干货 | Elasticsearch开发人员最佳实战指南
题记
几个月以来,我一直在记录自己开发Elasticsearch应用程序的最佳实践。本文梳理的内容试图传达Java的某些思想,我相信其同样适用于其他编程语言。我尝试尽量避免重复教程和Elasticsearch官方文档中已经介绍的内容。本文梳理的内容都是从线上实践问题和个人总结的经验汇总得来的。
文章从以下几个维度展开讲解:
映射(Mapping)
设置(Setting)
查询方式(Querying)
实战技巧(Strategy)
1、映射(Mapping)
1.1 避免使用nested类型
每个Elasticsearch文档都对应一个Lucene文档。
nested类型是个例外,对于nested类型,每个字段都作为单独的文档存储与父Lucene的关联。
其影响是:
nested与父文档中的字段相比,查询字段的速度较慢
检索匹配nested字段会降低检索速度
一旦更新了包含nested字段的文档的任何字段(与是否更新嵌套字段无关,则所有基础Lucene文档(父级及其所有nested子级)都需要标记为已删除并重写)。除了降低更新速度外,此类操作还会产生大量垃圾文件,直到通过段合才能进行清理。
在某些情况下,你可以将nested字段展平。
例如,给定以下文档:
{
"attributes": [
{"key": "color", "val": "green"},
{"key": "color", "val": "blue"},
{"key": "size", "val": "medium"}
]
}
展平如下:
{
"attributes": {
"color": ["green", "blue"],
"size": "medium"
}
}
1.2 Mapping设置strict
实际业务中,如果不明确设定字段类型,Elasticsearch有动态映射机制,会根据插入数据自动匹配对应的类型。
假定:本来准备插入浮点型数据,但由于第一个插入数据为整形,Elasticsearch 自定会判定为long类型,虽然后续数据也能写入,但很明显“浮点类型”只阉割保留了整形部分。
铭毅给个demo一探究竟:
POST my_index03/_doc/1
{
"tvalue":35
}
POST my_index03/_doc/2
{
"tvalue":3.1415
}
GET my_index03/_mapping
GET my_index03/_search
{
"query": {
"term": {
"tvalue": {
"value": 3.1415
}
}
}
}
注意:term查询是不会返回结果的。
所以,实战环境中,Mapping设定要注意如下节点:
显示的指定字段类型
尽量避免使用动态模板(dynamic-templates)
禁用日期检测 (date_detection),默认情况下处于启用状态。“strict”实践举例:
PUT my_index
{
"mappings": {
"dynamic": "strict",
"properties": {
"user": {
"properties": {
"name": {
"type": "text"
},
"social_networks": {
"dynamic": "strict",
"properties": {
"network_id": {
"type": "keyword"
},
"network_name": {
"type": "keyword"
}
}
}
}
}
}
}
}
1.3 合理的设置string类型
Elasticsearch5.X 之后,String 被分成两种类型,text和keyword。两者的区别:
text:适用分词全文检索场景
keyword:适用字符串的精准匹配场景
默认,如果不显示指定字段类型,字符串类型自定映射后的Mapping如下所示:
"cont" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
而公司实战的业务场景,通常会面临:
需不需要分词,不需要的话仅保留keyword即可。
需要用什么分词?英文分词还是中文分词?
分词后是否还需要排序和聚合,即fielddata是否需要开启
是否需要精准匹配,即是否需要保留keyword
所以,回答了如上几个问题,再有针对的显示设定string类型的Mapping方为上策!
2、设置(Setting)
在这里,我分享了Elasticsearch集群 设置 相关的技巧。
2.1 避免过度分片
分片是Elasticsearch的最大优势之一,即将数据分散到多个节点以实施并行化。关于这个主题有过很多讨论。
但请注意,索引的主分片一旦设置便无法更改(除非重建索引或者reindex)。
对于新来者来说,过度分片是一个非常普遍的陷阱。在做出任何决定之前,请确保先通读官方的这篇博文:
我在 Elasticsearch 集群内应该设置多少个分片?
