GNN图神经网络详述-01
最近的有GNN学习需要,但这部分的资料整理还不算太多。本篇主要是作为知识梳理,主要参考综述性论文:Graph Neural Networks: A Review of Methods and Applications,在此基础上结合理解进行翻译和补充,首先想搞清楚目前的发展状况和一些主要的研究方向。
注:下文中出现的所有名词图的说法即为Graph,在此不讨论Graph与Network的区别。个人理解图是数学上提出的概念,网络是一种特殊的图,图由其邻接矩阵中包含的结构信息定义,网络可能在其顶点具有任意数量的辅助信息,边缘可以具有容量或重量等属性,也可以是其他变量的函数。
Graph研究简介
Graph是一种数据结构,常见的图结构包含节点(node)和边(edge),其中,节点包含了实体(entity)信息,边包含实体间的关系(relation)信息。图神经网络(GNN)是基于图结构的一种深度学习。
图是种非结构化(也可以表达结构化数据,只算是一种特例)的数据表达方法,这恰好对应到现实生活中的很多信息,在实际情况下我们面对的许多任务都需要处理非结构化的数据,如物理系统建模(physics system)、学习分指纹(molecular fingerprints)、蛋白质接口预测(protein interface)以及疾病分类(classify diseases),这些都需要模型能够从图结构的输入中学习相关的知识。
还有一些任务如文本(texts)和图片(images),并能够在提取出的图结构中进行推理(reasoning),比如句子的关系依赖树(dependency tree of sentences)和图片的情景图(scene graph of images),这些都需要图推理模型。GNN通过网络中节点之间的信息传递(message passing)来获取图中的依存关系(dependence of graph),GNN通过从节点任意深度的邻居来更新该节点状态,这个状态能够表示状态信息。
GNN模型基于信息传播机制,每个节点通过互相交换信息更新该节点自身的节点状态,直到达到某个稳定值。
GNN起源
卷积神经网络(CNN)和图嵌入(graph embedding) 启发了GNN的出现和发展。
首先,CNN因为能够提取出多尺度的局部空间特征而被熟知,并将它们进行组合来构建更加高级的表示(expressive representations)。如果深入研究CNN和图结构的特点,可以发现CNN的核心特点在于:
- 局部连接(local connection)
- 权值共享(shared weights)
- 多层结构(multi-layer)
欧几里得空间(左下)和非欧空间示意图(右下):

这些同样适用于图问题上,因为图结构是最典型的局部连接结构,其次,共享权重可以减少计算量,另外,多层结构是处理分级模式(hierarchical patterns)的关键。最主要的不同之处在于,CNN只能在欧几里得数据(Euclidean data),比如二维图片和一维文本数据上进行处理,而这些数据只是图结构的特例而已,对于一般的图结构,可以发现很难将CNN中的卷积核(convolutional filters)和池化操作(pooling operators)迁移到图的操作上。
对于图嵌入(Graph Embedding),实际上嵌入(Embedding)就是对图的节点、边或者子图(subgraph)学习得到一个低维的向量表示,传统的机器学习方法通常基于人工特征工程来构建特征,但是这种方法受限于灵活性不足、表达能力不足以及工程量过大的问题,我们常提及的词嵌入方法常见的模型有Skip-gram,CBOW等,而图嵌入领域的常见模型有DeepWalk,Node2Vec等,但是这些方法有两种缺点:
- 节点编码中权重未共享,导致权重数量随着节点增多出现线性增大,
- 直接嵌入方法缺乏泛化能力,意味着无法处理动态图以及泛化到新的图。
GNN和传统神经网络的区别
再次比较一下GNN和先提出的一些神经网络的区别,比如当前常用的深度神经网络CNN和RNN,输入是结构化的数据,如图像和文本序列,因为它们都需要节点的特征按照一定的顺序进行排列,但是,对于图结构而言,并没有天然的顺序而言,如果使用顺序来完整地表达图的话,那么就需要将图分解成所有可能的序列,然后对序列进行建模,这种方式非常的冗余以及计算量非常大,与此相反,**GNN采用在每个节点上分别传播(propagate)**的方式进行学习,由此忽略了节点的顺序,相当于GNN的输出会随着输入的不同而不同。
另外,图结构的边表示节点之间的依存关系,传统的神经网络不是显式地表达中这种依存关系,而是通过不同节点特征来间接地表达节点之间的关系。通常来说,GNN通过邻居节点的加权求和来更新节点的隐藏状态。
最后,就是对于更高阶段的人工智能来说,可靠的推理能力是一个非常重要的研究主题,人类大脑的推理过程基本上都是基于图的方式,这个图是从日常的生活经历中学习得到的。GNN的作用是从非结构化数据比如情景图片和故事文本中产生结构化的图,因为目前能够使用和存储的数据还是以结构化的数据为主,最终目的是能为更高层的AI系统作补充。
GNN分类
这篇论文对GNN模型分类如下:
- 图卷积网络(Graph convolutional networks)和图注意力网络(graph attention networks),因为涉及到传播步骤(propagation step)。
- 图的空域网络(spatial-temporal networks),因为该模型通常用在动态图(dynamic graph)上。
- 图的自编码(auto-encoder),因为该模型通常使用无监督学习(unsupervised)的方式。
- 图生成网络(generative networks),因为是生成式网络。
GNN模型概览
在该节中,首先提出原始的图神经网络问题以及处理方法,然后介绍各种GNN的变体模型,用来解决原始GNN的一些缺点,最后介绍三种通用的框架,包括MPNN、NLNN和GN。
如下表是论文通用的符号表示以及对应含义说明:

图神经网络
图神经网络的概念第一次在The Graph neural model一文中提出,该论文将现存的神经网络模型扩展到处理图领域的数据。在一个图结构中,每一个节点由它自身的特征以及与其相连的节点特征来定义该节点。GNN的目标是学习得到一个状态的嵌入向量(embedding) h v ∈ R s \mathbf{h}_{v} \in \mathbb{R}^{s} hv∈Rs,这个向量包含每个节点的邻居节点的信息,其中, h v \mathbf{h}_{v} hv表示节点 v v v的状态向量,这个向量可以用于产生输出 o v \mathbf{o}_{v} ov,比如输出可以是节点的标签,假设 f f f是带有参数的函数,叫做局部转化函数(local transition function),这个函数在所有节点中共享,并根据邻居节点的输入来更新节点状态,假设 g g g为局部输出函数(local output function),这个函数用于描述输出的产生方式。那么 h v \mathbf{h}_{v} hv和 o v \mathbf{o}_{v} ov按照如下式子产生:
h v = f ( x v , x c o [ v ] , h n e [ v ] , x n e [ v ] ) (1) \mathbf{h}_{v}=f\left(\mathbf{x}_{v}, \mathbf{x}_{c o[v]}, \mathbf{h}_{n e[v]}, \mathbf{x}_{n e[v]}\right)\tag{1} hv=f(xv,xco[v],hne[v],xne[v])(1) o v = g ( h v , x v ) (2) \mathbf{o}_{v}=g\left(\mathbf{h}_{v}, \mathbf{x}_{v}\right)\tag{2} ov=g(hv,xv)(2)
其中, x v \mathbf{x}{v} xv, x c o [ v ] \mathbf{x}{c o[v]} xco[v], h n e [ v ] \mathbf{h}_{n e[v]} hne[v], x n e [ v ] \mathbf{x}_{n e[v]} xne[v]分别表示节点 v v v的特征向量,节点 v v v边的特征向量,节点 v v v邻居节点的状态向量和节点 v v v邻居节点特征向量。
假设将所有的状态向量,所有的输出向量,所有的特征向量叠加起来分别使用矩阵 H \mathbf{H} H, O \mathbf{O} O, X \mathbf{X} X和 X N \mathbf{X}_{N} XN来表示,那么可以得到更加紧凑的表示:
H = F ( H , X ) (3) \mathbf{H}=F(\mathbf{H}, \mathbf{X})\tag{3} H=F(H,X)(3)
O = G ( H , X N ) (4) \mathbf{O}=G\left(\mathbf{H}, \mathbf{X}_{N}\right) \tag{4} O=G(H,XN)(4)
其中, F F F表示全局转化函数(global transition function), G G G表示全局输出函数(global output function),分别是所有节点 f f f和 g g g的叠加形式, H \mathbf{H} H是公式(3)不动点,并且在 F F F为收缩映射的假设下 H \mathbf{H} H被唯一地定义。根据Banach的不动点定理,GNN使用如下的传统迭代方法来计算状态参量:
H t + 1 = F ( H t , X ) (5) \mathbf{H}^{t+1}=F\left(\mathbf{H}^{t}, \mathbf{X}\right)\tag{5} Ht+1=F(Ht,X)(5) 其中, H t \mathbf{H}^{t} Ht表示 H \mathbf{H} H的第 t t t个迭代周期的张量,按照方程(5)迭代的系统按照指数级速度收敛收敛到最终的不动点解。
整个图更新的过程如下:
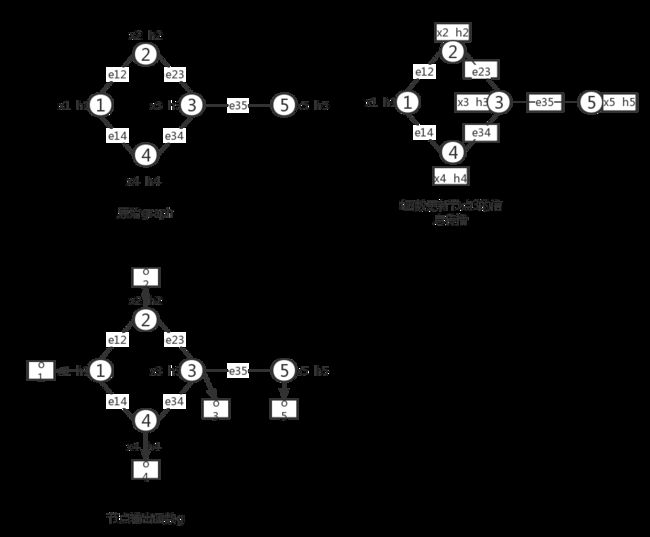
