本文会对胸罩销售数据进行更复杂的分析,如罩杯和上胸围的综合分析,以及胸罩颜色销售数据的分析。
按上胸围分析胸罩的销售比例
按上胸围分析胸罩的销售比例与按罩杯分析胸罩的销售比例的方式相同,只是将 size1 换成了 size2。
from pandas import *
from matplotlib.pyplot import *
import sqlite3
import sqlalchemy
# 打开SQLite数据库
engine = sqlalchemy.create_engine('sqlite:///bra.sqlite')
# 设置字体让图表显示中文
rcParams['font.sans-serif'] = ['SimHei']
options.display.float_format = '{:,.2f}%'.format
# 选择source和size2字段
sales = read_sql('select source,size2 from t_sales',engine)
# 按上胸围(size2)分组,并计算每一类上胸围的销售数据
size2Count = sales.groupby('size2')['size2'].count()
print(size2Count)
size2Total = size2Count.sum()
print(size2Total)
size2 = size2Count.to_frame(name='销量')
# 插入“比例”字段,用于显示销售比例
size2.insert(0,'比例',100*size2Count/size2Total)
size2.index.names=['上胸围']
# 按销量排序
size2 = size2.sort_values(['销量'], ascending=[0])
print(size2)
# 将上胸围尺寸转换为列表,作为在饼图上显示的标签
labels = size2.index.tolist()
size2['销量'].plot(kind='pie',labels=labels,autopct='%.2f%%')
legend()
axis('equal')
show()
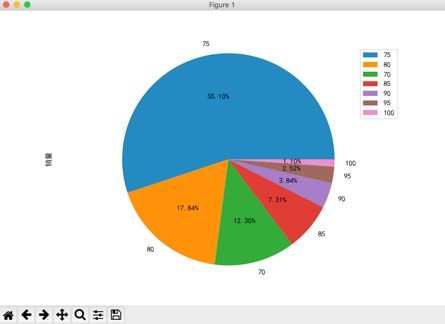
运行程序,会看到在窗口中绘制了如图1所示的饼图。
罩杯和上胸围综合数据可视化分析
罩杯和上胸围综合数据分析要稍微复杂一些,因为要同时考虑 size1 和 size2,主要是同时按 size1 和 size2 分组,但组分得这么细就会造成一个问题,有一些组的记录很少,而且组过多,如果将所有的组都放到饼图上,那么显得太乱。所以我们会将销售量比较大的组显示在饼图上,哪些销售量比较小的组统计一个总销量,都作为“其他”显示。本例将 500 作为单独显示的阈值,也就是说,只有销量大于 500 的组才会显示在饼图上。
from pandas import *
from matplotlib.pyplot import *
import sqlite3
import sqlalchemy
engine = sqlalchemy.create_engine('sqlite:///bra.sqlite')
rcParams['font.sans-serif'] = ['SimHei']
options.display.float_format = '{:,.2f}%'.format
sales = read_sql('select source,size1,size2 from t_sales',engine)
size1size2Count = sales.groupby(['size1','size2'])['size1'].count()
print(size1size2Count)
size1size2Total = size1size2Count.sum()
print(size1size2Total)
size1size2 = size1size2Count.to_frame(name='销量')
n = 500
# 过滤出销量小等于500的组,并统计这些组的总销量,将统计结果放到DataFrame中
others = DataFrame([size1size2[size1size2['销量'] <=
n].sum()],index=MultiIndex(levels=[[''],['其他']],labels=[[0],[0]]))
# 将“其他”销量放到记录集的最后
size1size2 = size1size2[size1size2['销量']>n].append(others)
print(size1size2)
size1size2 = size1size2.sort_values(['销量'],ascending=[0])
size1size2.insert(0,'比例',100 * size1size2Count / size1size2Total)
print(size1size2)
labels = size1size2.index.tolist()
newLabels = []
# 生成饼图外侧显示的每一部分的表示(如75B、80A等)
for label in labels:
newLabels.append(label[1] + label[0])
pie(size1size2['销量'],labels=newLabels,autopct='%.2f%%')
legend()
axis('equal')
title('罩杯+上胸围销售比例')
show()
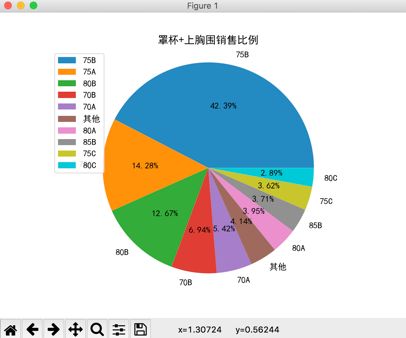
运行程序,会看到在窗口上显示了如图2所示的饼图。
哪一种颜色的胸罩卖的最好
这一节会按颜色统计胸罩的销售比例,从而可知哪一种颜色的胸罩卖的最好。按颜色对胸罩销售数据进行统计和按罩杯、上胸围对胸罩销售数据进行统计的方式类似,只是需要将分组的字段改成 color1。
from pandas import *
