码的阅读经验、个人理解及解析,希望能够使阅读源码变成一件更简单有趣,且有价值的事情,抽空更新中…(如果本项目对您有帮助,请watch、star、fork 素质三连一波,鼓励一下作者,谢谢)地址:
https://github.com/doocs/source-code-hunter