【PaperReading】GraphIE:A Graph-Based Framework for Information Extraction
GraphIE:A Graph-Based Framework for Information Extraction
GraphIE:基于图的信息提取框架
Yujie Qian,Enrico Santus,Zhijing Jin,Jiang Guo,Regina Barzilay
Abstract
Most modern Information Extraction (IE) systems are implemented as sequential taggers and only model local dependencies. Non-local and non-sequential context is, however, a valuable source of information to improve predictions. In this paper, we introduce GraphIE, a framework that operates over a graph representing a broad set of dependencies between textual units (i.e. words or sentences). The algorithm propagates information between connected nodes through graph convolutions, generating a richer representation that can be exploited to improve word-level predictions. Evaluation on three different tasks — namely textual, social media and visual information extraction — shows that GraphIE consistently outperforms the state-of-the-art sequence tagging model by a significant margin.
摘要
大多数现代信息提取(IE)系统都实现为顺序标记器,并且仅对本地依赖项进行建模。 但是,非本地和非顺序上下文是改进预测的有价值的信息来源。 在本文中,我们介绍了GraphIE,这是一个在表示代表文本单位(即单词或句子)之间广泛依赖关系的图形的框架上运行。 该算法通过图卷积在连接的节点之间传播信息,从而生成更丰富的表示形式,可以用来改善单词级别的预测。 对三个不同任务(即文本,社交媒体和视觉信息提取)的评估表明,GraphIE在性能上一直明显领先于最新的序列标记模型。
源码下载地址:https://github.com/thomas0809/GraphIE
Introduce
大多数现代信息提取(IE)系统都实现为顺序标记器。 尽管此类模型有效地捕获了本地上下文中的关系,但它们利用非本地和非顺序依赖项的能力有限。 但是,在许多应用程序中,此类依赖性可以大大降低标记的歧义性,从而提高整体提取性能。 例如,当从文档中提取实体时,各种类型的非本地上下文信息(例如共同引用和相同的提及)可能会提供有价值的线索。 例如,请参见图1,其中非本地关系对于区分第二次提及华盛顿的实体类型(即人或地点)至关重要。

图1:一个不明确的实体提及情况的实体抽取任务示例(即,“…为华盛顿的请求…”)。 除了整合局部上下文信息的前向和后向边(绿色,纯色)以外,非局部关系(例如,共同指向边(红色,虚线)和相同提及边(蓝色,虚线))还提供了其他有价值的信息,以减少标记的歧义(即PERSON、ORGANIZATION或LOCATION)。
以往大多数研究非本地依赖关系的工作都是通过在结构化预测框架中约束输出空间来将它们合并的(Finkel等人,2005; Reichart和Barzilay,2012; Hu等人,2016)。但是,这些方法大多忽略了输入空间中更丰富的结构关系集。 参考图1中的示例,通过简单地限制输出空间将不容易利用共指关系,因为它们不一定被标记为实体(例如代词)。为了捕获输入空间中的非本地依赖关系,替代方法定义了一个图,该图概述了输入结构并描述了其特征(Quirk and Poon,2017)。然而,设计有效的特征是具有挑战性的,任意的和费时的,尤其是当基础结构复杂时。而且,这些方法具有有限的捕获由图结构告知的节点交互的能力。
在本文中,我们提出了GraphIE,该框架可通过自动学习输入空间中本地和非本地依赖项之间的交互来改善预测。 我们的方法将图形模块与编码器-解码器体系结构集成在一起,以进行序列标记。 该算法在图上运行,其中节点对应于文本单位(即单词或句子),而边描述它们之间的关系。 在我们模型的核心部分,递归神经网络顺序编码局部上下文表示,然后图模块使用图卷积在相邻节点之间迭代地传播信息(Kipf和Welling,2016)。 最后,将学习到的表示形式投影回循环解码器,以支持单词级别的标记。
我们评估GraphIE的三个IE任务,即文本,社交媒体和视觉(Aumann等,2006)信息提取。对于每个任务,我们在输入中提供一个简单的特定于任务的图形,该图形定义了数据结构,而无需访问任何主要处理或外部资源。我们的模型有望从相关的依赖中学习,以识别和提取适当的信息。在多个基准数据集上的实验结果表明,GraphIE始终胜过强大且通常采用的顺序模型(SeqIE,即双向长短期记忆(BiLSTM)和条件随机字段(CRF)模块)。具体而言,在文本IE任务中,我们在CONLL03数据集上比SeqIE改进了0.5%,在化学实体提取方面改进了1.4%(Krallinger等人,2015)。在社交媒体IE任务中,在从Twitter用户提取教育属性时,GraphIE比SeqIE提高了3.7%。最后,在可视化IE中,我们的表现优于基准1.2%。