https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
铭毅提示:
主分片数过多:
批量写入或者查询请求被分割成过多的子写入、子查询,导致索引的写入、查询拒绝率上升。
主分片数过少:
尤其对于数据量非常庞大的索引,若分片数过少或者就1个分片,会导致无法利用集群多节点资源(也就是分布式特性),造成资源利用率不高或者不均衡,影响写入或者查询效率。
并且,一旦该大的主分片出现问题,恢复起来耗时会非常长。
2.2 取消学习任何段合并的技巧
从本质上讲,Elasticsearch是另一种分布式 Lucene产品,就像Solr一样 。在底层,大多数时候,每个Elasticsearch文档都对应一个Lucene文档(nested除外,如1.1所述)。在Lucene中,文档存储在 segment中。后台的Elasticsearch通过以下两种模式连续维护这些Lucene段:
在Lucene中,当你删除或更新文档时,旧文档被标记为已删除,而新文档被创建。Elasticsearch会跟踪这些标记为deleted的文档,适时对其段合并。
新添加的文档可能会产生大小不平衡的段。Elasticsearch可能会出于优化目的而决定将它们合并为更大的段。
实战中一定要注意:段合并是高度受磁盘I / O和CPU约束的操作。
作为用户,我们不想让段合并破坏Elasticsearch的查询性能。
事实上,在某些情况下可以完全避免使用它们:一次构建索引,不再更改它。尽管在许多应用场景中可能很难满足此条件。一旦开始插入新文档或更新现有文档,段合并就成为不可避免的一部分。
正在进行的段合并可能会严重破坏集群的总体查询性能。在Google上进行随机搜索,你会发现许多人发帖求助求助:“在段合并中减少对性能的影响的配置“,还有许多人共享某些适用于他们的配置。但,很多配置都是早期1.x,2.X版本的设置,新版本已经废弃。
综上,我进行段合并的经验法则如下:
取消学习任何段合并的技巧。早期版本的段合并配置是与Elasticsearch的内部紧密耦合的操作,新版本一般不再兼容。几乎没有“神秘”的底层配置修改可以使它运行得更快。
找到translog flush 的最优配置 。尝试调整index.translog.sync_interval和index.translog.flush_threshold_size设置。
详见:https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
动态调整index.refresh_interval以满足业务需求。如果实时性要求不高,可以调大刷新频率(默认是1s,可以调到30s甚至更大)。
PUT /twitter/_settings
{
"index" : {
"refresh_interval" : "30s"
}
}
2.3 注意JVM内存设置
Elasticsearch可以根据两个主要内存设置产生引人注目的性能特征:
JVM堆空间——主要用途:缓存(节点缓存、分片请求缓存、Field data缓存以及索引缓存)
堆外内存空间——lucene段文件缓存
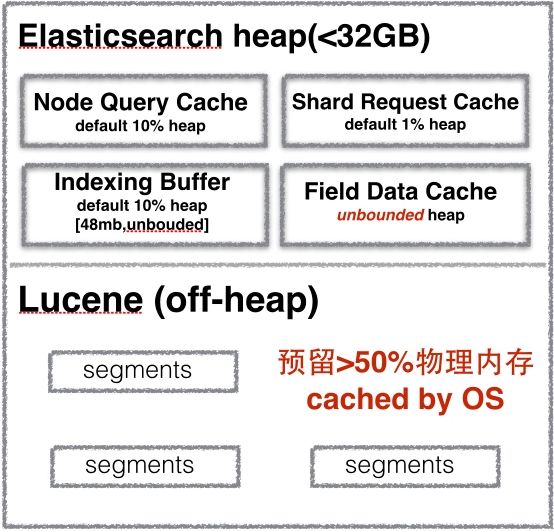
提醒你不要根据过去的非Elasticsearch JVM应用程序经验来盲目设置Elasticsearch JVM堆大小。
详见官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
3、查询方式(Querying)
