大尺寸卫星图像目标检测:yoloT
大尺寸卫星图像目标检测:yoloT
- 前言
YOLT论文全称「You Only Look Twice: Rapid
Multi-Scale Object Detection In Satellite Imagery」,是专为卫星图像目标检测而设计的一个检测器,是在YOLOV2的基础上进行改进的。
论文原文:https://arxiv.org/abs/1805.09512?context=cs.CV
代码实现:https://github.com/CosmiQ/yolt
- 介绍
大范围图像中的小目标检测是卫星图像分析的主要问题之一。虽然地面图像中的目标检测得益于对新的深度学习方法的研究,但将这种技术过渡到头顶图像并非易事。挑战之一是每幅图像的像素数量和地理范围:一幅DigitalGlobe卫星图像的面积超过64平方公里,像素超过2.5亿。另一个挑战是,感兴趣的物体很小(通常只有10像素),这使传统的计算机视觉技术复杂化。为了解决这些问题,我们提出了一个管道(你只看两次,或者说YOLT),它可以以大于0.5 km2/s的速度评估任意大小的卫星图像。该方法可以在多个传感器上用相对较少的训练数据快速检测出不同尺度的物体。我们评估了原始分辨率下的大型测试图像,得到了F1>0.8的车辆定位分数。通过系统地测试管道在降低分辨率时的分辨率和目标大小要求,我们进一步探索了分辨率和目标大小的要求,并得出结论:只有~5像素大小的目标仍然可以高置信度地定位。
- YOLT核心理论
由于各种原因,深度学习方法在传统目标检测管道中的应用是不平凡的,由于卫星图像的独特性,需要采用多分辨率算法来解决与前景目标的空间范围、完全旋转不变性和大尺度搜索空间相关的挑战。排除实现细节,算法必须调整:感兴趣的卫星图像对象中的小空间范围通常非常小且密集,而不是像网数据中典型的大而突出的对象。在卫星领域,分辨率通常定义为地面采样距离(GSD),它描述一个图像像素的物理尺寸。商用图像从最清晰的数字地球图像的30厘米GSD到行星图像的3-4米GSD不等。这意味着,对于小型物体,如汽车座椅,即使在最高分辨率下,物体的范围也只有15像素。从头顶观察的完全旋转不变性对象可以具有任何方向(例如,船舶可以具有0到360度之间的任何航向,其中图像网数据中的树是可靠垂直的)。训练示例频率有一个相对地球的训练数据(尽管像SpaceNet这样的努力有可能改善这个问题)超高分辨率的输入图像是巨大的(通常是数亿像素),所以简单地降低采样到大多数算法所需的输入大小(几百像素)不是一个选项(见图1)。

卫星图像目标检测的主要几个难点以及YOLT的解决方案
我们来描述一下这几个难点和解决方案:
第一,卫星图目标的「尺寸,方向多样」。卫星图是从空中拍摄的,因此角度不固定,像船、汽车的方向都可能和常规目标检测算法中的差别较大,因此检测难度大。针对这一点的解决方案是对数据做「尺度变换,旋转等数据增强操作」。
第二,「小目标的检测难度大」。针对这一点解决方案有下面三点。
1、修改网络结构,使得YOLOV2的stride变成,而不是原始的,这样有利于检测出大小在。
2、沿用YOLOV2中的passthrough
layer,融合不同尺度的特征(和大小的特征),这种特征融合做法在目前大部分通用目标检测算法中被用来提升对小目标的检测效果。
3、不同尺度的检测模型融合,即Ensemble,原因是例如飞机和机场的尺度差异很大,因此采用不同尺度的输入训练检测模型,然后再融合检测结果得到最终输出。
第三,「卫星图像尺寸太大」。解决方案有将原始图像切块,然后分别输入模型进行检测以及将不同尺度的检测模型进行融合。
YOLT的网络结构如Table1所示:
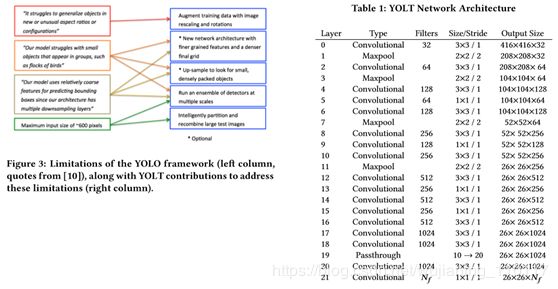
YOLT的网络结构
可以看到网络结构相对于YOLOV2最大的修改就是最后输出特征尺寸只到了,这样就能有效的提高对小目标的检测效果。
- 一些观察
Figure2展示了使用两种不同类型的图像作为输入时模型(原始的YOLOv2)的预测结果对比,左边是直接把卫星图像原图resize到大小,可有看到结果是一辆车都检测不出来。右边则是从原图中裁剪出大小的区域然后作为模型的输入,可以看到部分车被检测出来了,但是效果一般。从这个实验可以发现,如果直接将原图resize到网络输入大小是不靠谱的,所以YOLT采用了裁剪方式进行训练和测试图片。
将原图resize到网络输入大小是不合理的,还是得使用裁剪方式
Figure4则展示了在测试模型时如何对输入图像进行处理。

