python实践学习记录---day10.21
python实践学习记录---day10.21
- 学习内容
- 源代码及解析
学习内容
今天主要学习了如何安装IDE环境,如何安装python和pycharm软件,如何使用pycharm创建python项目。今天的实验主题是利用python实现网页的数据获取,老师给我们介绍了程序的基本流程图,并为我们示范了程序代码以及相应代码的功能。
流程图:
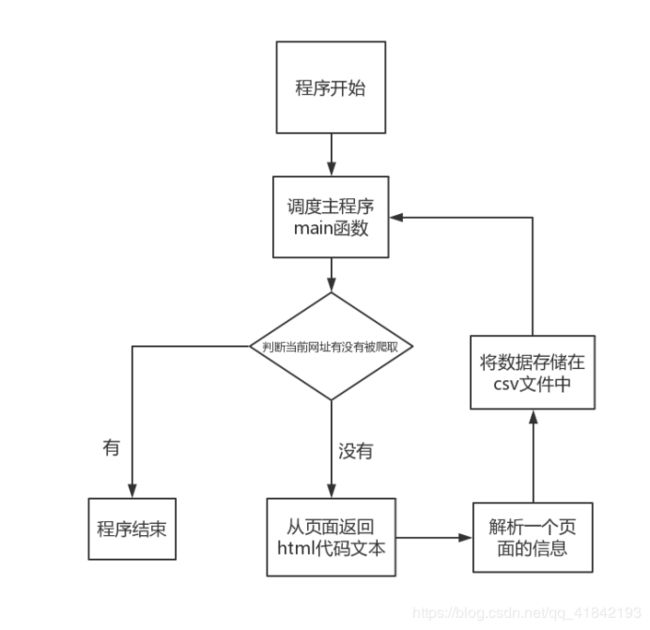
源代码及解析
import csv
import re
import requests
from requests import RequestException
#1.主程序
def main():
# 将猫眼电影网址设为起始url
start_url=“http://maoyan.com/board/4”
# 从0到100取数,间隔为10,100不取到
for i in range(0,100,10):
# 获取每个页面的响应文本内容
html = get_one_page(url=start_url, offset=i)
#当数据为空,如果数据没有连接网络,就抛出异常
if html is None:
print(“可能没有连接网络,请检查网络连接”)
continue
pass
#进行数据解析并数据存储
for item in parse_one_page(html=html):
store_data(item) #存储对象到csv文件中
download_thumb(item[“title”],item[“thumb”])
pass
pass
pass
#2.获取单个页面的内容
#请求一个页面返回响应内容
def get_one_page(url,offset):#@url:页面网址;offset:页面序号
try:
#200:响应成功;404:没有找到网址路径;500:代码语法问题
#获取报文
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36’}
response = requests.get(url=url, headers=headers,params={“offset”:offset})
if response.status_code==200:
return response.text #返回html文本源码
pass
else:
return None
pass
pass
except RequestException as e:
return None
pass
pass
#3.页面解析
#解析一个页面
def parse_one_page(html):
#页面中每个影片的dd信息
pattern = ‘
'(.?)
# re.S匹配多行
regex = re.compile(pattern, re.S)
items = regex.findall(html)
for item in items:
yield { #即直接认为return - 迭代器
‘index’: item[0],
‘thumb’: get_large_thumb(item[1]),
‘title’: item[2],
‘actors’: item[3].strip()[3:],
‘release_time’: get_release_time(item[4].strip()[5:]),
‘area’: get_release_area(item[4].strip()[5:]),
‘score’: item[5] + item[6]
}
pass
pass
#获取上映时间
def get_release_time(data):
pattern = ‘^(.*?)((|$)’
regex = re.compile(pattern)
w = regex.search(data)
return w.group(1)
#获取上映地区
def get_release_area(data):
pattern = ‘.((.))’
regex = re.compile(pattern)
w = regex.search(data)
if w is None:
return’未知’
return w.group(1)
#获取封面大图
def get_large_thumb(url):
pattern = ‘(.?)@.?’
regex = re.compile(pattern)
w = regex.search(url)
return w.group(1)
#存储数据
def store_data(item):
with open(‘movie.csv’,‘a’,newline=’’,encoding=‘utf-8’) as data_csv:
# dialect为打开csv文件的方式,默认是excel,delimiter="\t"参数指写入的时候的分隔符
try:
csv_writer = csv.writer(data_csv)
csv_writer.writerow([item[‘index’], item[‘thumb’], item[‘title’], item[‘actors’],item[‘release_time’],item[‘area’],item[‘score’]])
except Exception as e:
print(e)
print(item)
#下载封面图
def download_thumb(title,url):
try:
response = requests.get(url=url)
# 获取二进制数据
with open(‘thumb/’+title+’.jpg’, ‘wb’) as f:
f.write(response.content)
f.close()
except RequestException as e:
print(e)
pass
if name == ‘main’:
main()
print(“爬取完成!”)
pass