左转向善,右转向恶,2020 年的九大 AI 风向标
2017 年底,美国社交新闻网站 Reddit 一位名叫 deepfakes 的用户运用 AI 制作了一段“假”色情视频,将《神奇女侠》女主角盖尔·加朵的脸嫁接到一个成人电影女星身上,一时间引起轰动。
自此,AI 换脸核心算法就正式被命名为 DeepFakes,并一直颇具争议。不过,它“有趣又愚蠢”的一面,也为媒体公司提供了新的机会。
2019 年 12 月,社交媒体应用 Snapchat 以 1.66 亿美元收购了乌克兰图像和视频识别初创公司 AI Factory,两者此前曾合作,使用户能将自拍照片插入 GIF 中以创建动画化的 AI 换脸。另外,中国公司字节跳动的短视频应用 TikTok 也在开发类似功能。三星发表了一篇有关使用神经网络创建逼真的“说话人的头部”的论文。下面,左图显示了源图片,右图则是由 AI 生成的。

(来源:三星)
英国《金融时报》报道,价格昂贵且费时的传统的计算机生成图形,与最近出现的 AI 换脸技术正形成了鲜明对比。因此,好莱坞也朝着“数字化复活”那些“五、六十年代”电影中的演员这一方向发展。
而在零售方面,AI 换脸还使品牌为消费者提供超个性化的视觉营销。如初创公司 Superpersonal 会将用户的脸部视频片段替换为虚拟试装。

AI 换脸在影响者营销方面也有所作为。在非政府组织“疟疾必死”(Malaria Must Die)的活动宣传视频中,初创公司 Synthesia 使用 Deepfake 技术让贝克汉姆在视频中说了 9 种不同的语言。

(来源:“疟疾必死”(Malaria Must Die))
而在中国,2019 年 3 月,B 站上一个名叫“换脸哥”的用户上传了一条《射雕英雄传》片段,将其中黄蓉饰演者朱茵的脸换成了杨幂的脸。

(来源:网络)
不久,更多作品跟风而至,网友们利用该技术,将某平台女主播的脸换成刘亦菲、杨幂、唐嫣、范冰冰等女星的脸。另外,一款名叫 “ZAO” 的软件受到热捧,通过这款软件,用户可以将影视剧、综艺节目片段中明星的脸换成自己的脸。不过这一软件也被质疑涉及隐私泄露和侵权等问题。
关键词
个性化
零售中的换脸就是将消费体验加倍。该技术将促进电子商务体验和虚拟在线试用。
针对性的广告
随着技术的商品化,本地化的广告,如使用不同语言的即时配音,将成为更加可用的成果。
创意领域的自动化
在电视和电影行业中使用 AI 换脸可能会导致续集、衍生产品和现有内容的文化改编的泛滥。在铸造和建模等对人脸要求非常高的领域,AI 换脸可能带来负面影响。
下一代黑客:愚弄 AI 和利用 AI 的攻击
AI 时代下的黑客正朝两个方向发展:愚弄 AI 系统和利用 AI 发起攻击。
在 2019 年,总部位于悉尼的安全公司 Skylight Cyber 的研究人员破解了网络安全初创企业 Cylance 开发的 AI 杀毒软件。Skylight 报告说,它发现了其 AI 模型中的漏洞,并利用它创建了一个通用旁路,从而使恶意软件无法被发现。