下面我收集了一些技巧,你可以在Elasticsearch查询时使用它们。
3.1 Elasticseach里面多线程修改如何保证数据准确性?
1,用如下两个参数校验冲突
PUT products/_doc/1?if_seq_no=1&if_primary_term=1
{ "title":"iphone", "count":100 }
2,用version避免冲突
PUT products/_doc/1?version=30000&version_type=external
{ "title":"iphone", "count":100 }
3.2 尝试分割复杂的查询,并行执行提升性能
如果你同时具有过滤器和聚合组件的复杂查询,则在大多数情况下,可以将它们拆分为多个查询并并行执行它们可以提高查询性能。
也就是说,在第一个查询中,仅使用过滤器获取匹配,然后在第二个查询中,仅获取聚合结果而无需再获取检索结果,即size: 0。
3.3 了解你的数字类型,防止被优化导致精度损失
许多JSON解析器可以进行各种优化,以提供有效的读/写性能。但可能造成了精度的损失,所以在选型Jackson json解析器时:优先使用BigDecimal和BigInteger。
3.4 不要使用Elasticsearch Transport / Node客户端
TransportClient可以支持2.x,5.x版本,TransportClient将会在Elasticsearch 7.X版本弃用并在8.X版本中完成删除.
官方推荐使用Java High Level REST Client,它使用HTTP请求而不是Java序列化请求。为了安全起见,坚持使用HTTP上的JSON格式,而不使用 SMILE (二进制格式)。
3.5 使用官方的Elasticsearch High-level REST客户端
非官方客户端一般更新太慢,几乎无法跟上Elasticsearch新版本的特性,如:Jest客户端近一年几乎没有更新,只支持到6.X版本。
相比之下,官方REST客户端仍然是你相对最好的选择。https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.html
3.6 不要使用HTTP缓存来缓存Elasticsearch响应结果
由于便利性和低进入门槛,许多人陷入了将HTTP缓存(例如Varnish http://varnish-cache.org/)置于Elasticsearch集群前面的陷阱。使用HTTP缓存缺点如下:
在生产环境中使用Elasticsearch时,由于各种原因如:弹性扩展、测试和线上环境分离、零停机升级等,你很有可能最终会拥有多个集群。
(1)一旦为每个集群提供专用的HTTP缓存,99%的缓存内容是重复的。
(2)如果你决定对所有集群使用单个HTTP缓存,那么很难以编程方式配置HTTP缓存以适应不断变化的集群状态的需求。
如何传达集群负载以使缓存平衡流量?
如何配置计划内或手动停机时间?
在维护时段期间,如何使缓存逐渐从一个集群迁移到另一个集群?
这些都是亟待考虑的问题。
如上所述,HTTP缓存很难以编程方式进行实现。当你需要手动删除一个或多个条目时,它并不总是像DELETE FROM cache WHERE keys IN (...)查询那样容易。还得通过手动实现。
铭毅提示:这一条我实际没有用过,有用过的童鞋可以留言讨论。
3.7 使用基于_doc排序的slice scroll 遍历数据
Scrolls 是Elasticsearch提供的一种遍历工具,用来扫描整个数据集以获取大量甚至全量数据。它在功能上及内部实现上与RDBMS游标非常相似。但是,大多数人在第一次尝试中都没有使正确他。以下是一些基本知识:
如果你接触到scrolls,你可能正在读取大量数据。slicing 很可能会帮助你显著提高读取性能。
使用_doc进行排序,读取速度就会提高20%+,而无需进行其他任何更改。(_doc是一个伪字段)
scrollId调用之后会有变化。因此,请确保你始终使用最新检索的滚动scrollId。
在Reindex的时候使用slicing 也能提升索引数据迁移效率。
3.8 单文档检索 优先使用 GET /index/type/{id}而非POST /index/_search
Elasticsearch使用不同的线程池来处理 GET /index/type/{id}和 POST /index/_search查询。
使用POST /index/_search与有效载荷{query: {"match": {"_id": "123"}}}(或类似的东西)占据搜索专用线程池。
在高负载下,这将同时降低搜索和单个文档的获取性能。
所以,单文档坚持使用:GET /index/type/{id}。
3.9 使用size: 0和includes/ excludes限定字段返回
