SGC - Simplifying Graph Convolutional Networks 简化的图卷积网络 论文详解 ICML 2019
文章目录
- 1 相关介绍
- 1.1 Simple Graph Convolution (SGC)提出的背景
- 1.2 SGC效果
- 2 Simple Graph Convolution 简化的图卷积
- 2.1 符号定义
- 2.2 图卷积网络GCN
- GCN vs MLP
- Feature propagation 特征传播
- Feature transformation and nonlinear transition
- 分类器
- 2.3 简化的图卷积SGC
- 线性化
- 逻辑回归
- 优化细节
- 3 谱分析
- 3.1 在图上的初步做法
- 3.2 SGC and Low-Pass Filtering 简化的图卷积和低通滤波器
- 4 相关工作
- 4.1 图神经网络
- 4.2 其他在图上的工作
- graph embedding methods
- 5 实验结果
- 5.1 Citation Networks & Social Networks
- Performance
- Efficiency
- 5.2 下游任务
- Text classification
- Semi-supervised user geolocation
- Relation extraction
- Zero-shot image classification
- Graph classification
论文:Simplifying Graph Convolutional Networks 简化的图卷积网络GCN(SGC)
作者:Felix Wu, Tianyi Zhang, Amauri Holanda de Souza Jr., Christopher Fifty, Tao Yu, Kilian Q. Weinberger
来源:ICML 2019
论文链接:https://arxiv.org/abs/1902.07153v1
Github代码链接:https://github.com/Tiiiger/SGC
GCN在学习图的表示方面已经引起了广泛的关注,应用也非常广泛。GCNs的灵感主要来自最近的一些深度学习方法,因此可能会继承不必要的复杂度和冗余计算。文中通过反复消除GCN层之间的非线性并将得到的函数折叠成一个线性变换来减少GCNs的额外复杂度。并从理论上分析了得到的线性模型SGC,并证明了SGC相当于一个固定的低通道滤波器和一个线性分类器。实验结果表明,这些简化不会对许多下游应用的准确性产生负面影响。此外,得到的SGC模型可扩展到更大的数据集,并且比FastGCN产生两个数量级的加速。
1 相关介绍
1.1 Simple Graph Convolution (SGC)提出的背景
传统的机器学习方法的复杂度变化趋势都是从简单到复杂。例如从线性Perceptron到非线性MLP,从简单的线性图片filters到CNN都是这个趋势。GCN也是源于传统的机器学习方法,继承了这个复杂度的变化。此文的目的就是要把非线性的GCN转化成一个简单的线性模型SGC,通过反复消除GCN层之间的非线性并将得到的函数折叠成一个线性变换来减少GCNs的额外复杂度。
SGC中的特征提取等价在每个特征的维度上应用了单个固定的filter。
1.2 SGC效果
实验表明
- 这种简化了的线性SGC模型在很多任务上比GCN和一些其他GNN网络更高效,并且参数更少
- 并且在效率方面,在Reddit数据集上比FastGCN快两个数量级
- SGC在文本分类、用户地理定位、关系提取和zero-shot图像分类任务方面,即使不能超越基于GCN的方法,但至少也是竞争对手
2 Simple Graph Convolution 简化的图卷积
2.1 符号定义
- 图: G = ( V , A ) \mathcal{G}=(\mathcal{V}, \mathbf{A}) G=(V,A)
- A ∈ R n × n \mathbf{A} \in \mathbb{R}^{n \times n} A∈Rn×n是对称的邻接矩阵
- V \mathcal{V} V是图的节点集
- D = diag ( d 1 , … , d n ) \mathbf{D}=\operatorname{diag}\left(d_{1}, \ldots, d_{n}\right) D=diag(d1,…,dn)代表度矩阵, d i = ∑ j a i j d_{i}=\sum_{j} a_{i j} di=∑jaij
- y i ∈ { 0 , 1 } C \mathbf{y}_{i} \in\{0,1\}^{C} yi∈{0,1}C表示 C C C维的节点one-hot标签
数据集中只知道部分节点的标签,目标是预测未知的节点的标签。
2.2 图卷积网络GCN
GCN vs MLP