(来源:CB Insights)
黑客还可以通过污染数据来欺骗 AI。并且,还可能会在图像上引入人眼看不见的细微扰动,以欺骗神经网络。
AI 本身也可用于制造更复杂的、针对性强的网络攻击。有关 AI 产生的语音欺骗的报道最早出现于 2019 年 3 月的欧洲。据《华尔街日报》报道,犯罪分子通过 AI 语音生成软件,成功模仿并冒充一家英国能源公司的母公司 CEO,来欺骗其多位同事和合作伙伴,一天内多次诈骗并转移资金,使该公司损失约 173 万元。
另外,IBM 早在 2018 年就开发的一种名为“DeepLocker”的恶意软件表明,AI 可以绕过网络安全保护进行攻击。DeepLocker 被描述为“一种由 AI 驱动的具有高度针对性和规避性攻击工具的新型恶意软件”,只有在识别出如视觉、音频、地理定位和系统级特性等特定标准时,才会“解锁”恶意软件以开始攻击。由于几乎不可能确定所有可能的触发因素,就使深度神经网络的反向工程变得十分困难。
关键词
黑客无情
如今所有人比以往任何时候都更容易使用 AI 工具,这为黑客提供了更多的土壤。
网络 AI 初创企业可能面临新的攻击
黑客已经证明,利用机器学习模型的内在偏差并欺骗算法很容易。
重工业准备不足
在过去的十年中,已经出现过几例针对工业控制系统的恶意程序肆虐案例。如震网病毒 Stuxnet 2010 年被用于伊朗核设备攻击、Black Energy 2015 年被用于乌克兰电网攻击、Havex 攻击欧洲境内组织,以及 Industroyer 2016 年侵入乌克兰工控系统等。调查显示,重工业抵御网络风险的能力还很落后,也没有为 AI 恶意软件等更高级的威胁做好准备。
AutoML:未来“让 AI 学习设计 AI”
机器学习的兴起带动了这一波人工智能的浪潮。而自动机器学习 AutoML 则有可能引领下一代潮流。
AutoML 是一套用于自动化神经网络设计和训练的 AI 工具套件,它通过减少对 AI 专业知识的依赖,降低企业的准入门槛,使技术更民主化。通常,构建表现优良的机器学习应用,需要非常专业的数据科学家和领域专家。而 AutoML 的目标则是在即使没有统计学和机器学习方面的广泛知识的情况下,也能自动构建机器学习应用。
“神经网络的设计非常耗时且对专业要求很高,为此,我们创建了一种名为 AutoML 的方法,希望让神经网络自己设计神经网络。”谷歌 CEO 桑达尔·皮查伊(Sundar Pichai) 在博文中写道。于是,谷歌于 2017 年正式为此创造了 “ AutoML”。

(来源:谷歌)
而自谷歌提出这一概念后,用于 AI 设计的 AutoML 工具,包括数据准备、训练、模型搜索及特征工程的采用率一直在逐渐增加。如 Waymo 最近与谷歌合作,使寻找最佳神经网络架构的过程自动化,从而使自动驾驶汽车能够从激光雷达(光检测和测距)数据识别树木、行人和车辆。谷歌云 AutoML 还可用于计算机视觉、视频处理、翻译和 NLP 任务。初创公司还为企业提供即插即用的解决方案。
同时,中国也出现了不少相关研究,称能够解放算法工程师,让 AI 自动化。在去年的数据挖掘领域顶会 PAKDD 的 AutoML 挑战赛上,中国公司深兰的 DeepBlueAI、微软&北航团队、清华大学等团队都有上榜。
其中,深兰科技团队设计的机器学习框架通过融合不同时期的数据以及结合 DNN 和 Light GBM 的训练来自适应概念漂移,并引入了自适应采样来缓解类别不平衡,同时在一定时间间隔上让模型重复训练以适应概念漂移,实现终身机器学习。
关键词
人才短缺
在 AI 专家严重短缺的现实情况下,AutoML 能帮 AI 知识不足的企业将技术民主化。
成本和复杂性
即使对于专家而言,设计神经网络也是一个耗时的手动过程。AutoML 可创建更好的解决方案,并降低与试错相关的计算成本。
联邦学习将带来全新的数据合作生态系统
联邦学习(Federated Learning)在 2016 年由谷歌最先提出,是一种新兴的人工智能基础技术。
在谷歌 2019 年第二季度的财报会议中,谷歌 CEO 桑达尔·皮查伊强调,对谷歌来说,联邦学习和一些其他的隐私管控是其现阶段重点的关注和努力方向。他说:“我们一直以来都很关注用户的隐私及管理,三年来我们一直在提议并推进联邦学习的使用,这也是我们现阶段的重点之一。”
最初联邦学习被用在预测安卓系统用户在使用键盘时下一步会输入的内容,也被用在谷歌的文本预测软件以及火狐浏览器 URL 搜索方面。其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证在合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。
如下图所示,联邦学习可以让装配有 Gboard (谷歌推出的虚拟键盘)的软件在不向谷歌发送原始用户个人数据的前提下提升其 AI 模型。这样以来,用户手机中的数据还保存在用户手机中,而并未被发送或储存到某个中央云服务器中。

