- 顺序存储与哈希索引
- SSTable和LSM tree
- B-Tree
- 存储结构的比对
- 小结
本篇主要讨论的是不同存储结构(主要是LSM-tree和B-tree),它们应对的不同场景,所采用的底层存储结构,以及对应用以提升效率的索引。
所谓数据库,最基础的功能,就是保存数据,并且在需要的时候可以方便地检索到需要的数据。在这个基础上,演化出了不同的数据库系统,以及多种索引机制帮助检索数据。这篇我们就来讨论几种常见的数据存储和索引机制,主要是B-tree,LSM-Tree,以及它们对应的优缺点。
顺序存储与哈希索引
试想一下,如果按照保存数据,并且在需要的时候可以方便地检索到需要的数据这一标准,设计一个简单的数据库,那么最简单的做法应该怎么做呢?
最简单的做法,就是通过顺序保存数据到一个日志文件中。然后通过索引,这里以哈希索引为例(比如java的hashMap),记录每条数据的key以及对应的位移,将其保存到内存中,避免随机检索巨大的开销。值得注意的是,引入索引,虽然会显著提高查询效率,但会略微降低写入速度。因为每次写入的时候都需要额外写入到哈希索引中,这一点对大部分索引都是适用的。

上图为哈希索引示例,下面是顺序存储在磁盘上是日志数据,上面的内存中的哈希索引。哈希索引是很多复杂索引的基础,比如在mysql中就有提供哈希索引的选项,当然哈希索引并不常用,因为它最基础,同时也意味着它最容易被优化。
上述形式的顺序存储+哈希索引中,增加数据和查找数据相对容易理解,而修改数据则可以通过将新数据追加到文件尾部,重新生成索引实现,删除操作则可以给与哈希索引一个标识符实现(如对应key置为-1)。
但这样有一个问题,可能会出现磁盘耗尽的情况。针对这一个问题,我们可以将日志文件拆分成多个一定大小的文件段(这里的文件段可以理解为接受统一管理的数据文件)。当一个文件段达到一定大小,比如4kb的时候,就关闭它,新建一个文件段。而旧的文件段可以进行压缩,前面提到过,删除和修改都是通过追加日志相同的key-value实现的,那么早先的数据其实就已经没用的,所以压缩的时候只保留最新的key数据。压缩到过程如下面这张图所示:

图中上面的部分就是顺序存储的数据,可以发现其中有很多的key都是相同的,这是因为顺序存储情况下,修改数据就是不断新写入相同的key。这种情况我们要的只有相同key的最新的value。所以压缩过程也是一个清理磁盘的过程。
压缩合并过程可以由后台进行默默进行,所以不必担心这个过程影响查询性能。上图中只有一个数据文件段,但实际上可以有多个文件段,多个文件段也可以合并(类似于Hbase中多个文件的merge操作)。
当然这样的优化可以极大程度节省空间,但必不可少得会给检索带来时间上的损耗。在多个文件段的情况,每个文件段都有自己的哈希索引,故而要查找数据会首先根据key查找内存中最新文件段的哈希索引,如果找不到,那么找次新文件段的哈希索引,接着找次新的哈希索引,直到遍历所有文件段的哈希索引。
综上,顺序存储+哈希索引优点明显,简单,高效。缺点是哈希索引需全部存到内存(如果将哈希索引放到磁盘那相当于放弃了检索的高效),并且难以实现区域查询。
为了解决它的这些问题,我们可以将哈希索引做一些小小的改变。具体来说,就是让文件段的数据,按key进行排序存储。这样会带来哪些改变呢?
SSTable和LSM tree
将数据文件段中的数据按key进行排序,并且保证相同的key只出现一次(在压缩的时候保证),这种格式就称之为排序字符串表,简称SStable(Sorted String Table)。
将数据按Key进行排序后有以下几个好处:
- 合并更加简单高效,即使数据文件段大于内存,也可以使用类似归并排序算法进行数据段的压缩,即将一个大文件拆成多个小数据进行压缩。如果多个文件段中有相同的key,那么以最新的文件段的key为准。
- 缓解哈希索引需要整个hashMap存储到内存的窘境。因为key是排序的,所以可以在内存中维持一个稀疏索引,存储每个key的范围,具体见下图。并且这个稀疏索引所需的内存空间是很小的。
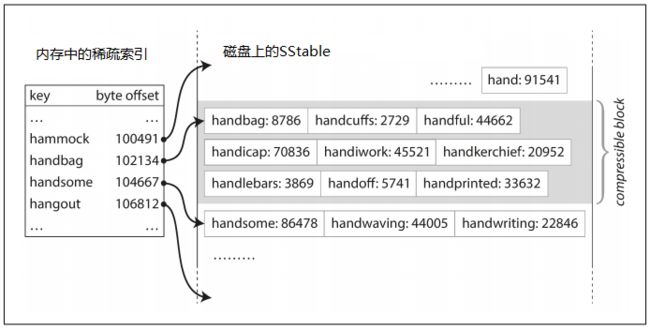