上面的过程定义了GNN的框架,下一个任务是学习函数 f f f和 g g g的参数,使用目标信息(使用 t v \mathbf{t}_v tv表示特定节点的标签)来进行监督学习,loss可以定义如下: l o s s = ∑ i = 1 p ( t i − o i ) (6) l o s s=\sum_{i=1}^{p}\left(\mathbf{t}_{i}-\mathbf{o}_{i}\right)\tag{6} loss=i=1∑p(ti−oi)(6) 其中, p p p表示监督的节点数量,学习算法使用梯度下降法,整个过程按照如下步骤进行:
- 状态 h v t 按 照 方 程 \mathbf{h}_{v}^{t}按照方程 hvt按照方程(1)的公式迭代更新 T T T个轮次,这时得到的 H \mathbf{H} H会接近不动点的解 H ( T ) ≈ H \mathbf{H}(T) \approx \mathbf{H} H(T)≈H。
- 权重 W \mathbf{W} W的梯度从loss计算得到。
- 权重 W \mathbf{W} W根据上一步中计算的梯度更新。
原始的GNN有如下的缺点:
- 对不动点使用迭代的方法来更新节点的隐藏状态,效率并不高
- 在迭代过程中,原始GNN使用相同的参数,而其他比较著名的模型在不同的网络层采用不同的参数,使得模型能够学习到更加深的特征表达,而且,节点隐藏层的更新是顺序流程,可以从GRU和LSTM的cell的结构中获取灵感。
- 一些边(edges)上可能会存在某些信息特征不能被有效地考虑进去。
- 如果需要学习节点的向量表示而不是图的表示,那么使用不动点的方法是不妥当的,因为在不动点的向量表示分布在数值上会非常的平滑,这样的向量对于区分不同的节点并无太大帮助。
GNN的网络变体
在该节中,论文首先列出各种GNN变体在不同的图类型上的操作方式,这些变体扩展了原始模型的表达能力,然后,论文列出了在传播步骤上的几种结构(包括卷积、门机制、注意力机制和跳过连接),最后描述使用特定的训练方法来提高训练效率。
不同的图类型
原始的GNN输入的图结构包含带有标签信息的节点和无向边,这是最简单的图结构,其它种类的图结构主要有有向图、异质图、带有边信息图和动态图。图类型以及主要的模型如下图:
-
有向图(Directed Graphs):无向边可以看成是两个有向边的结合,但是,有向边比无向边能够提供更多的信息,比如在知识图谱里面,边开始于头实体(head entity),结束于尾实体(tail entity),通常有向边表示两个节点之间存在某种关系。
论文DGP-Rethinking Knowledge Graph Propagation for Zero-Shot Learning使用两种权重矩阵 W p \mathbf{W}_{p} Wp和 W c \mathbf{W}_{c} Wc来结合更加精确的结构化信息,DGP的传播方式如下:
H t = σ ( D p − 1 A p σ ( D c − 1 A c H t − 1 W c ) W p ) (7) \mathbf{H}^{t}=\sigma\left(\mathbf{D}_{p}^{-1} \mathbf{A}_{p} \sigma\left(\mathbf{D}_{c}^{-1} \mathbf{A}_{c} \mathbf{H}^{t-1} \mathbf{W}_{c}\right) \mathbf{W}_{p}\right)\tag{7} Ht=σ(Dp−1Apσ(Dc−1AcHt−1Wc)Wp)(7)其中, D p − 1 A p \mathbf{D}_{p}^{-1} \mathbf{A}_{p} Dp−1Ap和 D c − 1 A c \mathbf{D}_{c}^{-1} \mathbf{A}_{c} Dc−1Ac分别是双亲(parents)和后代(children)的归一化邻接矩阵。 -
异质图(Heterogeneous Graphs):异质图含有多种不同的节点种类,处理这种图最简单的方法是将每种节点的类型转化为One-hot特征向量,然后将One-hot向量和原始的节点特征进行连接,作为该节点的特征向量。其中,论文GraphInception提出将元路径(metapath)概念用在异质图的信息传播上,通过元路径的方式,我们可以根据节点类型和距离来对局部范围内节点进行分组,对于每一组,GraphInception将它作为异质图的一个子图,然后在子图内进行传播,并将不同异质图得到的结果进行连接得到综合的节点表示。
-
带有边信息的图(Graphs with Edge Information):在这种图变体中,每一个边都带有额外的信息,比如权重和边的类型,我们可以使用两种方法来处理这种图:
一种方式是将原始的图转化为一个二分图(bipartite graph),处理方式为将原始的边转化为一个节点以及两条新的边,论文G2S的编码器使用如下的传播函数:
h v t = ρ ( 1 ∣ N v ∣ ∑ u ∈ N v W r ( r v t ⊙ h u t − 1 ) + b r ) (8) \mathbf{h}_{v}^{t}=\rho\left(\frac{1}{\left|\mathcal{N}_{v}\right|} \sum_{u \in \mathcal{N}_{v}} \mathbf{W}_{r}\left(\mathbf{r}_{v}^{t} \odot \mathbf{h}_{u}^{t-1}\right)+\mathbf{b}_{r}\right)\tag{8} hvt=ρ(∣Nv∣1u∈Nv∑Wr(rvt⊙hut−1)+br)(8)
其中, W r \mathbf{W}_r Wr和 b r \mathbf{b}_r br是不同边类型的传播参数。
另一种方式是在不同种类的边上,使用不同的权重矩阵来进行传播的方式,也就是说,每一种边类型都关联一个权重矩阵,显然,对于边类型有很多的情况下,这种方式的参数量会非常大,论文Modeling Relational Data with Graph Convolutional Networks采用两种方法来减小参数。 -
动态图(Dynamic Graphs):动态图类型有静态的图结构,并且能够处理动态的输入信号。DCRNN和STGCN首先使用GNN获取空域信息,然后将该信息输入到一个序列模型,比如sequence-to-sequence模型或者CNN模型。与此相反的是,Structural-RNN和ST-GCN同时获取时间信息和空间信息。
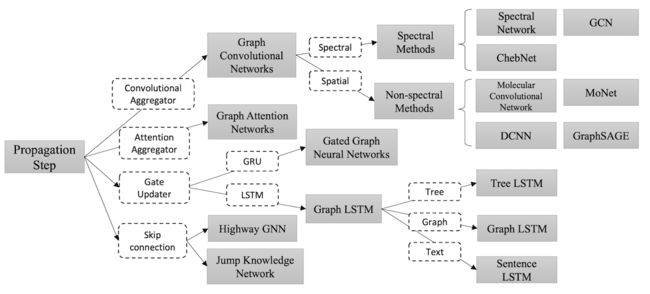
传播类型
论文中的传播(propagation)指的是汇集从邻居节点和连接的边的信息,来对节点进行更新的过程,这个过程在模型中获取节点(或边)的隐藏状态是非常重要的。对于信息传播步骤(propagation step),有几种主要的GNN变体,而在输出步骤(output step)中,研究者通常使用简单的前向传播的神经网络。
不同的GNN的信息传播变体使用下表进行列出,这些变体采用不同的信息传播方式来从邻居节点中获取信息,并通过设定的更新器(updater)来对节点的隐藏状态进行更新。
图的节点更新的主要信息传播(information aggregator)类型以及主要的模型如下图:
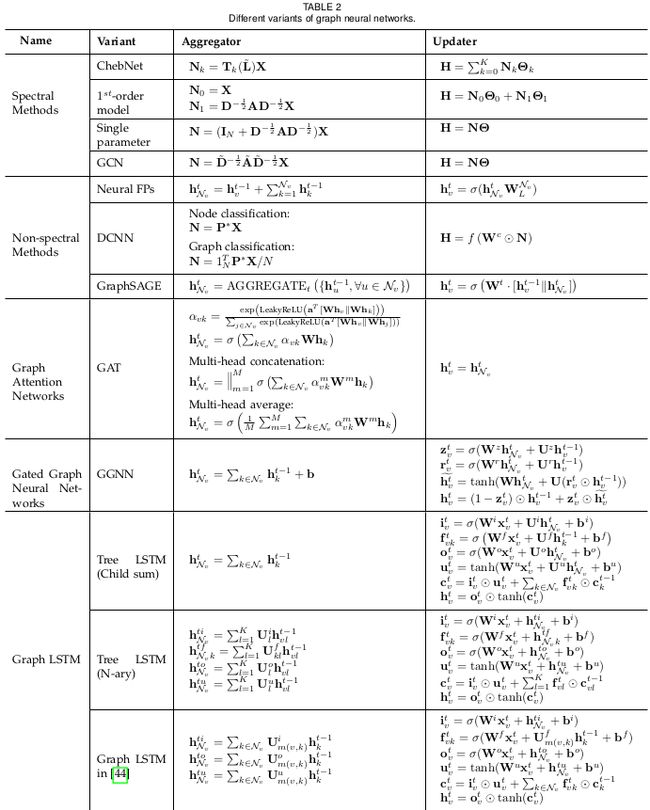
不同类别模型的Aggregator计算方法和Updater计算方法如下表
-
卷积(Convolution):这个方向上分为频域方法和非频域(空域)方法。
频域方法使用图的频域表示,主要有以下几种模型:
-
Spectral Network:论文提出了Spectral network,卷积操作定义为傅里叶频域计算图拉普拉斯(graph Laplacian)的特征值分解。这个操作可以定义为使用卷积核 g θ = diag ( θ ) \mathbf{g}_{\theta}=\operatorname{diag}(\theta) gθ=diag(θ)对输入 x ∈ R N \mathbf{x} \in \mathbb{R}^{N} x∈RN(每一个节点有一个标量值)的卷积操作,其中 θ ∈ R N \theta \in \mathbb{R}^{N} θ∈RN
g θ ⋆ x = U g θ ( Λ ) U T x (9) \mathbf{g}_{\theta} \star \mathbf{x}=\mathbf{U} \mathbf{g}_{\theta}(\mathbf{\Lambda}) \mathbf{U}^{T} \mathbf{x}\tag{9} gθ⋆x=Ugθ(Λ)UTx(9)
其中, U \mathbf{U} U是标准化图拉普拉斯矩阵 L = I N − D − 1 2 A D − 1 2 = U Λ U T \mathbf{L}=\mathbf{I}_{N}-\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}=\mathbf{U} \mathbf{\Lambda} \mathbf{U}^{T} L=IN−D−21AD−21=UΛUT的特征向量矩阵, D \mathbf{D} D是度矩阵(degree matrix), A \mathbf{A} A是图的邻接矩阵(adjacency matrix), Λ \mathbf{\Lambda} Λ为以特征值为对角线上的值的对角矩阵。这个操作会有导致较高的计算量。 -
ChebNet:论文根据切比雪夫多项式定理,认为 g θ ( Λ ) \mathbf{g}_{\theta}(\mathbf{\Lambda}) gθ(Λ)可以通过截取多项式的前 K K K项来进行估计,因此,操作为
g θ ⋆ x ≈ U ∑ k = 0 K θ k T k ( L ~ ) U T x (10) \mathbf{g}_{\theta} \star \mathbf{x} \approx \mathbf{U}\sum_{k=0}^{K} \theta_{k} \mathbf{T}_{k}(\tilde{\mathbf{L}})\mathbf{U^{T}} \mathbf{x}\tag{10} gθ⋆x≈Uk=0∑KθkTk(L~)UTx(10)