(来源:谷歌)
云服务器将某个人工智能算法的最新版本发送到某一用户群的设备上,然后用户的手机可以根据本地数据更新 AI 模型。这时,发送回云服务器的只是更新部分,而非更新所使用的本地数据。云服务器可以再根据接收到的更新部分,提升算法的全局状态(“global state”)。
联邦学习既可以保护用户数据,又不会影响 AI 算法的性能提升,其正在为包括医疗健康和银行业在内的、对于数据使用受到高度管控和关注的行业提供新的可能。
英伟达 AI 驱动的软硬件框架 Clara 主要针对医疗健康场景,现也支持联邦学习。其使用方包括美国放射医学院、麻省总医院、布列根和妇女医院临床数据科学中心、UCLA 医学中心等。此外,英伟达还与医疗健康领域初创公司 Owkin 合作,Owkin 主要从事使用联邦学习进行癌症患者的抗药性预测方面的业务。

(来源:英伟达)
中科院计算所泛在计算系统研究中心针对帕金森症建立了 FedHealth 框架,使用联邦学习、迁移学习、增量学习来判断病人服药前后的状况变化、用药效果等。
金融领域,中国的微众银行正与腾讯云和加拿大人工智能研究中心 Mila 合作进行联邦学习方面的研究。今年 1 月底,微众银行 AI 团队研发并推出了其联邦学习开源框架 FATE(Federated AI Technology Enabler),该框架采用了多种安全计算协议,从而保证在符合监管规定的数据保护前提下,进行跨域信息合作。
当然,联邦学习作为一个新兴概念正在越来越广泛地应用在其他领域,比如智能城市、智能制造等方面。中国公司(包括京东、华为等)也在积极布局联邦学习方面的应用,相信在未来可以看到更多联邦学习相关的落地应用。
关键词
全局模型+本地数据
通过使用联邦学习,用户可以通过使用本地数据训练 AI 模型,并只将 AI 模型的更新部分更新到中央云端。云端通过所有网络中使用者发送的模型更新来优化其模型应用。
数据多样化
联邦学习可以助力跨域合作,从而通过更加多样化的本地数据优化全局模型。
Alphabet 将通过 AI 主导智慧城市合约
凭借其强大的 IoT 和机器学习能力,这家一万亿美元的 Al 巨头正在积极布局城市发展及智慧城市规划领域。
通过联手政府,Alphabet 正在许多城市创造新的街区,并重新规划房地产、公共能源设施、交通等布局。去年第二季度,Alphabet 旗下子公司 Sidewalk Labs 发布了一份 1500 页的方案,其中详述了如何通过与政府和其他企业的合作,以 13 亿美元在多伦多打造一个智慧城市的项目。项目的重点和亮点就集中在 AI 在政府和城市规划的应用上。

