【Python | 杂代码】从0爬妹子图片教程,难道我也下海了?
往期精彩:
100多g Python 学习资源分享:
以前的爬虫文章:
下期分享预告:100多G精选Java学习资源(本周六)
前言:
正规妹纸图片网站、58同城房源信息、微信公众号文章,
分三期推送给大家
今天就是第一期:正规妹纸图片网站
本次爬虫主要用到的技术为:正则表达式基础学习链接
1.1 获取页面信息
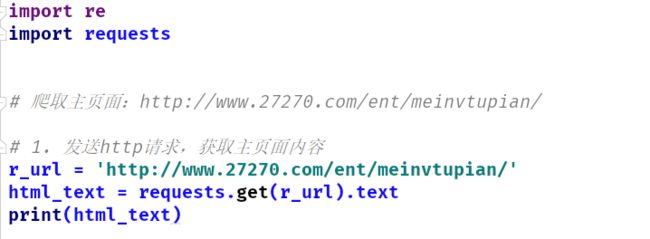
代码截图
1.2 发现获取页面内容出现乱码
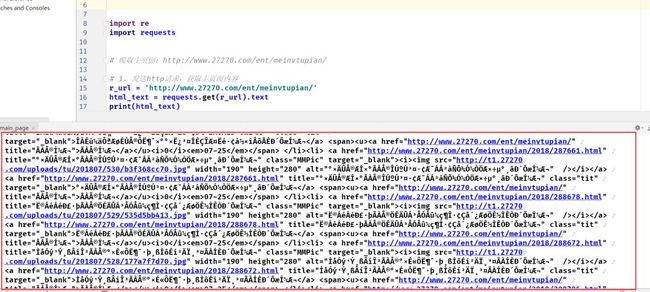
运行获取页面源码乱码截图
1.3 分析页面信息得原页面编码为:`gb2312`,修改获取内容编码
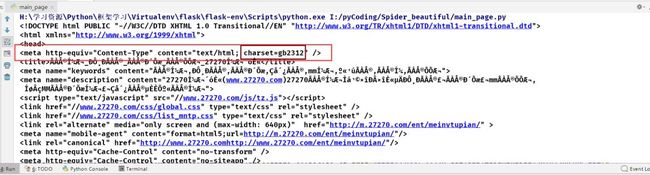
分析页码源码乱码
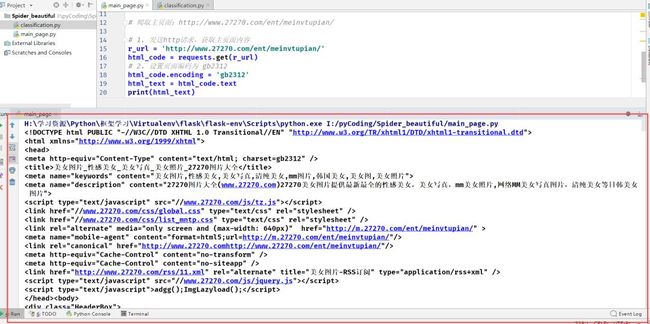
解决源码乱码情况
2.1 主页面源码已经获取到了,那我们到网页里看看源码的效果图吧

爬取页面web端效果图 有没有让你看的怦然心动,我是觉得清纯的妹纸挺好的。
2.2 爬取方式:简单 or 困难
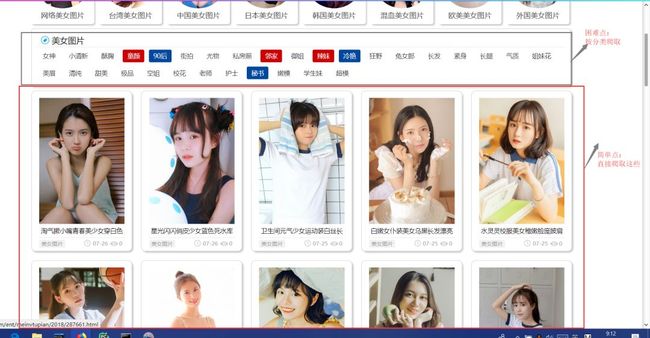
爬取方式分析
3.1 从简单开始
:首先我们要获取这个页面上的所有妹纸图的链接(一个妹纸有多张艺术照),然后向网站发送相应链接的请求,浏览器内按F12,进入开发者模式,小箭头选择想要的信息所在处。
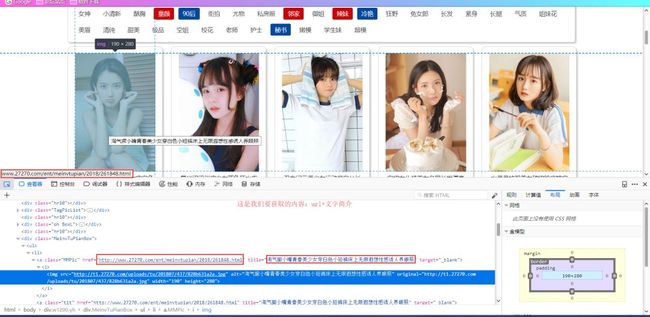
页面分析获取内容所在
3.2 分析我们拿到的页面源码,采用正则表达式获取相关内容

源码分析采用什么正则匹配
3.3 正则表达式获取首页所有妹纸图的网址和简介
1'''
2author : 极简XksA
3data : 2018.8.8
4goal : 分类爬取beautiful picture,保存到本地
5'''
6import re
7import requests
8# 爬取主页面:http://www.27270.com/ent/meinvtupian/
9
10# 1. 发送http请求,获取主页面内容
11r_url = 'http://www.27270.com/ent/meinvtupian/'
12html_code = requests.get(r_url)
13# 2. 设置页面编码为 gb2312
14html_code.encoding = 'gb2312'
15html_text = html_code.text
16# 3.1 获取链接
17pattern01 = r'.*? 美女图片'
18beautiful_url = re.findall(pattern01, html_text)
19print(beautiful_url)
20print(len(beautiful_url))
21# 3.2 获取简介
22pattern02 = r' 运行结果:
1['http://www.27270.com/ent/meinvtupian/2018/261848.html', 'http://www.27270.com/ent/meinvtupian/2018/263409.html', 'http://www.27270.com/ent/meinvtupian/2018/287594.html', 'http://www.27270.com/ent/meinvtupian/2018/287661.html', 'http://www.27270.com/ent/meinvtupian/2018/288678.html', 'http://www.27270.com/ent/meinvtupian/2018/288672.html', 'http://www.27270.com/ent/meinvtupian/2018/288706.html', 'http://www.27270.com/ent/meinvtupian/2018/288728.html', 'http://www.27270.com/ent/meinvtupian/2018/288734.html', 