Related Work
在文献中已经广泛研究了结合非局部和非顺序上下文以改善信息提取的问题。 大多数方法都集中于通过各种机制(例如后验正则化或泛化期望)在推理过程中对输出空间实施约束(Finkel et,2005; Mann和McCallum,2010; Reichart和Barzilay,2012; Li et al,2013; Hu et al. 2016)。
捕获输入空间中非本地依赖性的研究主要依赖于基于特征的方法。 Roberts(2008)以及Swampillai和Stevenson(2011)设计了基于话语和句法依存关系(例如最短路径)的句子内和句子间功能,以改善关系提取。 Quirk和Poon(2017)使用文档图来灵活表示单词之间的多种关系(例如句法,邻接和语篇关系)。
基于图的表示也可以通过神经网络来学习。 与我们最相关的工作是Kipf和Welling(2016)的图卷积网络,该网络被开发用于编码图结构并执行节点分类。 在我们的框架中,我们将GCN用作学习非本地上下文的中间模块,而不是直接用于分类,而是将其投影到解码器以丰富本地信息并执行序列标记。
少数其他信息提取方法已使用基于图的神经网络。 Miwa和Bansal(2016)应用Tree LSTM(Tai et al,2015)共同表示序列和依赖树,以进行实体和关系提取。在同一工作中,Peng(2017)和Song(2018)引入了Graph LSTM,它通过在每个存储单元中启用不同数量的输入边来将传统LSTM扩展到图。张(2018)利用图卷积在经过修剪的依赖关系树上合并信息,在关系提取任务中胜过现有序列和基于依赖关系的神经模型。这些研究在几个方面与我们的研究有所不同。首先,他们只能为单词级图建模,而我们的框架可以从单词级或句子级图中学习非本地上下文,并使用它来减少单词级标记时的歧义。其次,所有这些研究仅在使用依赖树时才得到改进。我们扩展了基于图的方法,以验证在更广泛的任务中使用其他类型的关系的好处,例如命名实体识别中的共指,社交媒体中的后续链接以及可视信息提取中的布局结构。
Problem Definition
我们将信息提取形式化为序列标记问题。 我们假设不是简单地将输入建模为序列,而是假设数据中存在一种图形结构,可以利用该结构捕获文本单位(即单词或句子)之间的非局部和非顺序依赖性。
我们考虑输入是一组句子 S = { s 1 , . . . , s N } S=\{s_1,...,s_N\} S={s1,...,sN},和一个辅助图 G = ( V , E ) G=(V,E) G=(V,E),其中 V = { v 1 , . . . , v M } V=\{v_1,...,v_M\} V={v1,...,vM}是节点集, E ⊂ V × V E\subset V\times V E⊂V×V是边集合。每个句子是单词的一个序列,我们考虑两种不同的图的设计:
(1)sentence-level graph:其中每个节点是一个句子(即 M = N M=N M=N),并且边编码了句子的相关性;
(2)word-level graph:每个节点是一个单词(即M是输入的单词的数量,边连接成对的单词,例如共同指代标记)。
图中的边 e i , j = ( v i , v j ) e_{i,j}=(v_i,v_j) ei,j=(vi,vj)既可以是有向的也可以是无向的。还可以定义多种边类型,以捕获特定于任务的输入数据的不同结构因素。
本文中,我们使用BIO(Begin,Inside,Outside)的标记方案。例如句子 s i = ( w 1 ( i ) , w 2 ( i ) , . . . , w k ( i ) ) s_i=(w_{1}^{(i)},w_{2}^{(i)},...,w_{k}^{(i)}) si=(w1(i),w2(i),...,wk(i))(虽然句子的长度可能不同,但为了简化符号,我们使用单个变量k),我们依次将每个单词标记为 y i = ( y 1 ( i ) , y 2 ( i ) , . . , y k ( i ) ) y_i=(y_1^{(i)},y_2^{(i)},..,y_k^{(i)}) yi=(y1(i),y2(i),..,yk(i))。
Method
GraphIE通过在节点表示之间迭代传播信息来共同学习局部和非局部依赖性。 我们的模型包含三个组成部分:
- an encoder, 它使用递归神经网络为文本单元(即单词或句子,取决于任务)生成本地上下文感知的隐藏表示。
- a graph module,捕获图结构,学习文本单元之间的非局部和非顺序依赖性;
- a decoder,利用由图模块生成的上下文信息来在单词级别执行标记。
图2展示了GraphIE的概述以及句子级和单词级图的模型架构。 在以下各节中,我们首先介绍句子级图的情况,然后说明如何针对词级图调整模型。
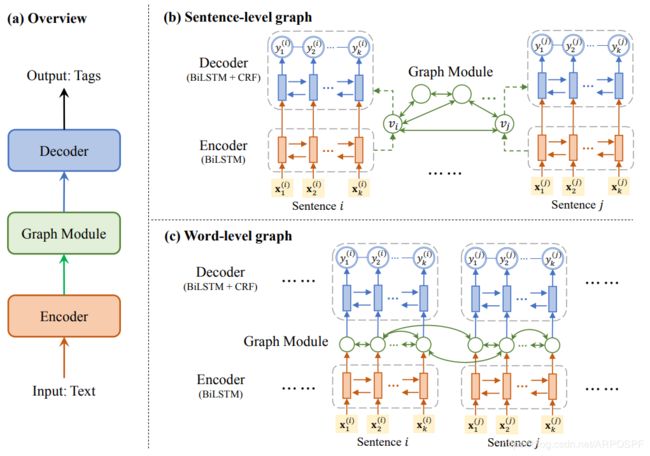
图2:GraphIE框架: (a)框架总览; (b)句子级图的体系结构,其中每个句子被编码为节点向量并馈入图模块,图模块的输出用作解码器的初始状态; ©词级图的体系结构,其中将编码器每个字的隐藏状态作为图模块的输入节点向量,然后将输出馈送到解码器。