其中, L ~ = 2 λ max L − I N \tilde{\mathbf{L}}=\frac{2}{\lambda_{\max }} \mathbf{L}-\mathbf{I}_{N} L~=λmax2L−IN, λ m a x \lambda_{max} λmax表示矩阵 L \mathbf{L} L最大的特征值, θ ∈ R K \theta \in \mathbb{R}^{K} θ∈RK为切比雪夫系数向量,切比雪夫多项式定义为 T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) \mathbf{T}_{k}(\mathbf{x})=2 \mathbf{x} \mathbf{T}_{k-1}(\mathbf{x})-\mathbf{T}_{k-2}(\mathbf{x}) Tk(x)=2xTk−1(x)−Tk−2(x),且有 T 0 ( x ) = 1 \mathbf{T}_{0}(\mathbf{x})=1 T0(x)=1以及 T 1 ( x ) = x \mathbf{T}_{1}(\mathbf{x})=\mathbf{x} T1(x)=x。可以看出,这个操作是 K K K-localized,因为在拉普拉斯中它是一个K阶多项式。由此避免了计算拉普拉斯的特征值。 -
GCN:论文限制了逐层的卷积操作,并设置 K = 1 K=1 K=1来减缓过拟合的问题,它还近似了 λ max ≈ 2 \lambda_{\max } \approx 2 λmax≈2,最后简化的方程如下
g θ ′ ⋆ x ≈ θ 0 ′ x + θ 1 ′ ( L − I N ) x = θ 0 ′ x − θ 1 ′ D − 1 2 A D − 1 2 x (11) \mathbf{g}_{\theta^{\prime}} \star \mathbf{x} \approx \theta_{0}^{\prime} \mathbf{x}+\theta_{1}^{\prime}\left(\mathbf{L}-\mathbf{I}_{N}\right) \mathbf{x}=\theta_{0}^{\prime} \mathbf{x}-\theta_{1}^{\prime} \mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}} \mathbf{x}\tag{11} gθ′⋆x≈θ0′x+θ1′(L−IN)x=θ0′x−θ1′D−21AD−21x(11)
使用两个无限制的参数 θ 0 ′ \theta'_0 θ0′和 θ 1 ′ \theta'_1 θ1′。在通过设置 θ = θ 0 ′ = − θ 1 ′ \theta=\theta_{0}^{\prime}=-\theta_{1}^{\prime} θ=θ0′=−θ1′来限制参数的数量之后,我们可以得到一下的表达式
g θ ⋆ x ≈ θ ( I N + D − 1 2 A D − 1 2 ) x (12) \mathbf{g}_{\theta} \star \mathbf{x} \approx \theta\left(\mathbf{I}_{N}+\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}\right) \mathbf{x}\tag{12} gθ⋆x≈θ(IN+D−21AD−21)x(12)
值得一提的是,叠加使用这个操作会导致数值不稳定性以及梯度爆炸或消失(因为不断地乘以同一个矩阵),因此,该论文里面使用了重规整化操作(renormalization):
I N + D − 1 2 A D − 1 2 → D ~ − 1 2 A ~ D ~ − 1 2 (13) \mathbf{I}_{N}+\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}\rightarrow{}\tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}}\tag{13} IN+D−21AD−21→D~−21A~D~−21(13)
其中 A ~ = A + I N \tilde{\mathbf{A}}=\mathbf{A}+\mathbf{I}_{N} A~=A+IN, D ~ i i = ∑ j A ~ i j \tilde{\mathbf{D}}_{i i}=\sum_{j} \tilde{\mathbf{A}}_{i j} D~ii=∑jA~ij,最后,论文将模型扩展为含有 C C C个输入通道的信号 X ∈ R N × C \mathbf{X} \in \mathbb{R}^{N \times C} X∈RN×C以及 F F F个滤波器来用于提取特征
Z = D ~ − 1 2 A ~ D ~ − 1 2 X Θ (14) \mathbf{Z}=\tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}} \mathbf{X} \boldsymbol{\Theta}\tag{14} Z=D~−21A~D~−21XΘ(14)其中, Θ ∈ R C × F \Theta \in \mathbb{R}^{C \times F} Θ∈RC×F是滤波器参数矩阵, Z ∈ R N × F \mathbf{Z} \in\mathbb{R}^{N \times F} Z∈RN×F是卷积信号矩阵。
在所有这些频域方法中,学习得到的滤波器都是基于拉普拉斯特征分解,也就是取决于图的结构,这也就意味着,在一个特定结构上训练得到的模型,并不能直接应用到另外一个结构不同的图上。
-
非频域的方法直接在图上定义卷积操作,也就是在空域上相邻的邻居节点上进行操作。这种非频域方法的主要难点在于如何定义拥有不同邻居数量的卷积操作以及保持CNN的局部不变性。主要的模型有如下一些:
-
Neural FPs:论文对不同度的节点使用不同的权重矩阵
x = h v t − 1 + ∑ i = 1 ∣ N v ∣ h i t − 1 (15) \mathbf{x}=\mathbf{h}_{v}^{t-1}+\sum_{i=1}^{\left|\mathcal{N}_{v}\right|} \mathbf{h}_{i}^{t-1}\tag{15} x=hvt−1+i=1∑∣Nv∣hit−1(15)h v t = σ ( x W t ∣ N v ∣ ) (16) \mathbf{h}_{v}^{t}=\sigma\left(\mathbf{x} \mathbf{W}_{t}^{\left|\mathcal{N}_{v}\right|}\right)\tag{16} hvt=σ(xWt∣Nv∣)(16)
其中, W t ∣ N v ∣ \mathbf{W}_{\mathbf{t}}^{\left|\mathcal{N}_{\mathbf{v}}\right|} Wt∣Nv∣是在第 t t t层的度为 ∣ N v ∣ \left|\mathcal{N}_{v}\right| ∣Nv∣的节点的权重矩阵,这种方法的缺点在于不能应用到节点度比较大的graph上。
论文的应用场景是分子指纹(Molecular Fingerprints)领域,通过图神经网络的方式来学习分子表示,从而提供下游任务比如相似度评估任务或分类任务需要的向量表示。
算法的实现步骤如下

模型缺点:
-
计算量较大:和传统的Circular fingerprints方法相比,有相近的atoms复杂度和网络深度复杂度,但是会有额外的矩阵乘法复杂度。对于网络深度为 R R R,fingerprint长度为 L L L,以及 N N N个原子的分子,卷积网络的特征维度为 F F F,计算复杂度为 O ( R N F L + R N F 2 ) \mathcal{O}(RNFL+RNF^2) O(RNFL+RNF2)。
-
每一层有计算量限制
-
信息传播效率限制:在图上进行信息传播的效果会受到图深度的影响。
-
无法区分立体异构:分子还会存在同分子式不同空间结构的情况,但是论文网络架构无法区分后者。
-
DCNN:论文提出了扩散卷积神经网络,转化矩阵用来定义节点的邻居,对于节点分类任务,有
H = f ( W c ⊙ P ∗ X ) (17) \mathbf{H}=f\left(\mathbf{W}^{c} \odot \mathbf{P}^{*} \mathbf{X}\right)\tag{17} H=f(Wc⊙P∗X)(17)
其中, X \mathbf{X} X是一个 N × F N\times{F} N×F的输入特征张量( N N N是节点的数量, F F F是特征的维度), P ∗ \mathbf{P}^* P∗是一个 N × K × N N\times{K}\times{N} N×K×N的张量,包含矩阵 P \mathbf{P} P的power series { P , P 2 , . . . , P K } \{\mathbf{P},\mathbf{P}^2,...,\mathbf{P}^K\} {P,P2,...,PK}, P \mathbf{P} P是来自于图邻接矩阵 A \mathbf{A} A的度标准(degree-normalized)的转化矩阵。 -
DGCN:论文提出了对偶图卷积网络,同时考虑到图上的局部一致性和全局一致性,它使用两组卷积网络来获取局部/全局的一致性,并采用一个无监督的loss来组合它们,第一个卷积网络和方程KaTeX parse error: Undefined control sequence: \eqref at position 1: \̲e̲q̲r̲e̲f̲{eq:14}相同,第二个卷积网络将邻接矩阵替换为PPMI(positive pointwise mutual information)矩阵
H ′ = ρ ( D P − 1 2 X P D P − 1 2 H Θ ) (18) \mathbf{H}^{\prime}=\rho\left(\mathbf{D}_{P}^{-\frac{1}{2}} \mathbf{X}_{P} \mathbf{D}_{P}^{-\frac{1}{2}} \mathbf{H} \Theta\right)\tag{18} H′=ρ(DP−21XPDP−21HΘ)(18)
其中, X P \mathbf{X}_{P} XP为PPMI矩阵, D P \mathbf{D}_{P} DP为 X P \mathbf{X}_{P} XP的对角度矩阵。 -