from matplotlib.pyplot import *
import sqlite3
import sqlalchemy
engine = sqlalchemy.create_engine('sqlite:///bra.sqlite')
rcParams['font.sans-serif'] = ['SimHei']
options.display.float_format = '{:,.2f}%'.format
sales = read_sql('select source,color1 from t_sales',engine)
# 按color1分组,并统计每组的数量
color1Count = sales.groupby('color1')['color1'].count()
# 统计总销量
color1Total = color1Count.sum()
print(color1Total)
color1 = color1Count.to_frame(name='销量')
print(color1)
color1.insert(0,'比例', 100 * color1Count / color1Total)
color1.index.names=['颜色']
color1 = color1.sort_values(['销量'], ascending=[0])
print(color1)
n = 1200
# 销量小于等于1200都属于“其他”分组
others = DataFrame([color1[color1['销量'] <= n].sum()],index=MultiIndex(levels=[['其他']],labels=[[0]]))
# 将others添加到原来的记录集中
color1 = color1[color1['销量']>n].append(others)
print(color1)
# 将索引转换为在饼图周围显示的标签
labels = color1.index.tolist()
pie(color1['销量'],labels=labels,autopct='%.2f%%')
legend()
axis('equal')
title('按胸罩颜色统计的比例')
show()
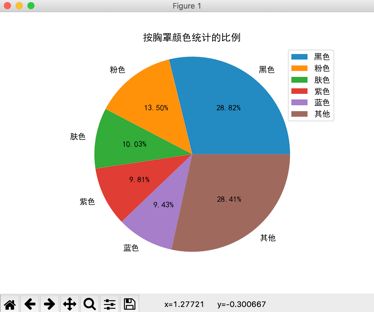
运行程序,会在窗口上显示如图3所示的饼图。
罩杯与上胸围分布【盒状图与直方图】
通过盒状图和直方图可以提现胸罩和上胸围的分布,也就是胸罩和上胸围主要集中在哪一个区域,要将罩杯和上胸围的综合统计数据显示在盒状图和直方图上,需要做一个变化。X 轴用浮点数同时表示罩杯和上胸围,整数部分表示罩杯,1:A、2:B、3:C、4:D。小数部分表示上胸围,如 .75 表示上胸围是 75,那么将整数和小数整合在一起就是 2.75 表示 75B、3.80 表示 80C,以此类推。
from pandas import *
from matplotlib.pyplot import *
import sqlite3
import sqlalchemy
engine = sqlalchemy.create_engine('sqlite:///bra.sqlite')
rcParams['font.sans-serif'] = ['SimHei']
options.display.float_format = '{:,.2f}%'.format
sales = read_sql('select source,size1,size2,color1 from t_sales', engine)
# 将A、B、C、D变成1、2、3、4
sales.loc[sales['size1'] == 'A','size1'] = 1
sales.loc[sales['size1'] == 'B','size1'] = 2
sales.loc[sales['size1'] == 'C','size1'] = 3
sales.loc[sales['size1'] == 'D','size1'] = 4
sales = sales.dropna()
print(sales)
# 组合整数和小数部分,变成2.75,2.80等样式
sales['size3'] = sales['size1'].astype('str') + '.' + sales['size2'].astype('str')
print(sales)
# 将size3转换为float类型的列
sales['size3'] = sales['size3'].astype('float')
box = {
'facecolor':'0.75',
'edgecolor':'b',
'boxstyle':'round'
}
fig,(ax1,ax2) = subplots(1,2,figsize=(12,6))
ax1.hist(x=sales.size3)
ax2.boxplot(sales.size3)
ax1.text(3.5,8000,'1:A\n2:B\n3:C\n4:D\n小数部分:上胸围\n1.80 = A80\n2.75 = B75',bbox = box)
ax2.text(1.2,4,'1:A\n2:B\n3:C\n4:D\n小数部分:上胸围\n1.80 = A80\n2.75 = B75',bbox = box)
show()
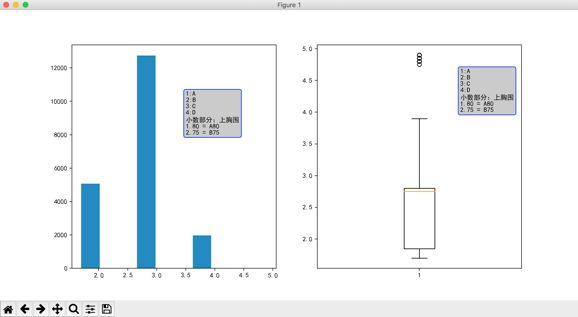
运行程序,会在窗口上显示如图4所示的直方图和盒状图。很显然,直方图和盒状图都显示数据主要集中在 2.0 到 3.0 之间,这区间主要包含 2.75、2.80、2.85 等值。而盒状图的平均值先正好在 2.75 的位置,所以说这这一尺寸的胸罩是最多的,也就是 75B,这个分析结果也正好与图4的结果吻合(75B 尺寸的胸罩销售量最大)。
本系列文章的项目是一个完整的集网络爬虫和数据分析于一体的系统,读者通过这个系统,可以非常全面地了解网络爬虫到底有什么用。