Elasticsearch在添加size: 0子句前后会带来显著的性能差异 。
除非业务需要,才返回必要字段,无需返回的字段通过includes和excludes控制。
3.10 提前做好压力测试,了解系统支持的上限
分享我的个人最佳实践:
使用应用程序的性能基准( performance benchmarks)测试来估计应用程序能提供支持的性能负载上限。
如基于esrally测试。
避免将线程池与无限制的任务队列一起使用。
队列的过度增长会对内存增加压力。
如果你的应用程序是借助第三方引擎中转或写入数据(例如,从kafka队列到Elasticsearch集群写入数据),请确保你的生产者对消费者的压力做出反应。
也就是说,如果消费者延迟开始增加,则最好开始降低生产者的速度。
3.11 在查询中提供明确的超时
几乎所有的Elasticsearch API都允许用户指定超时。
找出并摆脱耗时长的操作,节省相关资源,建立稳定的服务,这将对你的应用程序和Elasticsearch集群都有帮助。
3.12 不要使用注入变量的JSON模板
永远不要这样做:
{
"query": {
"bool": {
"filter": [
{
"term": {
"username": {
"value": {{username}}
}
}
},
{
"term": {
"password": {
"password": {{password}}
}
}
},
]
}
}
}
防止SQL注入,只要有人通过恶意username 和password输入,将暴露你的整个数据集,这只是时间问题。
我建议使用两种安全的方法来生成动态查询:
使用Elasticsearch官方客户端提供的查询模型。(这在Java上效果很好。)
使用JSON库(例如Jackson)构建JSON树并将其序列化为JSON。
4、实战技巧(Strategy)
在最后一节中,我收集了解决上述未解决问题的便捷的实战技巧。
4.1 始终(尝试)坚持使用最新的JVM和ES版本
Elasticsearch是一个Java应用程序。像其他所有Java应用程序一样,它也有hot paths和垃圾回收问题。几乎每个新的JVM版本都会带来很多优化,你可以不费吹灰之力利用这些优化。
Elasticsearch有一个官方页面,列出了支持的JVM版本和垃圾收集器。在尝试任何JVM升级之前,请务必先翻一翻如下文章清单:
https://www.elastic.co/guide/en/elasticsearch/guide/current/_don_8217_t_touch_these_settings.html
https://www.elastic.co/cn/support/matrix#matrix_jvm
注意:Elasticsearch升级也是免费获得性能提升的来源。
4.2 使用Elasticsearch完整和部分快照进行备份
Elasticsearch可以便捷的实现全部索引的全量快照或者部分索引数据的增量快照。
根据你的更新模式和索引大小,找到适合你的用例的快照最佳组合。
也就是说,例如,在00:00时有1个完整快照,在06:00、12:00和18:00时有3个局部增量快照。将它们存储在第三方存储也是一种好习惯。
有一些第三方 插件 可以简化这些情况。
举例:https://www.elastic.co/guide/en/elasticsearch/plugins/master/repository.html
与每份备份方案一样,安全起见,请确保快照可以还原并反复练习几次。
4.3 有一个持续的性能测试平台
像任何其他数据库一样,Elasticsearch在不同条件下显示不同的性能:
索引,文档大小;
更新,查询/检索模式;
索引,集群设置;
硬件,操作系统,JVM版本等。
很难跟踪每个设置的改变以观察其对整体性能的影响。确保你(至少)进行每日性能测试,以帮助缩小范围,快速定位最近引入的、导致性能下降的可能的原因。
这种性能测试说起来容易做起来难。你需要确保测试环境:
能有代表性的生产环境数据
配置和生产环境一致
完全覆盖用例
考虑包括操作系统缓存的测试的影响。
4.4 使用别名
告诉你一些颇有见地的实操经验:永远不要查询索引,而要查询 别名。
别名是指向实际索引的指针。你可以将一个或多个索引归为一个别名。
许多Elasticsearch索引在索引名称上都有内部上下文,例如events-20190515 代表20190515这一天的数据。
现在,在查询events-*索引时,应用程序代码中有两个选择:
选择1:通过特定日期格式即时确定索引名称:events-YYYYMMDD。
这种方法有两个主要缺点:
(1)需要回退到特定日期的索引,因此需要对整个代码库进行相应的设计以支持这种操作。
(2)撇开所有时钟同步问题,在凌晨,你需要用程序或者脚本控制索引切换,确保数据写入下一天索引。
