redis
redis cluster注意的问题 :
1、‘cluster-require-full-coverage’参数的设置。该参数是redis配置文件中cluster模式的一个参数,从字面上基本就能看出它的作用:需要全部覆盖!
具体点是redis cluster需要16384个slot都正常的时候才能对外提供服务,换句话说,只要任何一个slot异常那么整个cluster不对外提供服务。
redis默认是‘yes’,即需要全覆盖!建议设置成‘no’。
2、阻塞命令产生failover。由于一些阻塞命令(flushall, del key1 key2 …)会造成redis在‘cluster-node-timeout’时间内无法响应其他节点的ping请求,
从而导致其他节点都把该redis标记出了pfail状态,进而产生failover。redis作者计划使用lazy redis解决。
3、连接建立。当redis cluster的节点数多了以后,client对每个节点建立一个tcp连接需要花比较多的时间。如果是长连接,用户只需忍受一次连接建立的过程,
如果是短连接,那么频繁建立连接将会极大的降低效率。但即便是短连接,只要每次请求只涉及到一个key,有些客户端可能只需要与一个节点建立连接。
4、Jedis。Jedis是redis最流行的Java客户端,支持redis cluster。
‘MaxRedirectionsException’异常,出现该异常说明刚刚执行的那条命令经过多次重试,没有执行成功,需要用户再次执行。
在cluster扩容或者slot迁移的时候比较容易出现。建议捕获该异常并采取相应重试工作。
Pipeline,Jedis目前不支持cluster模式的pipeline,建议采用多并发代替pipeline。
5、Multi-key。Redis cluster对多key操作有限,要求命令中所有的key都属于一个slot,才可以被执行。客户端可以对multi-key命令进行拆分,再发给redis。
另外一个局限是,在slot迁移过程中,multi-key命令特别容易报错(CROSSSLOT Keys in request don’t hash to the same slot)。建议不用multi-key命令。
6、扩容速度慢。redis官方提供了redis cluster管理脚本redis-trib.rb。使用该脚本进行扩容cluster的时候,是串行的迁移slot中的每个key,这样导致了
扩容的速度非常慢,百G的数据要数小时。扩容时间越长,越容易出现异常。
http://www.ithao123.cn/content-10677390.html
先有鸡还是先有蛋?
最近有朋友问了一个问题,说毕业后去大城市还是小城市?去大公司还是小公司?我的回答都是大城市!大公司!
为什么这么说呢,你想一下,无论女孩男孩找朋友都喜欢找个子高胸大的。同样的道理嘛,「大」总有大的好。
当然,如果你要有能力找一个胸大个子高就更完美了。
Redis 集群简介
Redis 是一个开源的 key-value 存储系统,由于出众的性能,大部分互联网企业都用来做服务器端缓存。Redis 在3.0版本前只支持单实例模式,虽然支持主从模式、哨兵模式部署来解决单点故障,但是现在互联网企业动辄大几百G的数据,可完全是没法满足业务的需求,所以,Redis 在 3.0 版本以后就推出了集群模式。
Redis 集群采用了P2P的模式,完全去中心化。Redis 把所有的 Key 分成了 16384 个 slot,每个 Redis 实例负责其中一部分 slot 。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
Redis 客户端可以在任意一个 Redis 实例发出请求,如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。
随随便便搭建一个集群
安装部署任何一个应用其实都很简单,只要安装步骤一步一步来就行了。下面说一下 Redis 集群搭建规划,由于集群至少需要6个节点(3主3从模式),所以,没有这么多机器给我玩,我本地也起不了那么多虚拟机(电脑太烂),现在计划是在一台机器上模拟一个集群,当然,这和生产环境的集群搭建没本质区别。
我现在就要在已经有安装了 Redis 的一个 CentOS 下开始进行集群搭建,如果你还不是很清楚 Linux 下如何安装 Redis ,可以去看这一篇文章《了解一下 Redis 并在 CentOS 下进行安装配置》。请注意,下面所有集群搭建环境都基于已安装好的 Redis 做的。
1.创建文件夹
我们计划集群中 Redis 节点的端口号为 9001-9006 ,端口号即集群下各实例文件夹。数据存放在 端口号/data 文件夹中。

mkdir /usr/local/redis-cluster cd redis-cluster/ mkdir -p 9001/data 9002/data 9003/data 9004/data 9005/data 9006/data
2.复制执行脚本
在 /usr/local/redis-cluster 下创建 bin 文件夹,用来存放集群运行脚本,并把安装好的 Redis 的 src 路径下的运行脚本拷贝过来。看命令:
mkdir redis-cluster/bin cd /usr/local/redis/src cp mkreleasehdr.sh redis-benchmark redis-check-aof redis-check-dump redis-cli redis-server redis-trib.rb /usr/local/redis-cluster/bin
3.复制一个新 Redis 实例
我们现在从已安装好的 Redis 中复制一个新的实例到 9001 文件夹,并修改 redis.conf 配置。

cp /usr/local/redis/* /usr/local/redis-cluster/9001
注意,修改 redis.conf 配置和单点唯一区别是下图部分,其余还是常规的这几项:
port 9001(每个节点的端口号) daemonize yes bind 192.168.119.131(绑定当前机器 IP) dir /usr/local/redis-cluster/9001/data/(数据文件存放位置) pidfile /var/run/redis_9001.pid(pid 9001和port要对应) cluster-enabled yes(启动集群模式) cluster-config-file nodes9001.conf(9001和port要对应) cluster-node-timeout 15000 appendonly yes
集群搭建配置重点就是取消下图中的这三个配置: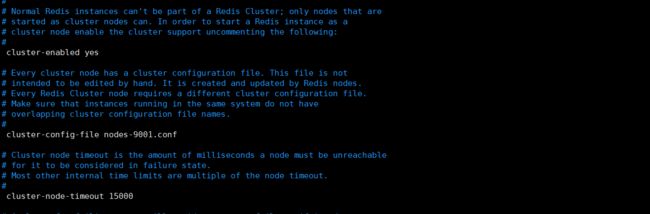
4.再复制出五个新 Redis 实例
我们已经完成了一个节点了,其实接下来就是机械化的再完成另外五个节点,其实可以这么做:把 9001 实例 复制到另外五个文件夹中,唯一要修改的就是 redis.conf 中的所有和端口的相关的信息即可,其实就那么四个位置。开始操作,看图:

\cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9002 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9003 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9004 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9005 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9006
\cp -rf 命令是不使用别名来复制,因为 cp 其实是别名 cp -i,操作时会有交互式确认,比较烦人。
5.修改 9002-9006 的 redis.conf 文件
其实非常简单了,你通过搜索会发现其实只有四个点需要修改,我们全局替换下吧,进入相应的节点文件夹,做替换就好了。命令非常简单,看图:

vim redis.conf :%s/9001/9002g
回车后,就会有替换几个地方成功的提示,不放心可以手工检查下:
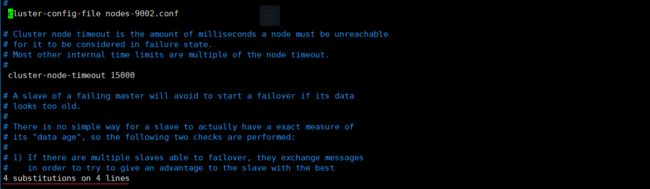
其实我们也就是替换了下面这四行:
port 9002 dir /usr/local/redis-cluster/9002/data/ cluster-config-file nodes-9002.conf pidfile /var/run/redis_9002.pid
到这里,我们已经把最基本的环境搞定了,接下来就是启动了。
其实我们已经几乎搭建好了
1.启动 9001-9006 六个节点
少废话,直接看图: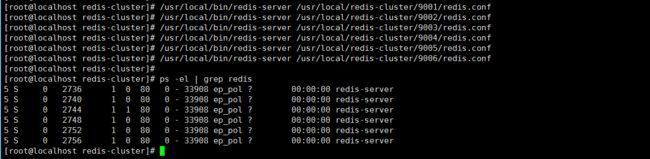
/usr/local/bin/redis-server /usr/local/redis-cluster/9001/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9002/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9003/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9004/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9005/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9006/redis.conf
可以检查一下是否启动成功:ps -el | grep redis
看的出来,六个节点已经全部启动成功了。
2.随便找一个节点测试试
/usr/local/redis-cluster/bin/redis-cli -h 192.168.119.131 -p 9001 set name mafly

连接成功了,但好像报错了阿???(error) CLUSTERDOWN Hash slot not served(不提供集群的散列槽),这是什么鬼?
