Quantopian 入门系列一

本文含 7926 字,52 图表截屏
建议阅读 40 分钟
在公众号对话框回复 QTP1 下载 notebook
0
引言
本系列将 Quantopian 官网上的四节 Tutorials 好好梳理一下。
本帖讲解第一节 Basic Quantopian Lessons,旨在说明如何使用 Quantopian 的研究环境和回测环境。目录如下:
简介
数据探索
流水线
策略分析
交易算法
数据流水线
组合优化
回测分析
1
简介
交易算法(trading algorithm)是用计算机来定义一组买卖资产规则的程序。大多的交易算法都是基于历史数据和数学/统计模型来做决策的。
在 Quantopian 研究环境中有完整的美股数据可供我们使用。在 Quantopian 主页,记注点击下图的 Research --> Notebooks 就可以创建一个 Jupyter Notebook 环境来运行 Python 代码
让我们看一个简单的例子,获取苹果(AAPL)股票的日终价,并计算出其 20 天和 50 天的移动平均值(Moving Average, MA)。代码和解释如下:

画图如下,注意,MA50 比 MA20 短,MA20 比 AAPL 短, 原因很简单,求 N 天移动均值的第一个点需要 AAPL 中前 N 个数据。

打印出 MA50, MA20 和 AAPL 的形状。
aapl_close.shape, aapl_sma20.shape, aapl_sma50.shape
((756,), (756,), (756,))三者包含一样多的数据?不合理,再看看三者含有的实际元素是什么样的。
df.head(5).append(df.tail(5))
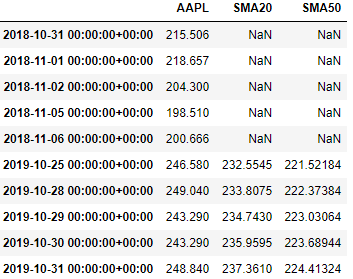
原来 MA20 和 MA50 前 19 个和前 49 个都是 NaN,NaN 值在图中是提下不出来的,这就解释了上图三条线长短不一的原因。
总结一下:
要点
用 quantopian.research 里面的 symbols 来获取资产代号。
用 quantopian.research 里面的 prices 来获取收盘价,需要设置代号、起始日和终止日,输出是一个数据帧。
数据帧可以直接用 df.plot() 的格式作图,和 matplotlib 里面的 plot(df) 效果类似。2
数据探索
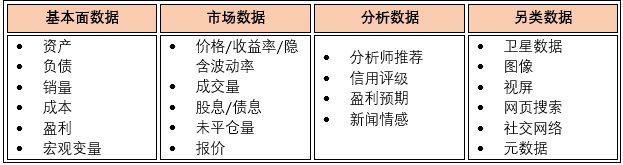
金融数据主要可分为四类,见下表总结。
在 Quantopian 中,我们可以获取从 2002 年开始每一个交易日的 8000+ 美股的价格和收益率,以数据帧的形式返回。
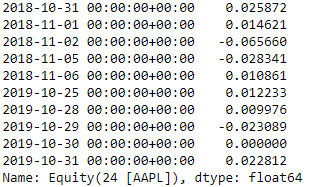
下面代码获取了苹果股票从 2018-10-31 到 2019-10-31 之间的收益率,代码和解释如下:

返回结果 aapl_returns 是一个系列(Series)即只有一个列标签的数据帧,行标签是日期+时间。
除了最基本的价格和收益率数据之外,Quantopian 里还可以提供公司基本面(corporate fundamentals)、股票情绪(stock sentiment)和宏观经济指标(macroecnomic indicator)等数据。在 Quantipian 里有 50+ 个这方面的数据集,列表如下:

我们用 PyschSignal Trader Mood(上图倒数第二个)来说明如何获取股票情绪数据。PyschSignal 是一个提供交易员情绪数据的公司,它主要用自然语言处理(NLP)来分析社交媒体(主要是 Twitter 和 StockTwits)上的消息,并从中为每个证券打分。从 2016 年起,这些数据就已经是 Point-In-Time (PIT) 了。
关于 PyschSignal 详情可参考以下链接:
https://www.quantopian.com/docs/data-reference/psychsignal
在下例中,我们只获取消息量(message volume)和情绪得分(sentiment score)这两类数据。为了能使获取过程更有效,Quantopian 提供了流水线 API,要使用它需要三件套:
引入流水线(import)
定义流水线(define)
执行流水线(execute)