选择2:创建一个events别名,指向events-*相关的索引。负责创建新索引的组件如:curator或者ILM(索引生命周期管理)可以自动将别名切换到新索引。
这种方法将带来两个明显的好处:
(1)它没有以前方法的缺点。
(2)只需指向events 别名,代码就会更简洁。
4.5 避免拥有大量同义词
Elasticsearch支持索引阶段和查询阶段指定 同义词。
没有同义词,搜索引擎是不完整的,但实战使用环境,注意如下问题:
索引阶段同义词增加了索引大小,并增加了运行时开销。
查询阶段同义词不会增加索引的大小,但顾名思义,这会增加运行时开销。
使用同义词,很容易在尝试修复其他问题时无意间破坏某些其他内容。
所以,要持续监视同义词对性能的影响,并尝试为添加的每个同义词编写测试用例。
同义词官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-tokenfilter.html
4.6 在启用副本之前强制段合并及增加带宽
一个非常常见的Elasticsearch用例是:定期(每两小时一次)创建一个索引。
关于如何实现最佳性能,SoundCloud上有一篇非常不错的 文章。从该文中引用,我特别发现以下几项“必须”。
在完成索引创建后,务必启用副本。
在启用副本之前,请确保:
(1)通过强制合并来缩小索引大小;
POST /twitter/_forcemerge
(2)临时增加副本传输带宽,直到分配完成为止 indices.recovery.max_bytes_per_sec。默认:40mb,该属性允许用户在恢复过程中控制网络的流量。设置一个比较大的值会导致网络变得繁忙,当然恢复过程也会加快。可以通过如下方式调整:
PUT /_cluster/settings
{
"transient": {
"indices.recovery.max_bytes_per_sec": "50mb"
}
}
推荐阅读:
https://developers.soundcloud.com/blog/how-to-reindex-1-billion-documents-in-1-hour-at-soundcloud
4.7 记录应用程序级别指标
Kibana对Elasticsearch性能提供了多维监控指标仪表盘:

indexing,
search latency and throughput,
flush
merge operations
GC pauses
heap size
OS (CPU usage, disk I/O
kernel caches 等......
但,这还不够。如果由多个应用程序使用,Elasticsearch将受到各种访问模式的影响。
想象一下,你的应用程序A试图删除1000万个不太重要的用户文档,而另一个组件B试图更新用户帐户详细信息。
如果你查看Elasticsearch监控指标,一切都是绿色正常。
但是,此时更新账户的用户可能不满意他们尝试更新帐户时的延迟。
因此,始终为你的Elasticsearch查询提供额外的应用程序级指标。
尽管Elasticsearch结合kibana或者cerbro已经为整体集群性能提供了足够的指标,但它们缺乏特定于操作的上下文监控,需要结合实际业务特事特办。
4.8 重视CPU的配置选型和使用率监控
怎么强调CPU都不过分。
从我过去的经验来看,无论是写负载还是读负载场景,CPU一直是我们的瓶颈。
4.9 谨慎编写自定义的Elasticsearch插件
许多Elasticsearch版本包含重大的内部更改。你的插件所基于的公共API很可能会向后不兼容。
你需要调整部署过程,不能再使用原始的Elasticsearch工作。
由于你的应用程序依赖于于插件提供的特定功能,因此在集成测试过程中运行的Elasticsearch实例也需要包含插件。你也就不能再使用原始的Docker镜像。
5、小结
本文是基于荷兰计算机博士:Volkan Yazıcı 文章翻译。翻译工作得到原作者的同意和许可。
原文名称:Elasticsearch Survival Guide for Developers
原文地址:https://vlkan.com/blog/post/2019/04/25/elasticsearch-survival-guide/#transport-client
文章很多细节值得实践中进一步消化吸收。文章没有直译,而在原文基础上,部分内容做了增删,部分内容加了实践和贴图,以达到简洁、通透的目的。
由于语言差异,尽管我翻译后又修正了2遍,难免部分细节还可能有些拗口,欢迎大家留言讨论。
推荐阅读:
干货 | Elasticsearch 索引设计实战指南
Elasticsearch性能优化实战指南
干货 | Elasticsearch多表关联设计指南
“金三银四“,敢不敢“试”?

更短时间更快习得更多干货!