GCNs和MLPs相似,都是通过多层网络学习一个节点的特征向量 X i \mathbf{X}_{i} Xi,然后再把这个学到的特征向量送入的一个线性分类器中进行分类任务。一个 k k k层GCN与 k k k层MLP在应用于图中每个节点的特征向量 X i \mathbf{X}_{i} Xi是相同的,不同之处在于每个节点的隐藏表示在每一层的输入时是取的它的邻居的平均。
每个图中的卷积层和节点表示都是使用三个策略来更新
- 特征传播
- 线性转换
- 逐点非线性激活

Feature propagation 特征传播
GCN的特征传播是区别MLP的,因为每一层的输入都是节点局部邻居的平均值:
h ‾ i ( k ) ← 1 d i + 1 h i ( k − 1 ) + ∑ j = 1 n a i j ( d i + 1 ) ( d j + 1 ) h j ( k − 1 ) (2) \tag{2} \overline{\mathbf{h}}_{i}^{(k)} \leftarrow \frac{1}{d_{i}+1} \mathbf{h}_{i}^{(k-1)}+\sum_{j=1}^{n} \frac{a_{i j}}{\sqrt{\left(d_{i}+1\right)\left(d_{j}+1\right)}} \mathbf{h}_{j}^{(k-1)} hi(k)←di+11hi(k−1)+j=1∑n(di+1)(dj+1)aijhj(k−1)(2)
用一个简单的矩阵运算来表示公式(2)的更新:
S = D ~ − 1 2 A ~ D ~ − 1 2 (3) \tag{3} \mathbf{S}=\tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}} S=D~−21A~D~−21(3)
- S \mathbf{S} S表示添加自循环“normalized”的邻接矩阵(实际上并没有归一化)
- A ~ = A + I \tilde{\mathbf{A}}=\mathbf{A}+\mathbf{I} A~=A+I
- D \mathbf{D} D是 A \mathbf{A} A的度矩阵
用公式(2)对所有节点进行同时更新,得到了一个简单的稀疏矩阵乘法:
H ‾ ( k ) ← S H ( k − 1 ) (4) \tag{4} \overline{\mathbf{H}}^{(k)} \leftarrow \mathbf{S} \mathbf{H}^{(k-1)} H(k)←SH(k−1)(4)
这一步平滑了沿着图的边的局部隐藏表示,并最终支持在局部连接的节点之间进行类似的预测。
Feature transformation and nonlinear transition
在局部平滑之后,一个GCN层就等于一个标准的MLP。每一个层对应一个可学习的权重矩阵 Θ ( k ) \Theta^{(k)} Θ(k),所以平滑处理了的隐藏特征表示 H ‾ ( k ) \overline{\mathbf{H}}^{(k)} H(k)是线性转换的(后面乘一个参数矩阵是线性的)。最后在逐节点应用一个非线性激活函数,例如ReLU就可以得到输出的特征表示 H ( k ) \mathbf{H}^{(k)} H(k):
H ( k ) ← ReLU ( H ‾ ( k ) Θ ( k ) ) (5) \tag{5} \mathbf{H}^{(k)} \leftarrow \operatorname{ReLU}\left(\overline{\mathbf{H}}^{(k)} \Theta^{(k)}\right) H(k)←ReLU(H(k)Θ(k))(5)
分类器
对于节点分类任务,最后一层和MLP相似,都是使用一个softmax分类器预测节点的标签,一个 K K K层的GCN的所有节点的类别预测可以写作:
Y ^ G C N = softmax ( S H ( K − 1 ) Θ ( K ) ) (6) \tag{6} \hat{\mathbf{Y}}_{\mathrm{GCN}}=\operatorname{softmax}\left(\mathbf{S} \mathbf{H}^{(K-1)} \mathbf{\Theta}^{(K)}\right) Y^GCN=softmax(SH(K−1)Θ(K))(6)
- Y ^ ∈ R n × C \hat{\mathbf{Y}} \in \mathbb{R}^{n \times C} Y^∈Rn×C表示所有节点的类别的预测
- y ^ i c \hat{y}_{i c} y^ic表示节点 i i i预测为类别 c c c
- softmax ( x ) = exp ( x ) / ∑ c = 1 C exp ( x c ) \operatorname{softmax}(\mathbf{x})=\exp (\mathbf{x}) / \sum_{c=1}^{C} \exp \left(x_{c}\right) softmax(x)=exp(x)/∑c=1Cexp(xc)是一个归一化操作
2.3 简化的图卷积SGC
