算法导论详解(1) 第二章算法基础+python实现
第二章 算法基础
伪码说明
数组A[1,…,n]长度为n的待排序序列。
注意,书中的下标都是从1开始的。python中是从0开始的。伪码中,A的长度用A.length表示。python中使用len(A)表示。
- 缩进表示块结构。提高代码清晰度。
- while, for, repeat-until 在循环结束后,循环计数器仍然保持其值。
- 符号“//”后面是注释。
- 数组元素通过“数组名[下标]”这样的形式来访问。
- 复合数据通常被组织成对象,对象又由属性组成。
- return允许返回多个值
- 按值把参数传递给过程,被调用过程接收其参数自身的副本。
- 布尔运算符“and”和“or”都是短路的。
2.1 插入排序
插入排序的Python实现:
# author: http://blog.csdn.net/qwerty200696
def insertion_sort(A):
length = len(A)
for j in range(1, length):
key = A[j]
i = j - 1
while i >= 0 and A[i] > key:
A[i + 1] = A[i]
i = i - 1
A[i + 1] = key
return A
A = [5, 3, 19, 1, 8, ]
print(insertion_sort(A))对插入排序的简单理解:
从第二个数开始,依次比较前面的数和key的大小,若大于key,则后移。
最后将key插入到最前方停下的位置。
j是遍历数组每个元素;
i是每个元素前面、需要移动的最前方。
形象的解释:插入纸牌:key是当前带插入的牌,找到插入的位置,先把每个大的都往后挪一个位置出来,再把key插入到空出来的位置。
2.2 分析算法
RAM(Random-access machine,RAM)模型:单处理器计算模型,指令一条接一条地执行,没有并发操作。
真实计算机如何设计,RAM模型就是如何设计的,RAM模型包含真实计算机的常见指令:算术指令(加减乘除,取余,向下取整,向上取整),数据移动指令(装入、存储和复制)和控制指令(条件与无条件转移、子程序调用与返回)。
灰色区域:真实计算机中未列出的指令。如指数运算算是常量时间的指令吗?
答案:①一般情况下不是,如 xy ,当x和y都是实数的时候。②在受限情况下,可以当做一个常量时间的操作。如 2k 是一个常量的操作。
一个整数的各位左移k位等价于将该整数乘以 2k 。
插入排序算法的分析
算法需要的时间与输入规模同步增长,通常把一个程序的运行时间描述成其输入规模的函数。
输入规模的最佳概念依赖于研究的问题。
一个算法在特定输入上的运行时间是指执行的基本操作数或步数。
算法的运行时间是执行每条语句的运行时间之和。
若数组已排好序,则出现最佳情况: T(n)=an+b
若数组已反向排序(即按递减序排好序),则导致最坏情况: T(n)=an2+b ,是n的二次函数。
最坏情况与平均情况分析
本书往往集中于只求最坏情况运行时间,即对于规模为n的任何输入,算法的最长时间。
书中给出了三个理由,在此不详述。其中一点是平均情况往往与最坏情况一样差。
增长量级
最坏情况运行时间表示为: T(n)=an2+b 。
现在我们做出一种更简化的抽象:我们真正感兴趣的运行时间的 增长率 或 增长量级 。
2.3 设计算法
2.3.1 分治法
许多算法在结构上是递归的,算法依次或多次递归地调用其自身以解决紧密相关的若干子问题。
分治模式在每层递归时都有三个步骤:
- 分解原问题为若干子问题;
- 解决这些子问题,递归地求解各子问题。
- 合并这些子问题的解成原问题的解。
归并排序算法完全遵循分治模式。归并算法的关键在于合并。
归并排序的的基本步骤如下:
1. 把待排序的数组分为左数组和右数组
2. 对左数组和右数组进行迭代排序
3. 将左数组和右数组进行合并
显然这些基本步骤符合分治模式在每一层递归上的三个步骤:分解、解决、合并。