最后运行完流水线后返回的 data_output 可看成是一个对象,包含所有股票在起始日和终止日之间的 return, sentiment, msg_volume 信息。如果要获取某只股票的信息,只需用 xs() 函数,设定好 symbols() 和 level 两个参数即可(注意第一个是函数类参数,还记得Python 里函数是第一公民吗,可以当参数用)。代码如下:
aapl_output = data_output.xs(symbols('AAPL'),
level=1)
为什么 level 要设定为 1 看 data_output 的格式就知道了。它是一个有多层行标签的数据帧,level 0 是日期,level 1 才是股票代号。

用 AAPL 代号获取完之后的结果 aapl_output 就是一个普通的数据帧了。
aapl_output.head()

最后画出 return, sentiment, msg_volume 信息随日期的折线图。
aapl_output.plot(subplots=True);
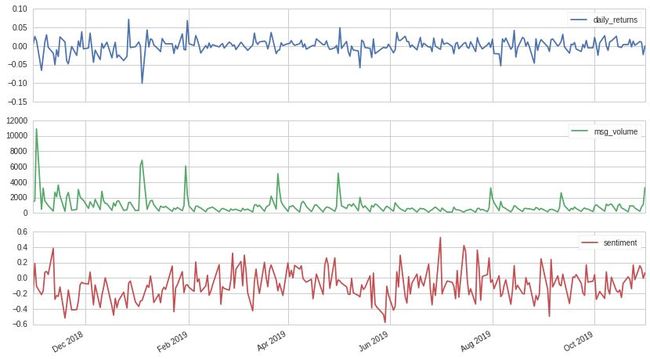
粗略来看,从上图的三条时间序列的模型可能可以挖出交易策略。比如信息量大(绿线)的时点通常伴随的收益率波动剧烈(蓝线)的时点,而有时情绪得分(红线)和收益率(蓝线)走向是一致的。
以上观察只是初探,要交易还需要进行严谨的统计检验。
总结一下:
要点
用 quantopian.research 里面的 symbols 来获取资产代号
用 quantopian.research 里面的 returns 来获取收益率,需要设置代号、起始日和终止日,输出是一个数据帧
用 quantopian.pipeline 里面的 Pipeline 来定义流水线。基本格式为
Pipeline(columns=dict)
用 quantopian.research 里面的 run_pipeline 来运行流水线。基本格式为
run_pipeline(pipe, s_date, e_date)
其中 pipe 是用 Pipeline 定义的流水线对象。
3
流水线
本章正式来介绍流水线(pipeline)。
流水线是做截面(cross-pal)数据分析的大杀器,在里面我们可以在同时在多个资产中的多维特征上定义一系列运算,举例应用包含:
根据规则筛选资产
根据得分排序资产
计算投资组合分配
定义流水线
首先引入 Pipeline 包来定义流水线,最简单的例子是定义一个空的流水线。

运行 make_pipeline() 得到一个流水线对象。
make_pipeline()
设定获取数据标签
空流水线没什么用,接着我们添加想获取的数据。首先我们想获取收盘价,引进 USEquityPricing 包,再用 .close.latest 得到最新收盘价。
把 close_price 放入 Pipeline() 里 columns 参数指定的字典中。
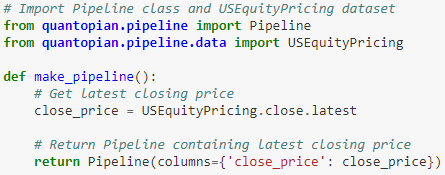
接下来我们还想获取 3 天情绪的移动平均指标。用 Quantopian 里面的内含子函数包 SimpleMovingAverage(),其中 window_length 设为 3。
把 sentiment_score 放入 Pipeline() 里 columns 参数指定的字典中。

设定筛选规则
我们不可能对所有资产感兴趣,因此需要一些筛选规则来去除不感兴趣的,比如那些流动性差的资产。这时我们用 QTradableStocksUS 包来定义交易资产界限。
把 base_universe 放入 Pipeline() 里 screen 参数中。