在传统的MLP中,层数变深加强了网络的表达能力,因为它允许创建特征的层次结构,例如,第二层的特征构建在第一层特征的基础上。在GCNs中,每一层都有一个重要的函数:在每一层中,隐藏的表示在1跳距离的邻居之间求平均值。这意味着在 k k k层之后,一个节点从图中所有 k k k跳的节点处获得特征信息。这种效果类似于卷积神经网络,深度增加了内部特征的感受野。虽然卷积网络可以在层数加深时提升性能(Deep networks with stochastic depth, 2016),但通常MLP的深度只限于为3至4层。
线性化
假设GCN层之间的非线性不是最关键的,最关键的是局部邻居的平均聚合操作。因此,考虑删除每层之间的非线性转换函数(如ReLU),只保留最终的softmax(以获得概率输出)。得到的模型是线性的
Y ^ = softmax ( S … S S X Θ ( 1 ) Θ ( 2 ) … Θ ( K ) ) (7) \tag{7} \hat{\mathbf{Y}}=\operatorname{softmax}\left(\mathbf{S} \ldots \mathbf{S}\mathbf{S}\mathbf{X} \mathbf{\Theta^{(1)} \Theta^{(2)} \ldots \Theta^{(K)}}\right) Y^=softmax(S…SSXΘ(1)Θ(2)…Θ(K))(7)
简化如下
Y ^ S G C = softmax ( S K X Θ ) (8) \tag{8} \hat{\mathbf{Y}}_{\mathrm{SGC}}=\operatorname{softmax}\left(\mathbf{S}^{K} \mathbf{X} \Theta\right) Y^SGC=softmax(SKXΘ)(8)
- S K = S … S S \mathbf{S}^{K}=\mathbf{S} \ldots \mathbf{S}\mathbf{S} SK=S…SS
- Θ = Θ ( 1 ) Θ ( 2 ) … Θ ( K ) \mathbf{\Theta=\Theta^{(1)} \Theta^{(2)} \ldots \Theta^{(K)}} Θ=Θ(1)Θ(2)…Θ(K)
这个简化的版本就叫做Simple Graph Convolution (SGC)。
逻辑回归
公式(8)给了SGC的一个自然直观的解释:SGC由两部分组成
- 一个固定的(没有参数,parameter-free)的特征提取器(或平滑器smoothing component): X ‾ = S K X \overline{\mathbf{X}}=\mathbf{S}^{K} \mathbf{X} X=SKX
- 特征提取器后是一个线性逻辑回归分类器 Y ^ = softmax ( X ‾ Θ ) \hat{\mathbf{Y}}=\operatorname{softmax}(\overline{\mathbf{X}} \Theta) Y^=softmax(XΘ)
可以看出,由于计算 X ‾ \overline{\mathbf{X}} X不需要权值,因此可以把这部分计算作为特征的预处理步骤,整个模型的训练可以直接简化为对预处理特征 X ‾ \overline{\mathbf{X}} X的多类逻辑回归。
优化细节
逻辑回归的训练是一个凸优化问题,可以用任何有效的二阶方法或随机梯度下降法进行执行(Large-scale machine learning with stochastic gradient descent,2010)。在图连通模式足够稀疏的情况下,SGD可以很自然地运用在非常大的图上,SGC的训练比GCN快得多。
3 谱分析
文中从图卷积的角度来研究SGC,并证明了SGC在图谱域上对于应一个固定的滤波器。此外,还证明了在原始图上添加自循环,即renormalization trick,可以有效地缩小底层图的谱。在这个缩放的谱域上,SGC充当一个低通滤波器,在图上生成平滑的特征。因此,邻居节点倾向于共享相似的表示,从而实现预测。
3.1 在图上的初步做法
经过傅里叶变换的信号 x x x和滤波器 g g g的GCN卷积操作为
g ∗ x = θ ( I + D − 1 / 2 A D − 1 / 2 ) x (11) \tag{11} \mathbf{g} * \mathbf{x}=\theta\left(\mathbf{I}+\mathbf{D}^{-1 / 2} \mathbf{A} \mathbf{D}^{-1 / 2}\right) \mathbf{x} g∗x=θ(I+D−1/2AD−1/2)x(11)
推导过程可以看GCN原始论文:Semi-Supervised Classification with Graph Convolutional Networks用图卷积进行半监督分类
最后,通过将卷积推广到 d d d维的通道输入中的多个滤波器上,并在每一层之间用非线性激活函数的分层模型,就得到了如公式(5)所定义的GCN传播规则