(来源:Sidewalk Labs)
从概念上来看,智慧城市可以包括智慧医疗、智慧出行、城市监控、数据基础设施以及许多其他 AI 和机器学习的应用领域。下图列出了 Alphabet 在上述领域的主要布局,其优势不言自明,这也让其成为从房地产到能源到交通领域再到咨询服务方面强有力的市场竞争者。
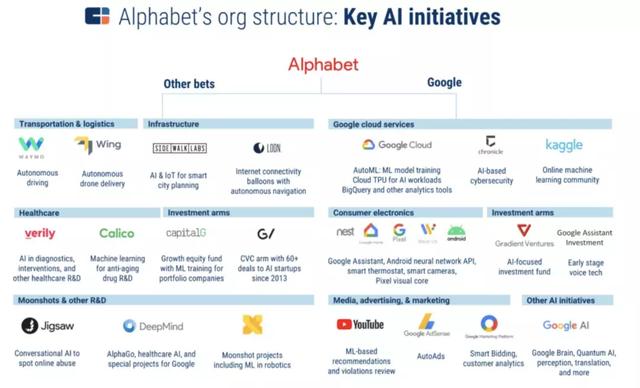
(来源:CB Insights)
在这里略微说一下两家小型初创公司 Replica 和 Coord。Replica 主要使用机器学习来为通勤行为建模,并关注影响通勤方式选择的因素等。应用方面已有与伊利诺伊政府签订的 360 万美元的三年合约,以及与波特兰政府的一年服务协议。Coord 主要关注使用机器学习绘制街道资产图景。其正在邀请各个城市参与其发起的“数字街道挑战”活动,最终的获胜城市将可以免费试用其技术,当然 Coord 也可以通过这次活动调试其平台性能及调整其策略方向。
上文说到的 Alphabet 旗下子公司 Sidewalk Labs 在处理特定城市发展问题方面正在超过较小型的初创公司(如 Replica 和 Coord)。Sidewalk Labs 在多伦多的试点项目中突出了减少温室气体排放和更智能的资源管理两个方面。通过机器学习工程师分析传感器收集的数据以及搭建管理系统,来建立能耗以及可持续性方面的推荐引擎和预测模型。
关键词
政府青睐
Alphabet 在 AI 方面的专业让其自然而然地成为政府合作青睐的对象,加之旗下子公司,比如 DeepMind,、Waymo、lab X 等,更为其竞争力加码。
端到端解决方案
相较于其他聚焦某一个领域的供应商,Alphabet 擅长基于机器学习的几乎所有智慧城市相关方面,从城市发展工具到自动驾驶汽车再到能源管理。
分担财务风险
Alphabet 有强大的实力分担财务风险并进行前期方面的投资。比如 Sidewalk Labs 就宣称,在其与其他机构或企业的合作中,其可以分担前期的创新成本,并在后期达标后获得报酬。这样一来,其与政府或相关机构在进行技术合作或者试验的时候,增加了合作的成功可能。
能源驱动的 AI 将会被用来解决能源问题
2020 年,更节省能源的 AI 将成为一个重要的话题。从科技巨头、汽车制造商到油气巨头,无一不在寻求削减成本、提升效率、降低能耗。
一直以来,我们都在说人工智能,也在强调其所需要的算力。但是算力不是凭空产生的,是需要消耗能量的。在我们不断强调要提高算力让 AI 变得更聪明的时候,我们也需要考虑使用更具可持续性的能源解决方案。
现阶段 AI 的进步多是自上而下的,也就是科技巨头在领导 AI 方面的研发以及开发开源工具方向,这主要是因为科技巨头在算力方面占有巨大优势。Fast Company 曾报道,2018 年谷歌在其 BigGAN 实验中,为创造出高度逼真的图像,消耗了相当于普通美国家庭半年的平均电量。
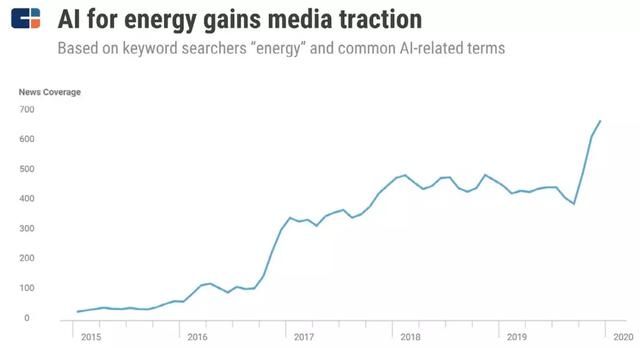
(来源:CB Insights)
相较于云计算,边缘计算并不具有同等的算力和资源,所以在 AI 越来越多地被应用在边缘设备(如电话、相机)的过程中,能源利用效率正变得越来越重要。这里第一个值得关注的方面是更加节能的 AI 设备。
Xnor.ai 是一家致力于开发低能耗边缘 AI 工具的初创公司,它关注超低功耗、可运行 AI 算法的相机。其硬件工程和机器学习团队曾提出一个问题:“(我们)是否可以开发出一台能够在没有电池的情况下运行深度学习模型的硬件设备及机器学习架构? 它可以是非常低功耗,甚至太阳能驱动的。”今年初,苹果公司收购了 Xnor.ai,这一举动反映了苹果在低能耗 AI 方面的布局,以及其在苹果手机的 AI 芯片及 VR 应用方面的积极努力。
中国深圳耐能人工智能有限公司(Kneron)主打高性能、低功耗、低成本的 AI 解决方案,最近发布了一款针对边缘设备的低耗能 AI 处理器。本月初,耐能宣布完成 4000 万美元 A2 轮融资,由李嘉诚旗下维港投资领投,其资方包括阿里巴巴创业者基金、高通、中科创达、红杉资本子基金 Cloudatlas 等,总计获得了超过 7300 万美元的融资。
另一个值得关注的方向是用于大型能源工厂及其设备的 AI 管理预测工具。比如,比尔·盖茨投资的初创公司 Heliogen 主要集中于一些能源行业的细分市场,比如通过使用 AI 算法来控制太阳能发电系统中的定日镜。
根据天气预报的数据以及收集到的风力发电机的数据,DeepMind 的神经网络可以提前 36 个小时预测未来风能产量。基于这些预测,DeepMind 的模型可以提前一天将如何实现最优交付告知电网企业。对电网企业来说,能够有计划地调度能源非常重要。
谷歌一直在积极推动在其数据中心使用可再生能源,而且它正在使用 AI 来帮助实现这一行动。通过与 DeepMind 合作,借助其神经网络来提高风能产量。