这是因为虽然我们配置并启动了 Redis 集群服务,但是他们暂时还并不在一个集群中,互相直接发现不了,而且还没有可存储的位置,就是所谓的slot(槽)。
3.安装集群所需软件
由于 Redis 集群需要使用 ruby 命令,所以我们需要安装 ruby 和相关接口。
yum install ruby yum install rubygems gem install redis

这才是真正的创建集群
先不废话,直接敲命令:
/usr/local/redis-cluster/bin/redis-trib.rb create --replicas 1 192.168.119.131:9001 192.168.119.131:9002 192.168.119.131:9003 192.168.119.131:9004 192.168.119.131:9005 192.168.119.131:9006
简单解释一下这个命令:调用 ruby 命令来进行创建集群,--replicas 1 表示主从复制比例为 1:1,即一个主节点对应一个从节点;然后,默认给我们分配好了每个主节点和对应从节点服务,以及 solt 的大小,因为在 Redis 集群中有且仅有 16383 个 solt ,默认情况会给我们平均分配,当然你可以指定,后续的增减节点也可以重新分配。
M: 10222dee93f6a1700ede9f5424fccd6be0b2fb73 为主节点Id
S: 9ce697e49f47fec47b3dc290042f3cc141ce5aeb 192.168.119.131:9004 replicates 10222dee93f6a1700ede9f5424fccd6be0b2fb73 从节点下对应主节点Id
目前来看,9001-9003 为主节点,9004-9006 为从节点,并向你确认是否同意这么配置。输入 yes 后,会开始集群创建。

上图则代表集群搭建成功啦!!!
验证一下:
依然是通过客户端命令连接上,通过集群命令看一下状态和节点信息等。
/usr/local/redis-cluster/bin/redis-cli -c -h 192.168.119.131 -p 9001 cluster info cluster nodes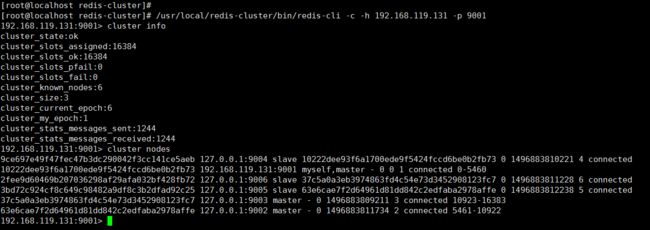
通过命令,可以详细的看出集群信息和各个节点状态,主从信息以及连接数、槽信息等。这么看到,我们已经真的把 Redis 集群搭建部署成功啦!
设置一个 mafly:
你会发现,当我们 set name mafly 时,出现了 Redirected to slot 信息并自动连接到了9002节点。这也是集群的一个数据分配特性,这里不详细说了。

总结一下
这一篇 Redis 集群部署搭建的文章真的是一步一步的走下来的,只要你安装我的步骤来,就保证你能成功搭建一个 Redis 集群玩玩,也可以这么说,除了步骤繁琐外,几乎不存在技术含量,估计能看完的人都感觉累(说真的,写这种文章真的很累人)。
接下来可能就是动态扩容、增加节点和减少节点,重新分配槽大小等,当然,还有最重要的就是怎么和我们程序结合起来,以及如何更好的把 Redis 缓存集群发挥出应有的效果,这些才是最重要的。
http://www.cnblogs.com/mafly/p/redis_cluster.html
redis3.0 cluster功能介绍
redis从3.0开始支持集群功能。redis集群采用无中心节点方式实现,无需proxy代理,客户端直接与redis集群的每个节点连接,根据同样的hash算法计算出key对应的slot,然后直接在slot对应的redis上执行命令。在redis看来,响应时间是最苛刻的条件,增加一层带来的开销是redis不原因接受的。因此,redis实现了客户端对节点的直接访问,为了去中心化,节点之间通过gossip协议交换互相的状态,以及探测新加入的节点信息。redis集群支持动态加入节点,动态迁移slot,以及自动故障转移。
集群架构
每个节点都会跟其他节点保持连接,用来交换彼此的信息。节点组成集群的方式使用cluster meet命令,meet命令可以让两个节点相互握手,然后通过gossip协议交换信息。如果一个节点r1在集群中,新节点r2加入的时候与r1节点握手,r1节点会把集群内的其他节点信息通过gossip协议发送给r2,r2会一一与这些节点完成握手,从而加入到集群中。
节点在启动的时候会生成一个全局的标识符,并持久化到配置文件,在节点与其他节点握手后,这些信息也都持久化下来。节点与其他节点通信,标识符是它唯一的标识,而不是IP、PORT地址。如果一个节点移动位置导致IP、PORT地址发生变更,集群内的其他节点能把该节点的IP、PORT地址纠正过来。
集群数据分布
集群数据以数据分布表的方式保存在各个slot上。默认的数据分布表默认含有16384个slot。
key与slot映射使用的CRC16算法,即:slot = CRC16(key) mod 16384。
集群只有在16384个slot都有对应的节点才能正常工作。slot可以动态的分配、删除和迁移。
每个节点会保存一份数据分布表,节点会将自己的slot信息发送给其他节点,发送的方式使用一个unsigned char的数组,数组长度为16384/8。每个bit标识为0或者1来标识某个slot是否是它负责的。
使用这样的方式传输,就能大大减少数据分布表的字节。这种方式使用的字节为2048,如果纯粹的传递数据分布表,那边一个slot至少需要2字节的slot值+2字节port+4字节ip,共8*16384=131072字节,或者以ip、port为键,把节点对应的slot放在后面,那么也至少需要2*16384加上节点的数量,也远远大于2048字节。由于节点间不停的在传递数据分布表,所以为了节省带宽,redis选择了只传递自己的分布数据。但这样的方式也会带来管理方面的麻烦,如果一个节点删除了自己负责的某个slot,这样该节点传递给其他节点数据分布表的slot标识为0,而redis采用了bitmapTestBit方法,只处理slot为1的节点,而并未把每个slot与收到的数据分布表对比,从而产生了节点间数据分布表视图的不一致。这种问题目前只能通过使用者来避免。
redis目前还支持slot的迁移,可以把一个slot从一个节点迁移到另一个节点,节点上的数据需要使用者通过cluster getkeysinslot去除迁移slot上的key,然后执行migrate命令一个个迁移到新节点。具体细节会在下面的slot迁移章节介绍。
集群访问
客户端在初始化的时候只需要知道一个节点的地址即可,客户端会先尝试向这个节点执行命令,比如“get key”,如果key所在的slot刚好在该节点上,则能够直接执行成功。如果slot不在该节点,则节点会返回MOVED错误,同时把该slot对应的节点告诉客户端。客户端可以去该节点执行命令。目前客户端有两种做法获取数据分布表,一种就是客户端每次根据返回的MOVED信息缓存一个slot对应的节点,但是这种做法在初期会经常造成访问两次集群。还有一种做法是在节点返回MOVED信息后,通过cluster nodes命令获取整个数据分布表,这样就能每次请求到正确的节点,一旦数据分布表发生变化,请求到错误的节点,返回MOVED信息后,重新执行cluster nodes命令更新数据分布表。
在访问集群的时候,节点可能会返回ASK错误。这种错误是在key对应的slot正在进行数据迁移时产生的,这时候向slot的原节点访问,如果key在迁移源节点上,则该次命令能直接执行。如果key不在迁移源节点上,则会返回ASK错误,描述信息会附上迁移目的节点的地址。客户端这时候要先向迁移目的节点发送ASKING命令,然后执行之前的命令。
这些细节一般都会被客户端sdk封装起来,使用者完全感受不到访问的是集群还是单节点。
集群支持hash tags功能,即可以把一类key定位到同一个节点,tag的标识目前支持配置,只能使用{},redis处理hash tag的逻辑也很简单,redis只计算从第一次出现{,到第一次出现}的substring的hash值,substring为空,则仍然计算整个key的值,这样对于foo{}{bar}、{foo}{bar}、foo这些冲突的{},也能取出tag值。使用者需遵循redis的hash tag规范。
127.0.0.1:6379> CLUSTER KEYSLOT foo{hash_tag}
(integer) 2515
127.0.0.1:6379> CLUSTER KEYSLOT fooadfasdf{hash_tag}
(integer) 2515
127.0.0.1:6379> CLUSTER KEYSLOT fooadfasdfasdfadfasdf{hash_tag}
(integer) 2515
集群版本的redis能够支持全部的单机版命令。不过还是有些命令会有些限制。
订阅在使用上与单机版没有任何区别。订阅功能通过集群间共享publish消息实现的,客户端可以向任意一个节点(包括slave节点)订阅消息,然后在一个节点上执行的publish命令,该节点会把该命令传播给集群内的每个节点,这样订阅该消息的客户端就能收到该命令。
redis集群版只使用db0,select命令虽然能够支持select 0。其他的db都会返回错误。
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> select 1
(error) ERR SELECT is not allowed in cluster mode
redis集群版对多key命令的支持,只能支持多key都在同一个slot上,即使多个slot在一个节点上也不行。
127.0.0.1:6379> mget key7 key28
(error) CROSSSLOT Keys in request don't hash to the same slot
事务的支持只能在也一个slot上完成。MULTI命令之后的命令的key必须都在同一个slot上,如果某条命令的key对应不在相同的slot上,则事务直接回滚。迁移的时候,在迁移源节点执行命令的key必须在移原节点上存在,否则事务就会回滚。在迁移目的节点执行的时候需要先执行ASKING命令再执行MULTI命令,这样接下来该slot的命令都能被执行。可以看出,对于单key和相同hash tags的事务,集群还是能很好的支持。
在迁移的时候有个地方需要注意,对于多key命令在迁移目的节点执行时,如果多个key全在该节点上,则命令无法执行。如下所示,key和key14939对应的slot为12539,执行命令的节点是迁移目的节点:
127.0.0.1:6379> asking
OK
127.0.0.1:6379> mget key key14939
(error) TRYAGAIN Multiple keys request during rehashing of slot
集群消息
集群间互相发送消息,使用另外的端口,所有的消息在该端口上完成,可以成为消息总线,这样可以做到不影响客户端访问redis,可见redis对于性能的追求。目前集群有如下几种消息:
CLUSTERMSG_TYPE_PING:gossip协议的ping消息。
CLUSTERMSG_TYPE_PONG:gossip协议的pong消息。
CLUSTERMSG_TYPE_MEET:握手消息。
CLUSTERMSG_TYPE_FAIL:master节点检测到,超过半数master认为某master离线,则发送fail消息。
CLUSTERMSG_TYPE_PUBLISH:publish消息,向其他节点推送消息。
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST:故障转移时,slave发送向其他master投票请求。
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK:故障转移时,其他master回应slave的请求。
CLUSTERMSG_TYPE_UPDATE:通知某节点,它负责的某些slot被另一个节点替换。