'http://www.27270.com/ent/meinvtupian/2018/288683.html', 'http://www.27270.com/ent/meinvtupian/2018/288712.html', 'http://www.27270.com/ent/meinvtupian/2018/288688.html', 'http://www.27270.com/ent/meinvtupian/2018/287365.html', 'http://www.27270.com/ent/meinvtupian/2018/287488.html', 'http://www.27270.com/ent/meinvtupian/2018/287638.html', 'http://www.27270.com/ent/meinvtupian/2018/287752.html', 'http://www.27270.com/ent/meinvtupian/2018/288005.html', 'http://www.27270.com/ent/meinvtupian/2018/288042.html', 'http://www.27270.com/ent/meinvtupian/2018/288003.html', 'http://www.27270.com/ent/meinvtupian/2018/287595.html', 'http://www.27270.com/ent/meinvtupian/2018/288074.html', 'http://www.27270.com/ent/meinvtupian/2018/287760.html', 'http://www.27270.com/ent/meinvtupian/2018/287670.html', 'http://www.27270.com/ent/meinvtupian/2018/287816.html', 'http://www.27270.com/ent/meinvtupian/2018/287719.html', 'http://www.27270.com/ent/meinvtupian/2018/288068.html', 'http://www.27270.com/ent/meinvtupian/2018/288052.html', 'http://www.27270.com/ent/meinvtupian/2018/288001.html', 'http://www.27270.com/ent/meinvtupian/2018/261655.html', 'http://www.27270.com/ent/meinvtupian/2018/261864.html']
230
3['淘气撅小嘴青春美少女穿白色小短裤床上无限遐想性感诱人养眼照', '星光闪闪俏皮少女蓝色死水库连衣裙展现娇小玲珑身材图片', '卫生间元气少女运动装白丝长腿俏皮碎发嘟嘴卖萌写真图片', '白嫩女仆装美女乌黑长发漂亮侧颜居家制作蛋糕写真图片', '水灵灵校服美女稚嫩脸庞披肩短发清纯气质教室写真图片', '体育馆高马尾美女白色运动服高挑身材细长美腿写真图片', '芭蕾舞美女高束发髻吊带舞蹈服柔软身体翩翩起舞写真图片', '露齿大笑美女微卷短发牛仔背带裤精致锁骨床上甜美写真图片', '楼梯口美女浓眉大眼碎花吊带裙白里透红气质端庄写真图片', '马尾少女上扬的嘴角纤纤玉指穿运动服清爽诱人写真', '扎两小辫极品白丝袜美女美腿裸肩黄色系闺房写真', '美乳小翘臀白色吊带美女双眼灵动纯净甜美私房写真图片', '丸子头舞蹈美女吊带芭蕾装光滑裸背修长美腿身姿轻盈写真图片', '黑长直发美女橘色背心睡裙粉嫩香唇小巧鹅蛋脸迷人写真图片', '眼镜美女死水库泳衣笔直长腿精致锁骨曲线柔美私房写真图片', '露齿甜笑美少女白衣短裤空气刘海眉清目秀温柔气质写真图片', '床上白嫩香肩美女唇红齿白蕾丝吊带纤细长腿慵懒写真图片', '狐媚眼性感熟女红唇微张吊带睡衣雪白肌肤春光乍泄写真图片', '樱桃小嘴美女学生学院风校服可爱麻花辫皮肤光滑写真图片', '薄纱遮玉体大胸美眉美乳圆润有弹性红唇点睛诱惑写真', '好看的柠檬少女肌肤如牛奶般丝滑白嫩治愈系写真图片', '浓眉大眼童颜美女蕾丝套装白丝大长腿搞怪卖萌私房写真图片', '小巧脸蛋美女萝莉休闲运动服高束马尾柔软身段活力写真图片', '丸子头泳衣美女明眸皓齿白皙藕臂修长玉腿开怀大笑写真图片', '碎花裙治愈系少女清澈大眼精致编发温暖笑容闺房写真图片', '灿烂甜笑美女浓密卷发粉嫩脸蛋白瓷肌肤吹弹可破写真图片', '居家美女条纹吊带短裤秀圆润香肩光滑美腿吃西瓜写真图片', '尖下巴美女学生妹俏皮马尾辫小清新水手制服户外写真图片', '运动型美女白嫩肌肤撩长发骚动人心高清图片', '玉体通透吊带美女可爱苹果头好俏皮逆光唯美写真']