Encoder
在GraphIE中,我们首先使用一个编码器去生成文本表示。给定一个长度为k的句子 s i = ( w 1 ( i ) , w 2 ( i ) , . . . , w k ( i ) ) s_i=(w_1^{(i)},w_2^{(i)},...,w_k^{(i)}) si=(w1(i),w2(i),...,wk(i)),每个单词 w t ( i ) w_t^{(i)} wt(i)由一个向量 x t ( i ) x_t^{(i)} xt(i)来表示,这是其单词嵌入和通过字符级卷积神经网络学习的特征向量的串联(CharCNN; Kim等人(2016))。 我们使用递归神经网络(RNN)对句子进行编码,将其定义为:
h 1 : k i = R N N ( x 1 : k ( i ) ; 0 , ⊖ e n c ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 1 ) h_{1:k}^{i}=RNN(x_{1:k}^{(i)};0,\ominus _{enc})..........................................................................(1) h1:ki=RNN(x1:k(i);0,⊖enc)..........................................................................(1)
其中 x l , k ( i ) x_{l,k}^{(i)} xl,k(i)表示输入句子 [ x 1 ( i ) , . . . , x k ( k ) ] [x_{1}^{(i)},...,x_k^{(k)}] [x1(i),...,xk(k)], h 1 : k ( i ) h_{1:k}^{(i)} h1:k(i)表示隐藏状态 [ h i ( i ) , . . , h k ( i ) ] [h_i^{(i)},..,h_k^{(i)}] [hi(i),..,hk(i)],0表明初始隐状态是0,并且 ⊖ e n c \ominus_{enc} ⊖enc表示编码器参数。我们将RNN实现为双向LSTM(Hochreiter和Schmidhuber,1997),并对每个句子进行独立编码。
对于句子 s i s_i si,我们通过平均其单词的隐状态来获得句子表示,即 E n c ( s i ) = 1 k ( ∑ t = 1 k ( h t ( i ) ) ) Enc(s_i)=\frac{1}{k}(\sum_{t=1}^{k}(h_{t}^{(i)})) Enc(si)=k1(∑t=1k(ht(i)))。然后将这个句子的表示馈入图模块。
Graph Module
图模块旨在从图中学习非局部和非等值信息。 我们采用图卷积网络(GCN)来对图上下文进行建模以进行信息提取。
给定一个句子级图 G = ( V , E ) G=(V,E) G=(V,E),其中每个节点 v i v_i vi(即,句子 s i s_i si)编码为 E n c ( s i ) Enc(s_i) Enc(si),用以捕获局部信息,图模块利用从图结构导出的邻接信息来丰富这种表示。
我们的图形模块是一个GCN,它以句子表示为输入,即 g i ( 0 ) = E n c ( s i ) g_i^{(0)}=Enc(s_i) gi(0)=Enc(si),并在每个节点上进行图卷积,在其相邻节点之间传播信息,并将这些信息整合为新的隐藏表示。具体来说,GCN的每一层都有两个部分。 第一部分从上一层获取每个节点的信息,即
α i ( l ) = W v ( l ) g i ( l − 1 ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 2 ) \alpha_i^{(l)}=W_v^{(l)}g_i^{(l-1)}..................................................................................(2) αi(l)=Wv(l)gi(l−1)..................................................................................(2)
其中, W v ( l ) W_v^{(l)} Wv(l)是学习到的权重,第二部分汇总来自每个节点邻居的信息,即对于节点 v i v_i vi,我们有
β i ( l ) = 1 d ( v i ) ⋅ W e ( l ) ( ∑ e i , j ∈ E g j ( l − 1 ) ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 3 ) \beta_i^{(l)}=\frac{1}{d(v_i)} \cdot W_e^{(l)}(\sum_{e_{i,j}\in E}^{}g_j^{(l-1)})...................................(3) βi(l)=d(vi)1⋅We(l)(ei,j∈E∑gj(l−1))...................................(3)