CLUSTERMSG_TYPE_MFSTART:手动故障转移时,slave请求master停止访问,从而对比两者的数据偏移量,可以达到一致。
集群节点间相互通信使用了gossip协议的push/pull方式,ping和pong消息,节点会把自己的详细信息和已经和自己完成握手的3个节点地址发送给对方,详细信息包括消息类型,集群当前的epoch,节点自己的epoch,节点复制偏移量,节点名称,节点数据分布表,节点master的名称,节点地址,节点flag为,节点所处的集群状态。节点根据自己的epoch和对方的epoch来决定哪些数据需要更新,哪些数据需要告诉对方更新。然后根据对方发送的其他地址信息,来发现新节点的加入,从而和新节点完成握手。
节点默认每秒在集群中的其他节点选择一个节点,发送ping消息。选择节点步骤是:
随机 5 个节点。
跳过断开连接和已经在ping还没收到pong响应的节点。
从筛选的节点中选择最近一次接收pong回复距离现在最旧的节点。
除了常规的选择节点外,对于那些一直未随机到节点,redis也有所支持。当有节点距离上一次接收到pong消息超过节点超时配置的一半,节点就会给这些节点发送ping消息。
ping消息会带上其他节点的信息,选择其他节点步骤是:
最多选择3个节点。
最多随机遍历6个节点,如果因为一些条件不能被选出,可能会不满3个。
忽略自己。
忽略正在握手的节点。
忽略带有 NOADDR 标识的节点。
忽略连接断开而且没有负责任何slot的节点。
ping消息会把发送节点的ping_sent改成当前时间,直到接收到pong消息,才更新ping_sent为0。当ping消息发送后,超过节点超时配置的一半,就会把发送节点的连接断开。超过节点超时配置,就会认为该节点已经下线。
接收到某个节点发来的ping或者pong消息,节点会更新对接收节点的认识。比如该节点主从角色是否变化,该节点负责的slot是否变化,然后获取消息带上的节点信息,处理新节点的加入。
slot更新这里要细说下。假设这里是节点A接收到节点B的消息。A节点会取出保存的B节点的分布表与消息的分布表进行对比,B节点如果是slave,则比较的是A节点保存的B的master的分布表和消息中的分布表。比较只是使用memcmp简单的比较两份数据是否一样,一样则无需处理,不一样就处理不一致的slot。更新的时候,这里只是处理消息中分布表为1的slot。如果和A节点保持一致或者该slot正准备迁移到A节点,则继续处理。如果slot产生了冲突,则以epoch大的为准。如果冲突的slot中有A自己负责的节点,而且B比A的epoch大导致需要更新slot为B负责,此时A负责的slot为0的时候,可以认为B是A的slave。这种情况经常发生在A由原来的master变成slave,B提升为master的场景下。
前面说到slot更新的时候,如果B比A的epoch大,则A更新对slot的认识。如果A比B的epoch大, 在redis接下来的逻辑会再次处理,A会给B发送update消息,B收到A发送的update消息,执行slot更新方法。这种情况也经常发生在主从切换的时候。第一种情况发生在新master把数据分布表推给旧master。第二种情况发生在旧master给新master发消息的时候,新master给旧master发送update消息。
slot迁移
redis cluster支持slot的动态迁移,迁移需要按照指定步骤进行,不然可能破坏当前的集群数据分布表。cluster setslot
下面先来看一下完整的迁移流程:
在迁移目的节点执行cluster setslot
在迁移源节点执行cluster setslot
在迁移源节点执行cluster getkeysinslot获取该slot的key列表。
在迁移源节点执行对每个key执行migrate命令,该命令会同步把该key迁移到目的节点。
在迁移源节点反复执行cluster getkeysinslot命令,直到该slot的列表为空。
在迁移源节点和目的节点执行cluster setslot
迁移过程中该slot允许继续有流量进来,redis保证了迁移过程中slot的正常访问。在迁移过程中,对于该slot的请求,如果key在源节点,则表示该key还没有迁移到目的节点。源节点会返回ASK错误,告诉客户端去迁移目的节点请求。这样新的key就直接写入到迁移目的节点了。客户端写入目的节点前需要发送ASKING命令,告诉迁移目的节点我是写入增量数据,没有ASKING命令,迁移目的节点会不认这次请求,返回MOVED错误,告诉客户端去迁移源节点请求。
凭借ASK机制和migrate命令,redis能保证slot的全量数据和增量数据都能导入目的节点。因为对于源节点返回了ASK错误,就能保证该key不在源节点上,那么它只会出现在目的节点或者不存在。所以客户端获取ASK错误到向目的节点无需保证原子性。然后migrate命令是个原子操作,它会等待目的节点写入成功才在源节点返回,保证了迁移期间不接受其他请求,从一个外部客户端的视角来看,在某个时间点上,迁移的键要么存在于源节点,要么存在于目的节点,但不会同时存在于源节点和目的节点。
迁移过程中几乎不影响用户使用,除了在多key的命令在迁移目的节点无法执行,这个在集群访问已经说明。
不过由于migrate命令是同步阻塞执行的,所以如果key对应的value很大,会增加阻塞时间,特别对于list、set、zset等结构如果value很大的话,redis并不关心这些结构的长度,而是直接以key为单位一次性迁移。同时迁移过程中大量执行migrate命令,会增加客户端的响应时间。
迁移的时候在master出现异常的时候,迁移工作需要做些处理。
如果在迁移过程中,源节点宕机,此时需做如下调整:
目的节点执行cluster setslot
源节点group内的新master执行cluster setslot
这样可以继续完成迁移操作。
如果在迁移过程中,目的节点宕机,此时需做如下调整:
目的节点group内的新master执行cluster setslot
源节点执行cluster setslot
这样也可以继续完成迁移操作。
主从复制
集群间节点支持主从关系,复制的逻辑基本复用了单机版的实现。不过还是有些地方需要注意。
首先集群间节点建立主从关系不再使用原有的SLAVEOF命令和SLAVEOF配置,而是通过cluster replicate命令,这保证了主从节点需要先完成握手,才能建立主从关系。
集群是不能组成链式主从关系的,也就是说从节点不能有自己的从节点。不过对于集群外的没开启集群功能的节点,redis并不干预这些节点去复制集群内的节点,但是在集群故障转移时,这些集群外的节点,集群不会处理。
集群内节点想要复制另一个节点,需要保证本节点不再负责任何slot,不然redis也是不允许的。
集群内的从节点在与其他节点通信的时候,传递的消息中数据分布表和epoch是master的值。
故障转移
集群主节点出现故障,发生故障转移时,其他主节点会把故障主节点的从节点自动提为主节点,原来的主节点恢复后,自动成为新主节点的从节点。
这里先说明,把一个master和它的全部slave描述为一个group,故障转移是以group为单位的,集群故障转移的方式跟sentinel的实现很类似。某个节点一段时间没收到心跳响应,则集群内的master会把该节点标记为pfail,类似sentinel的sdown。集群间的节点会交换相互的认识,超过一半master认为该异常master宕机,则这些master把异常master标记为fail,类似sentinel的odown。fail消息会被master广播出来。group的slave收到fail消息后开始竞选成为master。竞选的方式跟sentinel选主的方式类似,都是使用了raft协议,slave会从其他的master拉取选票,票数最多的slave被选为新的master,新master会马上给集群内的其他节点发送pong消息,告知自己角色的提升。其他slave接着开始复制新master。等旧master上线后,发现新master的epoch高于自己,通过gossip消息交互,把自己变成了slave。大致就是这么个流程。自动故障转移的方式跟sentinel很像,
redis还支持手动的故障转移,即通过在slave上执行cluster failover命令,可以让slave提升为master。failover命令支持传入FORCE和TAKEOVER参数。
FORCE:使用FORCE参数与sentinel的手动故障转移流程基本类似,强制开始一次故障转移。
不传入额外参数:如果主节点异常,则不能进行failover,主节点正常的情况下需要先比较从节点和主节点的偏移量,此时会让主节点停止客户端请求,直到超时或者故障转移完成。主从偏移量相同后开始手动故障转移流程。
TAKEOVER:这种手动故障转移的方式比较暴力,slave直接提升自己的epoch为最大的epoch。并把自己变成master。这样在消息交互过程中,旧master能发现自己的epoch小于该slave,同时两者负责的slot一致,它会把自己降级为slave。
均衡集群的slave(Replica migration)
在集群运行过程中,有的master的slave宕机,导致了该master成为孤儿master(orphaned masters),而有的master有很多slave。此处孤儿master的定义是那些本来有slave,但是全部离线的master,对于那些原来就没有slave的master不能认为是孤儿master。redis集群支持均衡slave功能,官方称为Replica migration,而我觉得均衡集群的slave更好理解该概念。集群能把某个slave较多的group上的slave迁移到那些孤儿master上,该功能通过cluster-migration-barrier参数配置,默认为1。slave在每次定时任务都会检查是否需要迁移slave,即把自己变成孤儿master的slave。 满足以下条件,slave就会成为孤儿master的slave:
自己所在的group是slave最多的group。
目前存在孤儿master。
自己所在的group的slave数目至少超过2个,只有自己一个的话迁移到其他group,自己原来的group的master又成了孤儿master。
自己所在的group的slave数量大于cluster-migration-barrier配置。
与group内的其他slave基于memcmp比较node id,自己的node id最小。这个可以防止多个slave并发复制孤儿master,从而原来的group失去过多的slave。
网络分区说明
redis的集群模式下,客户端需要和全部的节点保持连接,这样可能出现网络分区问题,客户端和一些节点在一个网络分区,另一部分节点在另一个网络分区。在分区期间,客户端仍然能执行命令,直到集群经过cluster-node-timeout发现分区情况,节点探测到有slot无法提供服务,才开始禁止客户端执行命令。
这时候会出现一种现象,假设客户端和一个master在小分区,其他节点在大分区。超时后,其他节点共同投票把group内的一个slave提为master,等分区恢复。旧的master会成为新master的slave。这样在cluster-node-timeout期间对旧master的写入数据都会丢失。
这个问题可以通过设置cluster-node-timeout来减少不一致。如果对一致性要求高的应用还可以通过min-slaves-to-write配置来提高写入的要求。
slot保存key列表
redis提供了cluster countkeysinslot和cluster getkeysinslot命令,可以获得某个slot的全部key列表。通过该列表,可以实现slot的迁移。该功能是通过skiplist实现的,skiplist是redis内部用来实现zset的数据结构,在slot保持key的时候也派上了用场。redis所有在db层对hash表的操作,也会在skiplist上执行相应的操作。比如往hash表增加数据,redis也会往skiplist也写一份数据,该skiplist的score就是slot的值,value对应了具体的key。这等于是redis在数据分布表上冗余了所有的key。不过相比skiplist所带来迁移的方便,冗余的结果是可以接受的,这也期望客户端,不要使用过长的key,从而增加内存的消耗。