2.3.2 归并排序算法(分治算法)
MERGE(A,p,q,r):完成合并。A是一个数组,p,q,r是数组的下标,满足 p⩽q<r 。假设A[p..q]与A[q+1..r]都已排好序,MERGE函数的目的就是合并这两个子数组形成单一的已排好序的数组A[p..r]。
形象地描述:同样以插入排序时的扑克牌为例,现在的情况是有两堆牌(两个输入堆),牌面朝上(可见,已排序),每次选取两堆中较小的放入到输出堆,牌面朝下。重复这个步骤,直到一个输入堆为空,则把另一个输入堆直接牌面朝下的放置到输出堆。
MERGE-SORT(A,p,r)排序子数组A[p,r]中的元素。若 p⩾r ,则该子数组最多只有一个元素,所以已经排好序,直接返回。否则,分解步骤。计算下表q,将A[p..r]分为A[p..q]和A[q+1..r]。
# author: http://blog.csdn.net/qwerty200696
from math import floor
MAX = 1 << 31
def merge(A, p, q, r):
n1 = q - p + 1
n2 = r - q
L = []
R = []
for i in range(0, n1):
L.append(A[p + i]) # 因为我初始化为空列表,所以直接赋值的话会报错,只能以append的形式追加值。
for i in range(0, n2):
R.append(A[q + i + 1])
L.append(MAX) # 使用无穷大作为哨兵
R.append(MAX)
assert len(L) == n1 + 1 and len(R) == n2 + 1
i = 0 # python是从0开始
j = 0
for k in range(p, r + 1): # 需要加1,因为首尾每个都算
if L[i] <= R[j]:
A[k] = L[i]
i += 1
else:
A[k] = R[j]
j += 1
def merge_sort(A, p, r):
if p < r:
q = floor((p + r) / 2)
merge_sort(A, p, q)
merge_sort(A, q + 1, r) # 首尾都包含了,所以要加1
merge(A, p, q, r)
if __name__ == "__main__":
# test function
A = [1, 3, 5, 2, 4, 6, 0, -1, 5]
merge_sort(A, 0, len(A) - 1)
print(A)上述代码测试成功。
2.3.2 分析分治算法
假设把原问题分解为a个子问题,每个子问题的规模都是原问题的1/b。(对于归并排序,a和b都是2,然而在许多分治算法中, a≠b 。)
求解规模为n/b的子问题,需要 T(n/b) 的时间,所以需要花费 aT(n/b) 的时间来求解a个子问题。
下面分析归并排序n个数的最坏情况运行时间 T(n) 的递归式。
- 分解:分解步骤只计算子数组的中间位置,需要常量时间,因此, D(n)=Θ(n)
- 解决:递归地求解两个规模为n/2的子问题,将贡献 2T(n/2) 的运行时间。
- 合并:n个子元素的数组上的merge需要 Θ(n) 的时间(线性复杂度),所以 C(n)=Θ(n) 。
D(n) 和 C(n) 相加的和,仍然是n的线性复杂度,即 Θ(n) 。再与“解决”步骤相加,为:
在第四章,我们将看到“主定理”,可以用该定理来证明 T(n) 为 Θ(nlgn) 。(即时间复杂度为n*lgn)
运行时间为 Θ(nlgn) 的归并排序优于运行时间为 Θ(n2) 的插入排序。
T(n)=Θ(nlgn) 的直观理解:
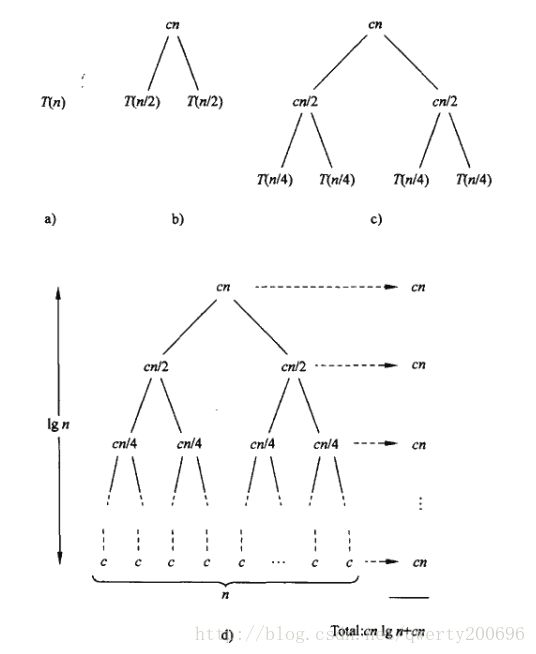
由(d)图,每层对n等分,可以展开为lgn层(再加上原来的一层,一共lgn+1层)。每层的复杂度都是cn,所以总的复杂度为 cnlgn+cn=cn(lgn+1) 。