GraphSAGE:论文提出了一个一般的归纳框架,这个框架通过从一个节点的局部邻居中采样和聚合特征,来产生节点的embedding
h N v t = AGGREGATE t ( { h u t − 1 , ∀ u ∈ N v } ) (19) \mathbf{h}_{\mathcal{N}_{v}}^{t}=\text { AGGREGATE }_{t}\left(\left\{\mathbf{h}_{u}^{t-1}, \forall u \in \mathcal{N}_{v}\right\}\right)\tag{19} hNvt= AGGREGATE t({hut−1,∀u∈Nv})(19)h v t = σ ( W t ⋅ [ h v t − 1 ∥ h N v t ] ) (20) \mathbf{h}_{v}^{t}=\sigma\left(\mathbf{W}^{t} \cdot\left[\mathbf{h}_{v}^{t-1} \| \mathbf{h}_{\mathcal{N}_{v}}^{t}\right]\right)\tag{20} hvt=σ(Wt⋅[hvt−1∥hNvt])(20)
但是,上述的方程并不会采用所有的邻居节点进行计算,而是使用均匀采样来得到固定大小的邻居节点集合,该论文推荐使用三种聚合函数:
-
平均值聚合(Mean aggregator):使用如下方式计算
h v t = σ ( W ⋅ MEAN ( { h v t − 1 } ∪ { h u t − 1 , ∀ u ∈ N v } ) \mathbf{h}_{v}^{t}=\sigma\left(\mathbf{W} \cdot \operatorname{MEAN}\left(\left\{\mathbf{h}_{v}^{t-1}\right\} \cup\left\{\mathbf{h}_{u}^{t-1}, \forall u \in \mathcal{N}_{v}\right\}\right)\right. hvt=σ(W⋅MEAN({hvt−1}∪{hut−1,∀u∈Nv}) 平均值聚合和其他的聚合方式不同,因为它不用进行连接操作。 -
LSTM聚合(LSTM aggregator):基于LSTM的聚合器有更好的表达能力,然而,LSTM以序列的方式顺序地处理输入,因此,它并没有排列不变性,论文采用重排列节点邻居的方式,在无序集合中使用LSTM操作。
-
池化聚合(Pooling aggregator):每一个邻居的隐藏状态输入到一个全连接层,然后使用最大池化操作应用到邻居节点集合。
h N v t = max ( { σ ( W p o o l h u t − 1 + b ) , ∀ u ∈ N v } ) \mathbf{h}_{\mathcal{N}_{v}}^{t}=\max \left(\left\{\sigma\left(\mathbf{W}_{\mathrm{pool}} \mathbf{h}_{u}^{t-1}+\mathbf{b}\right), \forall u \in \mathcal{N}_{v}\right\}\right) hNvt=max({σ(Wpoolhut−1+b),∀u∈Nv})值得一提的是,任何对称的函数都可以用来替换这里的最大池化操作。
-
-
门机制(Gate):目前在信息传播步骤中使用的门机制类似于GRU和LSTM模型,这种机制可以减小原始GNN模型的约束,并提升在图结构中的长期的信息传播。
-
论文提出了门控图神经网络(GGNN),在信息传播步骤中使用GRU,将递归循环展开固定数量的步数 T T T,并使用按照时间序的反向传播来计算梯度。
具体来说,传播的基本递归循环是模型如下
a v t = A v T [ h 1 t − 1 … h N t − 1 ] T + b z v t = σ ( W z a v t + U z h v t − 1 ) r v t = σ ( W r a v t + U r h v t − 1 ) h ~ v t = tanh ( W a v t + U ( r v t ⊙ h v t − 1 ) ) h v t = ( 1 − z v t ) ⊙ h v t − 1 + z v t ⊙ h v t ~ \begin{aligned} \mathbf{a}_{v}^{t} &=\mathbf{A}_{v}^{T}\left[\mathbf{h}_{1}^{t-1} \ldots \mathbf{h}_{N}^{t-1}\right]^{T}+\mathbf{b} \\ \mathbf{z}_{v}^{t} &=\sigma\left(\mathbf{W}^{z} \mathbf{a}_{v}^{t}+\mathbf{U}^{z} \mathbf{h}_{v}^{t-1}\right) \\ \mathbf{r}_{v}^{t} &=\sigma\left(\mathbf{W}^{r} \mathbf{a}_{v}^{t}+\mathbf{U}^{r} \mathbf{h}_{v}^{t-1}\right) \\ \widetilde{\mathbf{h}}_{v}^{t} &=\tanh \left(\mathbf{W} \mathbf{a}_{v}^{t}+\mathbf{U}\left(\mathbf{r}_{v}^{t} \odot \mathbf{h}_{v}^{t-1}\right)\right) \\ \mathbf{h}_{v}^{t} &=\left(1-\mathbf{z}_{v}^{t}\right) \odot \mathbf{h}_{v}^{t-1}+\mathbf{z}_{v}^{t} \odot \widetilde{\mathbf{h}_{v}^{t}} \end{aligned} avtzvtrvth vthvt=AvT[h1t−1…hNt−1]T+b=σ(Wzavt+Uzhvt−1)=σ(Wravt+Urhvt−1)=tanh(Wavt+U(rvt⊙hvt−1))=(1−zvt)⊙hvt−1+zvt⊙hvt
按照第一个公式,节点 v v v首先从它的邻居节点汇集信息,其中, A v \mathbf{A}_v Av为图邻接矩阵 A \mathbf{A} A的子矩阵,表示节点 v v v和它的邻居节点的连接关系。然后,类似于GRU的节点更新函数将该节点前一个时刻的信息和与该节点相邻的其它节点的信息结合起来,以此来更新每一个节点的隐藏状态。 a \mathbf{a} a汇集了节点 v v v周围节点的信息, z \mathbf{z} z和 r \mathbf{r} r分别是更新门(update gate)和重置门(reset gate)。LSTM同样使用类似的方法来进行信息传播过程。 -
论文提出了两个LSTM的扩展结构,Child-Sum Tree-LSTM和N-ary Tree-LSTM,类似于标准的LSTM单元,每一个Tree-LSTM单元(为 v v v)包含输入门(input gate) i v \mathbf{i}_v iv和输出门(output gate) o v \mathbf{o}_v ov,记忆单元(memory cell) c v \mathbf{c}_v cv和隐藏状态(hidden state) h v \mathbf{h}_v hv,但与LSTM(LSTM单元只包含一个遗忘门(forget gate))不同的是,Tree-LSTM单元对每一个孩子节点 k k k都有一个遗忘门 f v k \mathbf{f}_{vk} fvk,这样就可以从孩子节点中选择性地汇集并组合信息。Child-Sum Tree-LSTM的转换方程如下
h v t − 1 ~ = ∑ k ∈ N v h k t − 1 i v t = σ ( W i x v t + U i h v t − 1 ~ + b i ) f v k t = σ ( W f x v t + U f h k t − 1 + b f ) o v t = σ ( W o x v t + U o h v t − 1 ~ + b o ) u v t = tanh ( W u x v t + U u h v t − 1 ~ + b u ) c v t = i v t ⊙ u v t + ∑ k ∈ N v f v k t ⊙ c k t − 1 h v t = o v t ⊙ tanh ( c v t ) \begin{aligned} \widetilde{\mathbf{h}_{v}^{t-1}} &= \sum_{k \in \mathcal{N}_{v}} \mathbf{h}_{k}^{t-1} \\ \mathbf{i}_{v}^{t} &=\sigma\left(\mathbf{W}^{i} \mathbf{x}_{v}^{t}+\mathbf{U}^{i} \widetilde{\mathbf{h}_{v}^{t-1}}+\mathbf{b}^{i}\right) \\ \mathbf{f}_{v k}^{t} &=\sigma\left(\mathbf{W}^{f} \mathbf{x}_{v}^{t}+\mathbf{U}^{f} \mathbf{h}_{k}^{t-1}+\mathbf{b}^{f}\right) \\ \mathbf{o}_{v}^{t} &=\sigma\left(\mathbf{W}^{o} \mathbf{x}_{v}^{t}+\mathbf{U}^{o} \widetilde{\mathbf{h}_{v}^{t-1}}+\mathbf{b}^{o}\right) \\ \mathbf{u}_{v}^{t} &=\tanh \left(\mathbf{W}^{u} \mathbf{x}_{v}^{t}+\mathbf{U}^{u} \widetilde{\mathbf{h}_{v}^{t-1}}+\mathbf{b}^{u}\right) \\ \mathbf{c}_{v}^{t} &=\mathbf{i}_{v}^{t} \odot \mathbf{u}_{v}^{t}+\sum_{k \in \mathcal{N}_{v}} \mathbf{f}_{v k}^{t} \odot \mathbf{c}_{k}^{t-1} \\ \mathbf{h}_{v}^{t} &=\mathbf{o}_{v}^{t} \odot \tanh \left(\mathbf{c}_{v}^{t}\right) \end{aligned} hvt−1 ivtfvktovtuvtcvthvt=k∈Nv∑hkt−1=σ(Wixvt+Uihvt−1 +bi)=σ(Wfxvt+Ufhkt−1+bf)=σ(Woxvt+Uohvt−1 +bo)=tanh(Wuxvt+Uuhvt−1 +bu)=ivt⊙uvt+k∈Nv∑fvkt⊙ckt−1=ovt⊙tanh(cvt) x v t \mathbf{x}_v^t xvt是标准LSTM中在时刻 t t t的输入。