运行流水线
设定好想要指标后,剔除掉不要的资产后,只需运行流水线就可以了,代码如下。
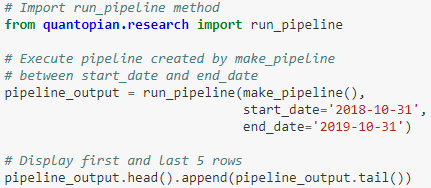
输出是一个多层行标签的数据帧,打印其首尾 5 行看看。
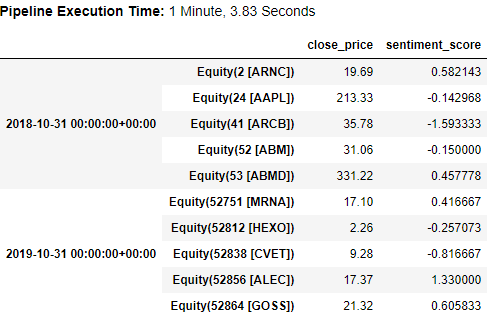
总结一下:
要点
定义流水线的 Pipeline 里有两个参数
columns = 想要的指标(字典)
screen = 想交易的空间(对象)
指标可以是没被处理的 returns, price 等等,也可以是被处理的 MA, RSI 等等(加入一系列计算)。
4
策略分析
现在我们已经知道如何从 Quantopian 中获取数据了,接着我们用流水线来建立一个非常简单的多空股票策略。
策略:做多情绪最高分的 350 只股票,做空情绪最低分的 350 只股票,情绪得分用 3 天移动平均方法来计算。
代码和解释如下(操作符 | 表示并集,操作符 & 表示交集):

接着运行流水线返回值 pipeline_output,并打印其首尾 5 行。
每一天都会根据 sentiment_score 选取 700 只股票,350 只分数最高,350 只分数最低。

得到根据情绪得分筛选的股票后,我们要获取它们从起始日到终止日对应的价格(注意每天对应的 700 只股票是不同的)。首先获取 pipeline_output 中 level 1 行标签,再用 prices 包获取价格。
接着调用 Quantopian 里的因子分析包 Alphalens,根据分位段数(2 段)来对情绪因子分成两类,并计算 1 天、5 天、10 天的收益。
打印 factor_data 首尾 5 行,结果如下,
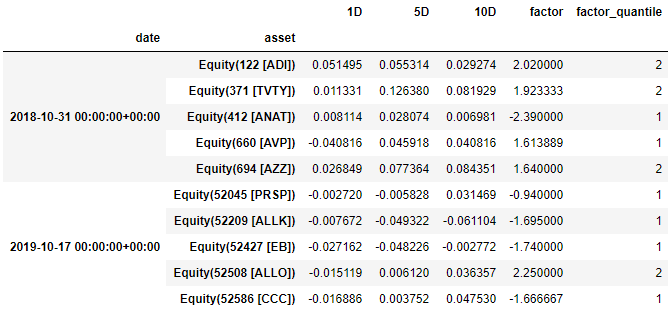
我们期望看到情绪因子能够很好的分类股票,即在 1 天、5 天、10 天窗口中,两个分段中的股票平均收益一个为正,一个为负。

让我们看看 mean_return_by_q,顾名思义,按照类别并在三个窗口下计算的均值收益。
mean_return_by_q
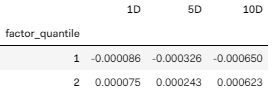
将 mean_return_by_q 可视化出来得到下图,很明显在 quantile 1 中三个窗口下的股票均值收益全部为负,在 quantile 1 中三个窗口下的股票均值收益全部为正。侧面证明用情绪因子来区分股票收益的表现还不错。

