最详细的Spark内存管理
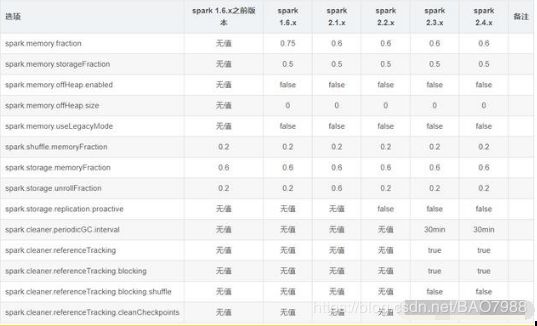
spark 各版本的内存参数:
一.Spark 1.6内存管理:
spark 1.6之前 使用StaticMemoryManager,叫legacy模式,默认是关闭的。
spark1.6开始,使用UnifiedMemoryManager。
1.6开始的内存结构:

由上图知道,内存由三部分组成。
1.Reserved Memory ,系统保留的内存,是硬编码写死的,spark 1.6 这个值是300MB.这300MB不算在spark使用的内存里。
2.user Memory 是spark Memory分配之后保留的。根据你自己的需要使用这块内存区域。 在spark 1.6中这块内存的大小计算:
(“Java Heap” – “Reserved Memory”) * (1.0 – spark.memory.fraction) ,默认大小: (“Java Heap” – 300MB) * 0.25
spark完全不关心你在这个区域做了什么和也不管是否达到了内存限制。如果超过内存限制会报OOM.
3.Spark Memory
这个区域是 spark管理的内存。 计算公式: (“Java Heap” – “Reserved Memory”) * spark.memory.fraction, spark 1.6 默认大小: (“Java Heap” – 300MB) * 0.75。
这个区域分成两块。Storage Memory和Execution Memory 这两块内存的边界由 spark.memory.storageFraction指定,默认0.5.
这个边界不是静态的,会移动。
3.1.Storage Memory
cache数据, broadcast 变量的数据,unroll序列化数据的临时空间。
内存计算:
“Spark Memory” * spark.memory.storageFraction = (“Java Heap” – “Reserved Memory”) * spark.memory.fraction * spark.memory.storageFraction.
默认:(“Java Heap” – 300MB) * 0.75 * 0.5 = (“Java Heap” – 300MB) * 0.375
3.2.Execution Memory: 存储任务运行期间需要的对象。
边界移动:Storage Memory 内数据可以被强制清除,但是Execution Memory内数据不能被强制清除。
2.关于executor.memoryOverhead
这块内存是分配给每个executor的堆外内存。executorMemory * 0.10, with minimum of 384
The amount of off-heap memory (in megabytes) to be allocated per executor. This is memory that accounts for things like VM overheads, interned strings, other native overheads, etc. This tends to grow with the executor size (typically 6-10%).
MemoryOverhead是JVM进程中除Java堆以外占用的空间大小,包括方法区(永久代)、Java虚拟机栈、本地方法栈、JVM进程本身所用的内存、直接内存(Direct Memory)等。通过spark.yarn.executor.memoryOverhead设置,单位MB。
二.Spark2.0+ 内存管理
1.Driver Memory
driver端的内存比较简单。Spark.driver.memory 默认1G 设置driver的堆内存。在yarn集群上执行时,也有overhead内存,为了防止使用太多资源时,导致driver container 被yarn给过早地kill掉。

2.executor Memory
2.1.executor的内存分布:
spark.executor.memory 指定executor的堆内存,默认1G.
spark.yarn.executor,memoryOverhead内存介绍相见spark1.6内存管理介绍。
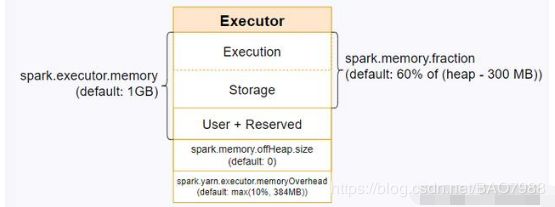
2.2.堆内存的分布:
堆内存主要是spark.execotor.memory指定的内存。

spark.memory.fraction指定的是storage和execution共享的内存,默认各占50%。
spark.memory.storageFraction。指定存储内存免于被执行内存驱逐的比例。默认0.5,在使用的时候,合理的配置该参数。例如,如果应用使用大量的cache 数据和没有太多的聚合操作,你可以增加storage memory把cache所有的数据到内存。
spark中的内存分为多个部分,UI页面上显示的只是缓存RDD用的storage memory,大约是(总内存 - 300M) * 60% * 50% 的量,所以会偏小。
executor默认的永久代内存是64K,如果看到永久代使用率长时间为99%,通过设置spark.executor.extraJavaOptions适当增大永久代内存,例如:–conf spark.executor.extraJavaOptions=”-XX:MaxPermSize=64m”
3.关于off-heap作为存储和执行内存
spark也可以使用堆外内存作为storage和execution内存。由spark.memory.offHeap.enabled 控制,默认为false。
spark.memory.offHeap.size指定内存大小,默认0.
4.DataFrame和Dataset 内存管理
高级api使用自己的方式管理内存,作为Tungsten计划的一部分。由于数据类型对框架是已知的,并且它们的生命周期定义得非常好,因此可以通过预先分配内存块并显式地对这些块进行微管理来完全避免垃圾收集。这将极大地重用分配的内存,有效地消除了在执行内存中进行垃圾收集的需要。这种优化实际上工作得非常好,以至于启用堆外内存几乎没有额外的好处(尽管仍然有一些好处)。