附录1:集群相关命令
cluster meet ip:port
集群间相互握手,加入彼此所在的集群。(将指定节点加入到集群)
cluster nodes
获取集群间节点信息的列表,如下所示,格式为
127.0.0.1:6379> cluster nodes
a15705fdb7cac60e07ff699bf4c514e80f245a2c 10.180.157.205:6379 slave 2b5603326d0fca28031467727fae4558115a99d8 0 1450854214289 11 connected
6477541e4594e60e095c8f440882636236545936 10.180.157.202:6379 slave 9b35a393fa6623887215023b761d531dde452d3c 0 1450854211276 12 connected
ecf9ae60e87ea3358d9c5f1f269e0ed9a387ea40 10.180.157.201:6379 master - 0 1450854214788 5 connected 10923-16383
2b5603326d0fca28031467727fae4558115a99d8 10.180.157.200:6379 master - 0 1450854213283 11 connected 5461-10922
f31f6ce49b3a2f3a246b2d97349c8f8614cf3a2c 10.180.157.208:6379 slave ecf9ae60e87ea3358d9c5f1f269e0ed9a387ea40 0 1450854212286 9 connected
9b35a393fa6623887215023b761d531dde452d3c 10.180.157.199:6379 myself,master - 0 0 12 connected 0-5460
cluster myid
返回节点的id。
127.0.0.1:6379> cluster myid
"9b35a393fa6623887215023b761d531dde452d3c"
cluster slots
返回集群间节点负责的数据分布表。
127.0.0.1:6379> cluster slots
1) 1) (integer) 10923
2) (integer) 16383
3) 1) "10.180.157.201"
2) (integer) 6379
4) 1) "10.180.157.208"
2) (integer) 6379
2) 1) (integer) 5461
2) (integer) 10922
3) 1) "10.180.157.200"
2) (integer) 6379
4) 1) "10.180.157.205"
2) (integer) 6379
3) 1) (integer) 0
2) (integer) 5460
3) 1) "10.180.157.199"
2) (integer) 6379
4) 1) "10.180.157.202"
2) (integer) 6379
cluster flushslots
清空该节点负责slots,必须在节点负责的这些slot都没有数据的情况下才能执行,该命令需要谨慎使用,由于之前说的bitmapTestBit方法,redis只比较负责的节点,清空的slots信息无法被其他节点同步。
cluster addslots [slot]
在当前节点上增加slot。(将指定的一个或多个slot 指派给当前节点)
cluster delslots [slot]
在节点上取消slot的负责。这也会导致前面说的slot信息无法同步,而且一旦集群有slot不负责,配置cluster-require-full-coverage为yes的话,该节点就无法提供服务了,所以使用也需谨慎。
cluster setslot
把本节点负责的某个slot设置为迁移到目的节点。(即将本节点的slot指派给或叫迁移到指定的节点)
cluster setslot
设置某个slot为从迁移源节点迁移标志。(即将指定节点的slot指派给或叫迁移到本节点)
cluster setslot
设置某个slot为从迁移状态恢复为正常状态。(取消slot的导入(importing)或迁移(migrating))
cluster setslot
设置某个slot为某节点负责。该命令使用也需要注意,cluster setslot的四个命令需要配置迁移工具使用,单独使用容易引起集群混乱。该命令在集群出现异常时,需要指定某个slot为某个节点负责时,最好在每个节点上都执行一遍,至少要在迁移的节点和最高epoch的节点上执行成功。(将指定的slot指派给指定的节点,如果该slot已经指派给另一个节点,则要另一个节点先删除该slot)
cluster info
集群的一些info信息。
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:12
cluster_my_epoch:12
cluster_stats_messages_sent:1449982
cluster_stats_messages_received:1182698
cluster saveconfig
保存集群的配置文件,集群默认在配置修改的时候会自动保存配置文件,该方法也能手动执行命令保存。
cluster keyslot
可以查询某个key对应的slot地址。
127.0.0.1:6379> cluster keyslot key
(integer) 12539
cluster countkeysinslot
可以查询该节点负责的某个slot内部key的数量。
127.0.0.1:6379> cluster countkeysinslot 13252
(integer) 2
cluster getkeysinslot
可以查询该节点负责的某个slot内部指定数量的key列表。
127.0.0.1:6379> cluster getkeysinslot 13252 10
1) "key0"
2) "key2298"
cluster forget
把某个节点加入黑名单,这样就无法完成握手。黑名单的过期时为60s,60s后两节点又会继续完成握手。
cluster replicate
负责某个节点,成为它的slave。(将当前节点设置为指定nodeid节点的从节点)
cluster slaves
列出某个节点slave列表。
127.0.0.1:6379> cluster slaves 2b5603326d0fca28031467727fae4558115a99d8
1) "a15705fdb7cac60e07ff699bf4c514e80f245a2c 10.180.157.205:6379 slave 2b5603326d0fca28031467727fae4558115a99d8 0 1450854932667 11 connected"
cluster count-failure-reports
列出某个节点的故障转移记录的长度。
cluster failover [FORCE|TAKEOVER]
手动执行故障转移。
cluster set-config-epoch
设置节点epoch,只有在节点加入集群前才能设置。
cluster reset [SOFT|HARD]
重置集群信息,soft是清空其他节点的信息,但不修改自己的id。hard还会修改自己的id。不传该参数则使用soft方式。
readonly
在slave上执行,执行该命令后,可以在slave上执行只读命令。
readwrite
在slave上执行,执行该命令后,取消在slave上执行命令。
附录2:集群相关配置
cluster-enabled
说明:集群开关,默认是不开启集群模式。
默认值:no。
是否可以动态修改:no。
值的范围:yes|no。
cluster-config-file
说明:集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息。
默认值:”nodes.conf”。
是否可以动态修改:no。
值的范围:文件路径。
cluster-node-timeout
说明:节点的超时时间,单位是毫秒。
默认值:15000。
是否可以动态修改:yes。
值的范围:大于0。
cluster-slave-validity-factor
说明:在进行故障转移的时候,group的全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间了,导致数据过于陈旧,这样的slave不应该被提升为master。该参数就是用来判断slave节点与master断线的时间是否过长。判断方法是比较slave断开连接的时间和(node-timeout * slave-validity-factor) + repl-ping-slave-period。
默认值:10。
是否可以动态修改:yes。
值的范围:大于等于0。
cluster-migration-barrier
说明:master的slave数量大于该值,slave才能迁移到其他孤儿master上,具体说明见均衡集群的slave章节。
默认值:1。
是否可以动态修改:yes。
值的范围:大于等于0。
cluster-require-full-coverage
说明:默认情况下,集群全部的slot有节点负责,集群状态才为ok,才能提供服务。设置为no,可以在slot没有全部分配的时候提供服务。不建议打开该配置,这样会造成分区的时候,小分区的master一直在接受写请求,而造成很长时间数据不一致。
默认值:yes。
是否可以动态修改:yes。
值的范围:yes|no。
1.Redis Cluster总览
1.1 设计原则和初衷
在官方文档Cluster Spec中,作者详细介绍了Redis集群为什么要设计成现在的样子。最核心的目标有三个:
- 性能:这是Redis赖以生存的看家本领,增加集群功能后当然不能对性能产生太大影响,所以Redis采取了P2P而非Proxy方式、异步复制、客户端重定向等设计,而牺牲了部分的一致性、使用性。
- 水平扩展:集群的最重要能力当然是扩展,文档中称可以线性扩展到1000结点。
- 可用性:在Cluster推出之前,可用性要靠Sentinel保证。有了集群之后也自动具有了Sentinel的监控和自动Failover能力。
1.2 架构变化与CAP理论
Redis Cluster集群功能推出已经有一段时间了。在单机版的Redis中,每个Master之间是没有任何通信的,所以我们一般在Jedis客户端或者Codis这样的代理中做Pre-sharding。按照CAP理论来说,单机版的Redis属于保证CP(Consistency & Partition-Tolerancy)而牺牲A(Availability),也就说Redis能够保证所有用户看到相同的数据(一致性,因为Redis不自动冗余数据)和网络通信出问题时,暂时隔离开的子系统能继续运行(分区容忍性,因为Master之间没有直接关系,不需要通信),但是不保证某些结点故障时,所有请求都能被响应(可用性,某个Master结点挂了的话,那么它上面分片的数据就无法访问了)。
有了Cluster功能后,Redis从一个单纯的NoSQL内存数据库变成了分布式NoSQL数据库,CAP模型也从CP变成了AP。也就是说,通过自动分片和冗余数据,Redis具有了真正的分布式能力,某个结点挂了的话,因为数据在其他结点上有备份,所以其他结点顶上来就可以继续提供服务,保证了Availability。然而,也正因为这一点,Redis无法保证曾经的强一致性了。这也是CAP理论要求的,三者只能取其二。
关于CAP理论的通俗讲解,请参考我的译文《可能是CAP理论的最好解释 》。简单分析了Redis在架构上的变化后,咱们就一起来体验一下Redis Cluster功能吧!