其中, d ( v i ) d(v_i) d(vi)是节点 v i v_i vi的度(即连接到 v i v_i vi的边的数量),并且被用于归一化 β i ( l ) \beta_i^{(l)} βi(l),确保不同度的节点具有相同比例的表示(我们选择这种简单的归一化策略,而不是Kipf和Welling(2016)中的双面归一化,因为它在实验中表现更好。 Zhang等人也采用了相同的策略(2018))。在最简单的情况下,图形中的边是无向的并且具有相同的类型,对于它们,我们使用相同的权重 W e ( l ) W_e^(l) We(l)。在更普遍的情况下,如果存在多种边类型,我们希望它们对聚合产生不同的影响。因此,我们使用等式3中的方法使用不同的权重对这些边类型进行建模,类似于Schlichtkrull等人(2018)提出的关联GCN模型。当边是有向的,即边 e i , j e_{i,j} ei,j不同于边 e j , i e_{j,i} ej,i,传播机制应该反映出这种差异。在这种情况下,我们把有向边视为两种边类型(前向和后向),并且对于它们使用不同的权重。
最后, α i ( l ) \alpha_i^{(l)} αi(l)和 β i ( l ) \beta_i^{(l)} βi(l)被合并以获得第 l l l层的表示,
g i ( l ) = σ ( α i ( l ) + β i ( l ) + b ( l ) ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 4 ) g_i^{(l)}=\sigma(\alpha_i^{(l)}+\beta_i^{(l)}+b^{(l)})........................................................(4) gi(l)=σ(αi(l)+βi(l)+b(l))........................................................(4)
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅)是一个非线性激活函数, b ( l ) b^{(l)} b(l)是一个偏差参数。
由于每一层仅仅在直接相连的节点之间传播信息,我们可以堆叠多个图卷积层以获得更大的接收域,即每个节点可以知道更远的邻居。经过 L L L层,对于每个节点 v i v_i vi,我们获得一个上下文表示, G C N ( s i ) = g i ( L ) GCN(s_i)=g_i^{(L)} GCN(si)=gi(L),即同时捕获局部和非局部的信息。
Decoder
为了支持标记,将学习到的表示传播到解码器。
在我们的工作中,解码器被实例化为BiLSTM+CRF标记器(Lample et al, 2016)。图形模块的输出表示 G C N ( s i ) GCN(s_i) GCN(si),分为了两个相同长度的向量,分别用作前向和后向LSTM的初始隐藏状态。这样,图上下文信息通过LSTM传播到每个单词。具体地,我们有
z 1 : k ( i ) = R N N ( h 1 : k ( i ) ; G C N ( s i ) , ⊖ d e c ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 5 ) z_{1:k}^{(i)}=RNN(h_{1:k}^{(i)};GCN(s_i), \ominus_{dec}).........................................................(5) z1:k(i)=RNN(h1:k(i);GCN(si),⊖dec).........................................................(5)
其中 h 1 : k ( i ) h_{1:k}^{(i)} h1:k(i)是编码器的输出隐状态。 G C N ( s i ) GCN(s_i) GCN(si)代表初始状态, ⊖ d e c \ominus_{dec} ⊖dec是解码器的参数。将图形表示形式合并到解码器中的一种更简单的方法是将其表示与输入连接,但是经验性能比用作初始状态要差。
最后,我们在BiLSTM的顶部使用CRF层(Lafferty等,2001)进行标记。
y i ∗ = a r g m a x y ∈ Y k p ( y ∣ z 1 : k ( i ) ; ⊖ c r f ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 6 ) y_i^*=arg max_{y\in Y_k} p(y|z_{1:k}^{(i)};\ominus_{crf})...........................................................(6) yi∗=argmaxy∈Ykp(y∣z1:k(i);⊖crf)...........................................................(6)
其中, Y k Y_k Yk是长度为k的所有可能标签序列的集合, ⊖ c r f \ominus_{crf} ⊖crf表示CRF参数,即标签的转换分数。CRF结合了BiLSTM的局部预测和转换分数来对标签序列的联合概率建模(在GraphIE中,图模块对输入空间结构进行建模,即对文本单元(即句子或单词)之间的依赖关系进行建模,最后的CRF层对输出标签的顺序连接进行建模。 即使输入图中可能存在循环,CRF仍会顺序运行,因此推理很容易。)。
Adaptation to Word-level Graphs
GraphIE可以轻松地用于对词级图进行建模。 在这种情况下,节点代表输入中的单词,即节点的数量M等于N个句子中单词的总数。此时,编码器中每个单词的隐藏状态都可以用作图模块的输入节点向量 g i ( 0 ) g_i^{(0)} gi(0)。然后,GCN可以在单词级图上进行图卷积,并为单词生成图上下文表示。 最后,解码器直接在GCN的输出上运行,即我们将BiLSTM解码器更改为