(来源:Google AI research)
关键词
超低功耗的机器学习设备
对于在边缘设备(如智能手机、智能家居摄像头等)来说,能效正在成为一个重要的考量因素。
大型能源企业
越来越多的大型云服务商正在向使用可再生能源方向转变,并通过融合 AI 来提高可再生能源产量、简化数据中心操作流程。
精简操作
AI 可以很好地预测可再生能源产量、将电网管理自动化、帮助精确钻探油井以及为智能家居和商业建筑中的可持续能源管理提供解决方案。
解决AI的小数据问题是重点
对深度学习算法,如果没有足够多的数据进行训练,有两种方法可以解决这个问题:生成合成数据,或者开发可利用小数据展开工作的 AI 模型。
众所周知,深度学习需要数据,其模型训练都是在大量标记数据的基础上进行的,比如,利用数以百万计的动物标记图像训练 AI 学会识别。但大量标记数据对某些应用来说并不适用,在这种情况下,从头开始训练一个 AI 模型,即使可能,也充满了困难。
一个潜在的解决方案是用合成数据扩充真实数据集。这在自动驾驶领域得到了广泛的应用。自动驾驶汽车在逼真的模拟环境中行驶数百万英里,会面临暴风雪以及行人突发行为等各种情况,而针对这些情况,我们很难获取到真实数据。
合成数据正在出现,如下图所示的来自英伟达(NVIDIA)的合成核磁共振(MRI )图像,就用于扩充罕见疾病的真实数据。

(来源:英伟达)
围绕数据问题的另一种解决方案是开发能够基于小数据集进行学习的 AI 模型。一种名为迁移学习(transfer learning)的方法已在计算机视觉任务中得到应用。该方法使用预先训练的 AI 算法来执行一个有大量标记数据的任务(如识别图像中的汽车),然后将该知识转移到另一个数据很少的不同任务上(如识别卡车)。使用预先训练的模型就像包饺子时使用现成的饺子皮,免去了和面的步骤。

图 | 美国有关迁移学习专利的统计(来源:CB Insights)
虽然预先训练的模型在计算机视觉领域已经取得了长足的发展,但在自然语言处理(NLP)领域,由于缺乏标记数据,到目前为止,一直是一项极具挑战的工作。不过,一种名为自我监督预训练(self-supervised pre-training)的方法在自然语言处理领域中逐渐流行起来。
所谓自我监督预训练,首先要根据网络上的大量数据训练 AI 模型。例如,OpenAI 进行了一项计算极其密集的任务:用 800 万个网页作为训练数据,训练一个基于给定文本预测下一文本词汇的 AI 模型。这一方法被称为自我监督学习,因为这里不涉及“标签”:AI 通过基于句子中的其他单词预测一个隐藏的单词来学习语言。研究员 Jeremy Howard 在 Fast.ai 的一段摘录中解释了为什么这些自我监督语言模型非常重要:
“我们不一定对语言模型本身感兴趣,但事实证明,能够完成这一任务的模型在学习语言的过程中必须了解语言的本质,甚至要对世界有所了解。当我们把这个预先训练好的语言模型用于另一项任务(比如情感分析)时,我们可以用很少的数据获得比较满意的结果。"
另一个典型的例子是谷歌 BERT,其 AI 语言模型不仅可以根据前文内容进行预测,还可以基于后文展开,也就是说该模型采用了双向语言模型的方式,能够更好的融合前后文的知识。