通过稍微改变一下文件段的结果,就获得如此多的好处。但还有一个问题,前面的哈希索引是基于顺序存储的日志文件的,要让SStable按key排序,那就不能顺序存储磁盘了呀(即无法存储的时候立即写入磁盘)!!的确是这样,虽然也可以使用类似B-tree来实现磁盘上的排序存储,但转换下思路,其实将数据先保存在内存中其实更加方便。
具体实现流程,是在内存中维护一个类似TreeMap的数据结构用于存储数据(TreeMap底层是基于红黑树对存储的key进行排序的。无论我们按照什么样的顺序存储数据,TreeMap总是会将数据按照key进行排序)。这个TreeMap称为内存表,当内存表超过一定阈值的时候,就将其写入到磁盘中,成为SStable,因为已经排好序,所以写入的效率其实比想象的要高。后期再对磁盘中的SStable进行压缩与合并操作。
当需要根据key检索的时候,会先去内存表中检索,找不到再去最新的SStable,再去次新的SStable,直到遍历完全部。
上述这种索引结构被称为之LSM-Tree,全称是Log-Structured Merge-Tree,即日志合并树。而这种基于合并和压缩文件原理的存储引擎被称为LSM存储引擎,其中比较为人所知的是Hbase。
B-Tree
最后,我们再来讨论流传最久的数据库村粗结构。与LSM-Tree这几年才逐渐为人所知不同,B-tree存储结构担得起经久不衰这四个字。
B-tree本身是一种树形的数据结构,更具体点说是一颗平衡查找树,它也是通过存储顺序的key存储数据(这一点和SStable有相似之处)。不同于前面的LSM-tree的文件段,B-tree将数据库分解成固定大小的块或页,通常一个页大小是4kb。这种分配方法更加贴合底层的磁盘。
当需要进行查找的时候,总是从根开始,根据范围跳转到对应的key,而其对应的value可以是值本身,也可以是指向存储对应数据的磁盘地址。下图是一个具体的例子:
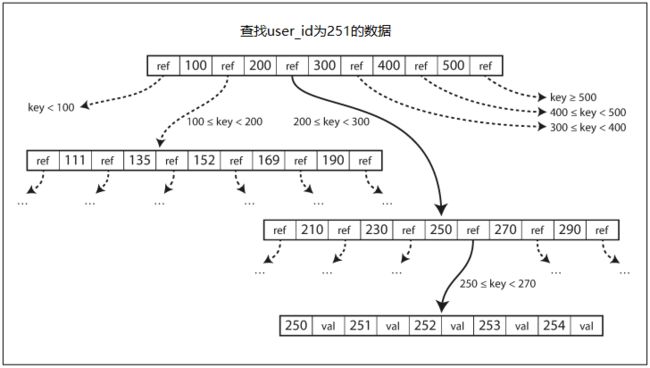
而在更新或插入的时候,有可能会出现没有足够空间来容纳新key的问题,这时候就会发生分裂。分裂操作是比较危险的,在分裂的时候如果数据库崩溃,可能会导致索引被破坏。为了防止这个问题,可以引入预写日志(write-ahead log,WAL)机制。mysql的binlog就是这样的东西。具体说就是在执行操作的时候,将此次操作写入一个只允许追加的文件中,这样一来当崩溃的时候就可以检查日志并进行恢复。
存储结构的比对
从使用的角度上来说,B-tree等索引存储结构多用于OLTP型的数据库,因为这类数据库主要以事务,或是行级别的读取和存储为主的(比如Mysql)。换句话说,这种类型的数据库更多的操作是小批量或单行级别的更新或读取,并且可能还有事务方面的需求,这种类型正是B-tree结构所擅长的。
而 LSM-tree则多用于大规模数据情况下的检索分析和快速写入的情况。在写入的性能上,因为上直接写入内存再定期刷入到磁盘中,所以写入操作对用户的感知而言上非常迅速的。而检索速度也因为key顺序存储,可以快速定位到key对应的位置,因而具有较好的检索性能。
但是LSM-tree比较显著的应用方向还是在大规模分析这方面,在大规模分析(OLAP)场景下,数据通常都是列式存储,并且需要全表扫描。其中磁盘数据可以使用二进制进行压缩,读取的时候可以有效减少磁盘IO的处理时间(与之相比,B-tree等存储结构就无法充分压缩,因为每次都只处理小部分数据)。同时在存储文件中还能再进一步切分,比如将列式数据按照水平切分成不同的Page,同时存储一些简单的索引,用来指定不同Page大概范围,Hadoop的存储数据格式Parquet就是类似的设计。
小结
本篇主要讨论了几种基础的存储结构和索引以及其对应使用场景,限于篇幅,更多索引的变种无法多加讨论,比如B-tree的优化版B+tree,多列索引等。
其实大部分数据库或者说存储引擎,都是针对不同的场景下,在旧有的基础上进行一定程度的微改造创新,但大体的结构依旧是以上述两三种为准,了解了上述几种结构,对数据存储方面应该能够有一个感性的认知了。
此外本章多参考自《DDIA》第三章节,对分布式系统感兴趣的童鞋可以看看此书,肯定不会失望的。
以上~