此外我们还可以计算用情绪因子加权的多空股票组合的 5 天累积收益。


五天累积收益总体趋势向上,但在 2019 年 3, 5, 9 月时有较大的回调。
总结一下:
要点
交易策略在流水线中制定,用 alphalens 里面的工具来验证交易策略,比如选取的因子是否能解释收益。
5
交易算法
确定好交易策略之后,我们会在 Quantopian 里的集成开发环境(Interactive Development Environment, IDE)中
构建交易算法(本节内容)
附上数据流水线(第 6 节)
构建投资组合(第 7 节)
分析回溯测试(第 8 节)
交易算法的核心函数有三个:
initialize(context)
before_trading_start(context, data)
schedule_function(func, day_rule, time_rule)
下面来一一说明:
initialize
顾名思义,initialize() 在算法开始运行时就被调用,里面有个参数起名为 context。它是一个字典型变量,可以在整套算法中的任何地方使用并更新。要获取它里面的属性,用操作符 . 来进行,比如
context.some_attribute
因此在 initialize() 函数里可以用 context 初始化一些交易前先定好的参数,比如最大杠杆比例、最大持仓比例等等。
context.max_leverage = 1
context.max_pos_size = 0.1
before_trading_start
顾名思义,before_trading_start() 在开市前才被调用,它需要两个参数:
context:上面已解释过
data:所有历史数据
before_trading_start() 也是调用流水线得到其返回值的地方,并在构建投资组合前做数据预处理的地方。
schedule_function
顾名思义,schedule_function() 会根据市场开市闭市时间来运行,它需要三个参数:
func:自已定义的函数,在以下两个参数确定的时间段中运行
day_rule:通常设置为 date_rules.week_start()
time_rule:通常设置为 time_rules.market_open()
需要注意的是,schedule_function() 要定义在 initialize() 里面,而自定义的函数 func() 需要 context 和 data 两个参数。
现在让我们来创建一个交易算法的简易框架,代码如下:
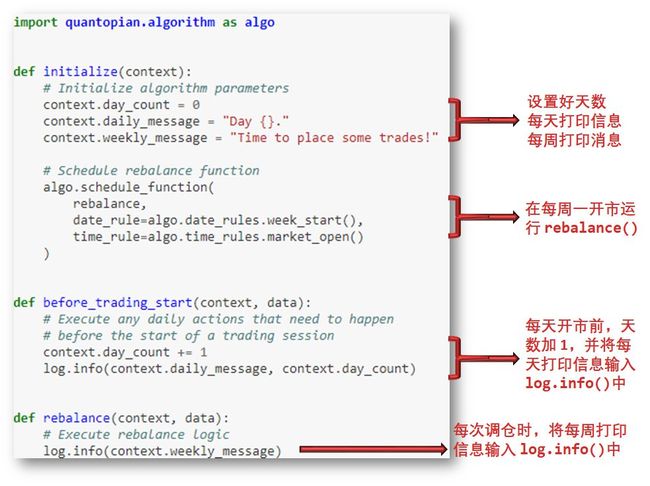
注意,上面的代码只能在 IDE 里运行,不能在 Jupyter Notebook 里运行。IDE 界面如下。
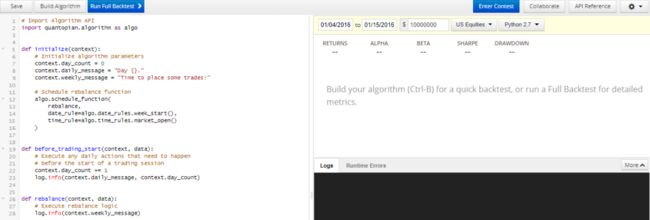
设定起始日和终止日为 2019-1-4 和 2019-1-15,再点击上图左上角的 Build Algorithm,得到下图的策略评估图以及日志记录 (log)。其实上面代码里没有任何交易策略,因此我们看到 Algorithm 0%,此外为了评估该策略,我们会选取 SPY 作为基准,Benchmark 在这两周涨了 6.07%。
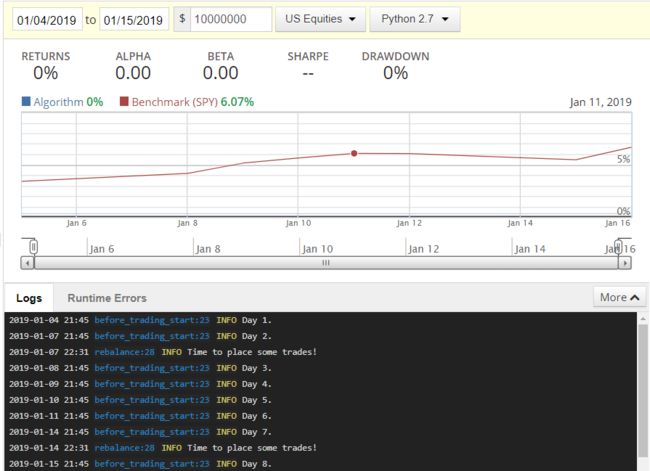
其实上图有用的信息是 log 里面的,我们可以发现该日志
每天打印 Day x,对应着代码里的 daily_message
每周打印 Time to place some trades!,对应着代码里的 weekly_message
除了点击 Build Algorithm,我们还可以点击左上角蓝色的 Run Full Backtest,得到下图。
由于这个交易算法没有编写任何策略,因此没有任何有意义的输出指标。
总结一下:
要点
交易算法里三大核心函数:
initialize(context) 在算法运行时就被调用,用来设置参数,存在字典型变量 context 里面
before_trading_start(context, data) 在每天开市前被调用,用来预处理数据
schedule_function(func, day_rule, time_rule) 在 initialize() 里面定义,func 是自定义函数,写成
func(context, data)
6
数据流水线
交易算法的骨架有了,是时候添加血肉了,即数据。本节将数据流水线整合到交易算法中。
回忆在第 2 节中用 make_pipeline() 定义流水线时,我们需要设定起始日和终止日,但是在回测时,流水线是每天要跑的,因此不需要设定起始日和终止日。
为了能在交易算法中使用流水线,可在 initialize() 用 attach_pipeline() 方法:
第一个参数是流水线对象,即 make_pipeline() 的返回值
第二个参数是字符串,当做流水线的名称
代码如下:

数据流水线就是用来在开市前处理数据的,那么我们需要在 before_trading_start() 里使用它,可以用
pipeline_output() 函数
initialize() 中定义的 'data_pipe'
来生成流水线,并存到 context.pipeline_data 里。在下例中,我们在 rebalance() 函数打印 context.pipeline_data 的前 10 行。代码如下:
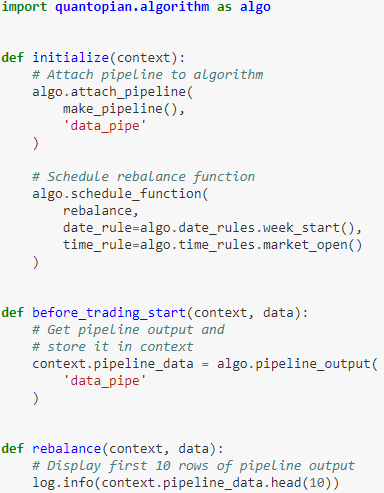
最后,我们来看一个实际的例子。使用流水线来
获取情绪得分的 3 天移动平均值
剔除情绪得分为空的可交易的股票

现在,我们的算法每天都会选择可交易的资产范围(screen),并产生可用于确定投资组合中资产分配的 alpha 分数(sentiment_scaore)。接下来,我们来看看如何根据数据流水线生成的 alpha 分数来构建最佳投资组合。
总结一下:
要点
交易算法里三大核心函数:
在 initialize() 里用 attach_pipeline() 接受「make_pipeline()」和「流水线名称」作为参数。
在 before_trading_start() 里用 pipeline_output() 和「流水线名称」来得到流水线,并储存在 context.pipeline_data 里。
7
组合优化
骨架(交易算法)和血肉(数据)都有了,我们需要用皮把骨架和血肉包在一起。姑且把组合的最优权重类比成皮吧。
组合优化
我们的目标是最大化基于 alpha 分数的收益,当然要遵循一些规则或限制。该问题通常被称为组合优化(portofolio optimization)问题。目标(objective)和限制(constraint)都是在 rebalance() 函数中设定的。
Quantopian 里的 API quantopian.optimize 让一切变得简单。首先将情绪分数(sentiment_score)定义为 alpha,而优化组合的目标就是最大化此alpha,代码如下。
import quantopian.optimize as opt
def rebalance(context, data):
# Retrieve alpha from pipeline output
alpha = context.pipeline_data.sentiment_score
if not alpha.empty:
# Create MaximizeAlpha objective
objective = opt.MaximizeAlpha(alpha)
接着我们将最大杠杆率、最大仓位比例和最大换手率分别设定为 1.0, 0.015 和 0.95。代码如下:
# Constraint parameters
context.max_leverage = 1.0
context.max_pos_size = 0.015
context.max_turnover = 0.95
设置头寸仓位在 [-0.015, 0.015] 之间,设置 Dollar Neutral,设置最大杠杆率为 1,设置最大换手率为 0.95,将这是个限制放入 constraints 列表中。代码如下:

风险管理
回顾上贴〖Quantopian Risk Model, QRM〗的内容,QRM 就是一个风险模型,可以被用来管理组合在 16 个风险因子(11 个行业因子和 5 个风格因子)上的暴露程度。
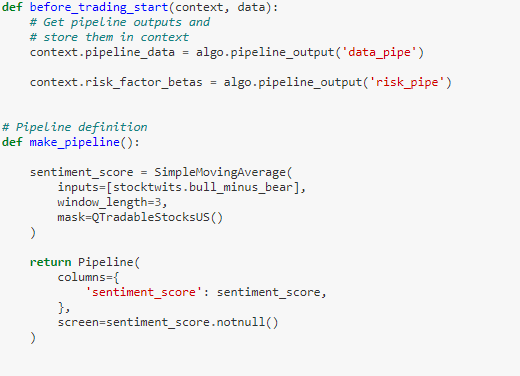
上贴最后也讲了,我们可以 Quantopian 里的 risk_loading_pipeline API,可以获取所有股票在任何历史时期的行业因子收益和风格因子载荷。我们可以类比数据流水线(data_pipe)来实现风险流水线(risk_pipe)。代码如下:

此外我们也需要给风险因子暴露设定限制,用 RiskModelExposure() 函数。
factor_risk_constraints = opt.experimental.RiskModelExposure(
context.risk_factor_betas,
version=opt.Newest
)
现在我们已经考虑的所有东西,完整代码如下。通过上面详细的分析,现在再看代码容易理解了吧。


在 IDE 界面中设定起始日和终止日为 2018-10-31 和 2019-10-31,再点击左上角蓝色的 Run Full Backtest,得到下图。
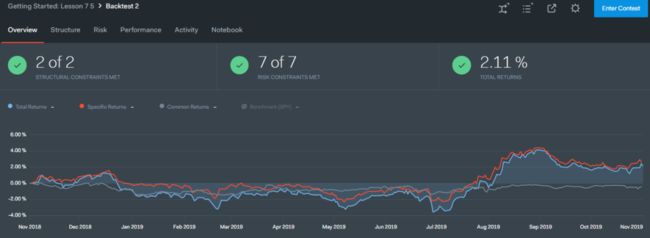
在「 Risk 界面」下还可以查看任何时点上的风险暴露。