430
3.4 请求单个页面,正则匹配图片url
3.4.1 页面分析
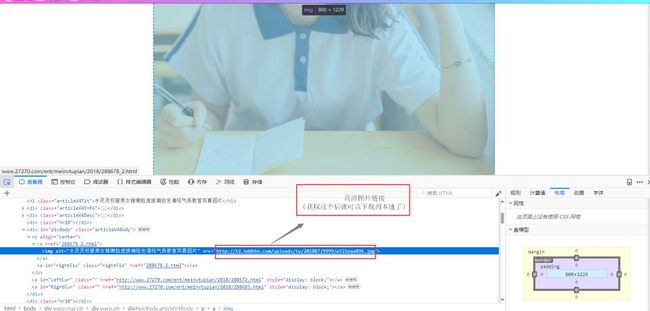
单组照片页面分析
3.4.2 代码实现
1for i in range(len(beautiful_url)):
2 # 4.1 请求单个页面
3 picture_codes = requests.get(beautiful_url[i])
4 picture_codes.encoding = 'gb2312'
5 picture_words = picture_codes.text
6 # 4.2 在页面中找到图片url
7 # print(picture_words)
8 pattern03 = r'3.4.3 运行结果
1# 这里获取的并不是全部,而是每个妹纸的第一张图
2['http://t2.hddhhn.com/uploads/tu/201803/9999/f45065ed61.jpg'],['http://t2.hddhhn.com/uploads/tu/201803/9999/9126579004.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/320ab4622e.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/1fde4d7a1f.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/ef21eaa896.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/e1697062d3.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/419c69bec1.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/4302dc643c.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/df7ff261b0.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/b7b870636f.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/11ec3cf8b2.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/10a0a11a02.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/53e4e2717c.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/7431e6e040.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/228cf34f62.jpg'],
3['http://t2.hddhhn.com/uploads/tu/201807/9999/a9b7d62201.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/ba91f1e60e.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/76da610fa9.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/3ed260e5ae.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/3d93b5fd09.