(来源:谷歌)
由 Yann LeCun 领导的 Facebook AI 研究部门一直都看好自我监督。比如,他们首先会训练出一个语言模型(类似上文),然后进行预训练,并对其进行微调以进行仇恨言论的识别。

(来源:Facebook)
最近,Facebook 还开源了其自我监督语音识别模型,很好地解决了小型研究项目对人工标记文本的需求问题。非英语语言的标注训练数据往往数量有限,针对这个问题, Facebook 开源了代码 wav2vec,这对非英语语言的语音识别尤其有用。
关键词
自然语言处理
由于自我监督技术的出现,2020 年自然语言处理将成为人们关注的焦点。我们最终会看到像聊天机器人、高级机器翻译以及类似于人类的写作等更好的下游自然语言处理应用的出现。
大型科技公司牵头
因为开发预训练的语言模型需要进行大量的计算,针对小数据的 AI 模型的研究将是自上而下的。科技巨头正在开源自己的研究成果,以便其他研究人员可以将其用于下游应用。
合成数据及其工具
合成数据及其工具为那些无法像科技巨头那样访问海量数据集的小公司提供了公平的竞争环境。
量子机器学习为传统的AI算法注入活力
我们将很快看到结合了传统机器学习算法与量子 AI 的模型的实际应用。
二进制计算中信息存储为 0 或 1。与二进制计算不同的是,量子计算机是基于量子比特的。量子比特可以是 0 到 1 的任意值,或者同时具有这两个值的属性。因此,在运行计算方面有很大的优势。
但是,我们与传统计算机交互的方式并不适用于量子计算机。它需要专门的数据、算法以及编程。
量子机器学习借鉴了传统机器学习的原理,但其算法会运行在量子处理器上,这使得它们比传统的神经网络更快,并且解决了当前 AI 在海量数据集上进行研究所受到的硬件限制问题。
不过,量子神经网络(Quantum Neural Networks,QNN)的研究尚处于起步阶段。对此,谷歌曾表示:“传统的机器学习从诞生到建立监督学习的通用框架,花了很多年的时间。在量子神经网络的设计方面,我们还在探索。”
那么,QNN 算法将如何解决现实问题呢?
科技巨头和量子创业公司正在考虑一种混合方法,其中一部分任务由运行在传统计算机上的传统神经网络完成,另一部分则由量子神经网络增强。
比如,多伦多创业公司 Xanadu 正在将量子与传统相结合的 AI 应用于迁移学习,其结果在图像分类任务中有很好的应用前景。

(来源:Xanadu 研究论文, arxiv.org)
另外,自 2013 年以来,谷歌 AI 团队就一直专注于为量子计算机编写算法。与 Xanadu 一样,其近期目标是开发“可适用于量子设备的量子与传统相结合的机器学习技术”。谷歌 AI 团队曾撰文表示:“虽然目前关于 QNN 的工作主要是理论方面的,但在不久的将来,它们将可能会在量子计算机上进行测试并得以实现。”
在谷歌发表的两片研究论文中,其分别探索了以不同于传统神经网络训练方法的方式训练 QNN,以及在模拟中测试 QNN 执行简单图像分类任务的能力。
尽管当今最强大的量子计算机,包括谷歌正在开发的那些,已经可以控制 50 到 100 个量子比特。但研究人员表示,若要量子计算机产生更广泛的商业影响,至少达到控制需要几千个量子比特的水平。
鉴于量子信息的发展可能带给信息领域的影响,政府和各科技公司巨头都对量子技术研究展开了积极投资。 CB Insights 的数据显示,2019 年量子计算领域共完成 14 笔交易,涉及金额达 1.978 亿美元,相较 2018 年略有下降。

