Logistic回归,优化求解
Logistic回归的目标函数
Logistic回归的损失函数采用Logistic损失/交叉熵损失:
![]()
其中y为真值,μ(x)为预测值为1的概率。
同其他机器学习模型一样,Logistic回归的目标函数也包括两项:
训练集上的损失和+正则项
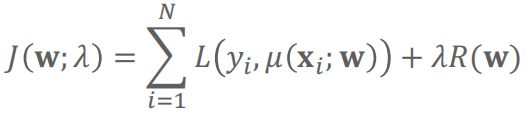
同回归任务,正则项R(w)可为L1正则,L2正则,L1正则+L2正则。
目标函数的最优解
给定正则参数(超参数)λ的情况下,目标函数最优解:

最优解的必要条件:一阶导数为0

同线性回归模型不同,Logistic回归模型的参数无法用解析求解法求得最优解,可采用迭代法求解:
一阶近似:梯度相关(梯度下降、随机梯度下降(SGD)、随即平均梯度法(SAG)、随机平均梯度法改进版(SAGA)、共轭梯度、坐标轴下降)
二阶近似:牛顿法及拟牛顿法(BFGS、LBFGS)
梯度
训练集上的损失函数和部分:
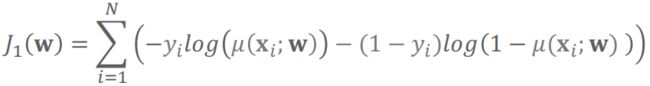
记![]()
梯度:![]()
形式同线性回归模型

牛顿法求解Logistic损失函数和的极小值:IRLS
梯度为:![]()
Hessian矩阵为:
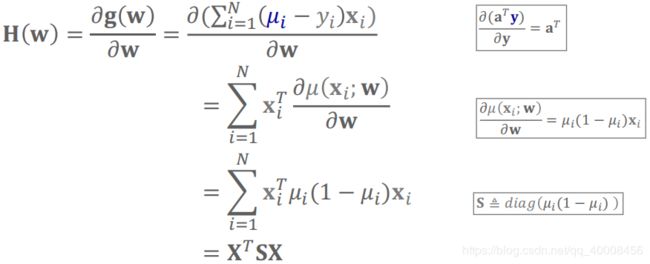
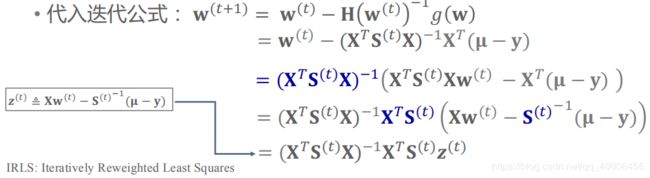
最小二乘:![]()
加权最小二乘(每个样本的权重为![]() ):
):![]()
IRLS代入迭代公式为:![]()
加权最小二乘又通过共轭梯度法求解,因此Scikit-Learn中的采用牛顿法求解的算法取名为“Newton-CG”。
Logistic回归优化求解
Logistic回归优化求解由多种方法。
L2正则函数连续,可采用所有优化方法。
由于L1正则函数不连续,所以需要梯度/Hessian矩阵的方法不适用。类似Lasso求解,可采用坐标轴下降法。
Scikit-Learn中实现Logistic回归的类
class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’liblinear’, max_iter=100, multi_cla ss=’ovr’, verbose=0, warm_start=False, n_jobs=1)
参数solver表示优化算法,可选:
1、liblinear:使用开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数,支持L1正则和L2正则。
2、lbfgs:拟牛顿法,只支持L2正则。
3、newton-cg:牛顿法(每个大迭代中的加权最小二乘回归部分采用共轭梯度算法实现),只支持L2正则。
4、sag:随机平均梯度下降,梯度下降法的变种,适合于样本数据多(如大于5万)的时候,只支持L2正则。
5、saga:改进的随机平均梯度下降,支持L1正则。
L1正则:liblinear,如果模型的特征非常多,希望一些不重要的特征系数归零,从而让模型系数稀疏的话,可以使用L1正则化。liblinear适用于小数据集。
L1正则:saga,当数据量较大,且选择L1,只能采用saga。
L2正则:liblinear,liblinear只支持多累Logistic回归的OvR,不支持多项分布损失(MvM),但MvM相对准确。
L2正则:lbfgs/newton-cg/sag,较大数据集,支持OvR和MvM两种多类Logistic回归。
L2正则:sag/saga,如果样本量非常大,支持OvR和MvM两种多类Logistic回归。
对于大数据集,考虑使用SGDClassifier,并使用logloss。(类似回归中的SGDRegressor)
sag/saga只在特征尺度大致相等时才能保证收敛,需对数据做缩放(如标准化)