如果一个树每一个节点最多有 K K K个分支,并且节点所有的孩子节点都是有序的,比如,这些孩子节点可以被从 1 1 1编号到 K K K,那么可以使用N-ary Tree-LSTM,对于节点 v v v, h v k t \mathbf{h}_{vk}^t hvkt和 c v k t \mathbf{c}_{vk}^t cvkt分别表示在 t t t时刻,它的第 k k k个孩子节点的隐藏状态和记忆单元,转化方程为
i v t = σ ( W i x v t + ∑ l = 1 K U l i h v l t − 1 + b i ) f v k t = σ ( W f x v t + ∑ l = 1 K U k l f h v l t − 1 + b f ) o v t = σ ( W o x v t + ∑ l = 1 K U l o h v l t − 1 + b o ) u v t = tanh ( W u x v t + ∑ l = 1 K U v l t ⊙ c v l t − 1 + b u ) c v t = i v t ⊙ u v t + ∑ l = 1 K f v l t ⊙ c v l t − 1 h v t = o v t ⊙ tanh ( c v t ) \begin{aligned} \mathbf{i}_{v}^{t} &=\sigma\left(\mathbf{W}^{i} \mathbf{x}_{v}^{t}+\sum_{l=1}^{K} \mathbf{U}_{l}^{i} \mathbf{h}_{v l}^{t-1}+\mathbf{b}^{i}\right) \\ \mathbf{f}_{v k}^{t} &=\sigma\left(\mathbf{W}^{f} \mathbf{x}_{v}^{t}+\sum_{l=1}^{K} \mathbf{U}_{k l}^{f} \mathbf{h}_{v l}^{t-1}+\mathbf{b}^{f}\right) \\ \mathbf{o}_{v}^{t} &=\sigma\left(\mathbf{W}^{o} \mathbf{x}_{v}^{t}+\sum_{l=1}^{K} \mathbf{U}_{l}^{o} \mathbf{h}_{v l}^{t-1}+\mathbf{b}^{o}\right) \\ \mathbf{u}_{v}^{t} &=\tanh \left(\mathbf{W}^{u} \mathbf{x}_{v}^{t}+\sum_{l=1}^{K} \mathbf{U}_{v l}^{t} \mathbf{\odot} \mathbf{c}_{v l}^{t-1}+\mathbf{b}^{u}\right) \\ \mathbf{c}_{v}^{t}&=\mathbf{i}_{v}^{t} \odot \mathbf{u}_{v}^{t}+\sum_{l=1}^{K} \mathbf{f}_{v l}^{t} \odot \mathbf{c}_{v l}^{t-1} \\ \mathbf{h}_{v}^{t}&=\mathbf{o}_{v}^{t} \odot \tanh \left(\mathbf{c}_{v}^{t}\right) \end{aligned} ivtfvktovtuvtcvthvt=σ(Wixvt+l=1∑KUlihvlt−1+bi)=σ(Wfxvt+l=1∑KUklfhvlt−1+bf)=σ(Woxvt+l=1∑KUlohvlt−1+bo)=tanh(Wuxvt+l=1∑KUvlt⊙cvlt−1+bu)=ivt⊙uvt+l=1∑Kfvlt⊙cvlt−1=ovt⊙tanh(cvt) 对每个孩子节点 k k k都赋予一个单独的参数矩阵,使得该模型相比于Child-Sum Tree-LSTM能够学习得到更加细微的节点表示。这两种类型的Tree-LSTM都能够很容易地应用到图- 论文提出了一个Graph LSTM的变体,用于关系抽取(relation extraction)的任务上。图和树的主要区别在于,图结构的边有它们自己的label,由此,论文采用不同的权重矩阵来表示不同的label
i v t = σ ( W i x v t + ∑ k ∈ N v U m ( v , k ) i h k t − 1 + b i ) f v k t = σ ( W f x v t + U m ( v , k ) f h k t − 1 + b f ) o v t = σ ( W o x v t + ∑ k ∈ N v U m ( v , k ) o h k t − 1 + b o ) u v t = tanh ( W u x v t + ∑ k ∈ N v U m ( v , k ) t − 1 h k t − 1 + b u ) c v t = i v t ⊙ u v t + ∑ k ∈ N v f v k t ⊙ c k t − 1 h v t = o v t ⊙ tanh ( c v t ) \begin{array}{l}{\mathbf{i}_{v}^{t}=\sigma\left(\mathbf{W}^{i} \mathbf{x}_{v}^{t}+\sum_{k \in \mathcal{N}_{v}} \mathbf{U}_{m(v, k)}^{i} \mathbf{h}_{k}^{t-1}+\mathbf{b}^{i}\right)} \\ {\mathbf{f}_{v k}^{t}=\sigma\left(\mathbf{W}^{f} \mathbf{x}_{v}^{t}+\mathbf{U}_{m(v, k)}^{f} \mathbf{h}_{k}^{t-1}+\mathbf{b}^{f}\right)} \\ {\mathbf{o}_{v}^{t}=\sigma\left(\mathbf{W}^{o} \mathbf{x}_{v}^{t}+\sum_{k \in \mathcal{N}_{v}} \mathbf{U}_{m(v, k)}^{o} \mathbf{h}_{k}^{t-1}+\mathbf{b}^{o}\right)} \\ {\mathbf{u}_{v}^{t}=\tanh \left(\mathbf{W}^{u} \mathbf{x}_{v}^{t}+\sum_{k \in \mathcal{N}_{v}} \mathbf{U}_{m(v, k)}^{t-1} \mathbf{h}_{k}^{t-1}+\mathbf{b}^{u}\right)} \\ {\mathbf{c}_{v}^{t}=\mathbf{i}_{v}^{t} \odot \mathbf{u}_{v}^{t}+\sum_{k \in \mathcal{N}_{v}} \mathbf{f}_{v k}^{t} \odot \mathbf{c}_{k}^{t-1}} \\ {\mathbf{h}_{v}^{t}=\mathbf{o}_{v}^{t} \odot \tanh \left(\mathbf{c}_{v}^{t}\right)}\end{array} ivt=σ(Wixvt+∑k∈NvUm(v,k)ihkt−1+bi)fvkt=σ(Wfxvt+Um(v,k)fhkt−1+bf)ovt=σ(Woxvt+∑k∈NvUm(v,k)ohkt−1+bo)uvt=tanh(Wuxvt+∑k∈NvUm(v,k)t−1hkt−1+bu)cvt=ivt⊙uvt+∑k∈Nvfvkt⊙ckt−1hvt=ovt⊙tanh(cvt) 其中, m ( v , k ) m(v,k) m(v,k)表示在节点 v v v和 k k k之间边的label。
-
-
注意力机制(Attention):注意力机制在很多基于序列任务(sequence-based tasks)比如机器翻译、机器阅读理解等等上都产生了非常好的效果。
-
论文提出了图注意力网络(graph attention network, GAT)将注意力机制引入到信息传播步骤,这个模型通过对它的邻居节点增加注意力来计算节点的隐藏状态,和self-attention策略类似。
该论文定义了一个graph attentional layer,并通过叠加这种层来构建任意的图注意力网络,这个层计算节点对 ( i , j ) (i,j) (i,j)的注意力系数(coefficients),计算方式如下:
α i j = exp ( Leaky ReLU ( a T [ W h i ∥ W h j ] ) ) ∑ k ∈ N i exp ( Leaky ReLU ( a T [ W h i ∥ W h k ] ) ) \alpha_{i j}=\frac{\exp \left(\text { Leaky ReLU }\left(\mathbf{a}^{T}\left[\mathbf{W} \mathbf{h}_{i} \| \mathbf{W} \mathbf{h}_{j}\right]\right)\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(\text { Leaky ReLU }\left(\mathbf{a}^{T}\left[\mathbf{W} \mathbf{h}_{i} \| \mathbf{W} \mathbf{h}_{k}\right]\right)\right)} αij=∑k∈Niexp( Leaky ReLU (aT[Whi∥Whk]))exp( Leaky ReLU (aT[Whi∥Whj])) 其中, α i j \alpha_{ij} αij是节点 j j j对 i i i的注意力系数, N i \mathcal{N}_i Ni表示图中节点 i i i的邻居节点集合,节点特征的输入集合是 h = { h 1 , h 2 , … , h N } , h i ∈ R F \mathbf{h}=\left\{\mathbf{h}_{1}, \mathbf{h}_{2}, \ldots, \mathbf{h}_{N}\right\},\mathbf{h}_{i} \in\mathbb{R}^{F} h={h1,h2,…,hN},hi∈RF,其中 N N N是节点的个数, F F F是每个节点的特征维度。这个层会产生一个新的节点特征集(可能有不同的特征维度 F ′ F' F′) h ′ = { h 1 ′ , h 2 ′ , … , h N ′ } , h i ′ ∈ R F ′ \mathbf{h}^{\prime}=\left\{\mathbf{h}_{1}^{\prime}, \mathbf{h}_{2}^{\prime}, \ldots, \mathbf{h}_{N}^{\prime}\right\},\mathbf{h}_{i}^{\prime} \in \mathbb{R}^{F^{\prime}} h′={h1′,h2′,…,hN′},hi′∈RF′,作为该层的输出, W ∈ R F ′ × F \mathbf{W} \in \mathbb{R}^{F^{\prime} \times F} W∈RF′×F是共享的线性变换的权重矩阵, a ∈ R 2 F ′ \mathbf{a} \in \mathbb{R}^{2 F^{\prime}} a∈R2F′是单层的前向神经网络的权重向量,通过softmax函数对它进行归一化,然后使用LeakyReLU( α = 0.2 \alpha=0.2 α=0.2)非线性函数。最后每个节点的输出特征可以通过如下方程获得
h i ′ = σ ( ∑ j ∈ N i α i j W h j ) \mathbf{h}_{i}^{\prime}=\sigma\left(\sum_{j \in \mathcal{N}_{i}} \alpha_{i j} \mathbf{W h}_{j}\right) hi′=σ⎝⎛j∈Ni∑αijWhj⎠⎞ 另外,这个注意力层采用multi-head attention使得网络学习过程更加稳定,它使用 K K K个独立的注意力来计算隐藏状态,然后将计算出的 K K K个特征连接(或者求平均),得到最终的输出表示
h i ′ = ∥ k = 1 K σ ( ∑ j ∈ N i α i j k W k h j ) \mathbf{h}_{i}^{\prime}=\|_{k=1}^{K} \sigma\left(\sum_{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \mathbf{h}_{j}\right) hi′=∥k=1Kσ⎝⎛j∈Ni∑αijkWkhj⎠⎞h i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h j ) \mathbf{h}_{i}^{\prime}=\sigma\left(\frac{1}{K} \sum_{k=1}^{K} \sum_{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \mathbf{h}_{j}\right) hi′=σ⎝⎛K1k=1∑Kj∈Ni∑αijkWkhj⎠⎞
其中, α i j k \alpha_{i j}^{k} αijk是归一化的注意力系数,由第 k k k个注意力机制得到。
这篇论文的注意力机制结构有如下几个特点:(1)node-neighbor pair的计算可以是并行化的,因此操作的效率高;(2)通过给邻居节点赋予任意的权重,可以用在有不同度的图节点上;(3)可以容易地用于归纳学习问题上。
-
-
跳过连接(Skip connection):许多应用都会将图神经网络层进行叠加,以此来实现更好的结果,因为更多的层意味着每一个节点能够从更多的邻居节点中获取信息,但是,许多实验发现,更深的模型并不会表现更好,反而可能表现更坏,主要因为随着指数个数上升的相邻节点数量,更多的层可能会汇集到更多的噪声信息。
一个直接的想法是使用残差网络(residual network),但是即使使用残差连接,有更多层的GCN在很多数据上并没有2层的GCN表现的更好。
- 论文提出了Highway GCN,类似于highway network,使用了“逐层门机制”(layer-wise gates),一个层的输出公式如下:
T ( h t ) = σ ( W t h t + b t ) h t + 1 = h t + 1 ⊙ T ( h t ) + h t ⊙ ( 1 − T ( h t ) ) \begin{aligned} \mathbf{T}\left(\mathbf{h}^{t}\right) &=\sigma\left(\mathbf{W}^{t} \mathbf{h}^{t}+\mathbf{b}^{t}\right) \\ \mathbf{h}^{t+1} &=\mathbf{h}^{t+1} \odot \mathbf{T}\left(\mathbf{h}^{t}\right)+\mathbf{h}^{t} \odot\left(1-\mathbf{T}\left(\mathbf{h}^{t}\right)\right) \end{aligned} T(ht)ht+1=σ(Wtht+bt)=ht+1⊙T(ht)+ht⊙(1−T(ht)) 通过增加highway gates,在该论文指定的特定问题上,模型在4层的表现最好。
- 论文提出了Highway GCN,类似于highway network,使用了“逐层门机制”(layer-wise gates),一个层的输出公式如下:
-
分层池化(Hierarchical Pooling):在计算机视觉中,一个卷积层后通常会接一个池化层,来得到更加一般的特征。与这种池化层类似的是,在图结构中,一种分层池化层也能够起到类似的效果,复杂的和大规模的图通常会包含丰富的分层结构,这种结构对于节点层次(node-level)和图层次(graph-level)的分类任务非常重要。
训练方法
原始的图卷积神经网络在训练和优化方法上有一些缺点,比如,GCN需要计算整个图拉普拉斯矩阵,这个操作对于大型的图计算量非常大,另外,在第 L L L层的节点的embedding,是通过第 L − 1 L-1 L−1层其周围所有邻居节点的embedding递归循环得到的,因此,单个节点的感受野会随着层数的增加而指数上升,由此,计算单个节点的梯度会非常耗时,另外,GCN是对固定的图结构进行训练,缺乏归纳学习的能力。有以下几种改进的方法
-
采样(Sampling):GraphSAGE将full graph Laplacian替换为可学习的聚合函数(aggregation function)。在学习到聚合函数和传播函数后,GraphSAGE能够对未见过的节点产生embedding。另外,GraphSAGE使用邻居节点采样(neighbor sampling)的方法来缓和感受野扩展的扩展速度。
-
感受野控制(Receptive Field Control)
-
数据增强(Data Augmentation):论文考虑到GCN需要许多额外的标签数据集用于验证,以及卷积核局部化问题,为了解决这些问题,这篇论文提出Co-Training GCN和Self-Training GCN来扩充训练数据集。
-
无监督训练(Unsupervised Training)
GNN一般框架
除了一些GNN的变体之外,一些一般性的框架也用于将不同的模型结合到一个单一框架中,比如MPNN(结合了各种GNN和GCN方法),NLNN(结合几种self-attention的方法),GN(结合MPNN和NLNN以及其它一些GNN变体)。下面对这三种框架进行仔细介绍:
Message Passing Neural Networks
该模型提出一种general framework,用于在graph上进行监督学习。模型包含两个过程,message passing phase和readout phase。信息传递阶段就是前向传播阶段,该阶段循环运行T个steps,并通过函数 M t M_t Mt获取信息,通过函数 U t U_t Ut更新节点,该阶段方程如下
m v t + 1 = ∑ w ∈ N v M t ( h v t , h w t , e v w ) h v t + 1 = U t ( h v t , m v t + 1 ) \begin{aligned} \mathbf{m}_{v}^{t+1} &=\sum_{w \in \mathcal{N}_{v}} M_{t}\left(\mathbf{h}_{v}^{t}, \mathbf{h}_{w}^{t}, \mathbf{e}_{v w}\right) \\ \mathbf{h}_{v}^{t+1} &=U_{t}\left(\mathbf{h}_{v}^{t}, \mathbf{m}_{v}^{t+1}\right) \end{aligned} mvt+1hvt+1=w∈Nv∑Mt(hvt,hwt,evw)=Ut(hvt,mvt+1)其中, e v w \mathbf{e}_{vw} evw表示从节点 v v v到 w w w的边的特征向量。
readout阶段计算一个特征向量用于整个图的representation,使用函数 R R R实现
y ^ = R ( { h v T ∣ v ∈ G } ) \hat{\mathbf{y}}=R\left(\left\{\mathbf{h}_{v}^{T} | v \in G\right\}\right) y^=R({hvT∣v∈G})其中 T T T表示整个时间step数,其中的函数 M t M_t Mt, U t U_t Ut和 R R R可以使用不同的模型设置。
例如,考虑GGNN模型的例子,有如下函数设置