z 1 : k ( i ) = R N N ( [ G C N ( w 1 ( i ) ) , . . . , G C N ( w k ( i ) ) ] ; 0 ; ⊖ d e c ) z_{1:k}^{(i)}=RNN([GCN(w_1^{(i)}),...,GCN(w_k^{(i)})];0;\ominus_{dec}) z1:k(i)=RNN([GCN(w1(i)),...,GCN(wk(i))];0;⊖dec)
其中KaTeX parse error: Expected '}', got 'EOF' at end of input: GCN_{w_t^{(i)}是单词 w t ( i ) w_t^{(i)} wt(i)的GCN输出。在这种情况下,BiLSTM初始化状态被设置为默认0向量。CRF层保持不变。
从图2©中可以看出,单词级图模块与句子级模块不同,因为它直接从编码器获取单词表示并将其输出馈送到解码器。 在句子级图中,GCN对句子表示进行操作,然后将其用作解码器BiLSTM的初始状态。
Experimental Setup
我们在三个任务上评估该模型,其中包括两个传统的IE任务,即文本信息提取和社交媒体信息提取,以及一个未充分探索的任务——视觉信息提取。 对于这些任务中的每一项,我们创建了一个简单的特定于任务的图形拓扑,旨在轻松捕获输入数据的基础结构,而无需进行任何重大处理。 表1概述了这三个任务。
 表1:用于评估的三个IE任务中图结构的比较。
表1:用于评估的三个IE任务中图结构的比较。
Task 1:Textual Information Extraction
在此任务中,我们专注于话语级别的命名实体识别(DiscNER)。 与传统的句子级NER(SentNER)(分别对句子进行处理)不同,在DiscNER中,跨句子的长依赖关系和约束在标记过程中起着至关重要的作用。 例如,期望在同一对话中对同一实体的多次提及被一致地标记。 在这里,我们建议使用此(软)约束来改善实体提取。
数据集 我们对两个NER数据集进行了实验:CoNLL-2003数据集(CONLL03)(Tjong等人,2003年)和CHEMDNER数据集
用于化学实体提取(Krallinger et al。2015)。 我们遵循每个语料库的标准划分。 统计信息如表2所示。

表2:CONLL03和CHEMDNER数据集的统计信息(任务1)。
图构建 在此任务中,我们使用单词级图,其中节点表示单词。 我们为每个文档创建两种类型的边:
- 局部边(Local edges):在每个句子中相邻单词之间创建前向和后向边,从而可以利用局部上下文信息。
- 非局部边(Non-local edges):连接了除停用词以外的相同token的重复出现,以便可以传播信息,从而促进标签的全局一致性。(注意,可以使用其他非局部关系(例如,共同引用)(参见图1中的示例)进行进一步的改进。 但是,这些关系需要额外的资源才能获得,我们将其留给以后的工作。)
Task 2:Social Media Information Extraction
社交媒体信息提取是指从在线社交网络中的用户帖子中提取信息的任务(Benson等,2011; Li等,2014)。 本文旨在从用户的推文中提取教育和工作信息。 给定用户发布的一组推文,目标是提取对它们所属组织的提及。 推文简短且具有高度上下文相关性,并且显示特殊的语言特征,这一事实使这项任务特别具有挑战性。
数据集 我们根据Li等人(2014)发布的Twitter语料库构建了两个数据集:EDUCATION和JOB。 原始语料库包含由约1万名用户生成的数百万条推文,其中的教育和工作mentions均使用距离监督(distant supervision)进行注释(Mintzetal,2009)。 我们从每个用户中采样推文,并保持正面和负面帖子之间的比例(正面和负面是指推文中是否包含教育或职务说明)。 所获得的EDUCATION数据集包含由7,208位用户生成的443,476条推文,而JOB数据集包含由1,772位用户生成的176,043条推文。 数据集统计报告在表3中。
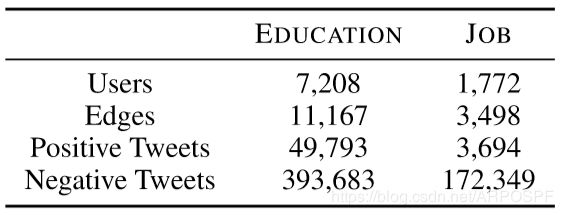 表3:EDUCATION和JOB数据集的统计信息(任务2)。
表3:EDUCATION和JOB数据集的统计信息(任务2)。
数据集都分为60%用于训练,20%用于开发和20%用于测试。 我们执行5个不同的随机分割,并报告平均结果。
图构建 我们将图构建为自我网络(ego-networks)(Leskovec和Mcauley,2012),即当我们提取有关一个用户的信息时,我们会考虑由用户及其直接邻居形成的子图。 每个节点对应一个Twitter用户,该用户由一组发布的推文表示(由于每个节点都是用户发布的一组推文,因此我们使用编码器对每个推文进行编码,然后对它们进行平均以获取节点表示形式。 在解码阶段,图模块的输出将针对每个推文馈送到解码器)。 假设连接的用户更有可能来自同一所大学或公司,则边由后继链接定义。 附录中报告了社交媒体图的示例。
Task 3:Visual Information Extraction
视觉信息提取是指从以各种布局格式化的文档中提取属性值。 示例包括发票和表格,其格式可用于推断有价值的信息以支持提取。