YOLT在测试模型时如何对输入图像进行处理
上半部分表示的是原始的卫星图片,因为图片分辨率太大,所以采用了划窗方式裁剪指定尺寸如的图像作为模型的输入,论文将裁剪后的区域称为chip,并且相邻的chip会有15%的重叠,这样做的目的是为了保证每个区域都能被完整检测到,虽然这带来了一些重复检测,但可以通过NMS算法滤掉。通过这种操作,一张卫星图像会被裁剪出数百/千张指定尺寸的图像,这些图像被检测之后将检测结果合并经过NMS处理后就可以获得最终的检测结果了。
Figure5展示了训练数据的整体情况,一共有个类别,包括飞机,船,建筑物,汽车,机场等。对训练数据的处理和测试数据是类似的,也是从原图裁剪多个chip喂给网络。
训练数据的整体情况,一共5个类别,注意有两张图像都是车
这篇论文的一个核心操作就是:
针对「机场目标」和「其它目标」分别训练了一个检测模型,这两个检测模型的输入图像尺度也不一样,测试图像时同理,最后将不同检测模型、不同chip的检测结果合并在一起就得到最终一张卫星图像的输出。也即是说这篇文章的核心操作就是这个「不同尺度的模型融合」以及「针对机场单独训练一个模型」,这样确实是从数据出发能够很好的解决实际场景(卫星图像)中机场目标数据太少带来的问题。
- 实验结果
Figure7展示了一张对于汽车目标的检测结果,可以看到效果还是不错的,并且在内能获得结果,同时F1值达到0.95。

YOLT对汽车目标的检测结果可视化
接下来作者还对不同输入分辨率做了实验,Figure10代表对原始分辨率(左上角的0.15m表示GSD是0.15m)进行不同程度的放大之后获得的低分辨率图像,这些图像都被用来训练模型,
不同分辨率的卫星图像
然后Figure13将不同分辨率输入下检测模型的F1值进行了图表量化,其中横坐标代表目标的像素尺寸。可以看到,随着分辨率的降低,图像中目标的像素尺寸也越来越小,检测效果(F1值)也越来越低。
我们还可以发现即便目标只有个像素点,依然有很好的检测效果,但需要注意的是这里的个像素点指的是在原图上,你crop之后目标的相对于网络输入的大小肯定是大于个像素点的,至少让YOLT网络能够检测出来。
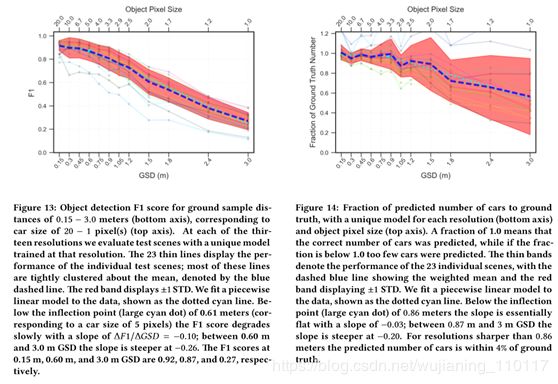
不同分辨率输入下检测模型的F1值可视化
其中不同的场景有不同颜色的线代表,不过这不重要,重要的已经讲过了。
Figure12则可视化了不同分辨率图像的检测效果,左边是15cm GSD的结果,右边则表示了90cm GSD的效果,直观来说,左边的效果是比右边好的。
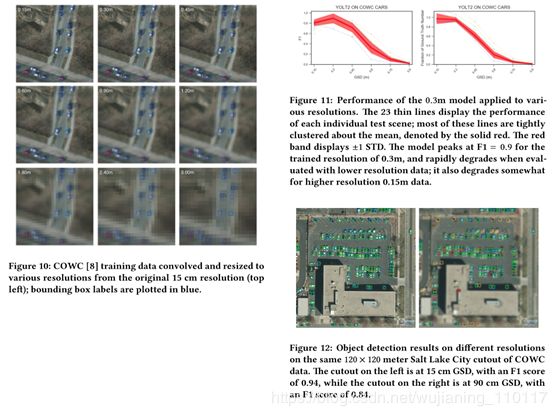
不同分辨率图像的检测效果
Table3展示了YOLT算法对于不同目标的测试精度以及速度情况。
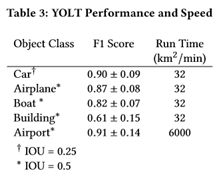
YOLT算法对于不同目标的测试精度以及速度情况
- 结论
在ImageNet风格的数据集中,目标检测算法在目标定位方面取得了很大的进展。然而,这种算法很少能很好地适应卫星图像中的目标大小或方向,也没有设计出数以亿计像素的处理图像。为了解决这些限制,本文实现了一个完全卷积的神经网络工作管道(YOLT),以快速定位卫星图像中的车辆、建筑物和机场。注意到,由于大小特征(如高速公路和跑道)之间的混淆,组合分类器的结果很差。在不同规模上训练双分类器(一个用于建筑物/车辆,一个用于基础设施),取得了更好的效果。根据类别,此管道产生的目标检测F1分数约为0.6~-0.9。虽然F1的分数可能不在许多读者从ImageNet比赛中习惯的水平,但卫星图像中的目标检测仍然是相对新生的领域,有着独特的挑战。此外,对于监督学习方法,针对大多数类别的训练数据集都相对较小,并且F1分数可能会随着检测的进一步后处理而提高。本文还演示了在一个传感器(如数字地球仪)上进行训练的能力,并将我们的模型应用于另一个传感器(如行星仪)。实验表明,至少对于从头顶观看的汽车,大于5像素的物体大小产生的物体检测分数F1>0.85。探测管道能够以自然分辨率评估任意输入尺寸的卫星和航空图像,以≈30km2的速率处理车辆和建筑物,以≈6000km2的速率处理机场。在这种推理速度下,16GPU集群可以对数字地球观3卫星进行实时推理。