H ( k ) ← ReLU ( H ‾ ( k ) Θ ( k ) ) (5) \tag{5} \mathbf{H}^{(k)} \leftarrow \operatorname{ReLU}\left(\overline{\mathbf{H}}^{(k)} \Theta^{(k)}\right) H(k)←ReLU(H(k)Θ(k))(5)
3.2 SGC and Low-Pass Filtering 简化的图卷积和低通滤波器
定理1
对于一个简单,没有孤立节点的无向图。令 A ~ = A + γ I , γ > 0 \tilde{\mathbf{A}}=\mathbf{A}+\gamma \mathbf{I},\gamma>0 A~=A+γI,γ>0, λ 1 \lambda_1 λ1和 λ n \lambda_n λn分别是对称归一化的拉普拉斯矩阵 Δ s y m = I − D − 1 / 2 A D − 1 / 2 \Delta_{s y m}=\mathbf{I}-\mathbf{D}^{-1 / 2} \mathbf{A} \mathbf{D}^{-1 / 2} Δsym=I−D−1/2AD−1/2的最小和最大的特征值。令 λ ~ 1 \tilde{\lambda}_{1} λ~1和 λ ~ n \tilde{\lambda}_{n} λ~n分别 Δ ~ s y m = I − D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{\Delta}_{s y m}=\mathbf{I}-\tilde{\mathbf{D}}^{-1 / 2} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-1 / 2} Δ~sym=I−D~−1/2A~D~−1/2的最小和最大的特征值。则有
0 = λ 1 = λ ~ 1 < λ ~ n < λ n (12) \tag{12} 0=\lambda_{1}=\tilde{\lambda}_{1}<\tilde{\lambda}_{n}<\lambda_{n} 0=λ1=λ~1<λ~n<λn(12)
关于定理1的证明,可参考文中提供的附录部分。
从定理1可以看出,当 γ > 0 \gamma>0 γ>0时,相当于图中添加了自循环,则归一化的拉普拉斯矩阵的最大特征值会变小。
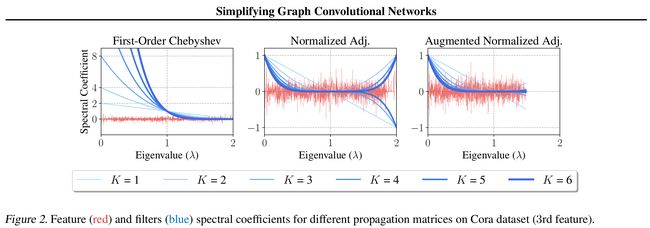
- 图2描述了在Cora数据集上使用的三种情况下特征值(频率)的变化和滤波器系数(谱系数)的变化关系
- Normalized Adjacency: S a d j = D − 1 / 2 A D − 1 / 2 \mathbf{S}_{\mathrm{adj}}=\mathbf{D}^{-1 / 2} \mathbf{A} \mathbf{D}^{-1 / 2} Sadj=D−1/2AD−1/2
- Augmented Normalized Adj: S ~ a d j = D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{\mathbf{S}}_{\mathrm{adj}}=\tilde{\mathbf{D}}^{-1 / 2} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-1 / 2} S~adj=D~−1/2A~D~−1/2
- First-Order Chebyshev: S 1 -order = ( I + D − 1 / 2 A D − 1 / 2 ) \mathbf{S}_{1 \text { -order }}=\left(\mathbf{I}+\mathbf{D}^{-1 / 2} \mathbf{A} \mathbf{D}^{-1 / 2}\right) S1 -order =(I+D−1/2AD−1/2)
- 使用 S a d j = D − 1 / 2 A D − 1 / 2 \mathbf{S}_{\mathrm{adj}}=\mathbf{D}^{-1 / 2} \mathbf{A} \mathbf{D}^{-1 / 2} Sadj=D−1/2AD−1/2的特征传播对应的滤波器 g ( λ i ) = ( 1 − λ i ) K g\left(\lambda_{i}\right)=\left(1-\lambda_{i}\right)^{K} g(λi)=(1−λi)K(展开就是一个关于拉普拉斯矩阵特征值的多项式)的取值范围为 [ 0 , 2 ] [0,2] [0,2]
- S a d j \mathbf{S}_{\mathrm{adj}} Sadj的奇数次幂在 λ i > 1 \lambda_i >1 λi>1时产生了负的滤波系数
- 添加了自循环的 S ~ a d j \tilde{\mathbf{S}}_{\mathrm{adj}} S~adj的最大特征值从2近似变为了1.5,并且消除了滤波系数为负数的影响