数据集 语料库由25,200个不良事件病例报告(AECR)组成,其中记录了与药物相关的副作用。 每个案例平均包含9页。 由于这些文件是由多个组织制作的,因此它们在版式和显示方式(例如文本,表格等)上表现出很大的差异(由于患者隐私和专有问题,无法共享此数据集)。 该数据集合配有单独的人工提取的ground truth数据库,可作为距离监督(distant supervision)的数据源。
我们的目标是提取与患者,事件,药物和报告者有关的八个属性(完整列表请参见表6)。 属性类型包括日期,单词和短语——可以直接从文档中提取。
将数据集分为50%的情况用于训练,10%的用于开发和40%的用于测试。
图构建 我们首先使用PDFMiner(https://euske.github.io/pdfminer/)将PDF转换为文本,该工具提供单词及其在页面中的位置(即边界框坐标)。 然后将连续单词以几何方式合并到文本框中。 每个文本框在此任务中均被视为“句子”,并且对应于图中的节点。
由于页面布局是这些文档中的主要结构因素,因此我们逐页进行工作,即每页对应一个图形。 边缘被定义为水平或垂直连接彼此靠近的节点(文本框)(即,当其边界框在垂直或水平方向上的重叠超过50%时)。 考虑了四种类型的边缘:从左到右,从右到左,从上到下和从上到下。 当多个节点对齐时,仅连接最近的节点。 附录中报告了可视文档图的示例。
Baseline and Our Method
我们实现了带有条件随机字段(CRF)标记器的两层BiLSTM,作为这些事例基线(SeqIE)。 该架构及其变体已被广泛研究并证明在先前的信息提取工作中是成功的(Lample et al。,2016; Ma and Hovy,2016)。 在文本IE任务(任务1)中,我们的基线显示为用CONLL03数据集中的最新方法获得了竞争结果。 在可视IE任务(任务3)中,为了进一步提高基线的竞争力,我们顺序连接了水平对齐的文本框,因此对图形的水平边缘进行了完全建模。
我们的基线与GraphIE共享相同的编码器和解码器体系结构,但没有Graph模块。 两种架构具有相似的计算成本。 在任务1中,我们将GraphIE与单词级图模块一起使用(请参见图2©),在任务2和任务3中,我们将GraphIE与句子级图模块一起应用(请参见图2(b))。
Implementation Details
使用Adam(Kingma and Ba,2014)对模型进行了训练,以最大程度地降低CRF目标。 为了进行正则化,我们在输入词表示形式和解码器的隐藏层上选择比率为0.1的dropout。 学习率设置为0.001。 我们使用开发集进行早期停止(early-stopping)和选择性能最佳的超参数。 对于CharCNN,我们使用64维字符嵌入和64个宽度为2到4的过滤器(Kim等,2016)。 在任务1和2中使用100维预训练的GloVe词嵌入(Pennington等人,2014年),在任务3中使用64维随机初始化的词嵌入。我们在Task1中使用两层GCN,在Task 2和Task 3中使用一层GCN。编码器和解码器BiLSTM具有与图卷积层相同的维度。 在任务3中,我们通过将其边界框坐标转换为长度为32的矢量,然后应用tanh激活,将位置编码与每个文本框的表示形式连接在一起。
Results
Task 1:Textual Information Extraction
表4描述了CoNLL03(Tjong et al.,2003)和CHEMDNER(Krallinger et al., 2015)数据集的NER精确度。

*表4,CONLL03和CHEMDNER数据集上的NER精度(任务1)。 我们方法的得分是5次测试的平均值。 表示优于SeqIE的统计学意义(p <0.01)。
对于CoNLL03数据集,我们列出了现有方法的性能。与最佳方法相比,我们的基准SeqIE获得了具有竞争力的得分。 事实是GraphIE的性能明显优于它,再次凸显了对非本地和非顺序依赖关系进行建模的重要性,并证实了我们的方法是实现此目标的合适方法。(在未使用最近引入的ELMo(Peters等人,2018)和BERT(Devlin等人,2018)的方法中,我们实现了最佳的报告性能,这些方法在超大型语料库上进行了预训练,并且对计算的要求很高。)
对于CHEMDNER数据集,表明具有最高性能的方法是Krallinger等的文章(2015),即使用基于特征的方法获得。 我们的基准性能优于基于特征的方法,而GraphIE进一步将性能提高了1.4%。
分析 为了理解GraphIE的优势,首先,我们研究了图结构对模型的重要性。如图3所示,使用随机连接显然会损害性能,将GraphIE的F1分数从95.12%降低到94.29%。 这表明特定于任务的图形结构引入了有益的归纳偏差(inductive bias)。 琐碎的特征增强也不能很好地起作用,这证实了学习使用GCN嵌入图形的必要性。
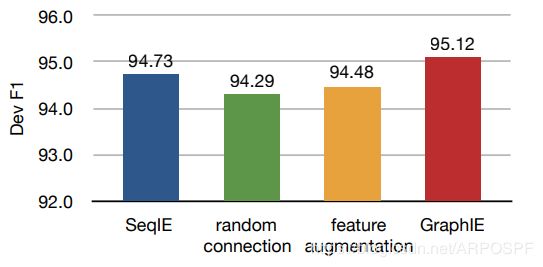
图3:CoNLL03数据集分析。我们将其和两个可替代的方案进行比对:(1)随机连接(random connection),其中我们用边数相同的随机图代替构造图;(2)特征增强(feature augmentation),我们使用每个节点及其邻居的平均嵌入作为解码器的输入,而不是具有附加参数的GCN。 我们在开发集上报告F1分数。