2.Redis集群初探
Redis的安装很简单,以前已经介绍过,就不详细说了。关于Redis Cluster的基础知识之前也有过整理,请参考《Redis集群功能预览》。如果需要全面的了解,那一定要看官方文档Cluster Tutorial,只看这一个就够了!
2.1 集群配置
要想开启Redis Cluster模式,有几项配置是必须的。此外为了方便使用和后续的测试,我还额外做了一些配置:
- 绑定地址:bind 192.168.XXX.XXX。不能绑定到127.0.0.1或localhost,否则指导客户端重定向时会报”Connection refused”的错误。
- 开启Cluster:cluster-enabled yes
- 集群配置文件:cluster-config-file nodes-7000.conf。这个配置文件不是要我们去配的,而是Redis运行时保存配置的文件,所以我们也不可以修改这个文件。
- 集群超时时间:cluster-node-timeout 15000。结点超时多久则认为它宕机了。
- 槽是否全覆盖:cluster-require-full-coverage no。默认是yes,只要有结点宕机导致16384个槽没全被覆盖,整个集群就全部停止服务,所以一定要改为no
- 后台运行:daemonize yes
- 输出日志:logfile “./redis.log”
- 监听端口:port 7000
配置好后,根据我们的集群规模,拷贝出来几份同样的配置文件,唯一不同的就是监听端口,可以依次改为7001、7002… 因为Redis Cluster如果数据冗余是1的话,至少要3个Master和3个Slave,所以我们拷贝出6个实例的配置文件。为了避免相互影响,为6个实例的配置文件建立独立的文件夹。
[root@8gVm redis-3.0.4]# pwd
/root/Software/redis-3.0.4 [root@8gVm redis-3.0.4]# tree -I "*log|nodes*" cfg-cluster/ cfg-cluster/ ├── 7000 │ └── redis.conf.7000 ├── 7001 │ └── redis.conf.7001 ├── 7002 │ └── redis.conf.7002 ├── 7003 │ └── redis.conf.7003 ├── 7004 │ └── redis.conf.7004 └── 7005 └── redis.conf.7005 6 directories, 6 files2.2 redis-trib管理器
Redis作者应该是个Ruby爱好者,Ruby客户端就是他开发的。这次集群的管理功能没有嵌入到Redis代码中,于是作者又顺手写了个叫做redis-trib的管理脚本。redis-trib依赖Ruby和RubyGems,以及redis扩展。可以先用which命令查看是否已安装ruby和rubygems,用gem list –local查看本地是否已安装redis扩展。
最简便的方法就是用apt或yum包管理器安装RubyGems后执行gem install redis。如果网络或环境受限的话,可以手动安装RubyGems和redis扩展(国外链接可能无法下载,可以从CSDN下载):
[root@8gVm Software]# wget https://github.com/rubygems/rubygems/releases/download/v2.2.3/rubygems-2.2.3.tgz
[root@8gVm Software]# tar xzvf rubygems-2.2.3.tgz
[root@8gVm Software]# cd rubygems-2.2.3 [root@8gVm rubygems-2.2.3]# ruby setup.rb --no-rdoc --no-ri [root@8gVm Software]# wget https://rubygems.org/downloads/redis-3.2.1.gem [root@8gVm Software]# gem install redis-3.2.1.gem --local --no-rdoc --no-ri Successfully installed redis-3.2.1 1 gem installed2.3 集群建立
首先,启动我们配置好的6个Redis实例。
[root@8gVm redis-3.0.4]# for ((i=0; i<6; ++i))
> do > cd cfg-cluster/700$i && ../../src/redis-server redis.conf.700$i && cd - > done此时6个实例还没有形成集群,现在用redis-trb.rb管理脚本建立起集群。可以看到,redis-trib默认用前3个实例作为Master,后3个作为Slave。因为Redis基于Master-Slave做数据备份,而非像Cassandra或Hazelcast一样不区分结点角色,自动复制并分配Slot的位置到各个结点。
[root@8gVm redis-3.0.4]# src/redis-trib.rb create --replicas 1 192.168.1.100:7000 192.168.1.100:7001 192.168.1.100:7002 192.168.1.100:7003 192.168.1.100:7004 192.168.1.100:7005 >>> Creating cluster Connecting to node 192.168.1.100:7000: OK Connecting to node 192.168.1.100:7001: OK Connecting to node 192.168.1.100:7002: OK Connecting to node 192.168.1.100:7003: OK Connecting to node 192.168.1.100:7004: OK Connecting to node 192.168.1.100:7005: OK >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 192.168.1.100:7000 192.168.1.100:7001 192.168.1.100:7002 Adding replica 192.168.1.100:7003 to 192.168.1.100:7000 Adding replica 192.168.1.100:7004 to 192.168.1.100:7001 Adding replica 192.168.1.100:7005 to 192.168.1.100:7002 ... Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join.... >>> Performing Cluster Check (using node 192.168.1.100:7000) ... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.至此,集群就已经建立成功了!“贴心”的Redis还在utils/create-cluster下提供了一个create-cluster脚本,能够创建出一个集群,类似我们上面建立起的3主3从的集群。
2.4 简单测试
我们连接到集群中的任意一个结点,启动redis-cli时要加-c选项,存取两个Key-Value感受一下Redis久违的集群功能。
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000
192.168.1.100:7000> set foo bar -> Redirected to slot [12182] located at 192.168.1.100:7002 OK 192.168.1.100:7002> set hello world -> Redirected to slot [866] located at 192.168.1.100:7000 OK 192.168.1.100:7000> get foo -> Redirected to slot [12182] located at 192.168.1.100:7002 "bar" 192.168.1.100:7002> get hello -> Redirected to slot [866] located at 192.168.1.100:7000 "world"仔细观察能够注意到,redis-cli根据指示,不断在7000和7002结点之前重定向跳转。如果启动时不加-c选项的话,就能看到以错误形式显示出的MOVED重定向消息。
[root@8gVm redis-3.0.4]# src/redis-cli -h 192.168.1.100 -p 7000
192.168.1.100:7000> get foo (error) MOVED 12182 192.168.1.100:70022.5 集群重启
目前redis-trib的功能还比较弱,需要重启集群的话先手动kill掉各个进程,然后重新启动就可以了。这也有点太… 网上有人重启后会碰到问题,我还比较幸运,这种“土鳖”的方式重启试了两次还没发现问题。
[root@8gVm redis-3.0.4]# ps -ef | grep redis | awk '{print $2}' | xargs kill
3.高级功能尝鲜
说是“高级功能”,其实在其他分布式系统中早就都有实现了,只不过在Redis世界里是比较新鲜的。本部分主要试验一下Redis Cluster中的数据迁移(Resharding)和故障转移功能。
3.1 数据迁移
本小节我们体验一下Redis集群的Resharding功能!