(来源:CB Insights)
其中,自 2015 年 1 月 1 日至 2020 年 2 月 9 日,就国家而言,相关交易数量占比位居前三位的分别是美国(45.3%)、加拿大(15.6%)以及英国(14.1%)。
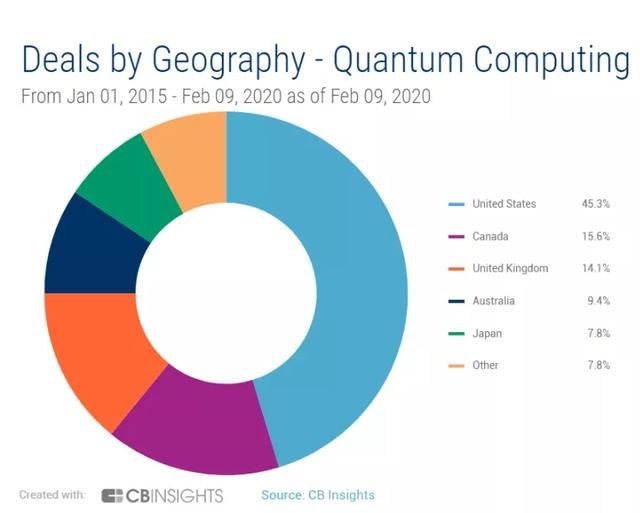
(来源:CB Insights)
那么,中国在该领域的投资情况如何呢?
2019 年 10 月,Nature 曾发表一篇专栏文章,分析了近年来私人投资大量涌入量子科技领域初创公司的情况。其中,针对中国的投资,文章指出,鉴于英语媒体报道以及西方分析公司的报道很少涉及中国的投资交易,所以在文章很可能缺少一部分中国数据。不过对于量子计算在中国的发展情况,文章援引了中国科学技术大学潘建伟教授的话表示,中国的量子技术产业化也在顺利进行。另外,专利的申请情况也能进行佐证:根据欧盟委员会联合研究中心的数据,2012 年至 2017 年的量子技术创新专利中,超过 43% 来自中国的大学和企业。

(来源:Martino Travagnin/欧盟委员会联合研究中心)
关键词
与传统计算机结合
我们将开始看到世界上最强大的两种计算范式——量子计算和 AI ——通过与传统计算机结合来解决实际问题。
量子云计算
量子云计算是“云战争”中的最新前沿领域,所有主要供应商,包括 AWS、谷歌、IBM 和微软,都在大力投入其中。正如 Rigetti、微软和 OpenAI 在 2020 年发表的一篇论文中所强调的那样,这意味着量子计算机将与传统 GPU 和 CPU 协同工作。我们会看到云 AI 算法在这样的混合硬件平台上运行。
自然语言处理将帮助我们理解生命的构成要素
自然语言处理和基因组有一个共同特点,即都是由序列数据组成。自然语言处理的发展,为基因组学的研究带来了启发。
在本报告前述的自我监督学习案例中,研究人员会隐藏句子中的特定单词,让算法猜测缺失的单词,从而更广泛地学习语言。正如句子是由单词按序列组成的一样,蛋白质是按特定顺序排列的氨基酸序列。
来自德国的研究人员利用了一个类似于自我监督语言模型的概念对蛋白质进行分类。Facebook AI 研究部门和纽约大学的研究人员在蛋白质序列的海量数据集上使用了自我监督概念,用 AI 预测隐藏的氨基酸。

(来源:Biorxiv)
针对最近流行起来的基因组建模,DeepMind 开发了一种名为 AlphaFold 的算法,通过理解蛋白质折叠(基因组学中最复杂的挑战之一)来确定蛋白质的 3D 结构。

(来源:DeepMind)
虽然 AlphaFold 使用的是一种混合方法,但它借用了自然语言处理中的概念来预测氨基酸对之间的距离,以及连接它们的化学键之间的角度。
针对最近在中国爆发的新型冠状病毒肺炎,百度在今年 2 月初开源了其 RNA 预测算法 LinearFold。该算法可以大大缩短预测病毒 RNA 的二级结构的时间(将预测时间从 55 分钟缩短至 27 秒),从而帮助为前线医疗研究人员更好更快地解析病毒及开发疫苗。
关键词
更好的药物设计
蛋白质会根据环境因素动态地改变结构,所以了解其结构及折叠方式将为未知的靶点开发药物带来机会。
无需深入了解领域知识
AI 算法可以在不深入地了解领域知识的前提下,帮助蛋白质建模并了解其结构。
具有特定功能的蛋白质设计
为医疗保健和材料科学开发或优化具有特定功能的新的蛋白质设计将成为可能。
结语
以上为 CB Insights 整理出来的 2020 年 AI 趋势,虽然其中一些技术已经取得了初步进展,但不可否认的是,我们也也面临着很多技术及应用方面的挑战。
希望在 2020 年我们能看到更多跨越了这些挑战的技术突破。