- 可以使用 S ~ a d j \tilde{\mathbf{S}}_{\mathrm{adj}} S~adj的 K > 1 K>1 K>1的幂来定义滤波器,此时为一个低通滤波器(文中附录部分对不同的传播函数提供了不同的选择)
4 相关工作
4.1 图神经网络
- Spectral networks and locally connected networks on graphs,ICML 2014-首次提出了一个扩展到图上的基于谱图理论的CNN网络
- Convolutional neural networks on graphs with fast localized spectral filtering,NIPS 2016-通过使用切比雪夫多项式近似消除了拉普拉斯矩阵分解带来的巨大的计算开销,定义了图卷积
- Semi-supervised classification with graph convolutional networks,ICLR 2017-通过使用预先定义的传播矩阵 S S S进行一阶切比雪夫近似,极大的降低了图卷积的计算,正式提出GCN
- Inductive representation learning on large graphs(GraphSAGE),NIPS 2017-Hamilton等人提出了一个inductive的图卷积,使用固定邻居size采样,然后进行邻居特征聚合
- Diffusion-convolutional neural networks,NIPS 2016;;NGCN: Multi-scale graph convolution for semi-supervised node classification,2018;Lanczosnet: Multi-scale deep graph convolutional networks,ICLR 2019-利用多尺度信息,将邻接矩阵 S S S提升到更高的阶
- How powerful are graph neural networks?,ICLR 2019-研究L图神经网络对任意两个图的区分能力,并引入图同构网络,证明其与图同构的Weisfeiler-Lehman检验同样强大
- Predict then propagate: Graph neural networks meet personalized pagerank,ICLR 2019-利用神经网络和个性化随机游走将非线性变换与传播分离
- Attention-based graph neural network for semisupervised learning,2018-提出了基于注意力机制的GCN
- A simple yet effective baseline for non-attribute graph classification,2018-提出了一种有效的基于节点度统计信息进行图分类的线性baseline
- Bootstrapped graph diffusions: Exposing the power of nonlinearity,2018-结果表明,使用线性特征/标签传播步骤的模型可以从自训练策略中提升效果
- Label efficient semi-supervised learning via graph filtering,CVPR 2019-提出了一种广义的标签传播,并提供了一个类似谱分析的renormalization trick
- Graph Attention Networks,ICLR 2018;Attention-based graph neural network for semisupervised learning,2018;Gaan: Gated attention networks for learning on large and spatiotemporal graphs,2018;Rethinking knowledge graph propagation for zero-shot learning,2018-这些基于注意力机制的模型为不同的边分配了权重,但是注意力机制也带来了内存的使用和巨大的计算开销
- 一篇基于图上的注意力模型的综述文章:Attention models in graphs: A survey,2018
4.2 其他在图上的工作
在图上的方法可分为两类:graph embedding methods和graph laplacian regularization methods。
graph embedding methods
- DeepWalk:它依赖于截断的随机游走,并使用一种skip-gram来生成节点表示
- Deep Graph Infomax (DGI),2019:用非监督策略学习图的节点表示,DGI通过最大化相互信息来训练一个图形卷积编码器
- …
5 实验结果