3.1.1 创建测试数据
首先保存foo1~10共10个Key-Value作为测试数据。
[root@8gVm redis-3.0.4]# for ((i=0; i<10; ++i))
> do > src/redis-cli -c -h 192.168.1.100 -p 7000 set foo$i bar > done [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 192.168.1.100:7000> keys * 1) "foo6" 2) "foo7" 3) "foo3" 4) "foo2" 192.168.1.100:7000> get foo4 -> Redirected to slot [9426] located at 192.168.1.100:7001 "bar" 192.168.1.100:7001> keys * 1) "foo4" 2) "foo8" 192.168.1.100:7001> get foo5 -> Redirected to slot [13555] located at 192.168.1.100:7002 "bar" 192.168.1.100:7002> keys * 1) "foo5" 2) "foo1" 3) "foo10" 4) "foo9"3.1.2 启动新结点
参照之前的方法新拷贝出两份redis.conf配置文件redis.conf.7010和7011,与之前结点的配置文件做一下区分。启动新的两个Redis实例之后,通过redis-trib.rb脚本添加新的Master和Slave到集群中。
[root@8gVm redis-3.0.4]# cd cfg-cluster/7010 && ../../src/redis-server redis.conf.7010 && cd -
[root@8gVm redis-3.0.4]# cd cfg-cluster/7011 && ../../src/redis-server redis.conf.7011 && cd -3.1.3 添加到集群
使用redis-trib.rb add-node分别将两个新结点添加到集群中,一个作为Master,一个作为其Slave。
[root@8gVm redis-3.0.4]# src/redis-trib.rb add-node 192.168.1.100:7010 192.168.1.100:7000
>>> Adding node 192.168.1.100:7010 to cluster 192.168.1.100:7000 Connecting to node 192.168.1.100:7000: OK Connecting to node 192.168.1.100:7001: OK Connecting to node 192.168.1.100:7002: OK Connecting to node 192.168.1.100:7005: OK Connecting to node 192.168.1.100:7003: OK Connecting to node 192.168.1.100:7004: OK >>> Performing Cluster Check (using node 192.168.1.100:7000) ... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. Connecting to node 192.168.1.100:7010: OK >>> Send CLUSTER MEET to node 192.168.1.100:7010 to make it join the cluster. [OK] New node added correctly. [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster nodes 0d1f9c979684e0bffc8230c7bb6c7c0d37d8a5a9 192.168.1.100:7010 master - 0 1442452249525 0 connected ... [root@8gVm redis-3.0.4]# src/redis-trib.rb add-node --slave --master-id 0d1f9c979684e0bffc8230c7bb6c7c0d37d8a5a9 192.168.1.100:7011 192.168.1.100:7000 >>> Adding node 192.168.1.100:7011 to cluster 192.168.1.100:7000 Connecting to node 192.168.1.100:7000: OK Connecting to node 192.168.1.100:7010: OK Connecting to node 192.168.1.100:7001: OK Connecting to node 192.168.1.100:7002: OK Connecting to node 192.168.1.100:7005: OK Connecting to node 192.168.1.100:7003: OK Connecting to node 192.168.1.100:7004: OK >>> Performing Cluster Check (using node 192.168.1.100:7000) ... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. Connecting to node 192.168.1.100:7011: OK >>> Send CLUSTER MEET to node 192.168.1.100:7011 to make it join the cluster. Waiting for the cluster to join. >>> Configure node as replica of 192.168.1.100:7010. [OK] New node added correctly.3.1.4 Resharding
通过redis-trib.rb reshard可以交互式地迁移Slot。下面的例子将5000个Slot从7000~7002迁移到7010上。也可以通过./redis-trib.rb reshard 在程序中自动完成迁移。
[root@8gVm redis-3.0.4]# src/redis-trib.rb reshard 192.168.1.100:7000
Connecting to node 192.168.1.100:7000: OK Connecting to node 192.168.1.100:7010: OK Connecting to node 192.168.1.100:7001: OK Connecting to node 192.168.1.100:7002: OK Connecting to node 192.168.1.100:7005: OK Connecting to node 192.168.1.100:7011: OK Connecting to node 192.168.1.100:7003: OK Connecting to node 192.168.1.100:7004: OK >>> Performing Cluster Check (using node 192.168.1.100:7000) M: b2036adda128b2eeffa36c3a2056444d23b548a8 192.168.1.100:7000 slots:0-5460 (4128 slots) master 1 additional replica(s) M: 0d1f9c979684e0bffc8230c7bb6c7c0d37d8a5a9 192.168.1.100:7010 slots:0 (4000 slots) master 1 additional replica(s) ... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 5000 What is the receiving node ID? 0d1f9c979684e0bffc8230c7bb6c7c0d37d8a5a9 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:all [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster nodes 0d1f9c979684e0bffc8230c7bb6c7c0d37d8a5a9 192.168.1.100:7010 master - 0 1442455872019 7 connected 0-1332 5461-6794 10923-12255 b2036adda128b2eeffa36c3a2056444d23b548a8 192.168.1.100:7000 myself,master - 0 0 1 connected 1333-5460 b5ab302f5c2395e3c8194c354a85d02f89bace62 192.168.1.100:7001 master - 0 1442455875022 2 connected 6795-10922 0c565e207ce3118470fd5ed3c806eb78f1fdfc01 192.168.1.100:7002 master - 0 1442455874521 3 connected 12256-16383 ...
迁移完成后,查看之前保存的foo1~10的分布情况,可以看到部分Key已经迁移到了新的结点7010上。
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 keys "*"
1) "foo3" 2) "foo7" [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7001 keys "*" 1) "foo4" 2) "foo8" 3) "foo0" [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7002 keys "*" 1) "foo1" 2) "foo9" 3) "foo5" [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7010 keys "*" 1) "foo6" 2) "foo2"3.2 故障转移
在高可用性方面,Redis可算是能够”Auto”一把了!Redis Cluster重用了Sentinel的代码逻辑,不需要单独启动一个Sentinel集群,Redis Cluster本身就能自动进行Master选举和Failover切换。
下面我们故意kill掉7010结点,之后可以看到结点状态变成了fail,而Slave 7011被选举为新的Master。
[root@8gVm redis-3.0.4]# kill 43637
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster nodes 0d1f9c979684e0bffc8230c7bb6c7c0d37d8a5a9 192.168.1.100:7010 master,fail - 1442456829380 1442456825674 7 disconnected b2036adda128b2eeffa36c3a2056444d23b548a8 192.168.1.100:7000 myself,master - 0 0 1 connected 1333-5460 b5ab302f5c2395e3c8194c354a85d02f89bace62 192.168.1.100:7001 master - 0 1442456848722 2 connected 6795-10922 0c565e207ce3118470fd5ed3c806eb78f1fdfc01 192.168.1.100:7002 master - 0 1442456846717 3 connected 12256-16383 5a3c67248b1df554fbf2c93112ba429f31b1d3d1 192.168.1.100:7005 slave 0c565e207ce3118470fd5ed3c806eb78f1fdfc01 0 1442456847720 6 connected 99bff22b97119cf158d225c2b450732a1c0d3c44 192.168.1.100:7011 master - 0 1442456849725 8 connected 0-1332 5461-6794 10923-12255 cd305d509c34842a8047e19239b64df94c13cb96 192.168.1.100:7003 slave b2036adda128b2eeffa36c3a2056444d23b548a8 0 1442456848220 4 connected 64b544cdd75c1ce395fb9d0af024b7f2b77213a3 192.168.1.100:7004 slave b5ab302f5c2395e3c8194c354a85d02f89bace62 0 1442456845715 5 connected
尝试查询之前保存在7010上的Key,可以看到7011顶替上来继续提供服务,整个集群没有受到影响。
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 get foo6