M t ( h v t , h w t , e v w ) = A e v w h w t U t = G R U ( h v t , m v t + 1 ) R = ∑ v ∈ V σ ( i ( h v T , h v 0 ) ) ⊙ ( j ( h v T ) ) \begin{aligned} M_{t}\left(\mathbf{h}_{v}^{t}, \mathbf{h}_{w}^{t}, \mathbf{e}_{v w}\right) &=\mathbf{A}_{\mathbf{e}_{vw}} \mathbf{h}_{w}^{t} \\ U_{t} &=G R U\left(\mathbf{h}_{v}^{t}, \mathbf{m}_{v}^{t+1}\right) \\ R &=\sum_{v \in V} \sigma\left(i\left(\mathbf{h}_{v}^{T}, \mathbf{h}_{v}^{0}\right)\right) \odot\left(j\left(\mathbf{h}_{v}^{T}\right)\right) \end{aligned} Mt(hvt,hwt,evw)UtR=Aevwhwt=GRU(hvt,mvt+1)=v∈V∑σ(i(hvT,hv0))⊙(j(hvT))其中, A e v w \mathbf{A}_{\mathbf{e}_{vw}} Aevw表示邻接矩阵, i i i和 j j j是函数 R R R的神经网络。
Non-local Neural Networks
该NLNN模型用于使用神经网络获取长远依赖信息,一个位置的non-local操作使用所有positions的特征向量的加权和来作为该位置的信息。以下为通用的non-local operation定义
h i ′ = 1 C ( h ) ∑ ∀ j f ( h i , h j ) g ( h j ) \mathbf{h}_{i}^{\prime}=\frac{1}{\mathcal{C}(\mathbf{h})} \sum_{\forall j} f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right) g\left(\mathbf{h}_{j}\right) hi′=C(h)1∀j∑f(hi,hj)g(hj)其中, i i i是输出位置(节点)的索引, j j j是所有可能位置(节点)索引, f ( h i , h j ) f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right) f(hi,hj)函数得到一个scalar,用于计算节点 i i i与节点 j j j之间的关联度, g ( h j ) g\left(\mathbf{h}_{j}\right) g(hj)表示输入 h j \mathbf{h}_{j} hj的转换函数,因子 1 C ( h ) \frac{1}{\mathcal{C}(\mathbf{h})} C(h)1用于对结果进行归一化。对于这几个函数有多种设置,各种函数配置说明如下
-
线性转换函数,即 g ( h j ) = W g h j g\left(\mathbf{h}_{j}\right)=\mathbf{W}_{g} \mathbf{h}_{j} g(hj)=Wghj,其中, W g W_g Wg为可学习的权重矩阵。
-
高斯函数,对函数 f f f使用高斯配置
f ( h i , h j ) = e h i T h j f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right)=e^{\mathbf{h}_{i}^{T} \mathbf{h}_{j}} f(hi,hj)=ehiThj 其中, h i T h j \mathbf{h}_{i}^{T} \mathbf{h}_{j} hiThj为点积相似度, C ( h ) = ∑ ∀ j f ( h i , h j ) \mathcal{C}(\mathbf{h})=\sum_{\forall j} f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right) C(h)=∑∀jf(hi,hj)。 -
Embedded Guassian,对Guassian函数的扩展,用于计算嵌入空间的相似度
f ( h i , h j ) = e θ ( h i ) T ϕ ( h j ) f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right)=e^{\theta\left(\mathbf{h}_{i}\right)^{T}} \phi\left(\mathbf{h}_{j}\right) f(hi,hj)=eθ(hi)Tϕ(hj) 其中, θ ( h i ) = W θ h i \theta\left(\mathbf{h}_{i}\right)=\mathbf{W}_{\theta} \mathbf{h}_{i} θ(hi)=Wθhi, ϕ ( h j ) = W ϕ h j \phi\left(\mathbf{h}_{j}\right)=W_{\phi} \mathbf{h}_{j} ϕ(hj)=Wϕhj, C ( h ) = ∑ ∀ j f ( h i , h j ) \mathcal{C}(\mathbf{h})=\sum_{\forall j} f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right) C(h)=∑∀jf(hi,hj)。 -
Dot product,对函数 f f f使用点积相似度
f ( h i , h j ) = θ ( h i ) T ϕ ( h j ) f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right)=\theta\left(\mathbf{h}_{i}\right)^{T} \phi\left(\mathbf{h}_{j}\right) f(hi,hj)=θ(hi)Tϕ(hj) 在这种情况下, C ( h ) = N \mathcal{C}(\mathbf{h})=N C(h)=N,其中 N N N为位置(节点)的个数。 -
Concatenation,即
f ( h i , h j ) = Re L U ( w f T [ θ ( h i ) ∥ ϕ ( h j ) ] ) f\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right)=\operatorname{Re} \mathrm{L} \mathrm{U}\left(\mathbf{w}_{f}^{T}\left[\theta\left(\mathbf{h}_{i}\right) \| \phi\left(\mathbf{h}_{j}\right)\right]\right) f(hi,hj)=ReLU(wfT[θ(hi)∥ϕ(hj)]) 其中, w f \mathbf{w}_{f} wf是一个权重向量,用于将一个vector映射成一个scalar, C ( h ) = N \mathcal{C}(\mathbf{h})=N C(h)=N。
Graph Networks
首先介绍网络的的定义,一个Graph Networks定义为三元组 G = ( u , H , E ) G=(\mathbf{u}, H, E) G=(u,H,E),这里使用 H = { h i } i = 1 : N v H=\left\{\mathbf{h}_{i}\right\}_{i=1 : N^{v}} H={hi}i=1:Nv表示节点集合, h i \mathbf{h}_{i} hi为节点的属性向量, u \mathbf{u} u是全局属性, E = { ( e k , r k , s k ) } k = 1 : N e E=\left\{\left(\mathbf{e}_{k}, r_{k}, s_{k}\right)\right\}_{k=1 : N^{e}} E={(ek,rk,sk)}k=1:Ne为边的集合,其中, e k \mathbf{e}_{k} ek为边的属性向量, r k r_k rk为receiver node索引, s k s_k sk为sender node索引。
然后是GN block的结构,一个GN block包含三个update functions( ϕ \phi ϕ)和三个aggregation functions( ρ \rho ρ)
e k ′ = ϕ e ( e k , h r k , h s k , u ) e ‾ i ′ = ρ e → h ( E i ′ ) h i ′ = ϕ h ( e ‾ i ′ , h i , u ) e ‾ ′ = ρ e → u ( E ′ ) u ′ = ϕ u ( e ‾ ′ , h ‾ ′ , u ) h ‾ ′ = ρ h → u ( H ′ ) \begin{array}{ll}{\mathbf{e}_{k}^{\prime}=\phi^{e}\left(\mathbf{e}_{k}, \mathbf{h}_{r_{k}}, \mathbf{h}_{s_{k}}, \mathbf{u}\right)} & {\overline{\mathbf{e}}_{i}^{\prime}=\rho^{e \rightarrow h}\left(E_{i}^{\prime}\right)} \\ {\mathbf{h}_{i}^{\prime}=\phi^{h}\left(\overline{\mathbf{e}}_{i}^{\prime}, \mathbf{h}_{i}, \mathbf{u}\right)} & {\overline{\mathbf{e}}^{\prime}=\rho^{e \rightarrow u}\left(E^{\prime}\right)} \\ {\mathbf{u}^{\prime}=\phi^{u}\left(\overline{\mathbf{e}}^{\prime}, \overline{\mathbf{h}}^{\prime}, \mathbf{u}\right)} & {\overline{\mathbf{h}}^{\prime}=\rho^{h \rightarrow u}\left(H^{\prime}\right)}\end{array} ek′=ϕe(ek,hrk,hsk,u)hi′=ϕh(ei′,hi,u)u′=ϕu(e′,h′,u)ei′=ρe→h(Ei′)e′=ρe→u(E′)h′=ρh→u(H′)其中, E i ′ = { ( e k ′ , r k , s k ) } r k = i , k = 1 : N e E_{i}^{\prime}=\left\{\left(\mathbf{e}_{k}^{\prime}, r_{k}, s_{k}\right)\right\}_{r_{k}=i, k=1 : N^{e}} Ei′={(ek′,rk,sk)}rk=i,k=1:Ne, H ′ = { h i ′ } i = 1 : N v H^{\prime}=\left\{\mathbf{h}_{i}^{\prime}\right\}_{i=1 : N^{v}} H′={hi′}i=1:Nv, E ′ = ⋃ i E i ′ = { ( e k ′ , r k , s k ) } k = 1 : N e E^{\prime}=\bigcup_{i} E_{i}^{\prime}=\left\{\left(\mathbf{e}_{k}^{\prime}, r_{k}, s_{k}\right)\right\}_{k=1 : N^{e}} E′=⋃iEi′={(ek′,rk,sk)}k=1:Ne。函数 ρ \rho ρ必须对于输入的顺序有不变性,而且需要能够接受不同数量的参数。