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/280277b310.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/b69662e2d9.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/fbf7a9178b.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/3f9a20a7da.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/691c12fa18.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/249d3362c4.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/29ea1b5fb7.jpg'],['http://t2.hddhhn.com/uploads/tu/201807/9999/db087ab231.jpg'],['http://t2.hddhhn.com/uploads/tu/201803/9999/1a9b5f8522.jpg'],['http://t2.hddhhn.com/uploads/tu/201803/9999/9b597acb26.jpg']
3.5 每个妹纸页面内翻页,爬取所有的图片地址
3.5.1 页面分析
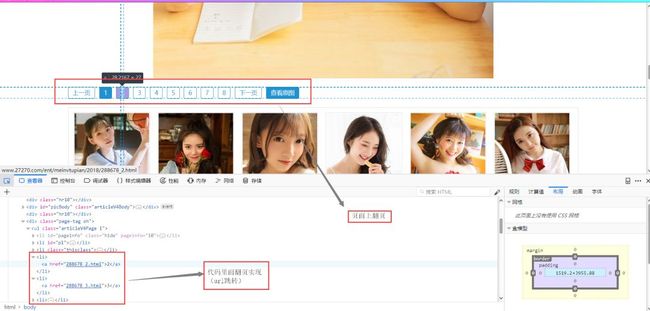
页面翻页分析 我们只用获取网页内代码即可实现页面翻转(即跳转url)
3.5.2 代码实现
1# 4.3 翻页爬取
2# 4.3.1 获取翻页链接
3pattern04 = r".*? 3.5.3 运行结果
1['261848_2.html', '261848_3.html', '261848_4.html', '261848_5.html', '261848_6.html', '261848_7.html', '261848_8.html']
23.6 下载图片
3.6.1 专门写个下载图片函数
1# 下载图片函数
2'''
3folder_name : 分类文件夹名称,按图片简介
4picture_address : 一组图片的链接
5'''
6def download_pictures(folder_name, picture_address):
7 file_path = r'G:\Beautiful\{0}'.format(folder_name)
8 if not os.path.exits(file_path):
9 # 新建一个文件夹
10 os.mkdir(os.path.join(r'G:\Beautiful', folder_name))
11 # 下载图片保存到新建文件夹
12 for i in range(len(picture_address)):
13 # 下载文件(wb,以二进制格式写入)
14 with open(r'G:\Beautiful\{0}\0{1}.jpg'.format(folder_name,i+1), 'wb') as f:
15 # 根据下载链接,发送请求,下载图片
16 response = requests.get(picture_address[i][0])
17 f.write(response.content)
3.6.2 运行结果
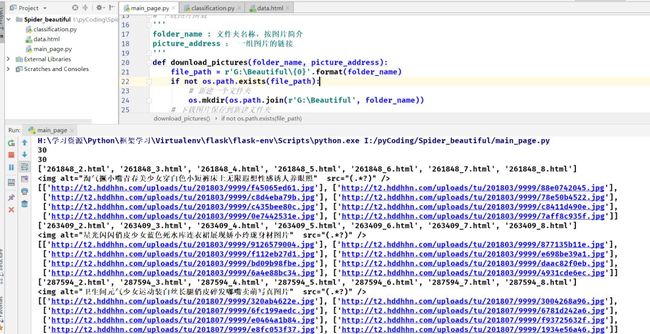
运行结果
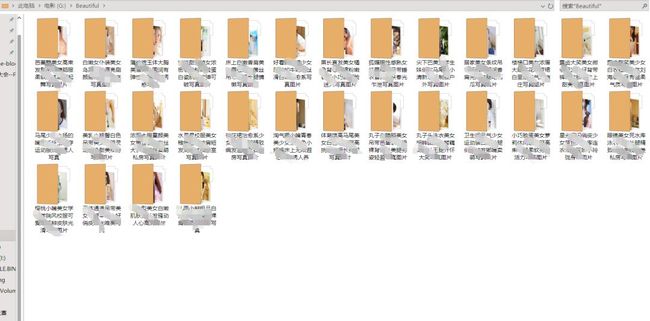
爬取结果(文字有点露骨)
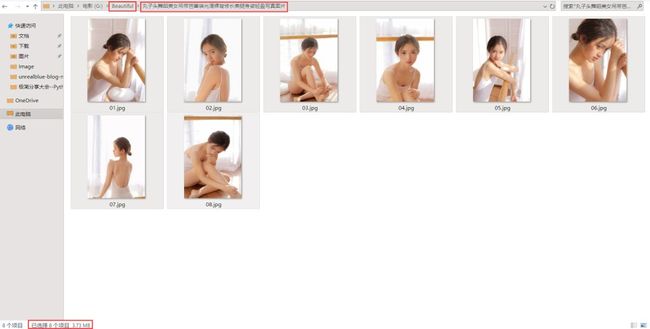
单组皂片示例,看图片大小,挺清晰的
4. 上面只是爬取了主页面的所有妹纸图片,如何实现在主页面翻页呢?
希望大家根据在单个妹子网页翻页的方法(3.5),自己动手写出如何在主页面翻页,爬取更多妹纸图!
实现下图页面翻页
主页面翻页 最后留上源码地址
https://gitee.com/ShaErHu/spider_beautiful_picture