"bar" [root@8gVm redis-3.0.4]# [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 get foo2 "bar"4.内部原理剖析
前面我们已经学习过,用Redis提供的redis-trib或create-cluster脚本能几步甚至一步就建立起一个Redis集群。这一部分我们为了深入学习,所以要暂时抛开这些方便的工具,完全手动建立一遍上面的3主3从集群。
4.1 集群发现:MEET
最开始时,每个Redis实例自己是一个集群,我们通过cluster meet让各个结点互相“握手”。这也是Redis Cluster目前的一个欠缺之处:缺少结点的自动发现功能。
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster nodes
33c0bd93d7c7403ef0239ff01eb79bfa15d2a32c :7000 myself,master - 0 0 0 connected [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster meet 192.168.1.100 7001 OK ... [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster meet 192.168.1.100 7005 OK [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster nodes 7b953ec26bbdbf67179e5d37e3cf91626774e96f 192.168.1.100:7003 master - 0 1442466369259 4 connected 5d9f14cec1f731b6477c1e1055cecd6eff3812d4 192.168.1.100:7005 master - 0 1442466368659 4 connected 33c0bd93d7c7403ef0239ff01eb79bfa15d2a32c 192.168.1.100:7000 myself,master - 0 0 1 connected 63162ed000db9d5309e622ec319a1dcb29a3304e 192.168.1.100:7001 master - 0 1442466371262 3 connected 45baa2cb45435398ba5d559cdb574cfae4083893 192.168.1.100:7002 master - 0 1442466372264 2 connected cdd5b3a244761023f653e08cb14721f70c399b82 192.168.1.100:7004 master - 0 1442466370261 0 connecte4.2 角色设置:REPLICATE
结点全部“握手”成功后,就可以用cluster replicate命令为结点指定角色了,默认每个结点都是Master。
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7003 cluster replicate 33c0bd93d7c7403ef0239ff01eb79bfa15d2a32c
OK
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7004 cluster replicate 63162ed000db9d5309e622ec319a1dcb29a3304e OK [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7005 cluster replicate 45baa2cb45435398ba5d559cdb574cfae4083893 OK [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster nodes 7b953ec26bbdbf67179e5d37e3cf91626774e96f 192.168.1.100:7003 slave 33c0bd93d7c7403ef0239ff01eb79bfa15d2a32c 0 1442466812984 4 connected 5d9f14cec1f731b6477c1e1055cecd6eff3812d4 192.168.1.100:7005 slave 45baa2cb45435398ba5d559cdb574cfae4083893 0 1442466813986 5 connected 33c0bd93d7c7403ef0239ff01eb79bfa15d2a32c 192.168.1.100:7000 myself,master - 0 0 1 connected 63162ed000db9d5309e622ec319a1dcb29a3304e 192.168.1.100:7001 master - 0 1442466814987 3 connected 45baa2cb45435398ba5d559cdb574cfae4083893 192.168.1.100:7002 master - 0 1442466811982 2 connected cdd5b3a244761023f653e08cb14721f70c399b82 192.168.1.100:7004 slave 63162ed000db9d5309e622ec319a1dcb29a3304e 0 1442466812483 3 connected
4.3 槽指派:ADDSLOTS
设置好主从关系之后,就可以用cluster addslots命令指派16384个槽的位置了。有点恶心的是,ADDSLOTS命令需要在参数中一个个指明槽的ID,而不能指定范围。这里用Bash 3.0的特性简化了,不然就得用Bash的循环来完成了:
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7000 cluster addslots {0..5000}
OK
[root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7001 cluster addslots {5001..10000} OK [root@8gVm redis-3.0.4]# src/redis-cli -c -h 192.168.1.100 -p 7001 cluster addslots {10001..16383} OK [root@8gVm redis-3.0.4]# src/redis-trib.rb check 192.168.1.100:7000 Connecting to node 192.168.1.100:7000: OK ... >>> Performing Cluster Check (using node 192.168.1.100:7000) ... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
这样我们就通过手动执行命令得到了与之前一样的集群。
4.4 数据迁移:MIGRATE
真正开始Resharding之前,redis-trib会先在源结点和目的结点上执行cluster setslot 和cluster setslot 命令,将要迁移的槽分别标记为迁出中和导入中的状态。然后,执行cluster getkeysinslot获得Slot中的所有Key。最后就可以对每个Key执行migrate命令进行迁移了。槽迁移完成后,执行cluster setslot命令通知整个集群槽的指派已经发生变化。
关于迁移过程中的数据访问,客户端访问源结点时,如果Key还在源结点上就直接操作。如果已经不在源结点了,就向客户端返回一个ASK错误,将客户端重定向到目的结点。
4.5 内部数据结构
Redis Cluster功能涉及三个核心的数据结构clusterState、clusterNode、clusterLink都在cluster.h中定义。这三个数据结构中最重要的属性就是:clusterState.slots、clusterState.slots_to_keys和clusterNode.slots了,它们保存了三种映射关系:
- clusterState:集群状态
- nodes:所有结点
- migrating_slots_to:迁出中的槽
- importing_slots_from:导入中的槽
- slots_to_keys:槽中包含的所有Key,用于迁移Slot时获得其包含的Key
- slots:Slot所属的结点,用于处理请求时判断Key所在Slot是否自己负责
- clusterNode:结点信息
- slots:结点负责的所有Slot,用于发送Gossip消息通知其他结点自己负责的Slot。通过位图方式保存节省空间,16384/8恰好是2048字节,所以槽总数16384不是随意定的。
- clusterLink:与其他结点通信的连接
// 集群状态,每个节点都保存着一个这样的状态,记录了它们眼中的集群的样子。
// 另外,虽然这个结构主要用于记录集群的属性,但是为了节约资源,
// 有些与节点有关的属性,比如 slots_to_keys 、 failover_auth_count
// 也被放到了这个结构里面。
typedef struct clusterState { ... // 指向当前节点的指针 clusterNode *myself; /* This node */ // 集群当前的状态:是在线还是下线 int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */ // 集群节点名单(包括 myself 节点) // 字典的键为节点的名字,字典的值为 clusterNode 结构 dict *nodes; /* Hash table of name -> clusterNode structures */ // 记录要从当前节点迁移到目标节点的槽,以及迁移的目标节点 // migrating_slots_to[i] = NULL 表示槽 i 未被迁移 // migrating_slots_to[i] = clusterNode_A 表示槽 i 要从本节点迁移至节点 A clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS]; // 记录要从源节点迁移到本节点的槽,以及进行迁移的源节点 // importing_slots_from[i] = NULL 表示槽 i 未进行导入 // importing_slots_from[i] = clusterNode_A 表示正从节点 A 中导入槽 i clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS]; // 负责处理各个槽的节点 // 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理 clusterNode *slots[REDIS_CLUSTER_SLOTS]; // 跳跃表,表中以槽作为分值,键作为成员,对槽进行有序排序 // 当需要对某些槽进行区间(range)操作时,这个跳跃表可以提供方便 // 具体操作定义在 db.c 里面 zskiplist *slots_to_keys; ... } clusterState; // 节点状态 struct clusterNode { ... // 节点标识 // 使用各种不同的标识值记录节点的角色(比如主节点或者从节点), // 以及节点目前所处的状态(比如在线或者下线)。 int flags; /* REDIS_NODE_... */ // 由这个节点负责处理的槽 // 一共有 REDIS_CLUSTER_SLOTS / 8 个字节长 // 每个字节的每个位记录了一个槽的保存状态 // 位的值为 1 表示槽正由本节点处理,值为 0 则表示槽并非本节点处理 // 比如 slots[0] 的第一个位保存了槽 0 的保存情况 // slots[0] 的第二个位保存了槽 1 的保存情况,以此类推 unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */ // 指针数组,指向各个从节点 struct clusterNode **slaves; /* pointers to slave nodes */ // 如果这是一个从节点,那么指向主节点 struct clusterNode *slaveof; /* pointer to the master node */ ... }; /* clusterLink encapsulates everything needed to talk with a remote node. */ // clusterLink 包含了与其他节点进行通讯所需的全部信息 typedef struct clusterLink { ... // TCP 套接字描述符 int fd; /* TCP socket file descriptor */ // 与这个连接相关联的节点,如果没有的话就为 NULL struct clusterNode *node; /* Node related to this link if any, or NULL */ ... } clusterLink;
4.6 处理流程全梳理
在单机模式下,Redis对请求的处理很简单。Key存在的话,就执行请求中的操作;Key不存在的话,就告诉客户端Key不存在。然而在集群模式下,因为涉及到请求重定向和Slot迁移,所以对请求的处理变得很复杂,流程如下:
- 检查Key所在Slot是否属于当前Node?