8
回测分析
一旦你做完了回测,点击 Notebook 标签。

我们得到下图中的字符串,注意每次得到的字符串都不一样。

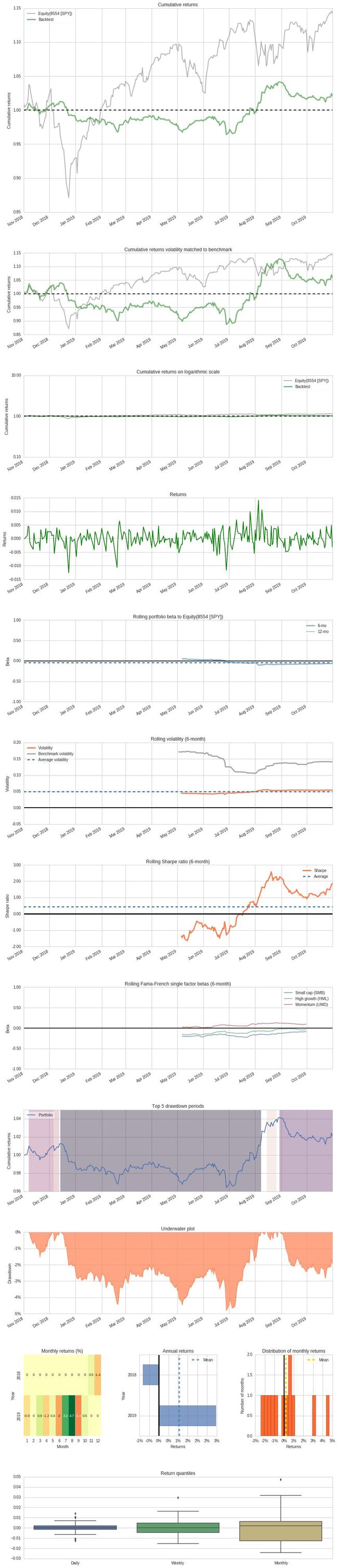
执行此单元格(Shift + Enter)会将回测生成的数据加载到研究笔记本中,并使用它来创建 Pyfolio tear sheet。Pyfolio 是 Quantopian 用于投资组合和风险分析的开源工具。它提供了许多可视化工具,帮助我们更好地了解算法以及风险暴露。
例如,下图第 4 张子图(rolling beta)显示了投资组合随时间推移的市场风险暴露。我们之所以要构造多空股票交易算法的原因之一是要保持与市场的低相关性(low correlation),因此我们希望该图在整个回测期间始终保持在 0 附近。
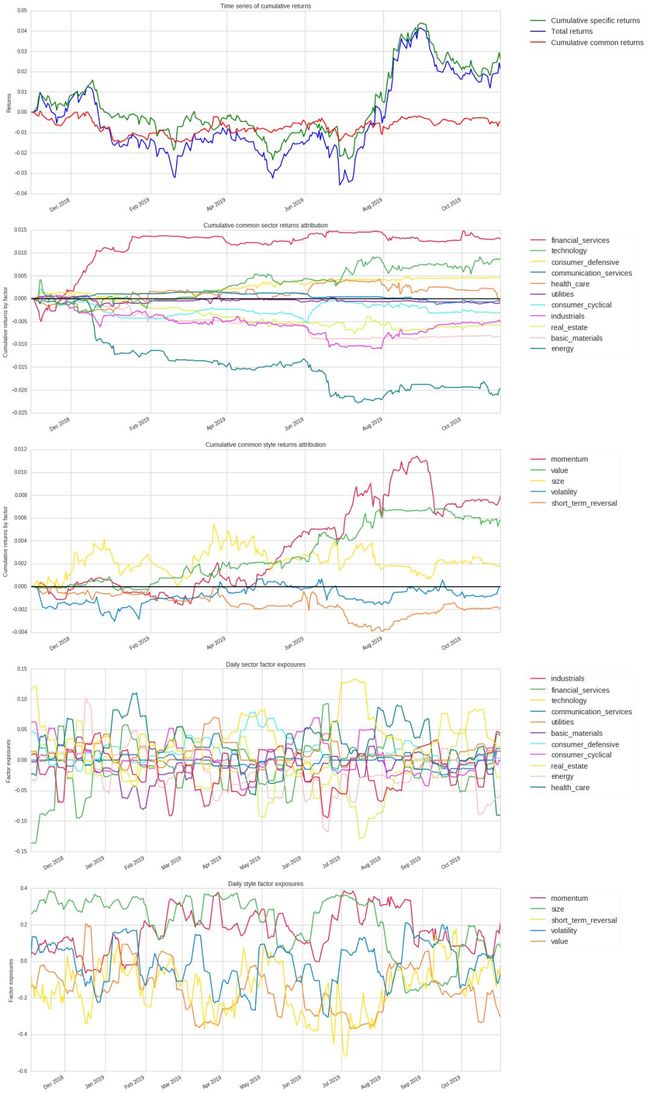
此外,Tear Sheet 可以做性能归因(Performance Attribution),下图展示使用 QRM 来分析多少收益归因于你的交易策略,多少收益来自共同风险因子。

从下图的第 1 子图可看出,投资组合的大部分收益来自特定收益(Specific Return)。 这表明算法性能并非来自于共同风险因子,该交易算法是好的。
9
总结
我还是喜欢一图顶千言,看下图就行了。

下帖细讲 Pipeline。Stay Tuned!