GN block的计算步骤如下:
-
使用函数 ϕ e \phi^{e} ϕe对每条边都使用一次,输入的参数为 ( e k , h r k , h s k , u ) \left(\mathbf{e}_{k}, \mathbf{h}_{r_{k}}, \mathbf{h}_{s_{k}}, \mathbf{u}\right) (ek,hrk,hsk,u),并返回向量 e k ′ \mathbf{e}_{k}^{\prime} ek′,对与每个节点 i i i相连的输出边的集合为 E i ′ = { ( e k ′ , r k , s k ) } r k = i , k = 1 : N e E_{i}^{\prime}=\left\{\left(\mathbf{e}_{k}^{\prime}, r_{k}, s_{k}\right)\right\}_{r_{k}=i, k=1 : N^{e}} Ei′={(ek′,rk,sk)}rk=i,k=1:Ne,所有输出边的集合为 E ′ = ⋃ i E i ′ = { ( e k ′ , r k , s k ) } k = 1 : N e E^{\prime}=\bigcup_{i} E_{i}^{\prime}=\left\{\left(\mathbf{e}_{k}^{\prime}, r_{k}, s_{k}\right)\right\}_{k=1 : N^{e}} E′=⋃iEi′={(ek′,rk,sk)}k=1:Ne。
-
对集合 E i ′ E_i' Ei′使用函数 ρ e → h \rho^{e \rightarrow h} ρe→h,得到与节点 i i i相连边的信息汇集向量 e ‾ i \overline{\mathbf{e}}_{i} ei,用于下一步的节点更新。
-
对每一个节点 i i i使用函数 ϕ h \phi^{h} ϕh,用于计算并更新节点的属性向量 h i ′ \mathbf{h}_{i}^{\prime} hi′,所有节点的输出集合为 H ′ = { h i ′ } i = 1 : N v H^{\prime}=\left\{\mathbf{h}_{i}^{\prime}\right\}_{i=1 : N^{v}} H′={hi′}i=1:Nv。
-
对集合 E ′ E' E′使用函数 ρ e → u \rho^{e \rightarrow u} ρe→u,得到所有边的信息汇集向量 e ‾ ′ \overline{\mathbf{e}}^{\prime} e′,用于下一步的全局更新。
-
对集合 H ′ H' H′使用函数 ρ h → u \rho^{h \rightarrow u} ρh→u,得到所有节点的信息汇集向量 h ‾ ′ \overline{\mathbf{h}}^{\prime} h′,用于下一步的全局更新。
-
对每个graph应用一次函数 ϕ u \phi^u ϕu,然后计算更新全局属性向量,得到 u ′ \mathbf{u}^{\prime} u′
图神经网络设计基于三个基本的原则:flexible representations、configurable within-block structure、composable multi-block architectures。 -
GN framework支持灵活的属性表达以及不同的图结构
-
GN block内函数可以有灵活的配置
-
GN block可以通过堆叠的方式以及权重共享的方式来得到更深的网络
GNN应用
论文将GNN的应用分为以下几种:
- 结构化数据场景,有明显的关系结构,比如物理系统,分子结构和知识图谱
- 非结构化场景,没有明显的关系结构,比如文本
- 其他应用场景,比如产生式模型和组合优化问题
-
物理系统应用
GNN可以用于对现实世界中的物理系统建模,将物体表示为节点,将物体之间的关系表示为边,由此可以使用GNN模型对目标、关系进行推理。有如下一些论文研究相关内容:
- Interaction Networks”:该模型对各种物理系统进行预测和推理。模型输入objects和relations,然后对它们的interaction进行推理,并预测出新的系统状态。
- Visual Interaction Networks:该模型实现像素级的预测。
-
化学和生物学应用
GNN能够用于计算分子指纹(molecular fingerprints),即使用特征向量来表示分子,用于下游任务,比如computer-aided drug design。另外,GNN也可以用于protein interface prediction,有助于药物研究。
-
知识图谱应用
有论文采用GNN来解决基于out-of-knowledge-base的实体问题。也有论文采用GCN来解决跨语言的知识图谱对齐任务,论文模型将不同语言的实体嵌入到向量空间,然后使用相似度进行实体对齐。
-
图像任务
目前的图像分类任务由于大数据和GPU的强大并行计算能力获得很大的突破,但是zero-shot and few-hot learning在图像领域仍然非常重要。有一些模型采用GNN结合图像的结构化信息来进行图像分类,比如,知识图谱可以用于额外的信息来指导zero-shot recognition classification。
GNN也可以用于visual reasoning,计算机视觉系统通常需要结合空间信息和语义信息来实现推理,因此,很自然地想到使用Graph来实现推理任务。一个典型的任务是visual question answering,该任务需要分别构建图像的场景图(scene graph)以及问题句法图(syntactic graph),然后使用GGNN来训练以及预测最终的结果。visual reasoning的其他应用还有object detection,interaction detection和region classification。
GNN还可以用于semantic segmentation,语义分割的任务在于对图像每一个像素预测出一个label,由于图像的区域往往不是网格形状的,并且需要全局信息,因此使用传统的CNN会有一些局限性,有一些论文采用图结构数据来解决这种问题。
-
文本任务
GNN能够应用到多个基于文本的任务上,既可以用于sentence-level的任务,也可以用于word-level的任务。
首先就是文本分类任务,GNN将一个document或者sentence表示为一个以字(或词)为节点的图结构,然后使用Text GCN来学习词汇或者文本的embedding向量,用于下游任务。
其次就是序列标注任务,对于图中的每一个节点都有一个隐藏状态,因此,可以使用这个隐藏状态来对每一个节点进行标注。
GNN还可以用于机器翻译任务,原始的机器翻译是sequence-to-sequence的任务,但是使用GNN可以将语法和语义信息编码进翻译模型中。
GNN用在关系抽取任务中,就是在文本中抽取出不同实体的语义关系,有一些系统将这个任务看作是两个单独的任务:命名实体识别和关系抽取。
GNN用于事件抽取任务,就是从文本中提取出事件关键的信息,有论文通过dependency tree来实现event detection。
GNN还被用于其他应用,比如文本生成任务,关系推理任务等等。
-
产生式模型
产生式模型对于社会关系建模、新型化学结构发现以及构建知识图谱也有重要作用,有如下相关的研究论文:
- NetGAN:模型使用随机漫步原理来产生图,该模型将graph generation问题转化为walk generation问题,它使用来自于特定图结构的random walks作为输入,并使用GAN的结构来训练一个产生式模型。
- MolGAN:该模型一次性预测离散的图结构,并采用permutation-invariant discriminator来解决node variant问题。
-
组合优化
GNN能够应用于解决在graph上的NP-hard的优化问题,比如旅行商问题(TSP),最小生成树问题(MSP)。
开放问题
GNN模型目前仍然存在一些问题
- Shallow Structure:传统的神经网络可以叠加上百层来提高模型的表达能力,而实验显示,GCN叠加过多的层或导致over-smoothing问题,也就是说,最终所有的节点会收敛于相同的值。
- Dynamic Graphs:静态图是稳定的,因此比较好灵活地进行建模,但是动态图是动态的结构,建模较难。
- Non-Structure Scenarios:对于如何从原始的非结构化数据来产生对应的图结构并没有最优的方法。
- Scalability:应用尺度问题,使用embedding的方法来处理web-scale的任务比如social networks或者recommendation systems对于使用embedding的方法来说计算量非常大。首先,由于不是欧几里得结构,所以不同的节点有不同的结构,无法使用batches;其次,计算图Laplacian矩阵对于有上百万的节点和边的图是不现实的。
跳转到第二篇GNN论文详述