5.1 Citation Networks & Social Networks

Performance

- 表2中,可以看出SGC和GCN的性能相当,并且在Citeseer数据集上比GCN高1%。性能提升的原因可能是由于SGC的参数更少较少了过拟合GCN中的过拟合的情况
- GIN中就有严重的过拟合
- LNet and AdaLNet在引文网络上不稳定

- 表3是在Reddit社交网络数据集上的实验
- SGC比基于GCN的变种GraphSAGE和FastGCN高1%
- DGI论文中表示随机初始化的DGI编码器的性能几乎与经过训练的编码器的性能相匹配;然而,这两种模型在Reddit上的表现都不如SGC。这个结果可能表明,额外的权重和非线性激活在DGI编码器中是多余的
Efficiency
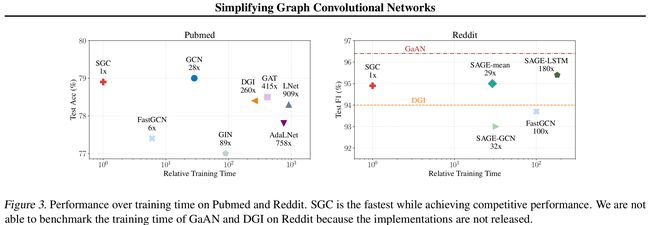
- 图3是在Pubmed和Reddit数据集上的效率对比图
- 显然,SGC是效率最高的
- SGC中 S K X \mathbf{S}^{K} \mathbf{X} SKX是预先计算的,SGC训练的时候只需要学习一个权重矩阵 Θ \Theta Θ,减少了内存的使用
- 由于 S \mathbf{S} S通常是稀疏的,而 K K K通常比较小,因此,可以用稀疏稠密矩阵乘法进行计算 S K X \mathbf{S}^{K} \mathbf{X} SKX
- 无法在Reddit上对GaAN和DGI的训练时间进行基准测试,因为实验没有发布
- GPU:NVIDIA GTX 1080 Ti
- 在大图上由于内存要求不能进行GCN的训练。FastGCN和GraphSAGE等方法使用采样的方法减少邻居数量来处理这个问题。Deep Graph InfoMax(ICLR,2019)通过限制模型的size来解决这个问题
- SGC训练的时候比使用快速采样的FastGCN快两个数量级,并且性能几乎没有损失
5.2 下游任务
使用5个下游任务来研究SGC的适应性:
- text classification
- semi-supervised user geolocation
- relation extraction
- zero-shot image classification
- graph classification
Text classification
- (Graph convolutional networks for text classification,2019)使用2层的GCN来实现了一个state-of-the-art的结果,创建了一个语料库图,该图将文档和单词都视为图中的节点。
- Word-word边的权值为点信息的互信息(point twise mutual information, PMI), word-document边的权值为标准化的TF-IDF socre。
- 如表4显示,一个SGC (K = 2)在5个基准数据集上与他们的模型竞争,同时达到了83.6倍的速度。

Semi-supervised user geolocation
- 半监督用户地理定位(Semi-supervised user geolocation)根据用户发布的帖子、用户之间的关系以及少数被标记的用户,来定位用户在社交媒体上的“家”的位置
- 表5显示,SGC在GEOTEXT、TWITTERUS和TWITTER-WORLD 的高速公路连接方面优于GCN,同时在TWITTER-WORLD上节省了30多个小时。

Relation extraction
- 关系抽取包括预测句子中主语和宾语之间的关系
- C-GCN采用LSTM,后面接着GCN和MLP层。实验将GCN替换为SGC (K = 2)
- 将得到的模型称为C-SGC

Zero-shot image classification
- zero-shot image分类包括学习一个图像分类器,不需要从测试类别中获取任何图像或标签
- GCNZ使用GCN将类别名称映射到图像特征域,并查找与查询图像特征向量最相似的类别 - 表7显示,使用MLP替换GCN,然后使用SGC可以提高性能,同时将参数数量减少55%
- 为了将预先训练好的GloVe向量映射到由ResNet-50提取的视觉特征空间,需要一个MLP特征提取器
- 同样,这个下游应用证明了学习图卷积滤波器是多余的

Graph classification
- 图分类要求模型使用图结构对图进行分类
- (How powerful are graph neural networks?,ICLR 2019)从理论上证明了GCNs不足以区分特定的图结构,并证明了GIN更具表现力,在各种图分类数据集上获得了 state-of-the-art的结果
- 将DCGCN中的GCN替换为SGC,分别获得NCI1和COLLAB数据集上的71.0%和76.2%,这与GCN相当,但远远落后于GIN
- 在QM8量子化学数据集上,更高级的AdaLNet和LNet在QM8上得到0.01MAE,远远超过SGC的0.03 MAE