2.1 计算crc16(key) % 16384得到Slot
2.2 查询clusterState.slots负责Slot的结点指针
2.3 与myself指针比较 - 若不属于,则响应MOVED错误重定向客户端
- 若属于且Key存在,则直接操作,返回结果给客户端
- 若Key不存在,检查该Slot是否迁出中?(clusterState.migrating_slots_to)
- 若Slot迁出中,返回ASK错误重定向客户端到迁移的目的服务器上
- 若Slot未迁出,检查Slot是否导入中?(clusterState.importing_slots_from)
- 若Slot导入中且有ASKING标记,则直接操作
- 否则响应MOVED错误重定向客户端
5.应用案例收集
5.1 有道:Redis Cluster使用经验
详情请参见原文,关键内容摘录如下:
5.1.1 两个缺点
“redis cluster的设计在这块有点奇葩,跟集群相关的操作需要一个外部的ruby脚本来协助(当然可能是为了让主程序的代码足够简洁?),然后那个脚本还只支持填实例的ip不支持host,还不告诉你不支持让你用host之后各种莫名其妙。”
“第一个缺点就是严格依赖客户端driver的成熟度。如果把redis cluster设计成类似Cassandra,请求集群中任何一个节点都可以负责转发请求,client会好写一些。”
“第二个缺点完全是设计问题了,就是一个redis进程既负责读写数据又负责集群交互,虽然设计者已经尽可能简化了代码和逻辑,但还是让redis从一个内存NoSQL变成了一个分布式NoSQL。分布式系统很容易有坑,一旦有坑必须升级redis。”
5.1.2 去中心化 vs. Proxy
“关于redis cluster的设计,Gossip/P2P的去中心化架构本身不是问题,但一旦有了中心节点,能做的事情就多了,比如sharding不均匀是很容易自动rebalance的,而无中心的只能靠外界来搞。然后redis cluster又是slot的形式而非C*式的一致性哈希,新节点分slot又不自动,依赖外界(ruby脚本)来分配显得不方便更不优美和谐。而且因为是master-slave的系统而非W+R>N的那种,master挂掉之后尽快发现是比较重要的,gossip对于节点挂掉的发现终究没有中心节点/zookeeper方便快速。”
“基于proxy做转发意味着屏蔽了下层存储,完全可以根据前缀/tag/冷热程度,来把部分甚至大多数数据放在磁盘从而节约成本又保证一致性,这都是有中心节点所带来的好处。”
5.2 奇虎360:Redis Cluster浅析和Bada对比
详情请参见原文,关键内容摘录如下:
5.2.1 负载均衡问题
“redis cluster的主备是以节点为单位,而bada则是以partition为单位,这样,同样是3个节点,1024个partition的情况下,redis cluster的主节点负责整个1024个partition的服务,而两个从节点则只负责异步备份,导致集群负载不均,再看bada,将1024个partition的主均分到3个节点中,每个节点各有主备,主对外提供服务,这样均分了访问压力,有效的利用了资源。”
5.2.2 一致性的保证
“redis cluster与bada一样,最终一致性,读写都只请求主节点,当一条写请求在对应的主节点写成功后,会立刻返回给客户端成功,然后主节点通过异步的方式将新的数据同步到对应的从节点,这样的方式减少了客户端多个节点写成功等待的时间,不过在某些情况下会造成写丢失:
1)当主节点接受一条写请求,写入并返回给客户端成功后不幸宕掉,此时刚才的写还未同步给其对应的从节点,而从节点在发现主节点挂掉并重新选主后,新的主节点则永久丢失了之前老的主节点向用户确认的写
2)当网络发生割裂,将集群分裂成少数派与多数派,这样在客户端不知情的情况下,会将写继续写入到少数派中的某些主节点中,而当割裂超过一定时长后,集群感知到异常,此时少数派中的所有主节点会停止响应所有的写请求,多数派的其对应的从节点则会发起选举成为新的主节点,假设过了一会后割裂恢复,老的主节点发现有更新的主存在,自动变成其从节点,而新的主节点中则会永久丢失掉网络割裂至集群感知异常进行切主这个阶段老主节点确认的所有写
相对于redis cluster的永久丢失,bada通过binlog merge有效的解决了这一问题。所有partition的主节点在响应客户端的写请求时,都会在本地记录binlog,binlog实质就是带有时间戳的KV对。当老主以从节点的身份重新加入集群时,会触发binlog merge操作,新主会比较并且合并二者的binlog,这样就可以将之前丢失掉得写再补回来。”
5.2.3 请求重定向问题
“bada服务端节点在收到本不该由自己负责的Partition请求后,不会向客户端返回重定向信息,而是通过代理的方式,直接在集群内部向正确节点转发客户端的请求,并将结果同meta信息再转发回客户端。”
“再看multi key操作,redis cluster为了追求高性能,支持multi key的前提是所有的key必须在同一个节点中, 不过这样的处理需要交给用户,对需要进行multi key操作的所有key,在写入前人为的加上hash tags。当redis cluster进行resharding的时候,也就是将某些slot从一个节点迁移到另一个节点时,此时的multi key操作可能会失败,因为在迁移的slot中的key此时存在于两个节点。
bada怎么做呢?用户如果对multi key操作性能很在乎时,可以采用与redis cluster同样的方式,给这些key加上hash tags来让它们落在同一个节点,如果可以接受性能的稍微损耗而解放用户的处理逻辑,则可以像single key操作一样,请求任一bada节点,它会代理所有的key请求并将结果返回给用户。并且在multi key操作在任何时候都可以,即使在进行partition的迁移,bada也会提前进行切主,保证服务的正常提供。”
5.3 芒果TV:Redis服务解决方案
详情请参见原文,关键内容摘录如下:
芒果TV在Redis Cluster基础上进行开发,主要增加了两个组件:
- 监控管理:以Python为主要开发框架的Web应用程序Redis-ctl
- 请求代理:以C++11为开发语言的轻量数据代理程序cerberus。其作用和优点为:
- 集群代理程序的自动请求分发/重试机制使得应用不必修改自身代码或更新Redis库
- 代理节点为所有Redis节点加上统一管理和状态监测, 可以查阅历史数据, 或在发生任何问题之后快速响应修复
- 代理进程的无状态性使之可在故障后快速恢复, 不影响后端集群数据完整性
这两个组件都已开源到GitHub上,大家可以关注一下!
6.Pros & Cons总结
关于Redis Cluster带来的种种优势就不说了,在这里主要是“鸡蛋里挑骨头”,总结一下现阶段集群功能的欠缺之处和可能的“坑”。
6.1 无中心化架构
6.1.1 Gossip消息
Gossip消息的网络开销和时延是决定Redis Cluster能够线性扩展的因素之一。关于这个问题,在《redis cluster百万QPS的挑战》一文中有所提及。
6.1.2 结点粒度备份
此外,Redis Cluster也许是为了简化设计采用了Master-Slave复制的数据备份方案,并没有采取如Cassandra或IMDG等对等分布式系统中常见的Slot粒度(或叫Partition/Bucket等)的自动冗余和指派。
这种设计虽然避免比较复杂的分布式技术,但也带来了一些问题:
- Slave完全闲置:即便是读请求也不会被重定向到Slave结点上,Slave属于“冷备”
- 写压力无法分摊:Slave闲置导致的另一个问题就是写压力也都在Master上
6.2 客户端的挑战
由于Redis Cluster的设计,客户端要担负起一部分责任:
- Cluster协议支持:不管Dummy还是Smart模式,都要具备解析Cluster协议的能力
- 网络开销:Dummy客户端不断重定向的网络开销
- 连接维护:Smart客户端对连接到集群中每个结点Socket的维护
- 缓存路由表:Smart客户端Slot路由表的缓存和更新
- 内存消耗:Smart客户端上述维护的信息都是有内存消耗的
- MultiOp有限支持:对于MultiOp,由客户端通过KeyTag保证所有Key都在同一Slot。而即便如此,迁移时也会导致MultiOp失败。同理,对Pipeline和Transaction的支持也受限于必须操作同一Slot内的Key。
6.3 Redis实现问题
尽管属于无中心化架构一类的分布式系统,但不同产品的细节实现和代码质量还是有不少差异的,就比如Redis Cluster有些地方的设计看起来就有一些“奇葩”和简陋:
- 不能自动发现:无Auto Discovery功能。集群建立时以及运行中新增结点时,都要通过手动执行MEET命令或redis-trib.rb脚本添加到集群中
- 不能自动Resharding:不仅不自动,连Resharding算法都没有,要自己计算从哪些结点上迁移多少Slot,然后还是得通过redis-trib.rb操作
- 严重依赖外部redis-trib:如上所述,像集群健康状况检查、结点加入、Resharding等等功能全都抽离到一个Ruby脚本中了。还不清楚上面提到的缺失功能未来是要继续加到这个脚本里还是会集成到集群结点中?redis-trib也许要变成Codis中Dashboard的角色
- 无监控管理UI:即便未来加了UI,像迁移进度这种信息在无中心化设计中很难得到
- 只保证最终一致性:写Master成功后立即返回,如需强一致性,自行通过WAIT命令实现。但对于“脑裂”问题,目前Redis没提供网络恢复后的Merge功能,“脑裂”期间的更新可能丢失
6.4 性能损耗
由于之前手头没有空闲的物理机资源,所以只在虚拟机上做了简单的单机测试,在单独的一台压力机使用YCSB测试框架向虚拟机产生读写负载。虚拟机的配置为8核Intel Xeon CPU [email protected],16GB内存,分别搭建了4结点的单机版Redis和集群版Redis,测试一下Redis Cluster的性能损耗。由于不是最近做的测试,所以Jedis用的2.6.2版本。注:当然Redis Cluster可以通过多机部署获得水平扩展带来的性能提升,这里只是由于环境有限所以做的简单单机测试。
由于YCSB本身仅支持Redis单机版,所以需要我们自己增加扩展插件,具体方法请参照《YCSB性能测试工具使用》。通过YCSB产生2000w随机数据,Value大约100Byte左右。然后通过YCSB测试Read-Mostly(90% Read)和Read-Write-Mixed(50% Read)两种情况:
- 数据加载:吞吐量上有约18%的下降。
- Read-Mostly:吞吐量上有约3.5%~7.9%的下降。
- Read-Write-Mixed:吞吐量上有约3.3%~5.5%下降。
- 内存占用:Jedis客户端多占用380MB内存。
6.5 最后的总结
从现阶段看来,相比Sentinel或Codis等方案,Redis Cluster的优势还真是有限,个人觉得最大的优点有两个:
- 官方提供的Slot实现而不用像Codis那样去改源码了;
- 不用额外的Sentinel集群或类似的代码实现了。
同其他分布式系统,如Cassandra,或内存型的IMDG如Hazelcast和GridGain,除了性能方面外,从功能上Redis Cluster简直被爆得体无完肤… 看看我之前总结过的GridGain介绍《开源IMDG之GridGain》:
- 结点自动发现和Rebalance
- 分区粒度的备份
- 故障时分区角色自动调整
- 结果聚合(不会重定向客户端)
- “脑裂”恢复后的Merge(Hazelcast支持多种合并策略)
- 多Primary分区写操作(见Replicated模式)
这些都是Redis Cluster没有或者要手动完成的。当然这也不足为奇,因为这与Redis的设计初衷有关,毕竟作者都已经说了,最核心的设计目标就是性能、水平伸缩和可用性。
从Redis Cluster的环境搭建使用到高级功能和内部原理剖析,再到应用案例收集和优缺点的分析罗列,讲了这么多,关于Redis集群到底如何,相信大家根据自己切身和项目的具体情况一定有了自己的结论。不管是评估测试也好,二次开发也好,还是直接上线使用也好,相信随着官方的不断迭代更新和大家的力量,Redis Cluster一定会逐渐完善成熟的!
http://www.cnblogs.com/lixigang/articles/4847110.html