我们进一步在测试集上进行错误分析,以验证GraphIE通过鼓励相同实体提及(encouraging consistency among identical entity mentions)之间的一致性来解决标签歧义的动机(请参见图1)。在此我们检查单词级标签的准确性。 我们将数据集中具有多个可能标签的单词定义为不明确的(ambiguous)。 我们发现,在SeqIE的1.78%标记错误中,有1.16%是不明确的(ambiguous),而有0.62%是无歧义的(unambiguous)。 GraphIE可以将错误率降低到1.67%,其中不明确的(ambiguous)为1.06%,无歧义的(unambiguous)为0.61%。 我们可以看到,大多数错误减少的确归因于歧义词(ambiguous words)。
Task 2:Social Media Information Extraction
表5显示了社交媒体信息提取任务的结果。首先,我们以一个简单的基于字典的方法为基准。Neural IE模型的性能要好得多,这表明模型可以学习有意义的模式,而不仅仅是记住训练集中的实体。提出的GraphIE在EDUCATION和JOB数据集中均优于SeqIE,并且对EDUCATION数据集的改进更为显着(3.7% vs 0.3%)。造成这种差异的原因是两个数据集之间的亲和力得分(affinity scores)存在差异(Mislove等,2010)。 Li等(2014年)强调EDUCATION的亲和力值为74.3,而JOB的亲和力值为14.5,这意味着在数据集中,邻居在同一所大学学习的可能性是在同一所大学工作的可能性的5倍。因此,我们可以期望利用GraphIE之类的模型来利用邻接信息,从而在具有更高亲和力的数据集中获得更好的性能。
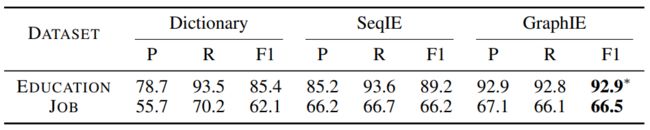
*表5,EDUCATION和JOB数据集的提取精度(任务2)。字典是一种简单的方法,可以从训练集中创建实体的字典,并在测试期间提取其提及(mentions)。 分数是5次运行的平均值。 表示相对于SeqIE的改进是具有统计学意义(Welch’s t-test, p<0.01)。
Task 3:Visual Information Extraction
表6展示了在视觉信息提取任务中的结果。GraphIE在大多数属性上均优于SeqIE基线方法,并且在micro average F1 score上提高了1.2%。它证实了在视觉信息提取中使用布局图结构的好处。
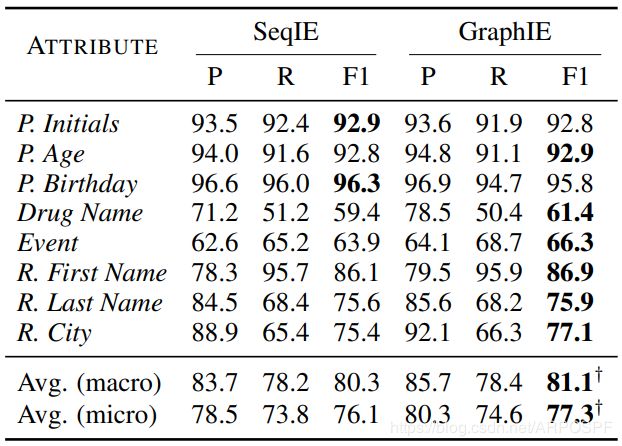
表6:AECR数据集上的提取精度(任务3)。得分是5次运行的平均值。 P . P. P.是Patient的缩写, R . R. R.是Reporter的缩写。$\dagger $表示与SeqIE相比改善的统计意义(p<0.05)。
提取性能随属性的不同而变化,从药物名称的61.4%到患者生日的95.8%不等(基线方法中可见类似的变化)。 同样,GraphIE和SeqIE之间的差异随属性而变化,在患者生日时为−0.5%,在事件时为2.4%。
在表7所述的消融测试(ablation test)中,我们可以看到以下贡献:对不同边缘类型(+ 0.8%),水平边缘(+ 3.1%),垂直边缘(+ 5.4%)和CRF(+5.7%)使用单独的权重。
泛化我们还将通过额外的分析来评估GraphIE处理看不见的布局的能力。 从我们的数据集中,我们抽样2,000个包含三个最常用模板的报告,并在此子集中训练模型。 然后,我们在两种设置下测试所有模型:1)可见的模板(seen templates),其中包含1,000个其他报告,它们位于用于训练的同一模板中; 和2)看不见的模板(unseen templates),由两种新模板类型的1,000个报告组成。
图4报告了GraphIE和SeqIE的性能。这两个模型在可见模板上均取得了不错的结果,而GraphIE的得分仍然比SeqIE高出2.8%。 当我们的模型和顺序模型在看不见的模板上进行测试时,差距变得更大(20.3%),这表明通过显式建模更丰富的结构关系,GraphIE可以实现更好的通用性。
Conclusions
我们引入了GraphIE,这是一个信息提取框架,可从图结构中学习局部和非局部上下文表示,以改善预测。 该系统在特定于任务的图形拓扑上运行,该拓扑描述了输入数据的基础结构。 GraphIE共同对节点(即文本单位,即单词或句子)表示及其依赖性进行建模。 图卷积通过相邻节点投影信息,以最终在字级标记期间支持解码器。
我们评估了三个IE任务的框架,即文本,社交媒体和视觉信息提取。 结果表明,它可以有效地对非局部和非顺序上下文进行建模,从而始终如一地提高准确性并优于竞争性SeqIE基线方法(即BiLSTM + CRF)。
未来的工作包括探索自动学习输入数据的基础图形结构的方法。
Acknowledgements
We thank the MIT NLP group and the reviewers for their helpful comments. This work is supported by MIT-IBM Watson AI Lab. Any opinions, findings, conclusions, or recommendations expressed in this paper are those of the authors, and do not necessarily reflect the views of the funding organizations.
References
Yonatan Aumann, Ronen Feldman, Yair Liberzon,Benjamin Rosenfeld, and Jonathan Schler. 2006. Visual information extraction. Knowl. Inf. Syst.,10(1):1–15.
Edward Benson, Aria Haghighi, and Regina Barzilay.2011. Event discovery in social media feeds. In Proceedings of ACL, pages 389–398. ACL.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Jenny Rose Finkel, Trond Grenager, and Christopher Manning. 2005. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of ACL, pages 363–370. ACL.
Sepp Hochreiter and Jurgen Schmidhuber. 1997. ¨ Long short-term memory. Neural computation, 9(8):1735–1780.
Zhiting Hu, Xuezhe Ma, Zhengzhong Liu, Eduard Hovy, and Eric Xing. 2016. Harnessing deep neural networks with logic rules. In Proceedings of ACL, pages 2410–2420.
Yoon Kim, Yacine Jernite, David Sontag, and Alexander M Rush. 2016. Character-aware neural language models. In Proceedings of AAAI, pages 2741–2749. AAAI Press.
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Thomas N Kipf and Max Welling. 2016. Semisupervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
Martin Krallinger, Florian Leitner, Obdulia Rabal, Miguel Vazquez, Julen Oyarzabal, and Alfonso Valencia. 2015. Chemdner: The drugs and chemical names extraction challenge. Journal of cheminformatics, 7(1):S1.
John D Lafferty, Andrew McCallum, and Fernando CN Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of ICML, pages 282–289.
Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016.
Neural architectures for named entity recognition. In Proceedings of NAACL-HLT, pages 260–270, San Diego, California. ACL.
Jure Leskovec and Julian J Mcauley. 2012. Learning to discover social circles in ego networks. In NIPS, pages 539–547.
Jiwei Li, Alan Ritter, and Eduard Hovy. 2014. Weakly supervised user profile extraction from twitter. In Proceedings of ACL, volume 1, pages 165–174.
Qi Li, Heng Ji, and Liang Huang. 2013. Joint event extraction via structured prediction with global features. In Proceedings of ACL, volume 1, pages 73–82.
Xuezhe Ma and Eduard Hovy. 2016. End-to-end sequence labeling via bi-directional lstm-cnns-crf. In Proceedings of ACL, pages 1064–1074, Berlin, Germany. ACL.
Gideon S Mann and Andrew McCallum. 2010. Generalized expectation criteria for semi-supervised learning with weakly labeled data. Journal of Machine Learning Research, 11(Feb):955–984.
Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of ACL, pages 1003–1011. ACL.
Alan Mislove, Bimal Viswanath, Krishna P Gummadi, and Peter Druschel. 2010. You are who you know: inferring user profiles in online social networks. InProceedings of the 3rd ACM International Conference on Web Search and Data Mining, pages 251–260. ACM.
Makoto Miwa and Mohit Bansal. 2016. End-to-end relation extraction using lstms on sequences and tree structures. arXiv preprint arXiv:1601.00770.
Nanyun Peng, Hoifung Poon, Chris Quirk, Kristina Toutanova, and Wen-tau Yih. 2017. Cross-sentencen-ary relation extraction with graph lstms. TACL, 5:101–115.
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. Glove: Global vectors for word representation. In Proceedings of EMNLP, pages 1532–1543.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of NAACL-HLT, volume 1, pages 2227–2237.
Chris Quirk and Hoifung Poon. 2017. Distant supervision for relation extraction beyond the sentence boundary. In Proceedings of ACL, volume 1, pages 1171–1182.
Roi Reichart and Regina Barzilay. 2012. Multi event extraction guided by global constraints. In Proceedings of NAACL-HLT, pages 70–79. ACL.
Angus Roberts, Robert Gaizauskas, and Mark Hepple. 2008. Extracting clinical relationships from patient narratives. In Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing, pages 10–18. ACL.
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In European Semantic Web Conference, pages 593–607. Springer.
Linfeng Song, Yue Zhang, Zhiguo Wang, and Daniel Gildea. 2018. N-ary relation extraction using graphstate lstm. In Proceedings of EMNLP, pages 2226–2235.
Kumutha Swampillai and Mark Stevenson. 2011. Extracting relations within and across sentences. In Proceedings of the International Conference Recent Advances in Natural Language Processing, pages 25–32.
Kai Sheng Tai, Richard Socher, and Christopher D Manning. 2015. Improved semantic representations from tree-structured long short-term memory networks. arXiv preprint arXiv:1503.00075.
Kim Sang Tjong, F Erik, and Fien De Meulder. 2003. Introduction to the conll-2003 shared task: Language-independent named entity recognition. In Proceedings of NAACL-HLT, pages 142–147. ACL.
Zhixiu Ye and Zhen-Hua Ling. 2018. Hybrid semimarkov crf for neural sequence labeling. In Proceedings of ACL, pages 235–240.
Yuhao Zhang, Peng Qi, and Christopher D Manning. 2018. Graph convolution over pruned dependency trees improves relation extraction. In Proceedings of EMNLP.
Appendices
我们展示了一些用于不同信息提取任务的构造图示例。
社交媒体信息提取

图5 社交媒体信息提取的模拟示例(任务2)。 节点表示为用户,边表示后续关系。
视觉信息提取

图6:视觉信息提取的模型示例(任务3)。 两种形式具有不同的布局。 图形相关性显示为绿色线条,用于在蓝色边框中连接文本。